SparkSQL 是Spark的一个模块, 用于处理海量结构化数据。

SparkSQL是用于处理大规模结构化数据的计算引擎
SparkSQL在企业中广泛使用,并性能极好
SparkSQL:使用简单、API统一、兼容HIVE、支持标准化JDBC和ODBC连接
SparkSQL 2014年正式发布,当下使用最多的2.0版Spark发布于2016年,当下使用的最新3.0办发布于2019年
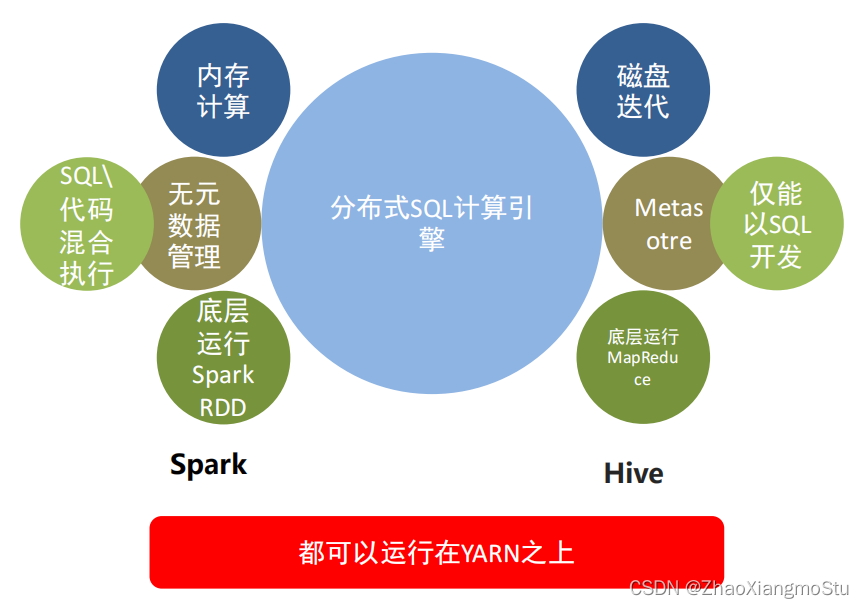
SparkSQL和Hive的异同
Hive和Spark 均是:“分布式SQL计算引擎”。均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。
SparkSQL的数据抽象
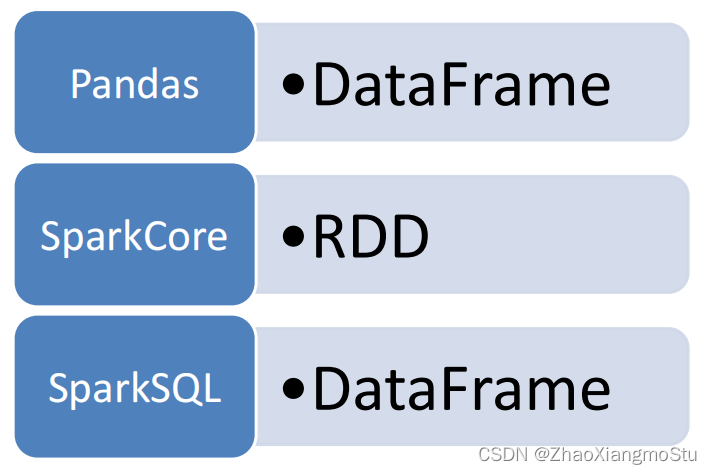
Pandas - DataFrame
• 二维表数据结构
• 单机(本地)集合
SparkCore - RDD
• 无标准数据结构,存储什么数据均可
• 分布式集合(分区)
SparkSQL - DataFrame
• 二维表数据结构
• 分布式集合(分区)

SparkSQL 其实有3类数据抽象对象
• SchemaRDD对象(已废弃)
• DataSet对象:可用于Java、Scala语言
• DataFrame对象:可用于Java、Scala、Python、R
以Python开发SparkSQL,主要使用的就是DataFrame对象作为核心数据结构
DataFrame概述
RDD:有分区的、弹性的、分布式的、存储任意结构数据
DataFrame:有分区的、弹性的、分布式的、存储二维表结构数据
DataFrame和RDD都是:弹性的、分布式的、数据集。只是,DataFrame存储的数据结构“限定”为:二维表结构化数据;而RDD可以存储的数据则没有任何限制,想处理什么就处理什么。
假定有如下数据集
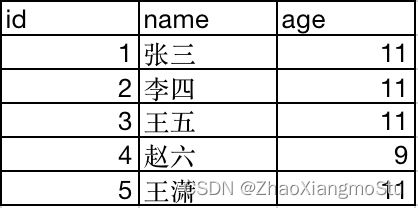
DataFrame按二维表格存储

RDD按数组对象存储

SparkSession对象
在RDD阶段,程序的执行入口对象是: SparkContext
在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
SparkSession对象可以:
- 用于SparkSQL编程作为入口对象
- 用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext
所以,后续的代码,执行环境入口对象,统一变更为SparkSession对象
构建SparkSession核心代码
有如下数据集:列1ID,列2学科,列3分数

数据集文件:资料\data\sql\stu_score.txt
需求:读取文件,找出学科为“语文”的数据,并限制输出5条where subject = '语文' limit 5
代码如下:
# coding:utf8# SparkSession对象的导包, 对象是来自于 pyspark.sql包中
from pyspark.sql import SparkSessionif __name__ == '__main__':# 构建SparkSession执行环境入口对象spark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()# 通过SparkSession对象 获取 SparkContext对象sc = spark.sparkContext# SparkSQL的HelloWorlddf = spark.read.csv("../data/input/stu_score.txt", sep=',', header=False)df2 = df.toDF("id", "name", "score")df2.printSchema()df2.show()df2.createTempView("score")# SQL 风格spark.sql("""SELECT * FROM score WHERE name='语文' LIMIT 5""").show()# DSL 风格df2.where("name='语文'").limit(5).show()
SparkSQL 和 Hive同样,都是用于大规模SQL分布式计算的计算框架,均可以运行在YARN之上,在企业中广泛被应用。
SparkSQL的数据抽象为:SchemaRDD(废弃)、DataFrame(Python、R、Java、Scala)、DataSet(Java、Scala)。
DataFrame同样是分布式数据集,有分区可以并行计算,和RDD不同的是,DataFrame中存储的数据结构是以表格形式组织的,方便进行SQL计算。
DataFrame对比DataSet基本相同,不同的是DataSet支持泛型特性,可以让Java、Scala语言更好的利用到。
SparkSession是2.0后退出的新执行环境入口对象,可以用于RDD、SQL等编程。
DataFrame的组成
DataFrame是一个二维表结构, 那么表格结构就有无法绕开的三个点:
• 行
• 列
• 表结构描述
比如,在MySQL中的一张表:
• 由许多行组成
• 数据也被分成多个列
• 表也有表结构信息(列、列名、列类型、列约束等)
基于这个前提,DataFrame的组成如下:
在结构层面:
- StructType对象描述整个DataFrame的表结构
- StructField对象描述一个列的信息
在数据层面:
- Row对象记录一行数据
- Column对象记录一列数据并包含列的信息
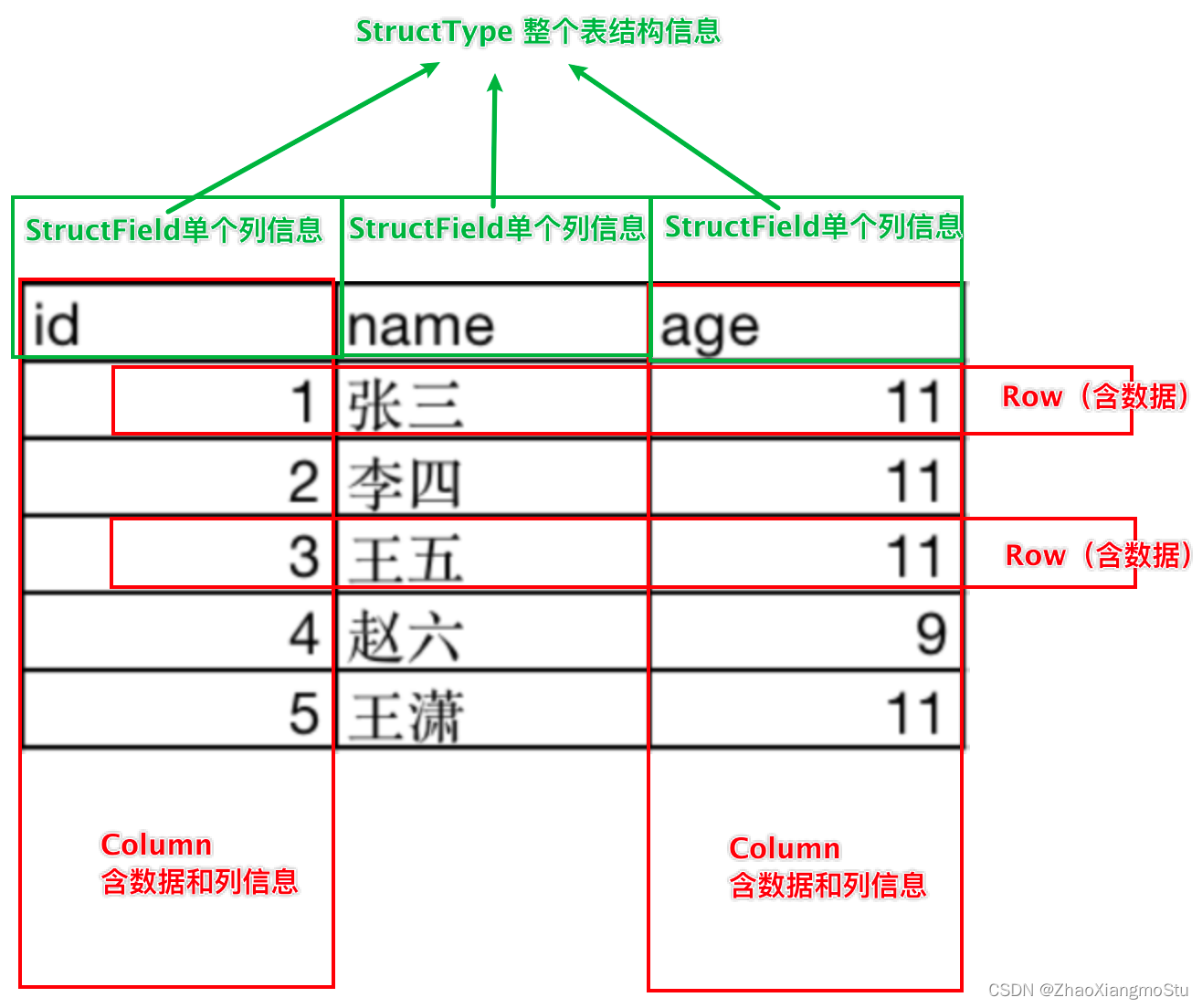
如图, 在表结构层面,DataFrame的表结构由:
StructType描述,如下图

一个StructField记录:列名、列类型、列是否运行为空
多个StructField组成一个StructType对象。
一个StructType对象可以描述一个DataFrame:有几个列、每个列的名字和类型、每个列是否为空。同时,一行数据描述为Row对象,如Row(1, 张三, 11)
一列数据描述为Column对象,Column对象包含一列数据和列的信息
DataFrame的代码构建 - 基于RDD方式1
DataFrame对象可以从RDD转换而来,都是分布式数据集,其实就是转换一下内部存储的结构,转换为二维表结构。
通过SparkSession对象的createDataFrame方法来将RDD转换为DataFrame
这里只传入列名称,类型从RDD中进行推断,是否允许为空默认为允许(True)
# coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于RDD转换成DataFramerdd = sc.textFile("../data/input/sql/people.txt").\map(lambda x: x.split(",")).\map(lambda x: (x[0], int(x[1])))# 构建DataFrame对象# 参数1 被转换的RDD# 参数2 指定列名, 通过list的形式指定, 按照顺序依次提供字符串名称即可df = spark.createDataFrame(rdd, schema=['name', 'age'])# 打印DataFrame的表结构df.printSchema()# 打印df中的数据# 参数1 表示 展示出多少条数据, 默认不传的话是20# 参数2 表示是否对列进行截断, 如果列的数据长度超过20个字符串长度, 后续的内容不显示以...代替# 如果给False 表示不阶段全部显示, 默认是Truedf.show(20, False)# 将DF对象转换成临时视图表, 可供sql语句查询df.createOrReplaceTempView("people")spark.sql("SELECT * FROM people WHERE age < 30").show()
DataFrame的代码构建 - 基于RDD方式2
通过StructType对象来定义DataFrame的“表结构”转换RDD
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于RDD转换成DataFramerdd = sc.textFile("../data/input/sql/people.txt").\map(lambda x: x.split(",")).\map(lambda x: (x[0], int(x[1])))# 构建表结构的描述对象: StructType对象schema = StructType().add("name", StringType(), nullable=True).\add("age", IntegerType(), nullable=False)# 基于StructType对象去构建RDD到DF的转换df = spark.createDataFrame(rdd, schema=schema)df.printSchema()df.show()
使用RDD的toDF方法转换RDD
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于RDD转换成DataFramerdd = sc.textFile("../data/input/sql/people.txt").\map(lambda x: x.split(",")).\map(lambda x: (x[0], int(x[1])))# toDF的方式构建DataFramedf1 = rdd.toDF(["name", "age"])df1.printSchema()df1.show()# toDF的方式2 通过StructType来构建schema = StructType().add("name", StringType(), nullable=True).\add("age", IntegerType(), nullable=False)df2 = rdd.toDF(schema=schema)df2.printSchema()df2.show()
将Pandas的DataFrame对象,转变为分布式的SparkSQL DataFrame对象
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于Pandas的DataFrame构建SparkSQL的DataFrame对象pdf = pd.DataFrame({"id": [1, 2, 3],"name": ["张大仙", "王晓晓", "吕不为"],"age": [11, 21, 11]})df = spark.createDataFrame(pdf)df.printSchema()df.show()
DataFrame的代码构建 - 读取外部数据
通过SparkSQL的统一API进行数据读取构建DataFrame
统一API示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 构建StructType, text数据源, 读取数据的特点是, 将一整行只作为`一个列`读取, 默认列名是value 类型是Stringschema = StructType().add("data", StringType(), nullable=True)df = spark.read.format("text").\schema(schema=schema).\load("../data/input/sql/people.txt")df.printSchema()df.show()
读取text数据源:使用format(“text”)读取文本数据,读取到的DataFrame只会有一个列,列名默认称之为:value
schema = StructType().add("data", StringType(), nullable=True)
df = spark.read.format("text")\
.schema(schema)\
.load("../data/sql/people.txt")读取json数据源
使用format(“json”)读取json数据
示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# JSON类型自带有Schema信息df = spark.read.format("json").load("../data/input/sql/people.json")df.printSchema()df.show()
读取csv数据源
使用format(“csv”)读取csv数据
示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 读取CSV文件df = spark.read.format("csv").\option("sep", ";").\option("header", True).\option("encoding", "utf-8").\schema("name STRING, age INT, job STRING").\load("../data/input/sql/people.csv")df.printSchema()df.show()
读取parquet数据源
使用format(“parquet”)读取parquet数据
parquet: 是Spark中常用的一种列式存储文件格式。和Hive中的ORC差不多, 他俩都是列存储格式。parquet对比普通的文本文件的区别:
● parquet 内置schema (列名\ 列类型\ 是否为空)
● 存储是以列作为存储格式
● 存储是序列化存储在文件中的(有压缩属性体积小)
Parquet文件不能直接打开查看,如果想要查看内容,可以在PyCharm中安装如下插件来查看:
示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 读取parquet类型的文件df = spark.read.format("parquet").load("../data/input/sql/users.parquet")df.printSchema()df.show()
DataFrame的入门操作
DataFrame支持两种风格进行编程,分别是:
• DSL风格
• SQL风格
DSL语法风格
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如:df.where().limit()
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据
比如:spark.sql(“SELECT * FROM xxx)
DSL - show 方法
功能:展示DataFrame中的数据, 默认展示20条
语法:
df.show(参数1, 参数2)
- 参数1: 默认是20, 控制展示多少条
- 参数2: 是否阶段列, 默认只输出20个字符的长度, 过长不显示, 要显示的话 请填入 truncate = True
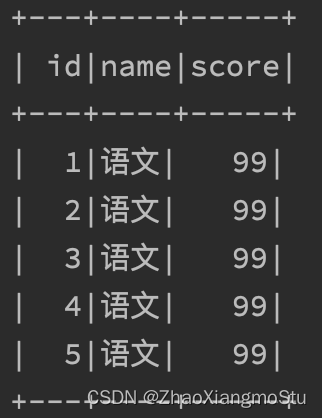
如图,某个df.show后的展示结果:
DSL - printSchema方法
功能:打印输出df的schema信息
语法:
df.printSchema()

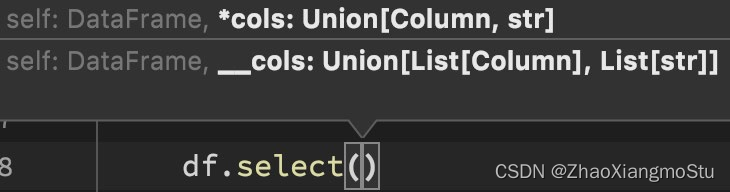
DSL - select
功能:选择DataFrame中的指定列(通过传入参数进行指定)
语法:
df.select()
可传递:
• 可变参数的cols对象,cols对象可以是Column对象来指定列或者字符串
列名来指定列
• List[Column]对象或者List[str]对象, 用来选择多个列
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
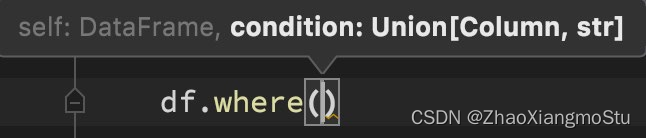
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContextdf = spark.read.format("csv").\schema("id INT, subject STRING, score INT").\load("../data/input/sql/stu_score.txt")# Column对象的获取id_column = df['id']subject_column = df['subject']# DLS风格演示df.select(["id", "subject"]).show()df.select("id", "subject").show()df.select(id_column, subject_column).show()DSL - filter和where
功能:过滤DataFrame内的数据,返回一个过滤后的DataFrame
语法:
df.filter()
df.where()
where和filter功能上是等价的
# filter APIdf.filter("score < 99").show()df.filter(df['score'] < 99).show()# where APIdf.where("score < 99").show()df.where(df['score'] < 99).show()DSL - groupBy 分组
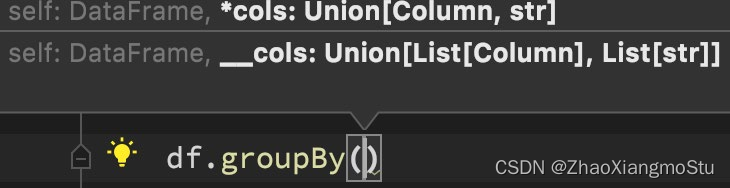
功能:按照指定的列进行数据的分组, 返回值是GroupedData对象
语法:
df.groupBy()
传入参数和select一样,支持多种形式,不管怎么传意思就是告诉spark按照哪个列分组
# group By APIdf.groupBy("subject").count().show()df.groupBy(df['subject']).count().show()GroupedData对象
GroupedData对象是一个特殊的DataFrame数据集
其类全名:<class 'pyspark.sql.group.GroupedData'>
这个对象是经过groupBy后得到的返回值, 内部记录了 以分组形式存储的数据
GroupedData对象其实也有很多API,比如前面的count方法就是这个对象的内置方法
除此之外,像:min、max、avg、sum、等等许多方法都存在
SQL风格语法 - 注册DataFrame成为表
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中
使用spark.sql() 来执行SQL语句查询,结果返回一个DataFrame。
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
# 注册成临时表df.createTempView("score") # 注册临时视图(表)df.createOrReplaceTempView("score_2") # 注册 或者 替换 临时视图df.createGlobalTempView("score_3") # 注册全局临时视图 全局临时视图在使用的时候 需要在前面带上global_temp. 前缀
SQL风格语法 - 使用SQL查询

# 可以通过SparkSession对象的sql api来完成sql语句的执行spark.sql("SELECT subject, COUNT(*) AS cnt FROM score GROUP BY subject").show()spark.sql("SELECT subject, COUNT(*) AS cnt FROM score_2 GROUP BY subject").show()spark.sql("SELECT subject, COUNT(*) AS cnt FROM global_temp.score_3 GROUP BY subject").show()pyspark.sql.functions 包
PySpark提供了一个包: pyspark.sql.functions
这个包里面提供了 一系列的计算函数供SparkSQL使用
如何用呢?
导包
from pyspark.sql import functions as F然后就可以用F对象调用函数计算了。
这些功能函数, 返回值多数都是Column对象。
词频统计案例练习
单词计数需求,使用DSL和SQL两种风格来实现。
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as Fif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# TODO 1: SQL 风格进行处理rdd = sc.textFile("../data/input/words.txt").\flatMap(lambda x: x.split(" ")).\map(lambda x: [x])df = rdd.toDF(["word"])# 注册DF为表格df.createTempView("words")spark.sql("SELECT word, COUNT(*) AS cnt FROM words GROUP BY word ORDER BY cnt DESC").show()# TODO 2: DSL 风格处理df = spark.read.format("text").load("../data/input/words.txt")# withColumn方法# 方法功能: 对已存在的列进行操作, 返回一个新的列, 如果名字和老列相同, 那么替换, 否则作为新列存在df2 = df.withColumn("value", F.explode(F.split(df['value'], " ")))df2.groupBy("value").\count().\withColumnRenamed("value", "word").\withColumnRenamed("count", "cnt").\orderBy("cnt", ascending=False).\show()
电影评分数据分析案例


# coding:utf8
import timefrom pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as Fif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 1. 读取数据集schema = StructType().add("user_id", StringType(), nullable=True).\add("movie_id", IntegerType(), nullable=True).\add("rank", IntegerType(), nullable=True).\add("ts", StringType(), nullable=True)df = spark.read.format("csv").\option("sep", "\t").\option("header", False).\option("encoding", "utf-8").\schema(schema=schema).\load("../data/input/sql/u.data")# TODO 1: 用户平均分df.groupBy("user_id").\avg("rank").\withColumnRenamed("avg(rank)", "avg_rank").\withColumn("avg_rank", F.round("avg_rank", 2)).\orderBy("avg_rank", ascending=False).\show()# TODO 2: 电影的平均分查询df.createTempView("movie")spark.sql("""SELECT movie_id, ROUND(AVG(rank), 2) AS avg_rank FROM movie GROUP BY movie_id ORDER BY avg_rank DESC""").show()# TODO 3: 查询大于平均分的电影的数量 # Rowprint("大于平均分电影的数量: ", df.where(df['rank'] > df.select(F.avg(df['rank'])).first()['avg(rank)']).count())# TODO 4: 查询高分电影中(>3)打分次数最多的用户, 此人打分的平均分# 先找出这个人user_id = df.where("rank > 3").\groupBy("user_id").\count().\withColumnRenamed("count", "cnt").\orderBy("cnt", ascending=False).\limit(1).\first()['user_id']# 计算这个人的打分平均分df.filter(df['user_id'] == user_id).\select(F.round(F.avg("rank"), 2)).show()# TODO 5: 查询每个用户的平局打分, 最低打分, 最高打分df.groupBy("user_id").\agg(F.round(F.avg("rank"), 2).alias("avg_rank"),F.min("rank").alias("min_rank"),F.max("rank").alias("max_rank")).show()# TODO 6: 查询评分超过100次的电影, 的平均分 排名 TOP10df.groupBy("movie_id").\agg(F.count("movie_id").alias("cnt"),F.round(F.avg("rank"), 2).alias("avg_rank")).where("cnt > 100").\orderBy("avg_rank", ascending=False).\limit(10).\show()time.sleep(10000)"""
1. agg: 它是GroupedData对象的API, 作用是 在里面可以写多个聚合
2. alias: 它是Column对象的API, 可以针对一个列 进行改名
3. withColumnRenamed: 它是DataFrame的API, 可以对DF中的列进行改名, 一次改一个列, 改多个列 可以链式调用
4. orderBy: DataFrame的API, 进行排序, 参数1是被排序的列, 参数2是 升序(True) 或 降序 False
5. first: DataFrame的API, 取出DF的第一行数据, 返回值结果是Row对象.
# Row对象 就是一个数组, 你可以通过row['列名'] 来取出当前行中, 某一列的具体数值. 返回值不再是DF 或者GroupedData 或者Column而是具体的值(字符串, 数字等)
"""
SparkSQL Shuffle 分区数目
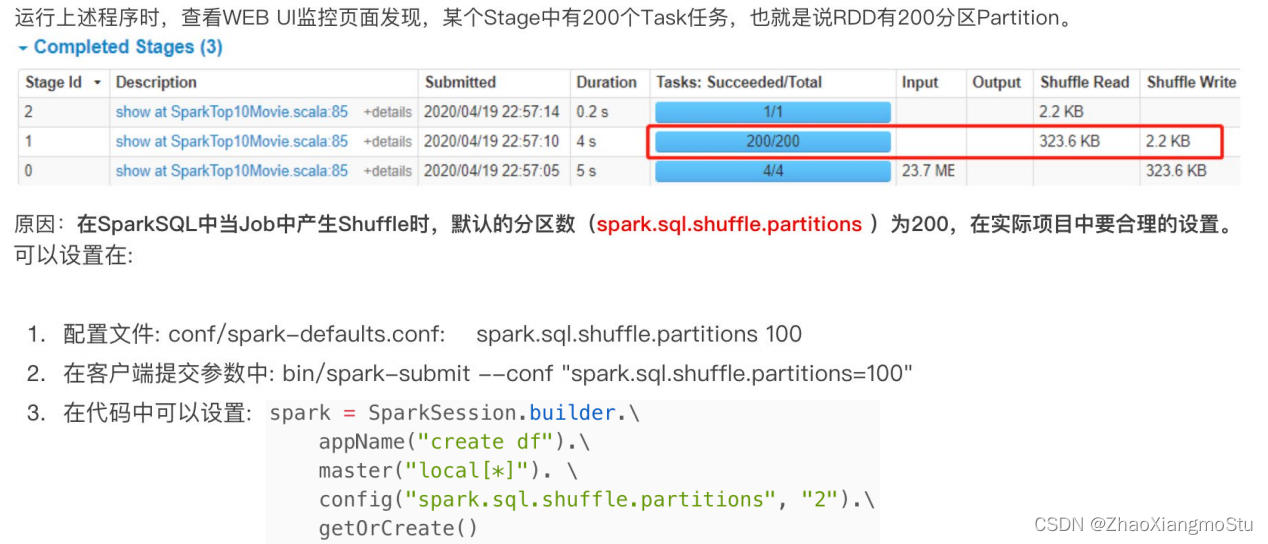
# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\config("spark.sql.shuffle.partitions", 2).\getOrCreate()sc = spark.sparkContext"""spark.sql.shuffle.partitions 参数指的是, 在sql计算中, shuffle算子阶段默认的分区数是200个.对于集群模式来说, 200个默认也算比较合适如果在local下运行, 200个很多, 在调度上会带来额外的损耗所以在local下建议修改比较低 比如2\4\10均可这个参数和Spark RDD中设置并行度的参数 是相互独立的."""SparkSQL 数据清洗API

df.dropDuplicates().show()df.dropDuplicates(['age', 'job']).show() 
df.dropna().show()# # thresh = 3表示, 最少满足3个有效列, 不满足 就删除当前行数据df.dropna(thresh=3).show()df.dropna(thresh=2, subset=['name', 'age']).show()
# 缺失值处理也可以完成对缺失值进行填充# DataFrame的 fillna 对缺失的列进行填充df.fillna("loss").show()# 指定列进行填充df.fillna("N/A", subset=['job']).show()# 设定一个字典, 对所有的列 提供填充规则df.fillna({"name": "未知姓名", "age": 1, "job": "worker"}).show()DataFrame数据写出



# Write text 写出, 只能写出一个列的数据, 需要将df转换为单列dfdf.select(F.concat_ws("---", "user_id", "movie_id", "rank", "ts")).\write.\mode("overwrite").\format("text").\save("../data/output/sql/text")# Write csvdf.write.mode("overwrite").\format("csv").\option("sep", ";").\option("header", True).\save("../data/output/sql/csv")# Write jsondf.write.mode("overwrite").\format("json").\save("../data/output/sql/json")# Write parquetdf.write.mode("overwrite").\format("parquet").\save("../data/output/sql/parquet")DataFrame 通过JDBC读写数据库(MySQL示例)
# 1. 写出df到mysql数据库中df.write.mode("overwrite").\format("jdbc").\option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true").\option("dbtable", "movie_data").\option("user", "root").\option("password", "2212072ok1").\save()

# 2. 从mysql数据库中读dfdf2 = spark.read.format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true"). \option("dbtable", "movie_data"). \option("user", "root"). \option("password", "2212072ok1"). \load()
DataFrame 在结构层面上由StructField组成列描述,由StructType构造表描述。在数据层面上,Column对象记录列数据,Row对象记录行数据。
DataFrame可以从RDD转换、Pandas DF转换、读取文件、读取JDBC等方法构建。
spark.read.format()和df.write.format() 是DataFrame读取和写出的统一化标准API。
SparkSQL默认在Shuffle阶段200个分区,可以修改参数获得最好性能。
dropDuplicates可以去重、dropna可以删除缺失值、fillna可以填充缺失值。
SparkSQL支持JDBC读写,可用标准API对数据库进行读写操作。