🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
🦄 个人主页——🎐开着拖拉机回家_Linux,Java基础学习,大数据运维-CSDN博客 🎐✨🍁
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
一、DataNode简介
二、DataNode工作机制
三、DataNode文件结构
四、HDFS中的chunk、packet和block
五、心跳机制
一、DataNode简介
Datanode是HDFS文件系统的工作节点,它们根据客户端或者是namenode的调度进行存储和检索数据,并且定期向namenode发送它们所存储的块(block)的列表。
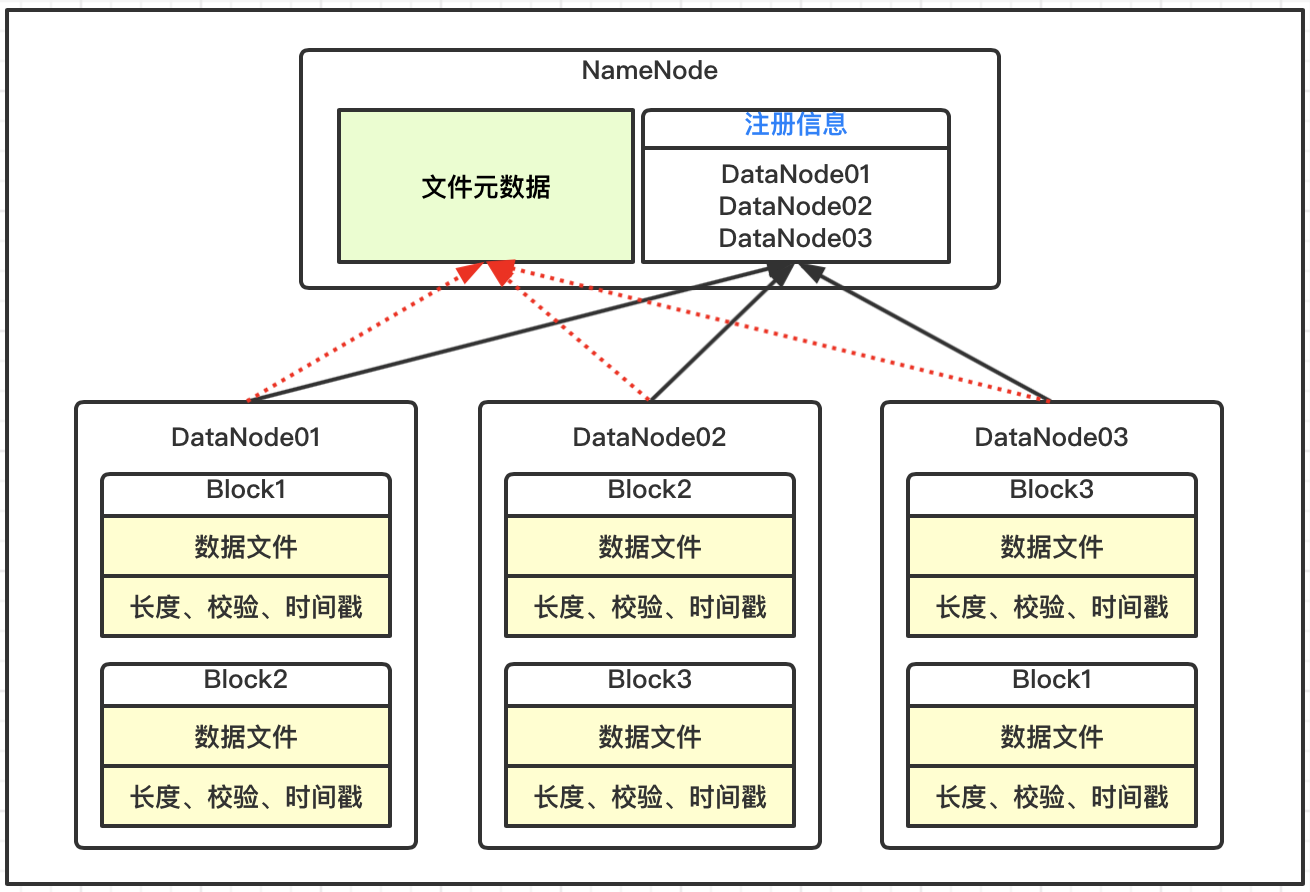
NameNode上并不永久保存哪个DataNode上有哪些数据块的信息,而是通过DataNode启动时的上报来更新NameNode上的映射表。
- 根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送所存储的块(block)的列表
- 数据块在DataNode进程所在的节点上以文件的形式存储在本地磁盘上
- 一个是数据本身
- 一个是元数据(数据块的长度,块数据的校验和,以及时间戳)
3.维护blockid与DataNode之间的映射信息(元信息)
二、DataNode工作机制
DataNode启动时,每个datanode对本地磁盘进行扫描,将本DataNode上保存的block信息汇报给namenode, NameNode在接收到的block信息以及该block所在的datanode信息等保存在内存中。
DataNode启动后向NameNode注册,通过后周期性(1小时)的向NameNode上报所有的块信息。在测试环境我们重启NameNode 可以发现 当元数据上千万时重启花费的时间就会比较久,这是因为NameNode 要将所有的Block 的信息加载到内存中。
- 通过向NameNode发送心跳保持与其联系(3秒一次),心跳返回结果带有NN的命令返回的命令为:如块的复制,删除某个数据块, 节点退役block 的移动…..
- 如果10分钟没有收到DataNode的心跳,则认为其已经lost,并copy其上的block到其它DataNode
- DN在其文件创建后三周进行验证其checkSum的值是否和文件创建时的checkSum值一致
三、DataNode文件结构
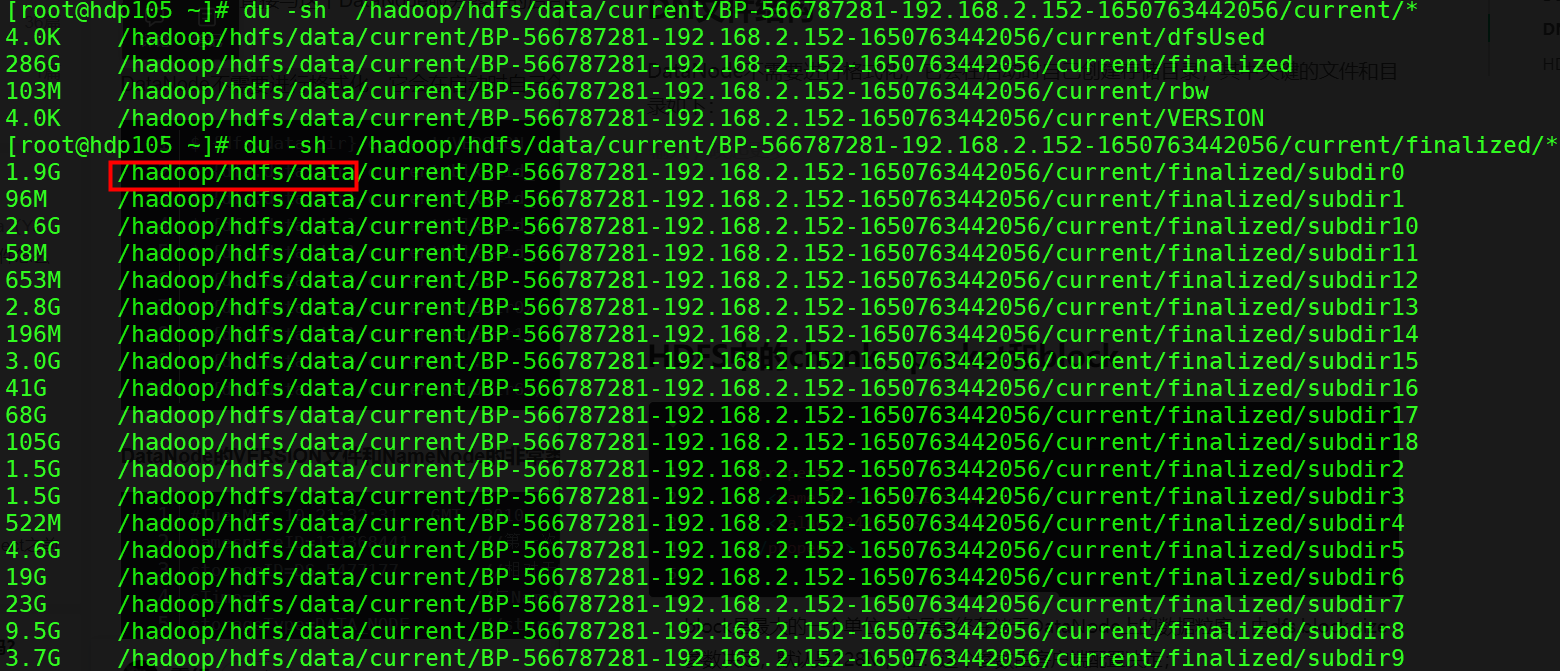
DataNode不需要进行格式化,它会在启动时自己创建存储目录,其中关键的文件和目录如下图, " /hadoop/hdfs/data" 为DataNode directories。
当目录中存储的块数量增加到一定规模时,DataNode会创建一个新的目录,用于保存新的块及元数据。当目录中的块数量达到一定数据时(可由dfs.DataNode.numblocks属性值确定)时,便会新建一个子目录subdir*,这样就会形成一个更宽的文件树结构,避免了由于存储大量数据块而导致目录很深,使检索性能免受影响。通过这样的措施,数据节点可以确保每个目录中的文件块数是可控的,也避免了一个目录中存在过多文件。可以看如下两个截图:
DataNode中current目录下的其他文件都有blk_xxxx前缀,它有两种类型:
(1)HDFS中的文件块本身,存储的是原始文件内容;
(2)块的元数据信息(使用.meta后缀标识)。一个文件块由存储的原始文件字节组成,元数据文件由一个包含版本和类型信息的头文件和一系列的区域校验和组成。
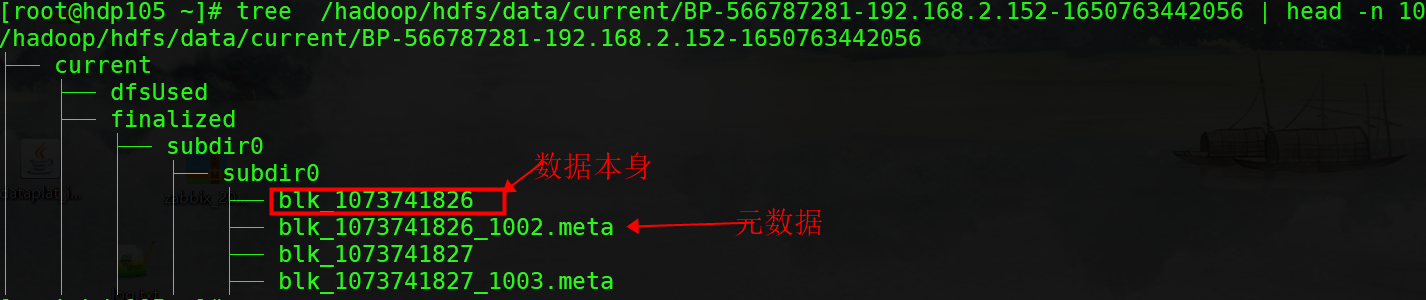
in_user.lock:表示当前目录已经被使用,实现了一种锁机制,这样DataNode可以独自使用该目录;

DataNode的VERSION文件和NameNode的非常类似,内容如下:
# 目录版本号
[root@hdp105 ~]# cat /hadoop/hdfs/data/current/VERSION
#Wed Aug 09 16:35:41 CST 2023
storageID=DS-162f7349-32c8-4b4b-b99b-95d9e18d93c0
clusterID=CID-53b4def4-a7f9-4c80-812c-6d70f214fa9a
cTime=0
datanodeUuid=73a1565b-dc67-4292-a605-6c5f45f68a2a
storageType=DATA_NODE
layoutVersion=-57
[root@hdp105 ~]#
具体解释
- storageID: 存储 id 号
- clusterID : 集群 id, 全局唯一
- cTime: 属性标记了 datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0; 但是在文件系统升级之后,该值会更新到新的时间戳。
- datanodeUuid: datanode 的唯一识别码
- storageType: 存储类型
- layoutVersion :是一个负整数。 通常只有 HDFS 增加新特性时才会更新这个版本号。
查看该数据块的版本号 /hadoop/hdfs/data/current/BP-566787281-192.168.2.152-1650763442056/current/VERSION :
[root@hdp105 ~]# cat /hadoop/hdfs/data/current/BP-566787281-192.168.2.152-1650763442056/current/VERSION
#Wed Aug 09 16:35:41 CST 2023
namespaceID=1378550782 # 第一个连接NameNode 从中获取
cTime=1650763442056 # 与NameNode 值一样 ,属性标记了 datanode 存储系统的创建时间
blockpoolID=BP-566787281-192.168.2.152-1650763442056
layoutVersion=-57 # 一个负整数具体解释:
- namespaceID: 是 datanode 首次访问 namenode 的时候从 namenode 处获取的storageID 对每个 datanode 来说是唯一的(但对于单个 datanode 中所有存储目录来说则是相同的),namenode 可用这个属性来区分不同 datanode。
- cTime :属性标记了 datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0; 但是在文件系统升级之后,该值会更新到新的时间戳。
- blockpoolID: 一个 block pool id 标识一个 block pool,并且是跨集群的全局唯一。当一个新的 Namespace 被创建的时候(format 过程的一部分)会创建并持久化一个唯一 ID。在创建过程构建全局唯一的 BlockPoolID 比人为的配置更可靠一些。NN 将 BlockPoolID 持久化到磁盘中,在后续的启动过程中,会再次 load 并使用。
- layoutVersion: 是一个负整数。 通常只有 HDFS 增加新特性时才会更新这个版本号。
四、HDFS中的chunk、packet和block
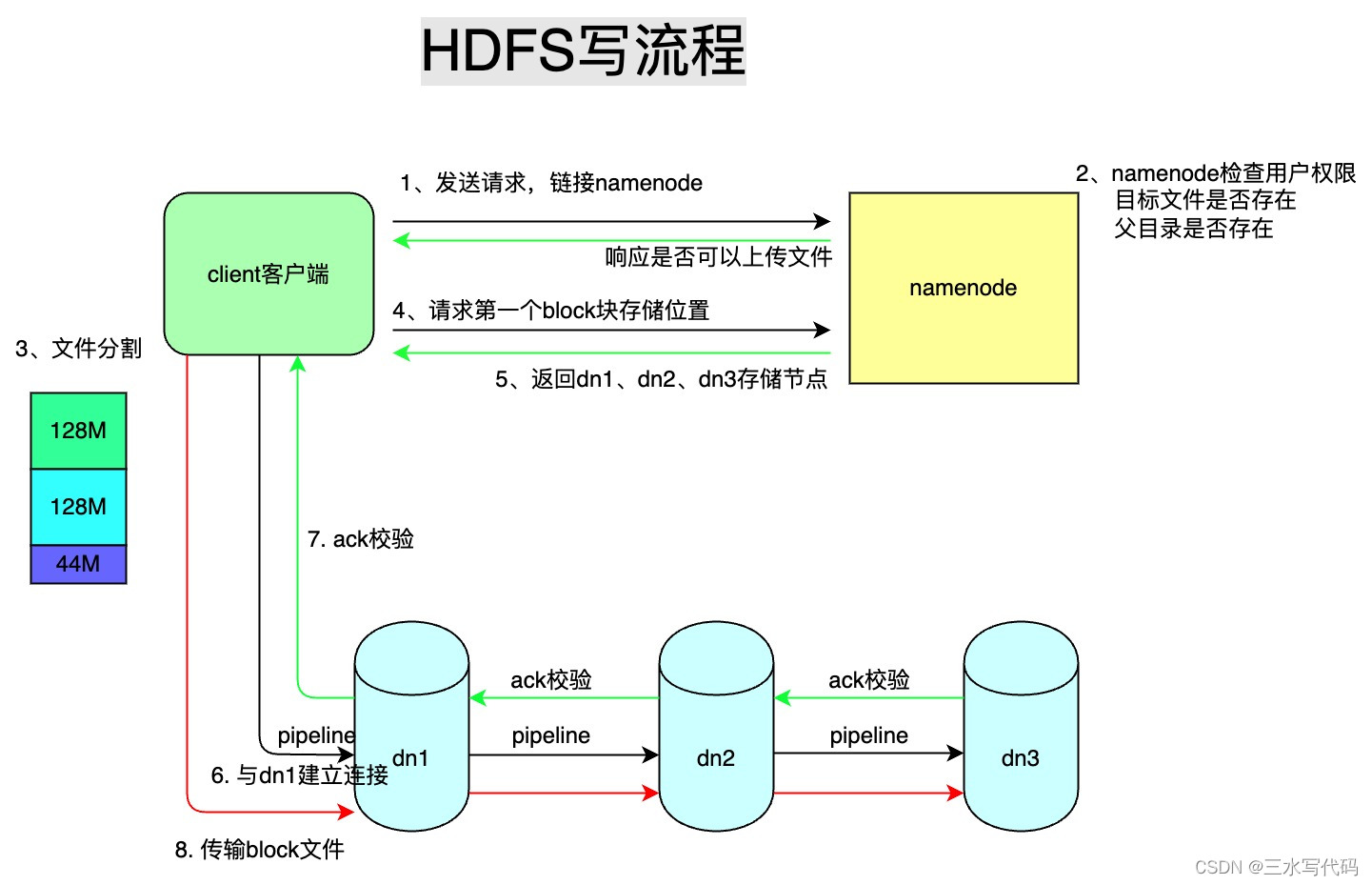
HDFS文件写入流程如下图:
hdfs-site.xml 中 block 大小默认配置
<property><name>dfs.blocksize</name><value>134217728</value></property>
- block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,默认是128M;注:这个参数由客户端配置决定;
- packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
- chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;
注意:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
2023-08-26 16:50:24 DEBUG [main] (DFSOutputStream.java:472) - WriteChunk allocating new packet seqno=80, src=/winner/hadoop/winipva/config/temp/siteinfo/000000, packetSize=65016, chunksPerPacket=126, bytesCurBlock=5160960, DFSOutputStream:blk_1074938158_1198973
2023-08-26 16:50:24 DEBUG [main] (DFSOutputStream.java:485) - enqueue full packet seqno: 80 offsetInBlock: 5160960 lastPacketInBlock: false lastByteOffsetInBlock: 5225472, src=/winner/hadoop/winipva/config/temp/siteinfo/000000, bytesCurBlock=5225472, blockSize=134217728, appendChunk=false, blk_1074938158_1198973
2023-08-26 16:50:24 DEBUG [main] (DataStreamer.java:1953) - Queued packet seqno: 80 offsetInBlock: 5160960 lastPacketInBlock: false lastByteOffsetInBlock: 5225472, blk_1074938158_1198973
2023-08-26 16:50:24 DEBUG [main] (DFSOutputStream.java:407) - computePacketChunkSize: src=/winner/hadoop/winipva/config/temp/siteinfo/000000, chunkSize=516, chunksPerPacket=126, packetSize=65016
2023-08-26 16:50:24 DEBUG [main] (DFSOutputStream.java:472) - WriteChunk allocating new packet seqno=81, src=/winner/hadoop/winipva/config/temp/siteinfo/000000, packetSize=65016, chunksPerPacket=126, bytesCurBlock=5225472, DFSOutputStream:blk_1074938158_1198973
2023-08-26 16:50:24 DEBUG [main] (DFSOutputStream.java:485) - enqueue full packet seqno: 81 offsetInBlock: 5225472 lastPacketInBlock: false lastByteOffsetInBlock: 5289984, src=/winner/hadoop/winipva/config/temp/siteinfo/000000, bytesCurBlock=5289984, blockSize=134217728, appendChunk=false, blk_1074938158_1198973
2023-08-26 16:50:24 DEBUG [DataStreamer for file /winner/hadoop/winipva/config/temp/siteinfo/000000 block BP-566787281-192.168.2.152-1650763442056:blk_1074938158_1198973] (DataStreamer.java:627) - nodes [DatanodeInfoWithStorage[192.168.2.154:1019,DS-162f7349-32c8-4b4b-b99b-95d9e18d93c0,DISK], DatanodeInfoWithStorage[192.168.2.152:1019,DS-ff3d5e8b-c345-4ef6-878d-a2b0a6bf30bb,DISK], DatanodeInfoWithStorage[192.168.2.153:1019,DS-0c73463c-22db-49af-82d0-c8b2c010ff00,DISK]] storageTypes [DISK, DISK, DISK] storageIDs [DS-162f7349-32c8-4b4b-b99b-95d9e18d93c0, DS-ff3d5e8b-c345-4ef6-878d-a2b0a6bf30bb, DS-0c73463c-22db-49af-82d0-c8b2c010ff00]
2023-08-26 16:50:24 DEBUG [DataStreamer for file /winner/hadoop/winipva/config/temp/siteinfo/000000 block BP-566787281-192.168.2.152-1650763442056:blk_1074938158_1198973] (DataStreamer.java:769) - blk_1074938158_1198973 sending packet seqno: 0 offsetInBlock: 0 lastPacketInBlock: false lastByteOffsetInBlock: 64512
2023-08-26 16:50:24 DEBUG [DataStreamer for file /winner/hadoop/winipva/config/temp/siteinfo/000000 block BP-566787281-192.168.2.152-1650763442056:blk_1074938158_1198973] (DataStreamer.java:712) - stage=DATA_STREAMING, blk_1074938158_1198973
2023-08-26 16:50:24 DEBUG [DataStreamer for file /winner/hadoop/winipva/config/temp/siteinfo/000000 block BP-566787281-192.168.2.152-1650763442056:blk_1074938158_1198973] (DataStreamer.java:769) - blk_1074938158_1198973 sending packet seqno: 1 offsetInBlock: 64512 lastPacketInBlock: false lastByteOffsetInBlock: 129024
2023-08-26 16:50:24 DEBUG [DataStreamer for file /winner/hadoop/winipva/config/temp/siteinfo/000000 block BP-566787281-192.168.2.152-1650763442056:blk_1074938158_1198973] (DataStreamer.java:712) - stage=DATA_STREAMING, blk_1074938158_1198973
2023-08-26 16:50:24 DEBUG [DataStreamer for file /winner/hadoop/winipva/config/temp/siteinfo/000000 block BP-566787281-192.168.2.152-1650763442056:blk_1074938158_1198973] (DataStreamer.java:769) - blk_1074938158_1198973 sending packet seqno: 2 offsetInBlock: 129024 lastPacketInBlock: false lastByteOffsetInBlock: 193536
2023-08-26 16:50:24 DEBUG [DataStreamer for file /winner/hadoop/winipva/config/temp/siteinfo/000000 block BP-566787281-192.168.2.152-1650763442056:blk_1074938158_1198973] (DataStreamer.java:712) - stage=DATA_STREAMING, blk_1074938158_1198973
通过将Block切分为多个chunk,每 chunksPerPacket个chunk 组合成一个packet进行发送,并且packet的缓冲区大小采用冗余分配的方式,会为数据块内容预留空间,以防止数据块内容变化的时候重新计算校验和。
如上put代码打印的DEBUG日志:
chunkSize=516, chunksPerPacket=126, packetSize=65016 , 516 * 126 = 65016
五、心跳机制
DataNdde每间隔3 秒 向NameNode传递当前的状态信息(正常运行还是异常),NameNode每次接到信息后,就会返回要求DataNode所需要做的工作,如复制块数居到另一台机器,或删除某个数据块。如果超过10分钟30秒没有收到某个DataNode的心跳,则认为该节点不可用。
<property><name>dfs.namenode.heartbeat.recheck-interval</name><value>300000</value></property>
<property><name>dfs-heartbeat.interval</name><value>3</value>
</property>
DataNode每隔三秒汇报给namenode
判断DataNode超时的时间公式:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认的大小为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒


参考文档:Hadoop之DataNode_麦兜仔的博客-CSDN博客