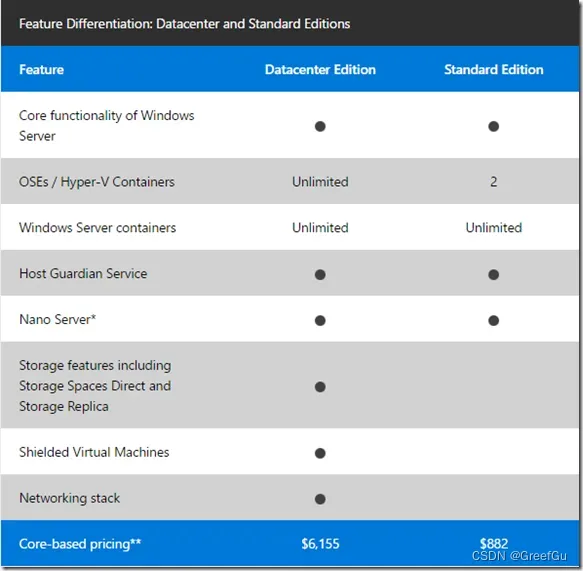
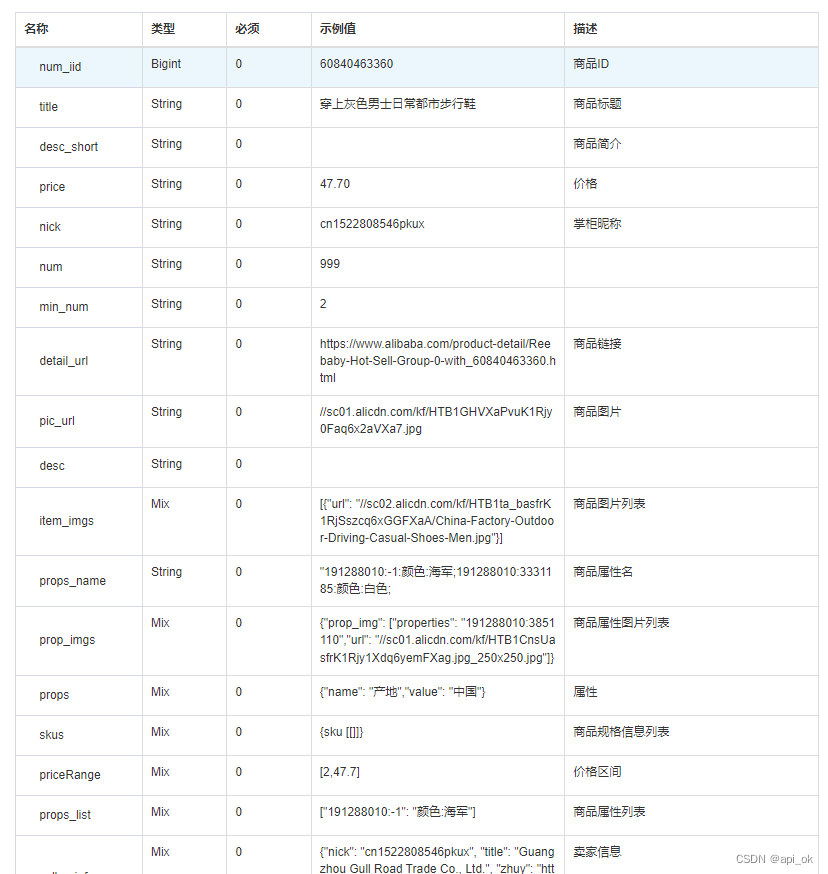
【数据清洗】
异常检测
孤立森林(Isolation Forest)从原理到实践
效果评估:F-score
【1】 保护隐私的时间序列异常检测架构
概率后缀树 PST – (异常检测)
【1】 UEBA架构设计之路5: 概率后缀树模型
【2】 基于深度模型的日志序列异常检测
【3】 史上最全异常检测算法概述
后缀树 – (最长公共子串)
【1】 【1】 【1】 【1】 【1】后缀树 - 字符串问题
【2】 后缀树应用5 – 最长的公共子字符串
【2】 【2】后缀树构造、C++代码
【3】 python库 suffix_tree

风控
【1】 风控策略产品经理:案例蚂蚁金服-支付宝的风控策略(浅析)
一致性检测
【1】 【推荐】样本/数据一致性检验的方法:Kappa检验、ICC组内相关系数、Kendall W协调系数
【2】 一致性检验 Kappa、Kendell


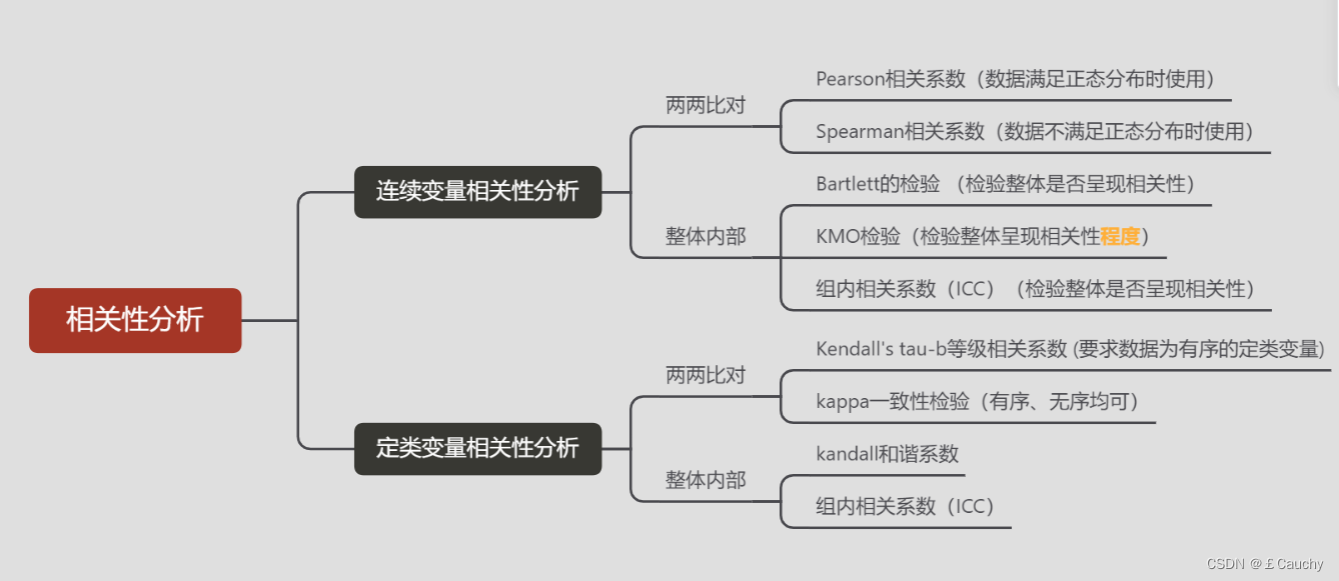
冲突识别
【时间序列预测分析】
AR / MA / ARMA / GARCH 模型
- AR模型:自回归模型,是一种线性模型.AR模型是一种线性预测,即已知N个数据,可由模型推出第N点前面或后面的数据(设推出P点),所以其本质类似于插值。
- MA模型:移动平均法模型,其中使用趋势移动平均法建立直线趋势的预测模型。
- ARMA模型:自回归滑动平均模型,拟合较高阶模型。模型参量法高分辨率谱分析方法之一。这种方法是研究平稳随机过程有理谱的典型方法。它比AR模型法与MA模型法有较精确的谱估计及较优良的谱分辨率性能,但其参数估算比较繁琐。
- GARCH模型:广义回归模型,是ARCH模型的拓展,对误差的方差建模,适用于波动性的分析和预测。
SARIMA 模型 (seasonal ARIMA)
用Python预测「周期性时间序列」的正确姿势
SARIMA季节项时间序列分析流程+python代码:模型定阶 枚举法
Python - 时序
- pandas处理时间序列(2):DatetimeIndex、索引和选择、含有重复索引的时间序列、日期范围与频率和移位、时间区间和区间算术
- seasonal_order定阶
【A/B 实验】
【1】 干货!22道AB实验面试题,涵盖95%常考知识点『中篇』
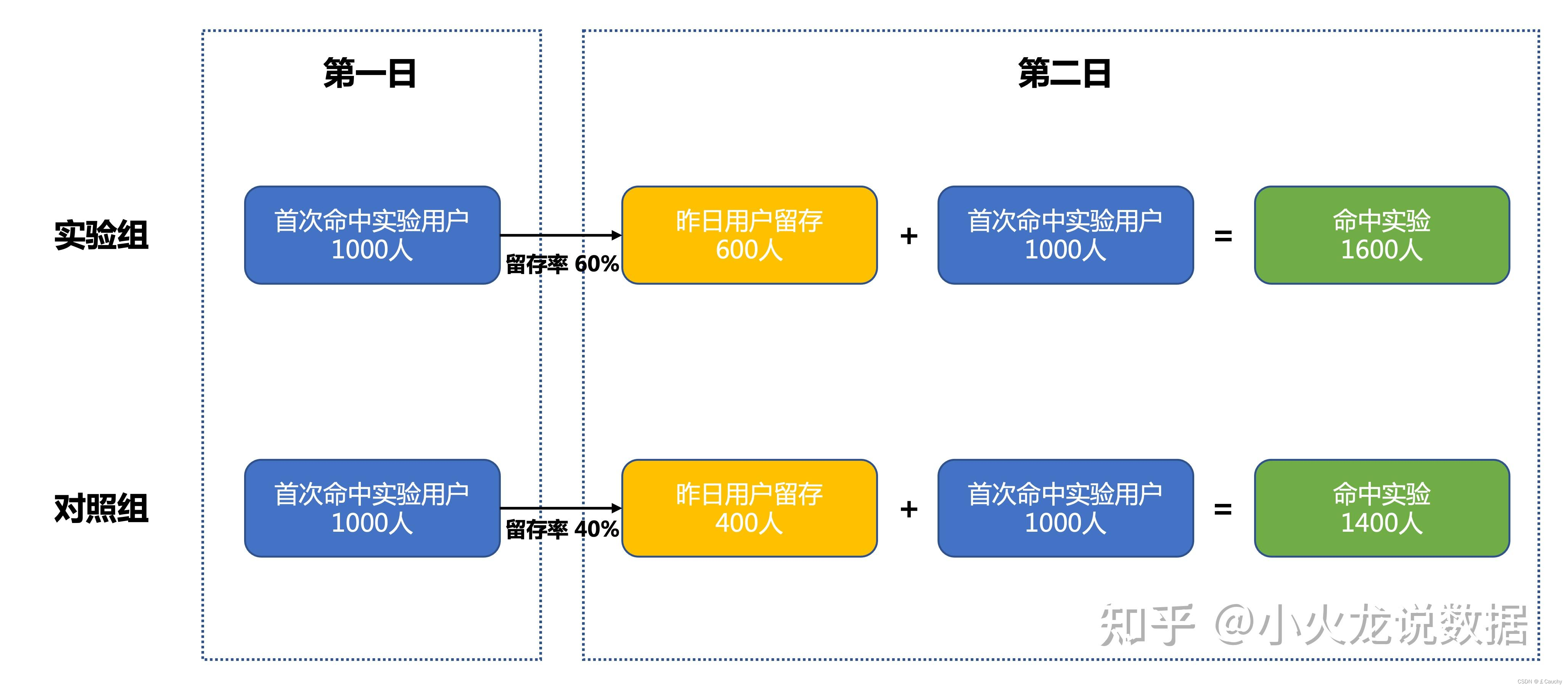
累计去重口径
Q:在进行AB实验评估时,选择指标的「累计去重口径」还是「非累计去重口径」更为科学呢?
A:答案是「累计去重口径」,在分组用户均衡的情况下,累计去重口径可以保证样本量的均衡,不会受到实验策略对留存的干扰,避免用户出现有偏的情况。
举个例子:
第一日来了100个用户,第二日来了100个用户,两日中有50个用户是重复的。
两日累计去重口径用户数 = 100+100-50=150
两日非累计去重口径用户数 = 100+100=200人。
实验周期的确定
最小样本量 = 每天进入实验的样本量 × 实验天数
= (实验层的总流量 × 实验流量占比) × 实验天数
在实际的业务操作过程当中,业务都存在一些效应,例如新奇效应、改变厌恶等等,另外我们也需要考虑一个完整的业务周期,因为就大多数APP而言,周中和周末的人群行为表现是存在差异的,因此我们一般会尽量通过调整实验流量配比来满足7天的实验天数。
第八章 【集成学习】
【1】
1. (串行 - 偏差)【Boosting算法】 – Adaboost

boosting的算法过程如下:
对于训练集中的每个样本建立权值wi,表示对每个样本的关注度。当某个样本被误分类的概率很高时,需要加大对该样本的权值。
进行迭代的过程中,每一步迭代都是一个弱分类器。我们需要用某种策略将其组合,作为最终模型。(例如AdaBoost给每个弱分类器一个权值,将其线性组合最为最终分类器。误差越小的弱分类器,权值越大)
2. (并行 - 方差)【Bagging算法】
【1】【2】
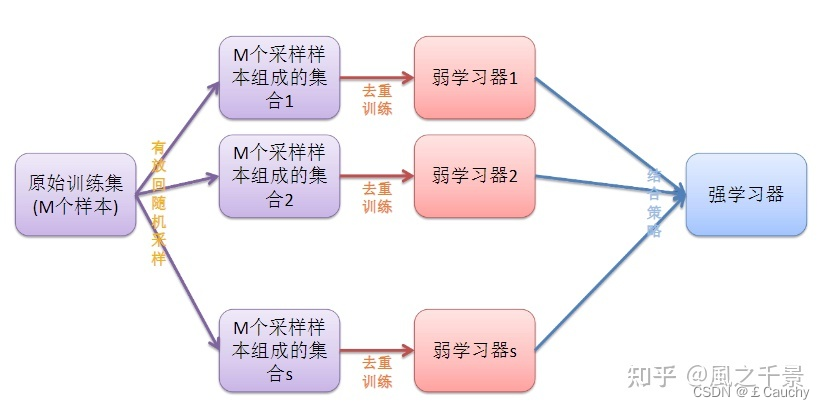
bagging的算法过程如下:
从原始样本集中使用Bootstraping方法(自助法,是一种有放回的抽样方法)随机抽取n个训练样本,共进行k轮抽取,得到k个训练集。(k个训练集之间相互独立,元素可以有重复)
对于k个训练集,我们训练k个模型。(这k个模型可以根据具体问题而定,比如决策树等)
对于分类问题:由投票表决产生分类结果;对于回归问题:由k个模型预测结果的均值作为最后预测结果。(所有模型的重要性相同)
随机森林
- 优点
1) 训练可以高度并行化,对于大数据时代的大样本训练速度有优势。个人觉得这是的最主要的优点。
2) 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
3) 在训练后,可以给出各个特征对于输出的重要性
4) 由于采用了随机采样,训练出的模型的方差小,泛化能力强。
5) 相对于Boosting系列的Adaboost和GBDT, RF实现比较简单。
6) 对部分特征缺失不敏感。
- 缺点
1)在某些噪音比较大的样本集上,RF模型容易陷入过拟合。
2) 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
3. Adaboost & Bagging 区别
1)样本选择:
Bagging采用的是Bootstrap随机有放回抽样;
Boosting每一轮的训练集是不变的,改变的只是每一个样本的权重。
2)样本权重:
Bagging使用的是均匀取样,每个样本权重相等;
Boosting根据错误率调整样本权重,错误率越大的样本权重越大。
3)预测函数:
Bagging所有的预测函数的权重相等;
Boosting中误差越小的预测函数其权重越大。
4)并行计算:
Bagging各个预测函数可以并行生成,不存在强依赖关系;
Boosting各个预测函数必须按顺序迭代生成,存在强依赖关系。
5)计算效果:
Bagging主要减小了variance,Boosting主要减小了bias,而这种差异直接推动结合二者的MultiBoosting的诞生
下面是将决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
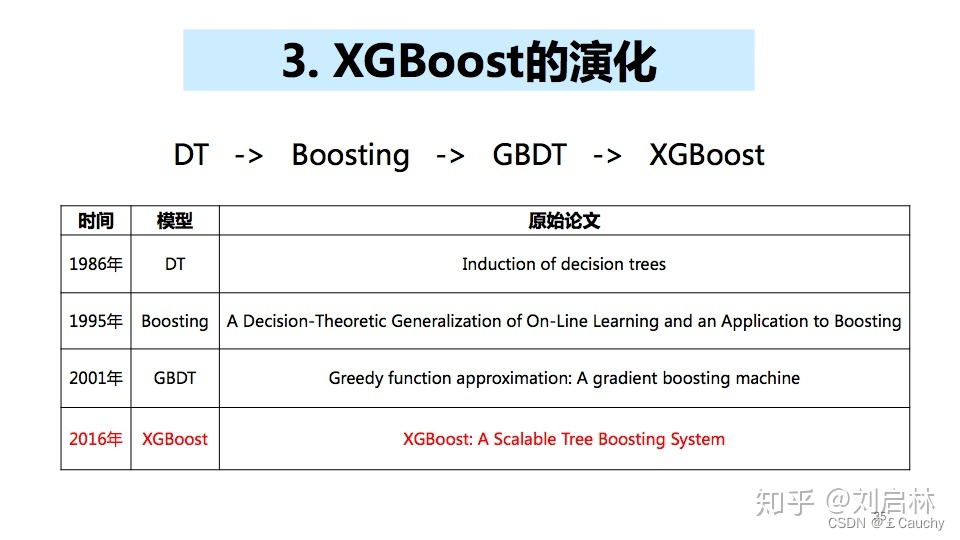
*)GBDT vs XGBoost (eXtreme Gradient Boosting)极致梯度提升:基本思想相同,但是XGBoost做了一些优化,比如二阶导数使损失函数更精准;正则项避免树过拟合;Block存储可以并行计算等。

第九章 【高斯过程】
【1】
【2】
第十章 【半监督学习】
1. 协同训练(多视图半监督)

2. 图 · 半监督
3. 半监督SVM
【1】【2】
直推式支持向量机「TSVM」与半监督支持向量机「S3VM」:
- S3VM 基于聚类假设,试图通过探索未标记数据来规范、调整决策边界,为了利用未标记的数据,则需要在现有的支持向量机「SVM」上,增加两个对未标记的数据点限制。
- TSVM 主要用于二分类问题,其试图考虑对未标记样本进行可能的标记指标(Label Assignment),即尝试将每个未标记样本分别作为正例或反例,并在对应的结果中寻求间隔最大化的划分超平面
第十章 【神经网络 & 深度学习】
4. 卷积神经网络 CNN
【1】Sigmoid和Relu激活函数的对比
第十二章 【强化学习】
【1】
Q-learning
【激活函数】
【1】 python:激活函数及其导数画图sigmoid/tanh/relu/Leakyrelu/swish/hardswish/hardsigmoid
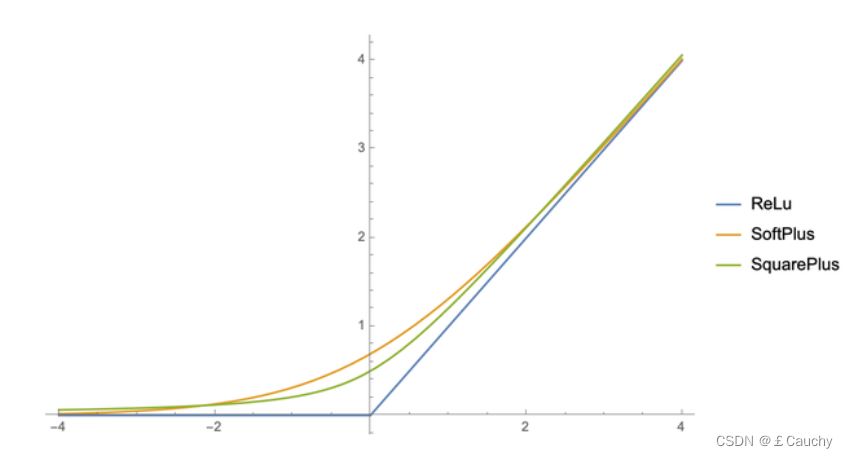
【2】 SquarePlus:可能是运算最简单的ReLU光滑近似
- R e L u = m a x { 0 , x } ReLu = max\{0,x\} ReLu=max{0,x}
- S o f t P l u s = l o g ( e x + 1 ) SoftPlus = log(e^x+1) SoftPlus=log(ex+1)
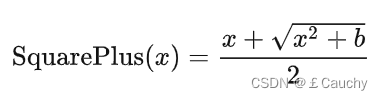
经典面试题目
数据分析
机器学习
集成学习
【1】 珍藏版 | 20道XGBoost面试题
【2】 机器学习算法之XGBoost
决策树\RF\XGB\GBDT之间的关系