关注:CodingTechWork
CompletableFuture 概述
介绍
CompletableFuture是 Java 8 引入的一个非常强大的类,属于 java.util.concurrent 包。它是用于异步编程的一个工具,可以帮助我们更方便地处理并发任务。与传统的线程池或 Future 对比,CompletableFuture 提供了更多灵活性和组合功能,使得异步编程更加简单和易于维护。
CompletableFuture主要用于异步操作和组合多个异步任务。它可以通过执行非阻塞的操作来避免阻塞主线程,从而提高程序的性能和响应速度。
CompletableFuture实现了 Future 和 CompletionStage 接口。
优势
相比传统的 Future 接口,具有以下核心优势:
- 支持非阻塞的异步操作
- 提供链式调用和组合操作的能力
- 内置完善的异常处理机制
- 支持函数式编程风格
与传统 Future 对比
| 特性 | Future | CompletableFuture |
|---|---|---|
| 结果获取 | 阻塞 get() 方法 | 支持回调通知 |
| 链式调用 | 不支持 | 支持多级流水线处理 |
| 异常处理 | 需要 try-catch | 内置异常传播机制 |
| 组合操作 | 手动实现 | 提供多种组合方法 |
| 手动完成 | 不支持 | 支持 complete() 方法 |
核心方法
supplyAsync()
用于执行一个异步任务并返回一个结果。它接受一个 Supplier,并在后台线程执行该任务。
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {return 42;
});
runAsync()
用于执行一个异步任务,但不返回结果。它接受一个Runnable,并在后台线程执行该任务。
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {System.out.println("Task executed");
});
thenApply()
用于将前一个计算的结果转换为另一个结果。它接受一个Function,该函数作用于先前计算的结果,并返回一个新的CompletableFuture。
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> 5).thenApply(result -> result * 2);
thenAccept()
用于处理前一个计算结果并返回Void。它接受一个Consumer,用于对先前的结果执行操作。
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> 5).thenAccept(result -> System.out.println(result));
thenCombine()
用于将两个CompletableFuture的结果结合成一个新的结果。它接受两个CompletableFuture和一个BiFunction。
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(() -> 5);
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(() -> 10);CompletableFuture<Integer> combined = future1.thenCombine(future2, (result1, result2) -> result1 + result2);
thenCompose()
用于将两个异步操作串联起来,第二个任务依赖第一个任务的结果。它接受一个Function,返回一个新的CompletableFuture。
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> 5).thenCompose(result -> CompletableFuture.supplyAsync(() -> result * 2));
allOf()
用于组合多个CompletableFuture,并等待它们全部完成。返回一个新的 CompletableFuture,它完成时表示所有的CompletableFuture都已完成。
CompletableFuture<Void> future1 = CompletableFuture.supplyAsync(() -> 5);
CompletableFuture<Void> future2 = CompletableFuture.supplyAsync(() -> 10);CompletableFuture<Void> allOf = CompletableFuture.allOf(future1, future2);
anyOf()
用于组合多个CompletableFuture,并等待任意一个任务完成。返回一个新的 CompletableFuture,该CompletableFuture完成时表示至少有一个任务已完成。
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(() -> 5);
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(() -> 10);CompletableFuture<Object> anyOf = CompletableFuture.anyOf(future1, future2);
exceptionally()
用于在异步任务执行过程中发生异常时处理异常。它接受一个Function,如果任务执行失败(抛出异常),则返回一个备用值。
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {if (true) throw new RuntimeException("Error");return 5;})// 处理异常,返回-1.exceptionally(ex -> -1);
whenComplete()
用于在任务完成后进行额外操作,不论任务是正常完成还是异常完成。它接受一个 BiConsumer,用于处理结果和异常。
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> 5).whenComplete((result, ex) -> {if (ex == null) {System.out.println("Completed with result: " + result);} else {System.out.println("Completed with exception: " + ex.getMessage());}});
supplyAsync()和runAsync() 区别
CompletableFuture.supplyAsync() 和 CompletableFuture.runAsync() 都是用来异步执行任务的,但它们之间有一些关键区别,主要体现在是否返回结果以及如何处理任务:
返回值
supplyAsync()功能:该方法接受一个Supplier函数,Supplier是一个能够返回结果的函数。它会异步执行任务并返回一个CompletableFuture<T>,这个CompletableFuture可以通过get()等方法获取任务的返回值。supplyAsync()适用场景:当你需要执行一个任务,并且希望获取这个任务的结果时,使用supplyAsync()。runAsync()功能:该方法接受一个Runnable函数,Runnable是一个没有返回值的任务。它会异步执行任务,但不会返回任何结果,因此返回的是一个CompletableFuture<Void>,意味着你只能知道任务是否完成,但无法直接获取任务的结果。runAsync()适用场景:当你只需要执行任务,但不关心返回结果时,使用runAsync()。
任务执行
supplyAsync():异步任务执行后会返回一个值,通常使用 thenApply()、thenAccept() 等方法来处理返回值。runAsync():执行的是没有返回值的任务,通常用 thenRun() 来处理任务完成后的操作。
使用场景
supplyAsync():适用于有返回值的任务,例如你需要异步计算某个结果。runAsync():适用于没有返回值的任务,例如日志记录、状态更新等。
技术原理
创建异步任务
// 使用默认 ForkJoinPool
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> "Result");// 指定自定义线程池
ExecutorService executor = Executors.newFixedThreadPool(2);
CompletableFuture<String> cf2 = CompletableFuture.supplyAsync(() -> {// 业务逻辑return "Custom Result";
}, executor);
结果处理
同步回调
// thenApply: 同步转换结果
cf.thenApply(s -> s + " processed").thenAccept(System.out::println);// thenAccept: 同步消费结果
cf.thenAccept(result -> {System.out.println("Received: " + result);
});
异步回调
// thenApplyAsync: 异步转换
cf.thenApplyAsync(s -> {// 在 ForkJoinPool 异步执行return s.toUpperCase();
});// 指定自定义线程池
cf.thenAcceptAsync(result -> {System.out.println("Async processing");
}, executor);
组合操作
串行组合
// 查询用户信息,然后根据用户ID查询订单信息(串行执行)
CompletableFuture<String> cf = queryUserInfo()// 使用 thenCompose 实现串行组合.thenCompose(user -> queryOrder(user.getId()));
并行组合
// 并行查询服务A和服务B
// 查询服务A
CompletableFuture<String> cf1 = queryServiceA();
// 查询服务B
CompletableFuture<String> cf2 = queryServiceB(); // 合并两个结果(并行执行,结果合并)
CompletableFuture<String> combined = cf1// 使用 thenCombine 合并两个任务的结果.thenCombine(cf2, (res1, res2) -> res1 + " & " + res2); // 任意一个完成即返回(并行执行,取最先完成的结果)
// 使用 anyOf 实现快速返回
CompletableFuture<Object> anyOf = CompletableFuture.anyOf(cf1, cf2);
异常处理
// 异常处理:捕获异常并返回默认值
cf.exceptionally(ex -> {// 打印异常信息System.err.println("Error: " + ex.getMessage()); // 返回默认值return "default value";
});// 异常处理:捕获异常并返回 fallback 值
cf.handle((result, ex) -> {// 如果有异常if (ex != null) { // 返回 fallback 值return "fallback"; }// 否则返回正常结果return result;
});
超时控制
// 超时控制:如果任务在指定时间内未完成,返回默认值
// 1秒后未完成则返回 "default"
cf.completeOnTimeout("default", 1, TimeUnit.SECONDS);
典型应用场景
并行任务处理
// 并行处理多个请求
List<CompletableFuture<String>> futures = requests.stream().map(request -> // 对每个请求异步处理CompletableFuture.supplyAsync(() -> process(request), executor)) // 收集所有任务.collect(Collectors.toList()); // 等待所有任务完成
CompletableFuture<Void> allDone = CompletableFuture// 使用 allOf 等待所有任务完成.allOf(futures.toArray(new CompletableFuture[0]));
服务调用编排
// 服务调用编排:依次执行多个异步任务
CompletableFuture<Order> orderFuture = // 获取用户信息getUserProfile() // 验证地址.thenCompose(user -> validateAddress(user)) // 创建订单.thenCompose(address -> createOrder(address)) // 异常时创建备用订单.exceptionally(ex -> createFallbackOrder());
异步结果聚合
// 异步结果聚合:合并两个异步任务的结果
CompletableFuture<Integer> total = // 任务1:返回10CompletableFuture.supplyAsync(() -> 10) // 任务2:返回20,合并结果为30.thenCombine(CompletableFuture.supplyAsync(() -> 20), Integer::sum);
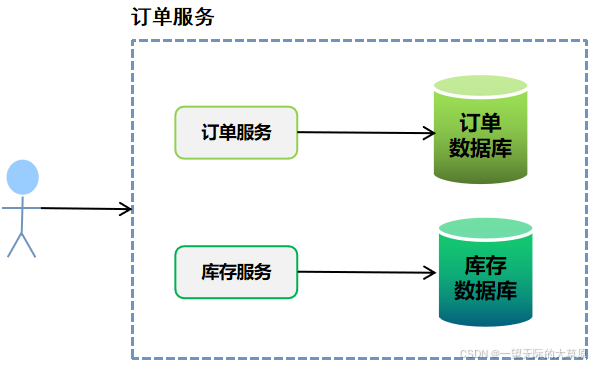
demo:电商订单处理
场景需求
- 并行查询用户信息和商品库存
- 验证地址有效性
- 组合结果创建订单
- 记录操作日志
实现代码
import java.util.concurrent.*;public class OrderService {private final ExecutorService executorService;// 构造函数接受线程池大小参数public OrderService(int poolSize) {// 创建一个自定义线程池,大小为 poolSizethis.executorService = Executors.newFixedThreadPool(poolSize);System.out.println("Thread pool initialized with size: " + poolSize);}// 线程池大小配置方法public void setThreadPoolSize(int poolSize) {// 关闭现有线程池并创建一个新的线程池shutdown(); // 关闭旧线程池this.executorService = Executors.newFixedThreadPool(poolSize); // 创建新的线程池System.out.println("Thread pool resized to: " + poolSize);}// 获取当前线程池大小public int getThreadPoolSize() {if (executorService instanceof ThreadPoolExecutor) {return ((ThreadPoolExecutor) executorService).getCorePoolSize();}return -1; // 如果没有获取到线程池大小,则返回 -1}public CompletableFuture<OrderResult> createOrderAsync(OrderRequest request) {// 并行查询用户信息和库存信息CompletableFuture<UserInfo> userFuture = queryUserAsync(request.getUserId());CompletableFuture<Inventory> inventoryFuture = queryInventoryAsync(request.getSkuId());// 使用 thenCombine 合并两个异步结果return userFuture.thenCombine(inventoryFuture, (user, inventory) -> {// 验证用户地址validateAddress(user.getAddress());// 检查库存是否足够checkInventory(inventory);// 根据用户信息、库存信息和订单请求生成订单return generateOrder(user, inventory, request);})// 使用 thenCompose 对生成的订单进行进一步处理.thenCompose(order -> {// 异步保存订单return saveOrderAsync(order)// 保存成功后,发送通知.thenApply(savedOrder -> sendNotification(savedOrder));})// 处理最终结果,或者处理异常.handle((result, ex) -> {// 如果出现异常,记录错误并返回失败的结果if (ex != null) {log.error("Order failed", ex);return OrderResult.failure(ex.getMessage());}// 如果成功,返回成功的结果return OrderResult.success(result);});}// 异步查询用户信息,使用自定义线程池private CompletableFuture<UserInfo> queryUserAsync(String userId) {return CompletableFuture.supplyAsync(() -> userService.getUser(userId), executorService);}// 异步查询库存信息,使用自定义线程池private CompletableFuture<Inventory> queryInventoryAsync(String skuId) {return CompletableFuture.supplyAsync(() -> inventoryService.getStock(skuId), executorService);}// 验证用户地址是否合法private void validateAddress(String address) {if (address == null || address.isEmpty()) {throw new IllegalArgumentException("Address is invalid.");}// 进一步的地址验证逻辑}// 检查库存是否足够private void checkInventory(Inventory inventory) {if (inventory == null || inventory.getStock() <= 0) {throw new IllegalArgumentException("Insufficient inventory.");}}// 根据用户和库存信息生成订单private Order generateOrder(UserInfo user, Inventory inventory, OrderRequest request) {Order order = new Order();order.setUserId(user.getUserId());order.setSkuId(request.getSkuId());order.setQuantity(request.getQuantity());order.setTotalPrice(inventory.getPrice() * request.getQuantity());order.setShippingAddress(user.getAddress());order.setStatus(OrderStatus.PENDING);return order;}// 异步保存订单,使用自定义线程池private CompletableFuture<Order> saveOrderAsync(Order order) {return CompletableFuture.supplyAsync(() -> orderService.saveOrder(order), executorService);}// 发送订单通知private String sendNotification(Order order) {notificationService.sendOrderConfirmation(order);return "Order placed successfully!";}// 关闭线程池public void shutdown() {if (executorService != null && !executorService.isShutdown()) {executorService.shutdown();System.out.println("Thread pool shut down gracefully.");}}// 强制关闭线程池public void shutdownNow() {if (executorService != null && !executorService.isShutdown()) {executorService.shutdownNow();System.out.println("Thread pool shut down immediately.");}}// 线程池是否已关闭public boolean isShutdown() {return executorService.isShutdown();}// 主方法示例public static void main(String[] args) {// 初始化 OrderService 并传入线程池大小OrderService orderService = new OrderService(5);// 获取并输出当前线程池大小int poolSize = orderService.getThreadPoolSize();System.out.println("Current thread pool size: " + poolSize);// 假设创建一个订单请求对象OrderRequest orderRequest = new OrderRequest("user123", "sku456", 2);orderService.createOrderAsync(orderRequest).thenAccept(result -> {System.out.println(result.getMessage());});// 动态调整线程池大小orderService.setThreadPoolSize(10);System.out.println("Updated thread pool size: " + orderService.getThreadPoolSize());// 关闭线程池orderService.shutdown();}
}输出结果
Thread pool initialized with size: 5
Current thread pool size: 5
Order placed successfully!
Thread pool resized to: 10
Updated thread pool size: 10
Thread pool shut down gracefully.最佳实践与注意事项
线程池选择策略
CPU密集型任务使用有界线程池IO密集型任务使用缓存线程池- 避免混合使用不同任务类型
资源管理
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {CompletableFuture.runAsync(() -> task(), executor);
}
调试技巧
- 使用 thenApplyAsync 添加日志点
- 包装异步操作添加跟踪ID
cf.thenApplyAsync(result -> {log.debug("[Trace-{}] Step completed", traceId);return result;
});
性能优化
- 避免过度嵌套回调
- 及时关闭自定义线程池
- 使用
CompletableFuture#join()谨慎
总结
CompletableFuture为 Java 异步编程提供了强大支持,特别适用于:
- 需要编排多个异步操作的场景
- 实现非阻塞的响应式系统
- 需要精细控制任务执行顺序和依赖关系
- 构建高并发、低延迟的服务















![2 [GitHub遭遇严重供应链投毒攻击]](https://i-blog.csdnimg.cn/img_convert/32d5bbe15e03baf1da2eb3e47cf60eee.jpeg)