本文主要介绍在S4 HANA OP中明确税金汇差科目(OBYY)相关设置。具体请参照如下内容:
1. 明确税金汇差科目(OBYY)


以上配置点定义了在外币挂账时,当凭证抬头汇率和税金行项目汇率不一致时,造成的差异金额进入哪个科目。此类情况只发生在FB60/FB65/FB70/FB75/MRO。
通常税金行项目的汇率和凭证抬头汇率相同,但是如果手工修改了税金的外币金额和本币金额导致税金行项目的汇率和凭证抬头汇率不同,那么税金行项目汇差会进入此处配置的科目。
案例:





因此税金行项目的汇率和凭证抬头汇率不同,会产生单独的税金汇差,后续记账,凭证如下:
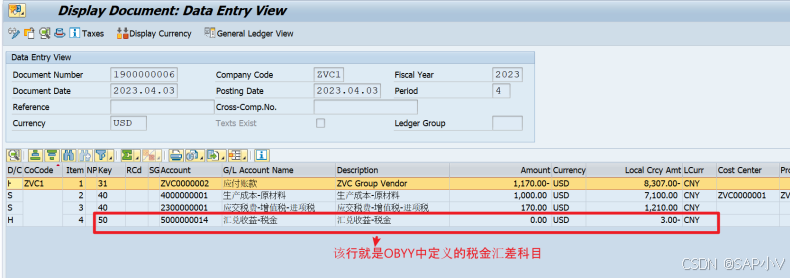






![93,【1】buuctf web [网鼎杯 2020 朱雀组]phpweb](https://i-blog.csdnimg.cn/direct/fb79d26bc7ac41ae8b8d4b901ae51988.png)