Python单函数读取常用文件
代码如下:
import pandas as pd# 读取数据文件
def readDataFile(readPath): # readPath: 数据文件的地址和文件名try:if (readPath[-4:] == ".csv"):dfFile = pd.read_csv(readPath, header=0, sep=",") # 间隔符为逗号,首行为标题行# dfFile = pd.read_csv(filePath, header=None, sep=",") # sep: 间隔符,无标题行elif (readPath[-4:] == ".xls") or (readPath[-5:] == ".xlsx"): # sheet_name 默认为 0dfFile = pd.read_excel(readPath, header=0) # 首行为标题行# dfFile = pd.read_excel(filePath, header=None) # 无标题行elif (readPath[-4:] == ".dat"): # sep: 间隔符,header:首行是否为标题行dfFile = pd.read_table(readPath, sep=" ", header=0) # 间隔符为空格,首行为标题行# dfFile = pd.read_table(filePath,sep=",",header=None) # 间隔符为逗号,无标题行else:print("不支持的文件格式。")except Exception as e:print("读取数据文件失败:{}".format(str(e)))returnreturn dfFileif __name__ == '__main__':readPath = "C:/Users/lenovo/Desktop/lut.xls" # 数据文件的地址和文件名dfFile = readDataFile(readPath) # 调用读取文件子程序print(type(dfFile)) # 查看 dfFile 数据类型print(dfFile.shape) # 查看 dfFile 形状(行数,列数)print(dfFile.head()) # 显示 dfFile 前 5 行数据代码讲解
1、readPath[-4:]是对字符串切片,选取了倒数4位,也就是.以及.后面的文件格式。
2、read_csv是pd下读取.csv格式文件的函数。主要包括三个属性(路径,header,sep),路径是读取文件存放的路径,
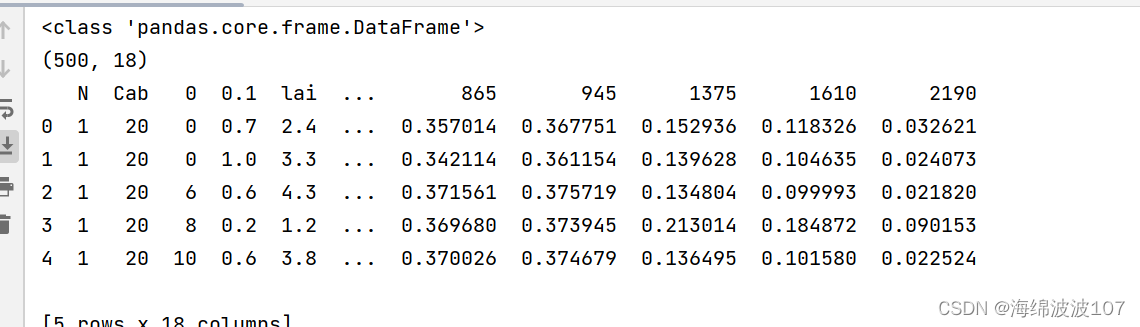
3、header=0的含义,下图为源文件,
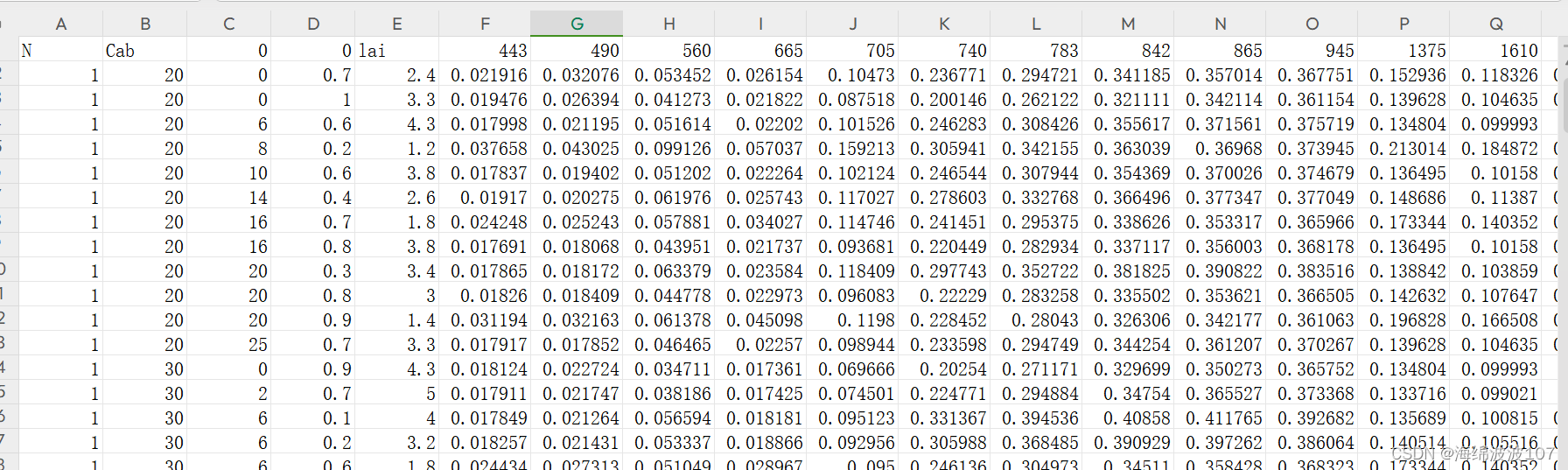
当设置header=0时表示首行为标题行,我们打印读取结果的前五行数据会发现自动读取了标题
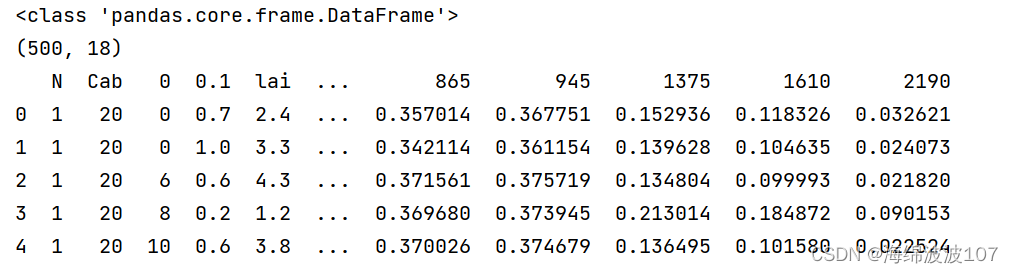
当设置header=1时,将第一行数据行作为读取数据的标题行,因此整体数据会少了一行,从500变为499
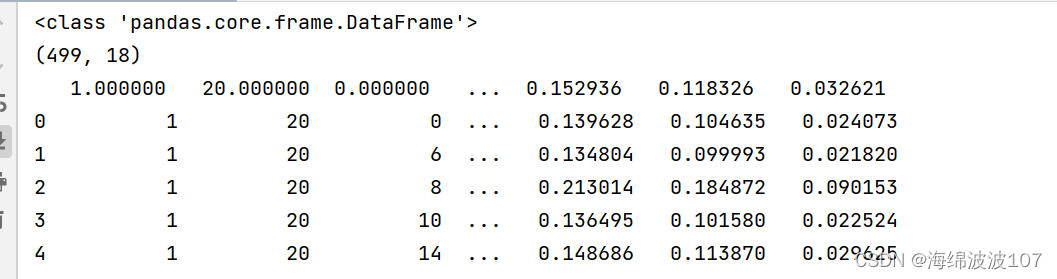
当header不设置时,默认第0行为标题行
当设置为header=None时,会认为原有数据没有标题行,并自动生成一个0开始的标题行。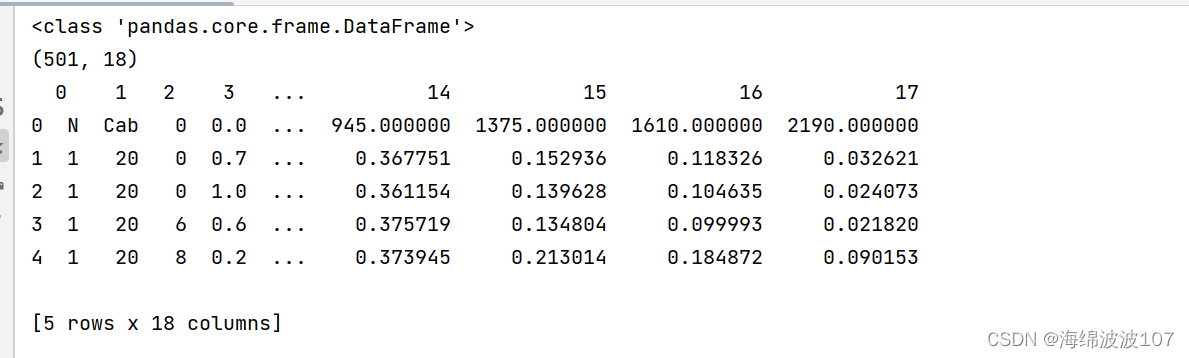
4、try 和except是捕获任何异常,并在发生异常时打印出错误信息。这样做是为了帮助调试和排除问题。你的代码在捕获异常后使用print函数将错误信息输出到控制台。这样,如果打开数据文件时出现任何问题,你都可以看到错误信息以便进行分析和修复。
5、return dfFile 表示该函数返回一个dataframe对象,变量名为dfFile,下面就可以对dtFile进行操作了
6、type(dfFile)能够查看dtFile的类型,dfFile.shape可以查看dtFile的行列数,dfFile.head()可以查看dtFile的前5行