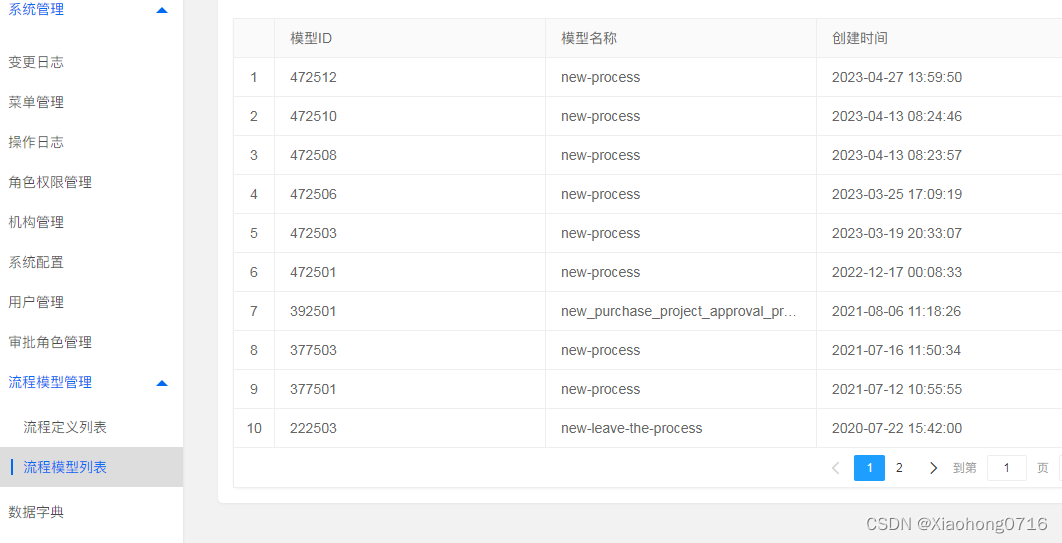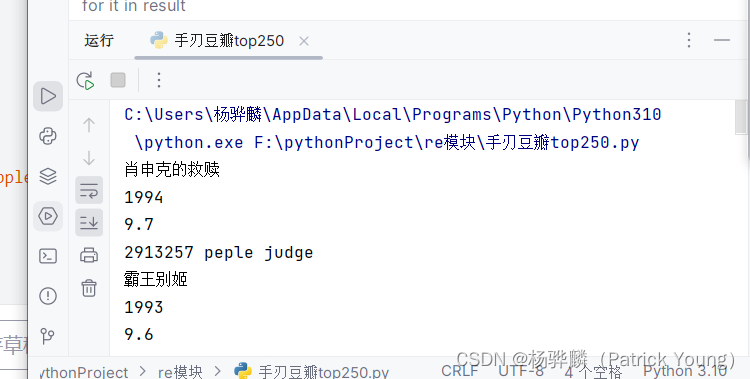
#拿到页面面源代码 request
#通过re来提取想要的有效信息 re
import requests
import re
url="https://movie.douban.com/top250"headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"}resp=requests.get(url,headers=headers)page_content=resp.text#解析数据
obj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'r'.*?<p class="">.*?<br>.*?(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?<span>(?P<people>.*?)人',re.S)
result=obj.finditer(page_content)
for it in result:print(it.group("name"))print(it.group("year").strip())print(it.group("score"))print(it.group("people")+" peple judge")#上述操作在于爬取文件
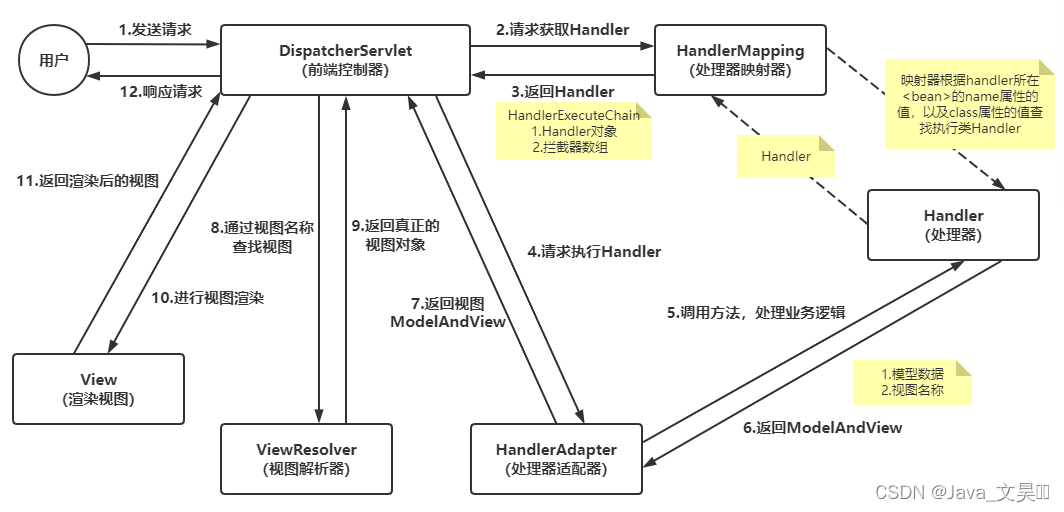
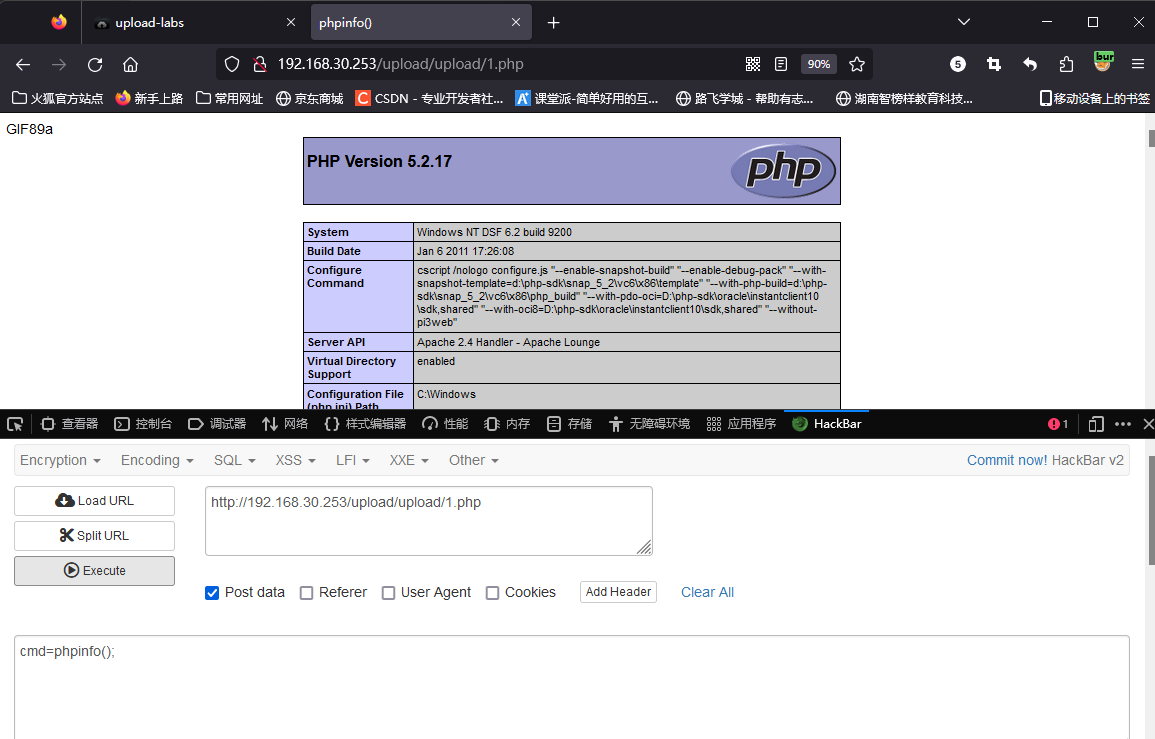
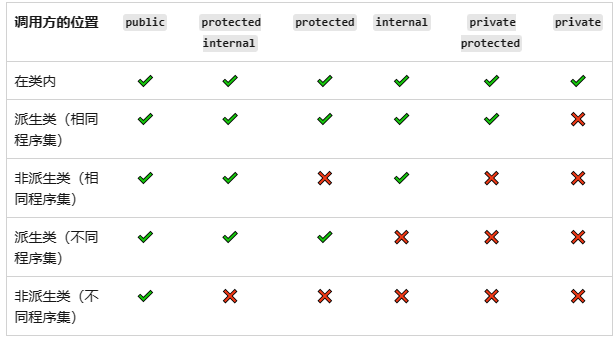

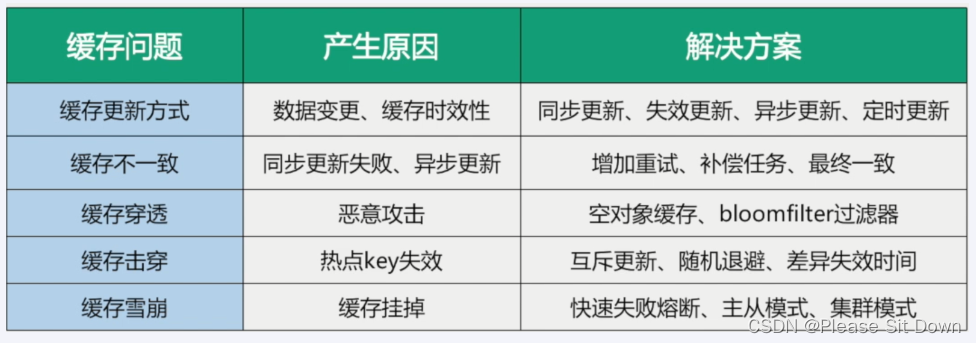
![【java】【项目实战】[外卖九]项目优化(缓存)](https://img-blog.csdnimg.cn/3dd4b4f783c043d0b9a6091f1b91eeb1.png)