Spring 怎么解决循环依赖
- 什么是循环依赖
- 那 Spring 怎么解决循环依赖的呢?
- 为什么要三级缓存?⼆级不⾏吗?
什么是循环依赖
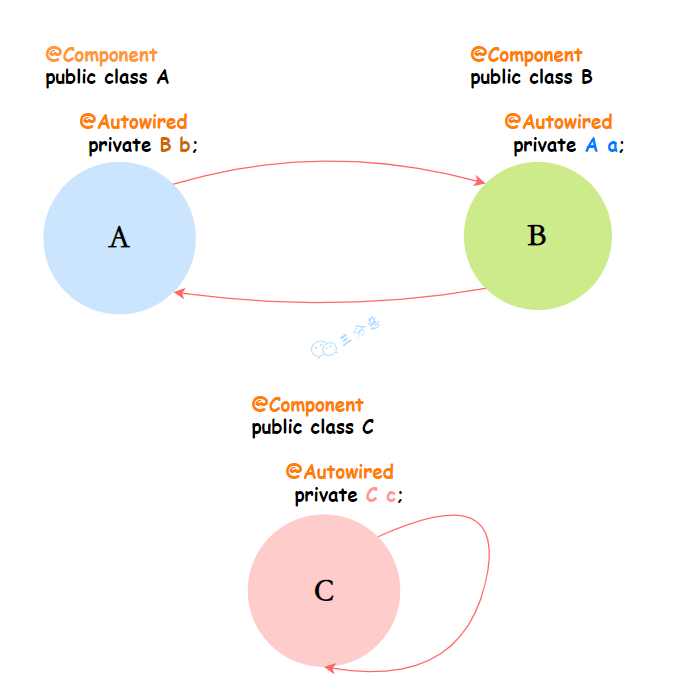
Spring 循环依赖:简单说就是自己依赖自己,或者和别的 Bean 相互依赖。
只有单例的 Bean 才存在循环依赖的情况,原型(Prototype)情况下,Spring 会直接抛出异常。原因很简单,AB 循环依赖,A 实例化的时候,发现依赖 B,创建 B 实例,创建 B 的时候发现需要 A,创建 A1 实例……无限套娃,直接把系统干垮。
Spring 可以解决哪些情况的循环依赖?
Spring 不支持基于构造器注入的循环依赖,但是假如 AB 循环依赖,如果一个是构造器注入,一个是 setter 注入呢?
看看几种情形:

第四种可以而第五种不可以的原因是 Spring 在创建 Bean 时默认会根据自然排序进行创建,所以 A 会先于 B 进行创建。
所以简单总结,当循环依赖的实例都采用 setter 方法注入的时候,Spring 可以支持,都采用构造器注入的时候,不支持,构造器注入和 setter 注入同时存在的时候,看天。
那 Spring 怎么解决循环依赖的呢?
我们都知道,单例 Bean 初始化完成,要经历三步:
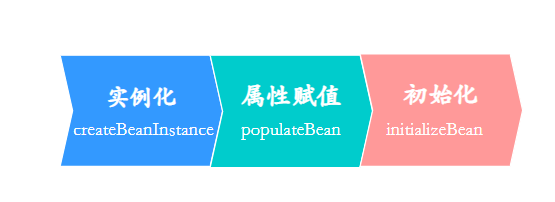
注入就发生在第二步,属性赋值,结合这个过程,Spring 通过三级缓存解决了循环依赖:
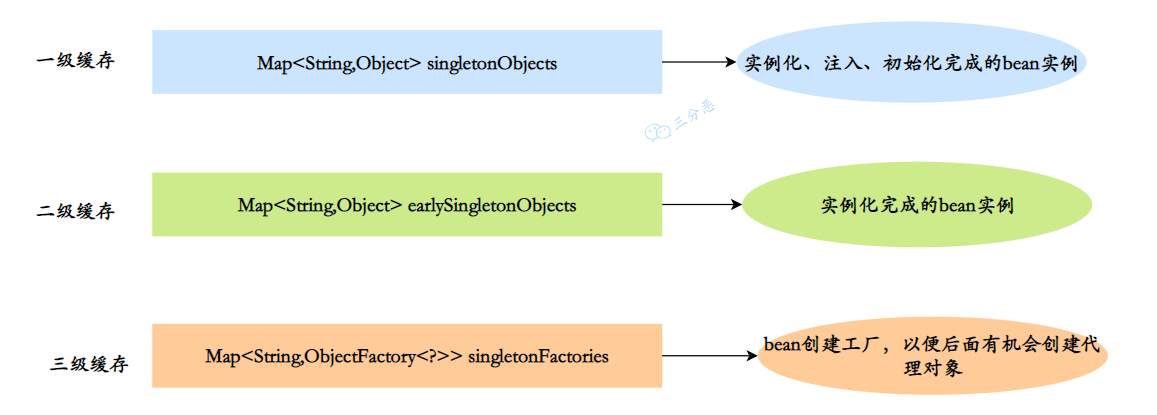
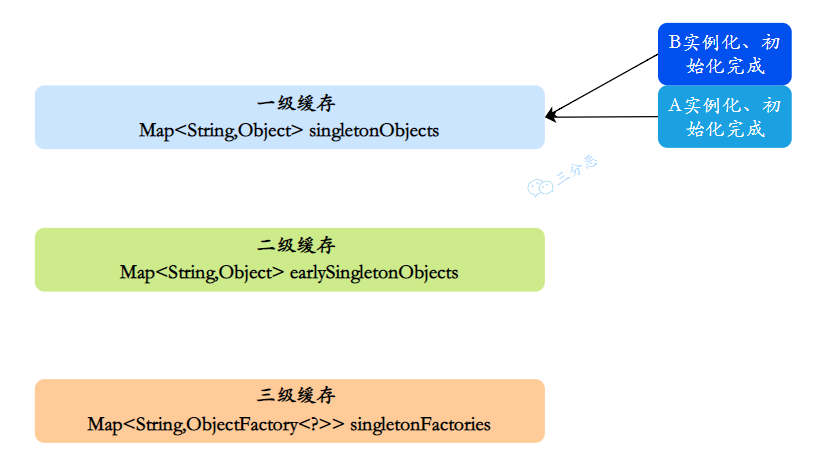
- 一级缓存 :
MapsingletonObjects,单例池,用于保存实例化、属性赋值(注入)、初始化完成的 bean 实例 - 二级缓存 :
MapearlySingletonObjects,早期曝光对象,用于保存实例化完成的 bean 实例 - 三级缓存 :
Map>singletonFactories,早期曝光对象工厂,用于保存 bean 创建工厂,以便于后面扩展有机会创建代理对象。
我们来看一下三级缓存解决循环依赖的过程:
当 A、B 两个类发生循环依赖时: 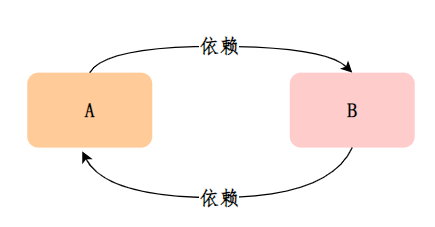
A 实例的初始化过程:
- 创建 A 实例,实例化的时候把 A 对象⼯⼚放⼊三级缓存,表示 A 开始实例化了,虽然我这个对象还不完整,但是先曝光出来让大家知道

- A 注⼊属性时,发现依赖 B,此时 B 还没有被创建出来,所以去实例化 B
- 同样,B 注⼊属性时发现依赖 A,它就会从缓存里找 A 对象。依次从⼀级到三级缓存查询 A,从三级缓存通过对象⼯⼚拿到 A,发现 A 虽然不太完善,但是存在,把 A 放⼊⼆级缓存,同时删除三级缓存中的 A,此时,B 已经实例化并且初始化完成,把 B 放入⼀级缓存。
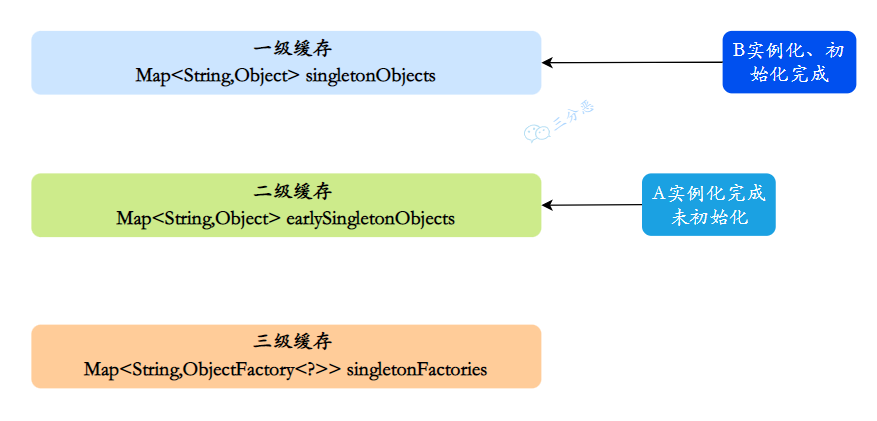
- 接着 A 继续属性赋值,顺利从⼀级缓存拿到实例化且初始化完成的 B 对象,A 对象创建也完成,删除⼆级缓存中的 A,同时把 A 放⼊⼀级缓存
- 最后,⼀级缓存中保存着实例化、初始化都完成的 A、B 对象
所以,我们就知道为什么 Spring 能解决 setter 注入的循环依赖了,因为实例化和属性赋值是分开的,所以里面有操作的空间。如果都是构造器注入的化,那么都得在实例化这一步完成注入,所以自然是无法支持了。
为什么要三级缓存?⼆级不⾏吗?
不行,主要是为了⽣成代理对象。如果是没有代理的情况下,使用二级缓存解决循环依赖也是 OK 的。但是如果存在代理,三级没有问题,二级就不行了。
因为三级缓存中放的是⽣成具体对象的匿名内部类,获取 Object 的时候,它可以⽣成代理对象,也可以返回普通对象。使⽤三级缓存主要是为了保证不管什么时候使⽤的都是⼀个对象。
假设只有⼆级缓存的情况,往⼆级缓存中放的显示⼀个普通的 Bean 对象,Bean 初始化过程中,通过 BeanPostProcessor 去⽣成代理对象之后,覆盖掉⼆级缓存中的普通 Bean 对象,那么可能就导致取到的 Bean 对象不一致了。