自然语言处理 微调大模型ChatGLM-6B
- 1、GLM设计原理
- 2、大模型微调原理
- 1、P-tuning v2方案
- 2、LORA方案
1、GLM设计原理
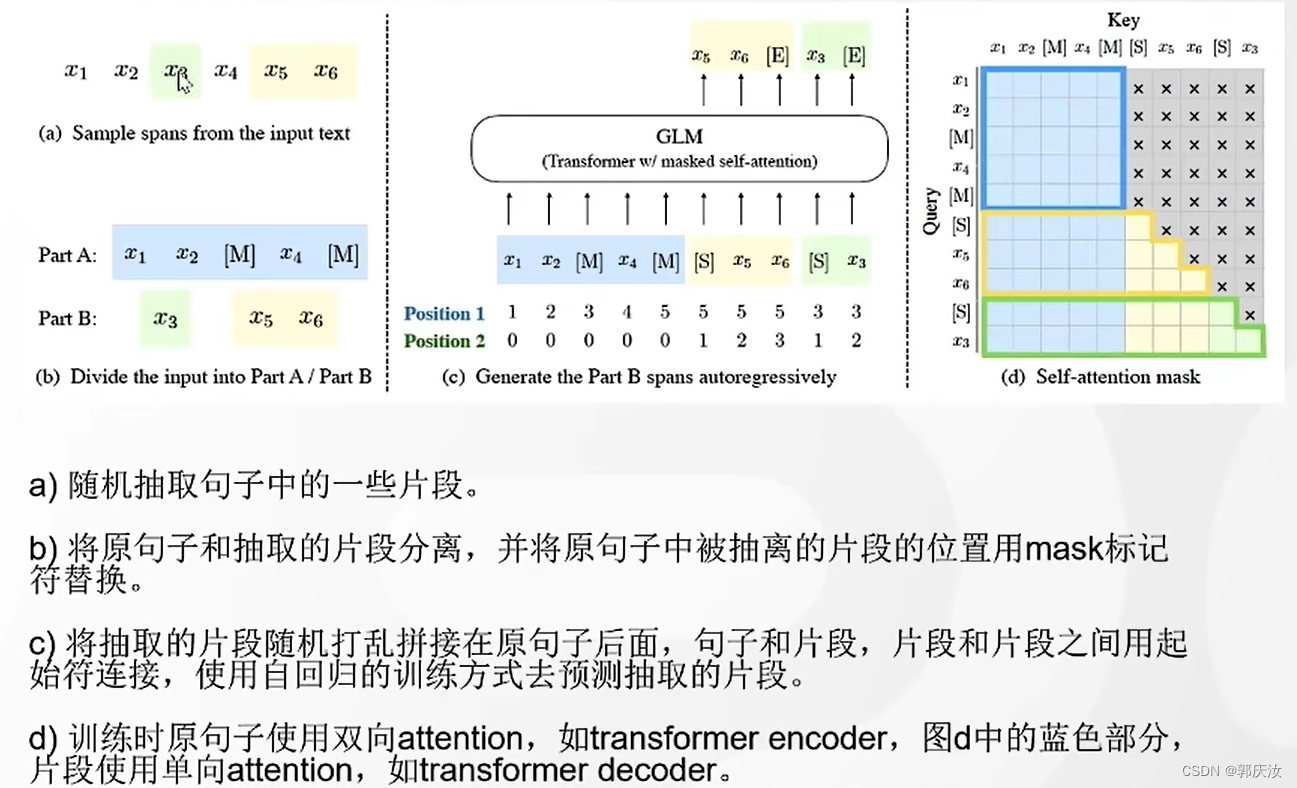
bert的主要任务是随机的去除掉某个单词,使用上下文将其预测出来(相当于完形填空任务);
GPT的主要任务是根据前面一句话,预测下面的内容;
GLM结合了bert的强大双向注意力与gpt的强大生成能力两种能力,被nask的地方使用单向注意力,未被mask的地方使用双向注意力

预测对应关系如下,即由当前词预测下一词

2、大模型微调原理
1、P-tuning v2方案
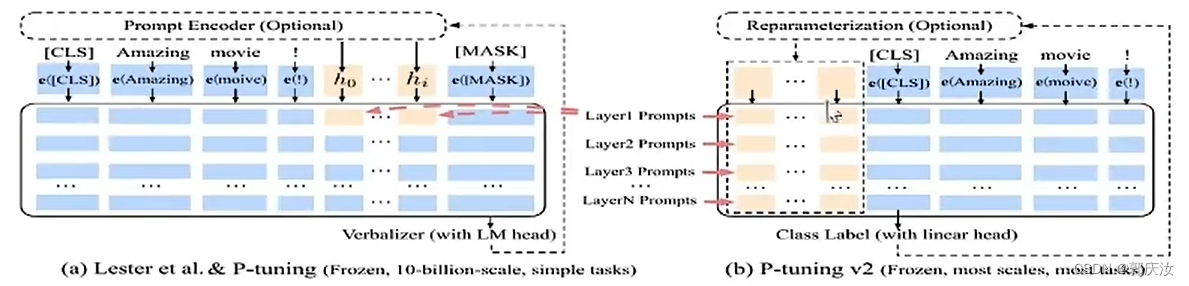
原理:由于大模型数据量庞大,如果对模型进行全量微调,需要的算力与数据量不好满足,为了降低要求,传统方法是只对其部分参数进行调整,冻结大部分层;P-tuning 的方案则是并行一个小网络,与大网络相连,原先大网络部分进行冻结,在反向传播时只更新前面小网络的参数,该方法的重要参数就是所加P-tuing大模型前面补丁模型的长度
PRE_SEQ_LEN=128 # gqr:P-tuing重要参数,即大模型前面补丁模型的长度
LR=2e-2 # gqr:学习率CUDA_VISIBLE_DEVICES=0 python3 main.py \--do_train \ # gqr:是否训练--train_file AdvertiseGen/train.json \ # gqr:训练数据集--validation_file AdvertiseGen/dev.json \ # gqr:验证数据集--prompt_column content \ # gqr:数据集键值--response_column summary \ # gqr:数据集键值--overwrite_cache \ # gqr:每次训练是否重新生成数据集cache--model_name_or_path THUDM/chatglm-6b \--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ # gqr:训练得到模型路径--overwrite_output_dir \ # gqr:是否覆盖--max_source_length 64 \ # gqr:最大输入长度--max_target_length 64 \ # gqr:最大输出长度--per_device_train_batch_size 1 \ # gqr:平均每张卡用几个样本训练--per_device_eval_batch_size 1 \# gqr:平均每张卡用几个样本测试--gradient_accumulation_steps 16 \ # gqr:累计多少部更新一下参数--predict_with_generate \ # gqr:是否将预测的测试集答案写出--max_steps 3000 \ # gqr:训练步数--logging_steps 10 \ # gqr:每多少步打印日志--save_steps 1000 \ # gqr:每多少步不存一次模型--learning_rate $LR \ # 学习率--pre_seq_len $PRE_SEQ_LEN \ # P-tuing模型的长度--quantization_bit 4 # 模型量化方式,int42、LORA方案
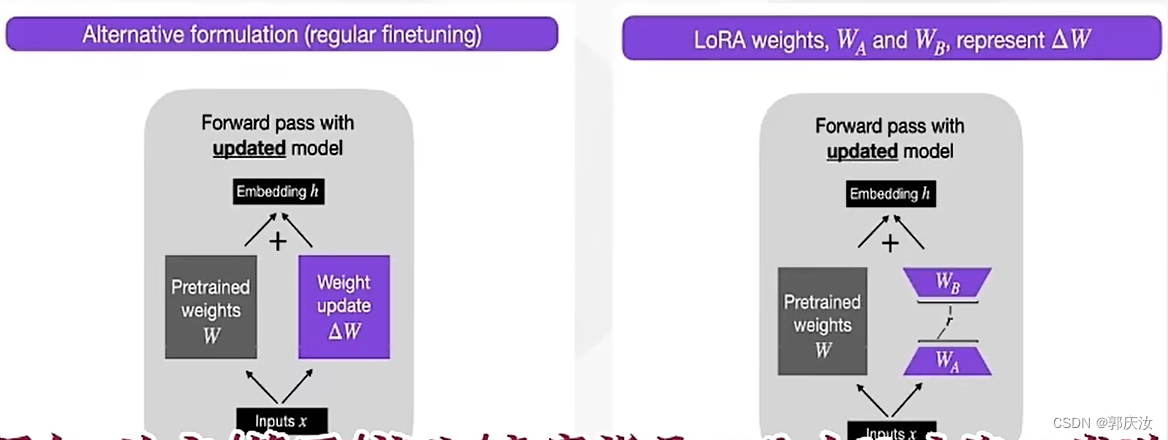
原理:给大模型结构并行一个更小模型,大模型部分参数不反向传播,仅对小模型进行反向传播更新参数;后期发现,可以将小模型部分分解成更小的模块,可以降低大量参数。