文章目录
- 2.1 着色器与OpenGL
- 2.2 0penGL的可编程管线
- 2.3 OpenGL着色语言GLSL概述
- 2.3.1 使用GLSL构建着色器
- 变量的声明
- 变量的作用域
- 变量的初始化
- 构造函数 、 类型转换
- 聚合类型
- 访问向量和矩阵中的元素
- 结构体
- 数组
- 多维数组
- 2.3.2 存储限制符
- const 存储限制符
- in 存储限制符
- out 存储限制符
- uniform 存储限制符
- buffer 存储限制符
- shared 存储限制符
- 2.3.3 语句
- 算术操作符
- 操作符重载
- 流控制
- 循环语句
- 流控制语句
- 函数
- 声明
- 参数限制符
- 2.3.4 计算的不变性
- invariant 限制符
- precise限制符
- 2.3.5 着色器的预处理器
- 宏定义
- 预处理器中的条件分支
- 2.3.6 编译器的控制 #pragma
- 编译器优化选项
- 编译器调试选项
- 2.3.7 全局着色器编译
- 所有输出变量值的不变性检查 `#pragma STDGL invariant(all)`
- 着色器的扩展功能处理 #extension
- 2.4 数据块接口
- 2.4.1 uniform块(uniform缓冲对象)
- 2.4.2 指定着色器中的uniform块
- uniform 块的布局控制
- 访问 uniform 块中声明的 uniform 变量注意事项
- 2.4.3 从应用程序中访问和操作uniform块
- 示例:初始化一个命名uniform块中的uniform变量
- 2.4.4 buffer块
- 2.4.5 in/out块、位置和分量
- 2.5 着色器的编译
- 2.6 着色器子程序(后补)
- 2.7 独立的着色器对象(后补)
- 2.8 checkError
2.1 着色器与OpenGL
- 现代 OpenGL渲染管线严重依赖着色器来处理传人的数据。
- 在OpenGL3.0版本以前(含该版本),或者如果你用到了兼容模式(compatibility profile)环境,OpenGL还包含一个固定功能管线(fixed-function pipeline),它可以在不使用着色器的情况下处理几何与像素数据。从3.1版本开始,固定功能管线从核心模式中去除,因此我们必须使用着色器来完成工作。
- 任何一种 OpenGL程序本质上都可以被分为两个部分:CPU端运行的部分采用C++之类的语言进行编写;以及GPU端运行的部分,使用GLSL语言编写(与“C”语言非常类似)。
2.2 0penGL的可编程管线
- 详细解释 OpenG可编程管线的每个阶段。
- 4.5版本的图形管线有4个处理阶段还有1个通用计算阶段,每个阶段都需要由一个专门的着色器进行控制。

- 顶点着色阶段:
- 接收你在顶点缓存对象中给出的顶点数据,独立处理每个顶点。
- 这个阶段对于所有的OpenGL程序都是唯一且必需的,并且OpenGL程序在绘制时必须绑定一个着色器。
- opengl绘制方式章节将对顶点着色的操作进行介绍。
- 细分着色阶段:可选阶段
- 应用程序中显式地指定几何图元的方法不同,它会在OpenGL管线内部生成新的几何体。
- 这个阶段启用之后会收到来自顶点着色阶段的输出数据,并且对收到的顶点进行进一步的处理。
- 细分阶段实际上是通过两个着色器来完成的,分别叫做细分控制着色器(tessellationcontrol shader)和细分赋值 / 计算着色器(tessellation evaluation shader)。
- 细分章节会介绍。
- 几何着色阶段:可选阶段
- 它会在 OpenGL 管线内部对所有几何图元进行修改。
- 这个阶段会作用于每个独立的几何图元。
- 此时你可以选择从输入图元生成更多的几何体,改变几何图元的类型(例如将三角形转化为线段),或者放弃所有的几何体。
- 片元着色阶段:
- 这个阶段会处理 OpenGL光栅化之后生成的独立片元(如果启用了采样着色的模式,就是采样数据),并且这个阶段也必须绑定一个着色器。
- 在这个阶段中,计算一个片元的颜色和深度值,然后传递到管线的片元测试和混合的模块。
- 计算着色阶段:
- 它并不是图形管线的一部分,而是在程序中相对独立的一个阶段。
- 计算着色阶段处理的并不是顶点和片元这类图形数据,而是应用程序给定范围的内容。
- 计算着色器在应用程序中可以处理其他着色器程序所创建和使用的缓存数据。这其中也包括帧缓存的后处理效果,详见计算着色器章节。
着色阶段之间数据传输的方式:in,out,uniform
- 每个着色器看起来都像是一个完整的C程序,它的输入点就是一个名为main()的函数。
- 但与C不同的是,GLSL的main()函数没有任何参数,在某个着色阶段中输入和输出的所有数据都是通过着色器中的特殊全局变量来传递的(请不要将它们与应用程序中的全局变量相混淆–着色器变量与你在应用程序代码中声明的变量是完全不相干的)。
- OpenGL定义了in变量将数据拷贝到着色器中,以及out变量将着色器的内容拷贝出去。
- 这些变量的值会在 OpenGL,每次执行着色器的时候更新。
- 另一类变量是直接从OpenGL应用程序中接收数据的,称作uniform变量。uniform变量不会随着顶点或者片元的变化而变化,它对于所有的几何体图元的值都是一样的,除非应用程序对它进行了更新。
2.3 OpenGL着色语言GLSL概述
2.3.1 使用GLSL构建着色器
#version 430 corein vec4 position;void main(void)
{gl_Position = position;// 注释/*注释*/
}
- 一个着色器程序和一个C程序类似,都是从main()函数开始执行的,但是不需要返回一个整数值。
变量的声明
- 所有变量都必须事先声明,并且要给出变量的类型。变量名称的命名规范与C语言相同,但是注意变量名称也不能包含连续的下划线(这些名称是 GLSL保留使用的)。
- 基本数据类型,包括后文中他们的聚合类型,他们的内部形式都是暴露的

- 不透明类型,即内部形式没有暴露:包括采样器(sampler)、图像(image),以及原子计数器(atomic counter)。
变量的作用域
- 在任何函数定义之外声明的变量拥有全局作用域,因此对该着色器程序中的所有函数都是可见的。
- 在一组大括号之内(例如函数定义、循环或者“if”引领的代码块等)声明的变量只能在大括号的范围内存在。
- 循环的迭代自变量,只能在循环体内起作用。
变量的初始化
- 所有变量都必须在声明的同时进行初始化。例如:

- 如果要表达一个double精度的浮点数,必须在末尾添加后缀“F”或者“LF"。
构造函数 、 类型转换
- GLSL比C++更注重类型安全,因此它支持的数值隐式转换更少些。例如
int f = false;会返回一个编译错误。 - 可以隐式转换的类型:

- 换适用于这些类型的标量、向量以及矩阵。
- 类型转换不能应用于数组或者结构体之上。
- 所有其他的数值转换都需要提供显式的转换构造函数,它是一个名字与类型名称相同的函数,返回值就是对应类型的值,例如:

- 其他一些类型也有转换构造函数,包括float、double、uint、bool,以及这些类型的向量和矩阵,可以传人多个其他类型的值并且进行显式转换,这里体现了函数重载的特性。
聚合类型
- GLSL支持2个、3个以及4个分量的向量,每个分量都可以使用boo1、intuint、float 和 double这些基本类型。
- 向量和矩阵类型也可以使用length()方法。向量的长度也就是它包含的分量的个数,矩阵的长度是它包含的列的个数。

length()返回的是编译时常量!可以当作常量使用。

- GLSL也支持float和 double类型的矩阵。

- 矩阵类型需要给出两个维度的信息,例如mat4x3,其中第一个值表示列数,第二个值表示行数。
- 初始化这些聚合类型和他们的标量类似:
vec3 temp = vec3(1.0,1.0,0.0); - 类型之间也可以进行等价转换:
ivec3 steps =ivec3(temp); - 向量的构造函数还可以用来截短或者加长一个向量。如果将一个较长的向量传递给个较短向量的构造函数,那么向量将被自动取短到对应的长度:

- 也可以使用同样的方式来加长一个向量。这也是唯一的一类构造函数,它的输入参数比变量的实际分量数更少:

- 矩阵可以将它初始化为一个对角矩阵或者完全填充的矩阵。
- 对于对角矩阵,只需要向构造函数传递一个值,矩阵的对角线元素就设置为这个值,其他元素全部设置为0,例如:

- 矩阵也可以通过在构造函数中指定每一个元素的值来构建,传入元素可以是标量和向量的集合,只要给定足够数量的数据即可。
- 矩阵的指定需要遵循列主序的原则,也就是说,传入的数据将首先填充列,然后填充行(这个c中的二维数组初始化相反),例如,可以通过下面几种形式之一来初始化一个3x3的矩阵:

访问向量和矩阵中的元素
- 向量与矩阵中的元素是可以单独访问和设置的。
- 向量支持两种类型的元素访问方式使用分量的名称,或者数组访问的形式。

- 向量分量的访问符:

这种分量访问符的一个常见应用叫做swizzle,即可以使用一个向量的多个访问符构建成另一个向量。
- 唯一的限制是,在一条语句的一个变量中,只能使用一种类型的访问符,例如下面是错误的:
- 此外,如果我们访问的元素超出了变量类型的范围,也会引发编译时错误。例如:



- 矩阵可以以二维数组的形式进行访问。
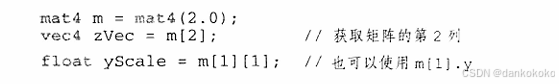
结构体
- 类似于c中的struct,从逻辑上将不同类型的数据组合到一个结构体当中。
- 如果定义了一个结构体,那么它会自动创建一个新类型,并且隐式定义一个构造函数,将各种类型的结构体元素作为输人参数,类似于{}构造。

- 访问成员也是用成员访问运算符“.”。
数组
- GLSL还支持任意类型的数组,包括结构体和数组(GLSL 4.3)。
- 数组的索引访问可以通过方括号来完成([])。
- 负数形式的数组索引,或者超出范围的索引值都是不允许的。
- 数组可以定义为有大小的,或者没有大小的。
- 我们可以使用没有大小的数组作为一个数组变量的前置声明,然后重新用一个合适的大小来声明它:

- 数组属于GLSL中的第一等(first-class)类型,也就是说它有构造函数,并且可以用作函数的参数和返回类型。
- 如果我们要静态初始化一个数组的值,参考:构造函数的维数值可以不填

- 数组.length()可以获得数组元素个数。
对于所有向量和矩阵,以及大部分的数组来说,length()都是一个编译时就已知的常量。
但是对于某些数组来说,length()的值在链接之前可能都是未知的。
甚至对于着色器中保存的缓存对象(使用 buffer来进行声明,后文将会介绍),length()的值直到渲染时才可能得到。
多维数组
- 多维数组相当于从数组中再创建数组,它的语法与C语言当中类似:

2.3.2 存储限制符
- 数据类型也可以通过一些修饰符来改变自己的行为。GLSL中一共定义了几种全局范围内的修饰符:

const 存储限制符
对变量的声明添加了const修饰符之后,如果再向这个变量写人,那么将会产生一个错误,因此这种变量必须在声明的时候就进行初始化。
in 存储限制符
- 这类输入变量可以是顶点属性(对于顶点着色器),或者前一个着色器阶段的输出变量。
- 片元着色器也可以使用一些其他的关键词来限定自己的输入变量,这会在第4章中进行讲解。
out 存储限制符
out修饰符用于定义一个着色器阶段的输出变量–例如,顶点着色器中输出变换后的齐次坐标,或者片元着色器中输出的最终片元颜色。
uniform 存储限制符
- 在着色器运行之前,uniform修饰符可以指定一个在应用程序中设置好的变量,它不会在图元处理的过程中发生变化。
- uniform变量在所有可用的着色阶段之间都是共享的,它必须定义为全局变量。
- 任何类型的变量(包括结构体和数组)都可以设置为uniform变量。
- 着色器无法写人到uniform变量,也无法改变它的值。
- 举例来说,我们可能需要设置一个给图元着色的颜色值。此时可以声明一个uniform变量,将颜色值信息传递到着色器当中。而着色器中会进行如下声明:
uniform vec4 BaseColor;
在着色器中,可以根据名字BaseColor来引用这个变量,但是如果需要在用户应用程序中设置它的值,还需要多做一些工作。
- GLSL编译器会在链接着色器程序时创建一个uniform变量列表。
- 在设定uniform值之前,需要先获得该uniform在列表中的索引:
// 返回着色器程序中uniform 变量 name 对应的索引值。
// 除非我们重新链接着色器程序(参见glLinkProgram()),否则这里的返回值不会发生变化。
// name是一个以NULL结尾的字符串,不存在空格。
// 如果 name 与启用的着色器程序中的所有uniform 变量都不相符,或者name是一个内部保留的着色器变量名称(例如,以gl_开头的变量),那么返回值为-1。
GLint glGetUniformLocation(GLuint program, const GLchar *name);
- name可以是单一的变量名称、数组中的一个元素(此时name主要包含方括号以及对应的索引数字),或者结构体的域变量(设置name时,需要在结构体变量名称之后添加“.”符号,再添加域变量名称,并与着色器程序中的写法一致)。
- 对于umifomm变量数组,也可以只通过指定数组的名称来获取数组中的第一个元素(例如,直接用“arayName”),或者也可以通过指定索引值来获取数组的第一个元素(例如,写作“arayName[0]”)。
- 当得到 uniform 变量的对应索引值之后,我们就可以通过 glUniform*()或者 glUniformMatrix*()系列函数来设置 uniform 变量的值了:

参数transpose:如果transpose设置为GL_TRUE,那么 values中的数据是以行主序的顺序读入的(与C语言中的数组类似),如果是GL_FALSE,那么values中的数据是以列主序的顺序读人的。

buffer 存储限制符
- 如果需要在应用程序中共享一大块缓存给着色器,则可以使用buffer限制符号。
- buffer修饰符指定随后的块作为着色器与应用程序共享的一块内存缓存。这块缓存对于着色器来说是可读的也是可写的。缓存的大小可以在着色器编译和程序链接完成后设置。
shared 存储限制符
shared修饰符只能用于计算着色器当中,它可以建立本地工作组内共享的内存。后续章节介绍。
2.3.3 语句
GLSL也提供了大量的操作符,来实现各种数值计算所需的算术操作,以及一系列控制着色器运行的逻辑操作。
算术操作符
总体上来说,操作符对应的类型必须是相同的,并且对于向量和矩阵而言,操作符的操作对象也必须是同一维度的。

操作符重载
GLSL中的大部分操作符都是经过重载的,也就是说它们可以用于多种类型的数据操作。
- 需要注意,如果我们需要进行向量和矩阵之间的乘法(注意,操作数的顺序非常重要,从数学上来说,矩阵乘法是不遵循交换律的),可以使用下面的操作:
此时向量应该是行向量。即1x3 匹配3x3 = 1x3。- 两个向量相乘得到的是一个逐分量相乘的新向量,但是两个矩阵相乘得到的是通常矩阵相乘的结果:
还可以通过函数调用的方式实现常见的一些向量操作(例如,点乘和又乘等)。


流控制
GLSL的逻辑控制方式用的也是流行的if-else和switch语句。
循环语句
GLSL 支持C语言形式的for、while 和 do… while 循环。
流控制语句
除了条件和循环之外,GLSL还支持一些别的控制语句。

函数
- 我们可以使用函数调用来取代可能反复执行的通用代码。
- GLSL支持用户自定义函数,同时它也定义了一些内置函数具体列表可以参见附录C。
OpenGL 着色语言有少量内置变量、适量的常量及大量的内置函数。
- 用户自定义函数可以在单个着色器对象中定义,然后在多个着色器程序中复用。
声明
- 函数声明语法与C语言非常类似,只是参数变量名需要添加参数限制符:

- 函数名不能使用数字、连续下划线或者 gl 作为函数的开始。
- 返回值可以是任何内置的GLSL类型,或者用户定义的结构体和数组类型。返回值为数组时,必须显式地指定其大小。
- 函数的参数也可以是任何类型,包括数组(但是也必须设置数组的大小)。
- 在使用一个函数之前,必须声明它的原型或者直接给出函数体,必须在使用函数之前找到函数的声明,否则会产生错误。
- 如果函数的定义和使用不在同一个着色器对象当中,那么必须声明一个函数原型。
参数限制符
- 尽管GLSL中的函数可以在运行后修改和返回数据,但是它与“C”或者C++不同并没有指针或者引用的概念,但是可以通过参数限制符实现差不多效果。

- 如果变量的值需要从函数中拷贝出来,那么我们就必须设置它为out(只能写出的变量)或者inout(可以读入也可以写出的变量)修饰符。
- 写了这四个之外的限制符,会产生编译时错误。
2.3.4 计算的不变性
- GLSL无法保证在不同的着色器中,两个完全相同的计算式会得到完全一样的结果。
- GLSL有两种方法来确保着色器之间的计算不变性,即invariant(不变) 或者precise关键字。
这两种方法都需要在图形设备上完成计算过程,来确保同一表达式的结果可以保证重复性(不变性)。
但是无法保证宿主机计算的结果与图形硬件计算的结果完全相同:

invariant 限制符
invariant 限制符可以设置任何着色器的输出变量或者内置变量。

- 它可以确保如果两个着色器的输出变量使用了同样的表达式,并且表达式中的变量也是相同值,那么计算产生的结果也是相同的。
- 在调试过程中,可能需要将着色器中的所有可变量都设置为invariance。可以通过顶点着色器的预编译命令pragma来完成这项工作:
#pragma STDGL invariant(all)
precise限制符
-
precise限制符可以设置任何计算中的变量、内置变量或者函数的返回值。

-
它的用途并不是增加数据精度,而是增加计算的可复用性。
-
我们通常在细分着色器中用它来避免造成几何体形状的裂缝。后续讲解。
-
总体上说,如果必须保证某个表达式产生的结果是一致的,即使表达式中的数据发生了变化(但是在数学上并不影响结果,例如交换律数学上是不影响结果的)也是如此。
-
在着色器中,关键字precise可以在使用某个变量之前的任何位置上设置这个变量并且可以修改之前已经声明过的变量。
-
但是此时声明precise过的变量不能再使用两种不同的乘法命令来同时参与计算。
例如,第一次相乘使用普通的乘法,而第二次相乘使用混合乘加运算。
计算结果可能会存在微小的差异。而这种差异是precise所不允许的,会编译错误。此时可以用内置函数替代某些运算。
2.3.5 着色器的预处理器
- 与C语言预处理器不同的是,没有#include命令。


宏定义
- 不过它不支持字符串替换以及预编译连接符。宏可以定义为单一的值。


- 可以通过 #undef命令来取消之前定义过的宏(GLSL内置的宏除外):
#undef LPos
预处理器中的条件分支
- 可以根据宏定义以及整型常数的条件来判断进入不同的分支,包含不同的代码段。
- 方法一:

- 方法二:

2.3.6 编译器的控制 #pragma
- #pragma命令可以向编译器传递附加信息,并在着色器代码编译时设置一些额外属性。
编译器优化选项
- 优化选项用于启用或者禁用着色器的优化,它会直接影响该命令所在的着色器源代码。
#pragma optimize(on)或#pragma optimize(off)。 - 一般默认所有着色器都开启了优化选项。
编译器调试选项
- 调试选项可以启用或者禁用着色器的额外诊断信息输出。
#pragma debug(on)或#pragma debug(off) - 默认情况下,所有着色器都会禁用调试选项。
2.3.7 全局着色器编译
所有输出变量值的不变性检查 #pragma STDGL invariant(all)
- 这个选项目前用于启用所有输出变量值的不变性检查。
着色器的扩展功能处理 #extension
GLSL与OpenGL类似,都可以通过扩展的方式来增加功能。设备生产商也可以在自己的 OpenGL实现中加人特殊的扩展,因此很有必要对着色器中可能用到的扩展功能进行编译级别的控制。

- directive参考:

2.4 数据块接口
- 着色器与应用程序之间,或者着色器各阶段之间共享的变量可以组织为变量块的形式。
- uniform变量可以使用uniform块,输人和输出变量可以使用in和out块,着色器的存储缓存可以使用 buffer块。
- 写法:

- 块(block)开始部分的名称(上面的代码中为b)对应于外部访问时的接口名称(我们知道uniform是需要应用程序设置的)。
- 结尾部分的名称(上面的代码中为name)用于在着色器代码中访问具体成员变量。
2.4.1 uniform块(uniform缓冲对象)
- 通常会在多个着色器程序中用到同一个uniform 变量。由于uniform 变量的位置是着色器链接的时候产生的(也就是调用glLinkProgram()的时候),因此它(同一个块)在应用程序(不同着色器)中获得的索引可能会有变化,即使我们给uniform 变量设置的值可能是完全相同的。
- uniform缓存对象(uniform buffer object,即数据块)就是一种优化 uniform 变量访问,以及在不同的着色器程序之间共享uniform数据的方法,uniform变量是同时存在于用户应用程序和着色器当中的,因此需要同时修改着色器的内容并调用OpenGL函数来设置uniform 缓存对象。
2.4.2 指定着色器中的uniform块
- 注意,着色器中的数据类型有两种:不透明的和透明的;其中不透明类型包括采样器图像和原子计数器。一个 uniform块中只可以包含透明类型的变量。此外,uniform 块必须在全局作用域内声明。
uniform 块的布局控制
- 在uniform块中可以使用不同的限制符来设置变量的布局方式。这些限制符可以用来设置单个的 uniform块,也可以用来设置所有后继uniform块的排列方式(需要使用布局声明)。

- 如果需要共享一个uniform块,并且使用行主序的方式来存储数据,那么可以使用下面的代码来``声明它:
layout(shared,row_major)uniform{...}; - 如果需要对所有后继的uniform 块设置同一种布局,那么可以使用下面的语句:
layout(packed,column major)uniform;
当前行之后的所有uniform 块都会使用这种布局方式,除非再次改变全局的布局,或者对某个块的声明单独设置专属的布局方式。
- 如果你在着色器和应用程序之间共享了一块缓存,那么这两者都需要确认成员变量所处的内存偏移地址。可以使用std140和 std430 所提供的功能,或者通过offset限制符来控制成员的精确位置,或者用align限制符来设置一个模糊的对齐方式(可以只对某些成员进行限制)。

没有使用限制符的成员会自动进行偏移位置的对齐,并且必须按照std140或者std430的规则对齐。只不过std140需要对类似 vec4 这样的类型增加一个额外的 16 字节对齐的限制。
- 注意N的定义:GLSL的布局限制符在任何时候都是1ayout(ID=N)的形式,这里的N必须是一个非负整数。从 #version 440开始,N也可以是一个常整数的表达式了(以前是需要字面整数值)。
访问 uniform 块中声明的 uniform 变量注意事项
- 虽然uniform块已经命名了,但是块中声明的uniform变量并不会受到这个命名的限制。也就是说,uniform块的名称并不能作为uniform 变量的父名称,因此在两个不同名的uniform 块中声明同名变量会在编译时造成错误。
- 在访问一个uniform 变量的时候也不一定非要使用块的名称。
2.4.3 从应用程序中访问和操作uniform块
- uniform 变量是着色器与应用程序之间共享数据的桥梁,因此如果着色器中的uniform变量是定义在命名的 uniform块中,那么就有必要找到不同变量的偏移值。
- 首先假设已知应用程序的着色器中uniform块的名字,然后找到块在着色器程序中的索引位置:
// 返回program中名称为uniformBlockName的uniform块的索引值。
// 错误返回GL_INVALID_INDEX
GLuint glGetUniformBlockindex(GLuint program, const char * uniformBlockName);
- 如果要初始化 uniform块对应的缓存对象,那么我们需要使用 glBindBuffer()将缓存对象绑定到目标GL_UNIFORM_BUFFER之上:
// 常用。
// 将缓存对象 buffer与索引为index的命名uniform块关联起来。
// target 必须是支持索引的某个缓存绑定目标。
// offset和size分别指定了 uniform 缓存映射的起始索引和大小。
void glBindBufferRange(GLenum target, GLuint index, GLuint buffer, GLintptr offset, GLsizeiptr size);// 如果uniform块是全部使用缓存来存储的,可以用该函数。
// target 必须是支持索引的某个缓存绑定目标。
// 将缓存对象 buffer与索引为index的命名uniform块关联起来。
// 等价于调用glBindBufferRange()并设置offset为0,size为缓存对象的大小。
void glBindBufferBase(GLenum target, GLuint index, GLuint buffer);
OpenGL错误GL_INVALID_VALUE的情况:
- size小于0;
- offset+size大于缓存大小;
- offset或size不是4的倍数;
- index小于0或者大于等于 target设置的绑定目标所支持的最大索引数。
- 当对缓存对象进行初始化之后,需要判断命名的uniform 块中的变量(成员)总共占据了多大的空间:
该函数还可以获取一个命名uniform块的一些相关参数:参考链接
// pname需要设定参数为GL_UNIFORMBLOCK_DATA_SIZE。
// params指定用于接收查询结果的变量的地址。
// 根据 uniform 块的布局设置编译器可能会自动排除着色器中没有用到的unifomm 变量.
void glGetActiveUniformBlockiv(GLuint program, GLuint uniformBlockIndex, GLenum pname, GLint *params);
- 当建立了命名uniform 块和缓存对象之间的关联之后,只要使用缓存相关的命令即可对
块内的数据进行初始化或者修改。 - 如果需要显式地控制一个uniform块的绑定方式(不使用链接器内部自动绑定块对象并且查询关联结果的方式),可以在调用glLinkProgram()之前调用(这样可以避免对于不同的着色器程序同一个块有不司的索引号):
// 显式地将块 uniformBlockIndex绑定到uniformBlockBinding.
void glUniformBlockBinding(GLuint program, GLuint uniformBlockIndex, GLuint uniformBlockBinding);
- 在一个命名的uniform块中,uniform变量的布局是通过各种布局限制符在编译和链接时控制的。如果使用了默认的布局方式,那么需要判断每个变量在uniform 块中的偏移量和数据存储大小:
// 返回uniformCount个uniform变量的索引位置.
// 变量的名称通过字符串数组uniformNames来指定,每个名称都是以NULL来结尾的.
// 程序返回值保存在数组uniformIndices当中.
// 并且uniformNames和uniformIndices的数组元素数都应该是uniformCount个。
// 如果在uniformNames中某个名称不是当前启用的uniform变量名称,
// 那么uniformIndices中对应的位置将会记录为GLINVALID INDEX。
void glGetUniformIndices(GLuint program, GLsizei uniformCount, const GLchar *const*uniformNames, GLuint *uniformIndices);// 获得指定索引位置的偏移量和大小
// 帮助文档:
//https://registry.khronos.org/OpenGL-Refpages/gl4/html/glGetActiveUniformsiv.xhtml
// uniformCount查询个数,uniformIndices需要查询的索引位置,pname需要查询的信息设置参数
// params返回结果节点
void glGetActiveUniformsiv(GLuint program, GLsizei uniformCount, const GLuint *uniformIndices, GLenum pname, GLint *params);
示例:初始化一个命名uniform块中的uniform变量
// Vertex Shader source code
const char* vertexShaderSource = "#version 450 core\n"
"layout (location = 0) in vec3 aPos;\n"
"uniform Uniform"
"{\n"
" vec3 translation;\n"
" float scale;\n"
" bool enabled;\n"
"};\n"
"void main()\n"
"{\n"
" vec3 pos = aPos;\n"
" pos *= scale;\n"
" pos += translation;\n"
" gl_Position = vec4(pos, 1.0);\n"
"}\0";
//Fragment Shader source code
const char* fragmentShaderSource = "#version 450 core\n"
"out vec4 FragColor;\n"
"uniform Uniform"
"{\n"
" vec3 translation;\n"
" float scale;\n"
" bool enabled;\n"
"};\n"
"void main()\n"
"{\n"
" FragColor = vec4(scale, scale, scale, 1.0f);\n"
"}\n\0";int initUniformBufferObject()
{// Create Vertex Shader Object and get its referenceGLuint vertexShader = glCreateShader(GL_VERTEX_SHADER);// Attach Vertex Shader source to the Vertex Shader Object// 参数2:GLchar *const*stringglShaderSource(vertexShader, 1, &vertexShaderSource, NULL);// Compile the Vertex Shader into machine codeglCompileShader(vertexShader);int result;glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &result);if (result == GL_FALSE){int length;glGetShaderiv(vertexShader, GL_INFO_LOG_LENGTH, &length);char* message = (char*)alloca(length * sizeof(char));glGetShaderInfoLog(vertexShader, length, &length, message);std::cout << message << std::endl;glDeleteShader(vertexShader);return -1;}// Create Fragment Shader Object and get its referenceGLuint fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);// Attach Fragment Shader source to the Fragment Shader ObjectglShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);// Compile the Vertex Shader into machine codeglCompileShader(fragmentShader);glGetShaderiv(fragmentShader, GL_COMPILE_STATUS, &result);if (result == GL_FALSE){int length;glGetShaderiv(fragmentShader, GL_INFO_LOG_LENGTH, &length);char* message = (char*)alloca(length * sizeof(char));glGetShaderInfoLog(fragmentShader, length, &length, message);std::cout << message << std::endl;glDeleteShader(fragmentShader);return -1;}// Create Shader Program Object and get its referenceGLuint shaderProgram = glCreateProgram();// Attach the Vertex and Fragment Shaders to the Shader ProgramglAttachShader(shaderProgram, vertexShader);glAttachShader(shaderProgram, fragmentShader);// Wrap-up/Link all the shaders together into the Shader ProgramglLinkProgram(shaderProgram);// Delete the now useless Vertex and Fragment Shader objectsglDeleteShader(vertexShader);glDeleteShader(fragmentShader);glUseProgram(shaderProgram);// 初始化uniform块和成员变量GLuint uboIndex;GLint uboSize;GLuint ubo;GLbyte* buffer = nullptr;// 查找Uniform的uniform缓存索引uboIndex = glGetUniformBlockIndex(shaderProgram,"Uniform");glGetActiveUniformBlockiv(shaderProgram,uboIndex,GL_UNIFORM_BLOCK_DATA_SIZE,&uboSize);buffer = new GLbyte[uboSize];/*准备存储在缓存对象中的值*/GLfloat scale = 0.5;GLfloat translation[] = { 0.1f,0.1f,0.0f };GLboolean enabled = GL_TRUE;// 查询对应的属性,以判断向数据缓存中写入数值的位置const int NumUniforms = 3;const char* names[NumUniforms] ={"translation","scale","enabled"};enum { Translation,Scale,Enabled };GLuint indices[NumUniforms];GLint size[NumUniforms];GLint offset[NumUniforms];GLint type[NumUniforms];glGetUniformIndices(shaderProgram, NumUniforms, names, indices);glGetActiveUniformsiv(shaderProgram, NumUniforms, indices,GL_UNIFORM_OFFSET,offset);/*将uniform变量值拷贝到缓存中*/memcpy(buffer + offset[Translation],&translation,3*sizeof(GLfloat));memcpy(buffer + offset[Scale], &scale,1 * sizeof(GLfloat));memcpy(buffer + offset[Enabled], &enabled, 1 * sizeof(GLboolean));/*建立 uniform缓存对象,初始化存储内容,并且与着色器程序建立关联*/glGenBuffers(1,&ubo);glBindBuffer(GL_UNIFORM_BUFFER,ubo);glBufferData(GL_UNIFORM_BUFFER,uboSize,buffer,GL_STATIC_DRAW);glBindBufferBase(GL_UNIFORM_BUFFER, uboIndex, ubo);// 关联到指定索引的uniform块!
}
2.4.4 buffer块
- 相当于着色器的存储缓存对象(shaderstorage buffer object),行为类似uniform块,但是着色器可以写人buffer块,修改其中的内容并呈现给其他的着色器调用或者应用程序本身。其次,可以在渲染之前再决定它的大小,而不是着色器编译和链接的时候:

着色器中可以通过length()方法获取渲染时的数组大小。
- 着色器可以对buffer块中的成员执行读或写操作。写入操作对着buffer块的修改对于其他着色器调用都是可见的。
- 设置着色器存储缓存对象的方式与设置uniform 缓存的方式类似,不过glBindBuffer()glBindBufferRange()和 glBindBufferBase()需要使用 GL_SHADER_STORAGE_BUFFER作为目标参数。
- buffer 块只可以使用 std430布局。
2.4.5 in/out块、位置和分量
- 着色器变量从一个阶段输出,然后再输入到下一个阶段中,这一过程可以使用块接口来表示。

- 从 OpenGL4.4版本开,layout(location=N)可以作用于输入和输出块的成员,显式地设置它们的位置:

- 如果把多个小的对象设置到同一个位置上,那么也可以使用分量(component)关键字:

- OpenGL着色语言中内置的接口同样也是以块的方式存在的,详见附录C的内置变量列表。
2.5 着色器的编译

- 创建着色器对象
// 返回值可能是一个非零的整数值,如果为0则说明发生了错误。GLuint glCreateShader(GLenum type);
type必须是 GL_COMPUTE_SHADER, GL_VERTEX_SHADER, GL_TESS_CONTROL_SHADER, GL_TESS_EVALUATION_SHADER, GL_GEOMETRY_SHADER, or GL_FRAGMENT_SHADER.
- 将着色器的源码关联到这个对象上。
// string是一个由count行GLchar 类型的字符串组成的数组,用来表示着色器的源代码数据。
// 如果length是NULL,那么我们假设 string给出的每行字符串都是NULL结尾的。
//否则,length中必须有count 个元素它们分别表示 sting 中对应行的长度。
//如果 length 数组中的某个值是一个整数,那么它表示对应的字符串中的字符数。
//如果某个值是负数,那么sting中的对应行假设为NULL结尾。
void glShaderSource(GLuint shader, GLsizei count, const GLchar *const*string, const GLint *length);
- 编译着色器对象的源代码
// glCompileShader
void glCompileShader(GLuint shader);// 参数pname为GL_COMPILE STATUS,params返回的就是编译过程的状态.
// 如果返回为GL_TRUE,那么编译成功,
// pname可以取:GL_SHADER_TYPE, GL_DELETE_STATUS, GL_COMPILE_STATUS,
// GL_INFO_LOG_LENGTH, GL_SHADER_SOURCE_LENGTH.
void glGetShaderiv(GLuint shader, GLenum pname, GLint *params);// 调取编译日志来判断错误的原因。
// 会返回一个与具体实现相关的信息,用于描述编译时的错误。
// 返回的日志信息是一个以 NULL结尾的字符串,它保存在infoLog 缓存中,长度为length个字符串。
// 这个错误日志的大小可以通过调用glGetShaderiv()(帶参数 GL_INFO_LOG_LENGTH)来查询.
// bufSize:指定infoLog缓冲区的大小,即日志可以返回的最大值。
// length:返回实际写入的字符数,包括空字符。
// 如果 length 设置为 NULL,那么将不会返回 infoLog 的大小。
// infoLog:返回着色器对象的信息日志。
void glGetShaderInfoLog(GLuint shader, GLsizei bufSize, GLsizei *length, GLchar *infoLog);
- 调取编译错误日志示例:
int result;
glGetShaderiv(id, GL_COMPILE_STATUS, &result);
if(result == GL_FALSE)
{int length;glGetShaderiv(id, GL_INFO_LOG_LENGTH, &length);char* message =(char*)alloca(length * sizeof(char));glGetShaderInfoLog(id,length,&length, message);std::cout<< message<< std::endl;glDeleteShader(id);return 0;
}
- 创建一个可执行的着色器程序
// 创建一个空的着色器程序。返回值是一个非零的整数,如果为0则说明发生了错误。
GLuint glCreateProgram(void);
- 关联着色器对象
//将着色器对象shader关联到着色器程序program上。
//着色器对象可以在任何时候关联到着色器程序,但是它的功能只有经过程序的成功链接之后才是可用的。
//着色器对象可以同时关联到多个不同的着色器程序上。
void glAttachShader(GLuint program, GLuint shader);
- 从着色器程序移除一个着色器对象
// 如果着色器已经被标记为要删除的对象(调用 gIDeleteShader()),然后又被解除了关联,那么它将会被即时删除。
void glDetachShader(GLuint program, GLuint shader);
- 链接对象来生成可执行程序
void glLinkProgram(GLuint program);// 链接操作的结果查询
// 参数pname为GL_LINK_STATUS.如果返回 GL_TRUE,那么链接成功;否则,返回GL_FALSE。
void glGetProgramiv(GLuint program, GLenum pname, GLint *params);// 获取程序链接的日志信息并判断错误原因
void glGetProgramInfoLog(GLuint program, GLsizei bufSize, GLsizei *length, GLchar *infoLog);
- 运行着色器代码
// 参数设置为程序对象的句柄来启用顶点或者片元程序。
void glUseProgram(GLuint program);
如果已经启用了一个程序,而它需要关联新的着色器对象,或者解除之前关联的对象,那么我们需要重新对它进行链接。
如果链接过程成功,那么新的程序会直接替代之前启用的程序。如果链接失败,那么当前绑定的着色器程序依然是可用的,不会被替代,直到我们成功地重新链接或者使用 glUseProgram()指定了新的程序为止
- 链接和使用着色器程序之后,可以把着色器对象删掉了(其实只是标记)
// 删除着色器对象shader。如果shader当前已经链接到一个或者多个激活的着色器程序上,那么它将被标识为“可删除”,
//当对应的着色器程序不再使用的时候,就会自动删除这个对象。
void glDeleteShader(GLuint shader);
- 删掉着色器程序
// 立即删除一个当前没有在任何环境中使用的着色器程序program,
// 如果程序正在被某个环境使用,那么等到它空闲时再删除。
void glDeleteProgram(GLuint program);
- 判断某个着色器对象或着色器程序是否存在
// 没被删除都是GL_TRUE
GLboolean glIsShader(GLuint shader);
GLboolean glIsProgram(GLuint program);
2.6 着色器子程序(后补)
- 介绍一种增加着色器可用性的方法,它可以在不用重新编译着色器的前提下选择执行某个子程序。
2.7 独立的着色器对象(后补)
- 介绍一种增加着色器可用性的方法,它可以在不用重新编译着色器的前提下选择执行某个子程序。
2.8 checkError
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include <string>namespace check_gl
{const char *opengl_errno_name(GLenum err);void opengl_check_error(const char *filename, int lineno, const char *expr);
}#define CHECK_GL(x) do { \(x); \::check_gl::opengl_check_error(__FILE__, __LINE__, #x); \
} while (0)
const char *check_gl::opengl_errno_name(GLenum err) {switch (err) {
#define PER_GL_ERROR(x) case GL_##x: return #x;PER_GL_ERROR(NO_ERROR)PER_GL_ERROR(INVALID_ENUM)PER_GL_ERROR(INVALID_VALUE)PER_GL_ERROR(INVALID_OPERATION)PER_GL_ERROR(STACK_OVERFLOW)PER_GL_ERROR(STACK_UNDERFLOW)PER_GL_ERROR(OUT_OF_MEMORY)
#undef PER_GL_ERROR}return "unknown error";
}void check_gl::opengl_check_error(const char *filename, int lineno, const char *expr) {GLenum err = glad_glGetError();if (err != GL_NO_ERROR) {std::cerr << filename << ":" << lineno << ": " << expr << " failed: " << opengl_errno_name(err) << '\n';std::terminate();//__debugbreak();可以加个断点}
}










![2 [GitHub遭遇严重供应链投毒攻击]](https://i-blog.csdnimg.cn/img_convert/32d5bbe15e03baf1da2eb3e47cf60eee.jpeg)




