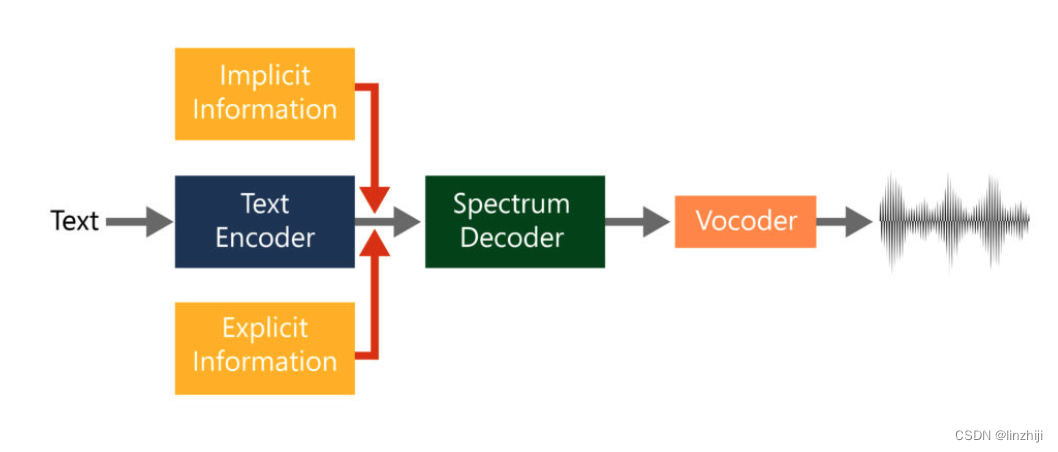
写在前面,最近一阵在做视频分类相关的工作,趁有时间来记录一下。本文更注重项目实战与落地,而非重点探讨多模/视频模型结构的魔改
零、背景
- 目标:通过多模态内容理解技术,构建视频层级分类体系
- 原技术方案:
a. 分别用 inception-Resnetv2/bert/vggish处理视觉/文本/音频特征,再用 netvlad 处理时序特征,再用 AFM/self-attention融合各模态信息
b. 方案缺点很明显,1)模块太多,维护成本太高;2)各模块独立训练,用每个模块最优的模型组合起来未必效果最好,如何选择各合适的模块不好确定 - 新技术方案:
a. attenion 一把梭,各种模态的信息直接送入类 bert 去处理,利用对比学习模型 cn-clip 提升视觉与文本对齐能力,采用 mlm、itc 、itm、mmm等多种预训练任务增强模态间交互,结合 rdrop、fgm等训练算法提升泛化性能,使用知识蒸馏与难例挖掘等手段提升样本标出率,借助 class balance 与 label smoothing 改善类别不均衡问题
b. 新方案效果提升明显,模块也少,维护起来成本也低
c. 新方案为 2022 某视频分类比赛第 8 名
一、技术手段
1、模型方面
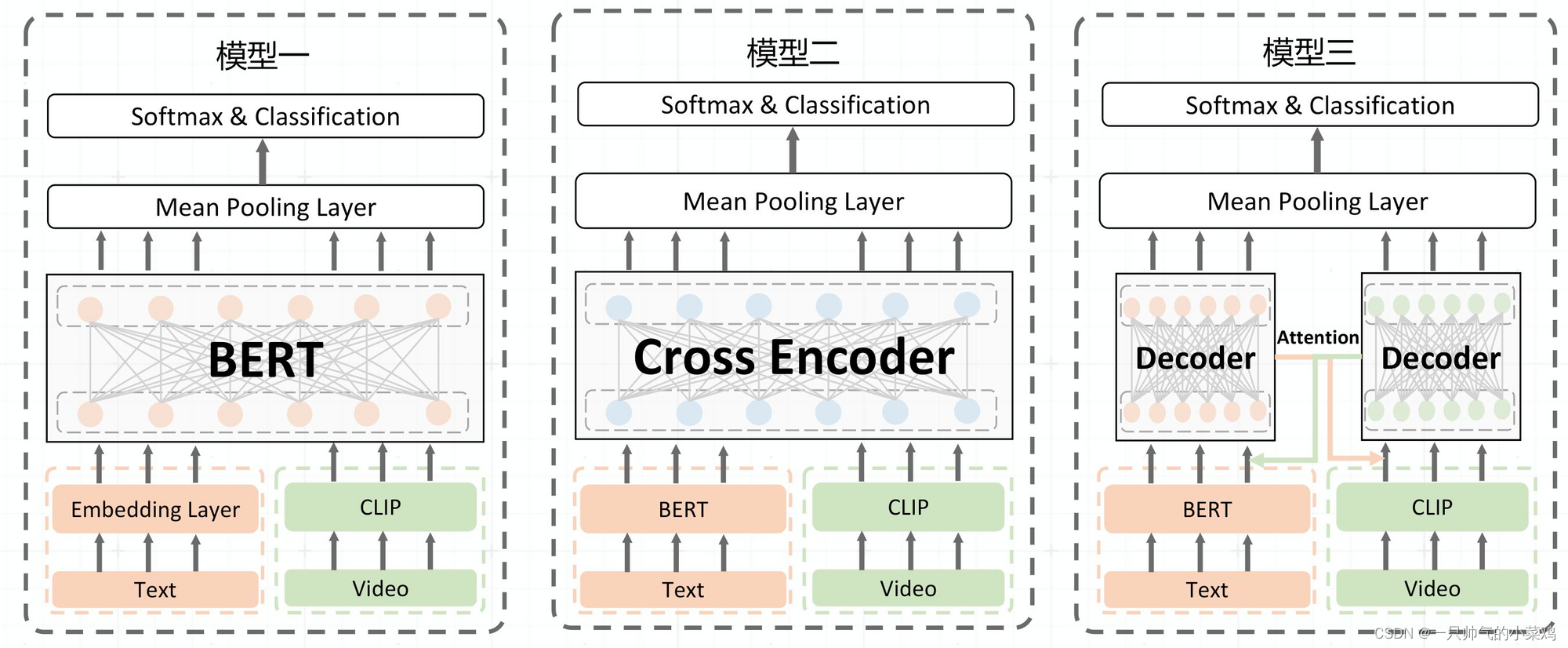
1)单流模型
-
结构:模型一
- 文本过embedding层,视频过zn_clip的vit,然后拼接起来送入bert,最后mean pooing后接分类层
-
优点:
- 架构简单、预训练好做,参数少
服务性能:a10卡,vit + bert 的 qps =9 左右
2)双流模型:
- 结构:
- 模型二:文本过bert,视频过clip,然后将视频向量和文本向量拼接起来,再过一个transformer,mean pooing后接分类层
- 模型三,文本过bert,视频过clip,得到视频向量和文本向量,然后做cross attention,即对于视频向量,用文本向量作为Q进行注意力加权,而对于文本向量,用视频向量作为Q进行注意力加权,最后mean pooing后接分类层
- 优点:
- 相当于一种后融合,先让每个模态单独学更好的特征,再去做融合,效果理论上也会更好
3)训练 tricks
-
训练手段
1)r-drop: acc 上升 71%—>71.7%
2)swa:平均最高 3 个 checkpoints权重,模型准确率略有提升(71.7%->71.8%)
4)ema:acc 71.879% -> 71.975%
5)fgm对抗训练,acc 71.975% -> 72.206%
6)word-base:acc 72.206% -> 72.4%
7)ensemble:model1(72.638%) + model2(72.785%)—> acc 73.601%
8)训练帧数增加:帧数从 10—>30,acc 67.308 -> 67.782
9)图片尺寸:resize224x224 —> centercrop,acc 72.4—>73
-
loss 改进
- 类别不均衡问题:label smoothing 和 class balanced loss 融合,acc 71.750% -> 71.879%
- 层级分类问题:细粒度分类+粗粒度分类、细粒度分类映射、hmc los
4)预训练
- mlm、mfm、itm、itc、mmm、mma
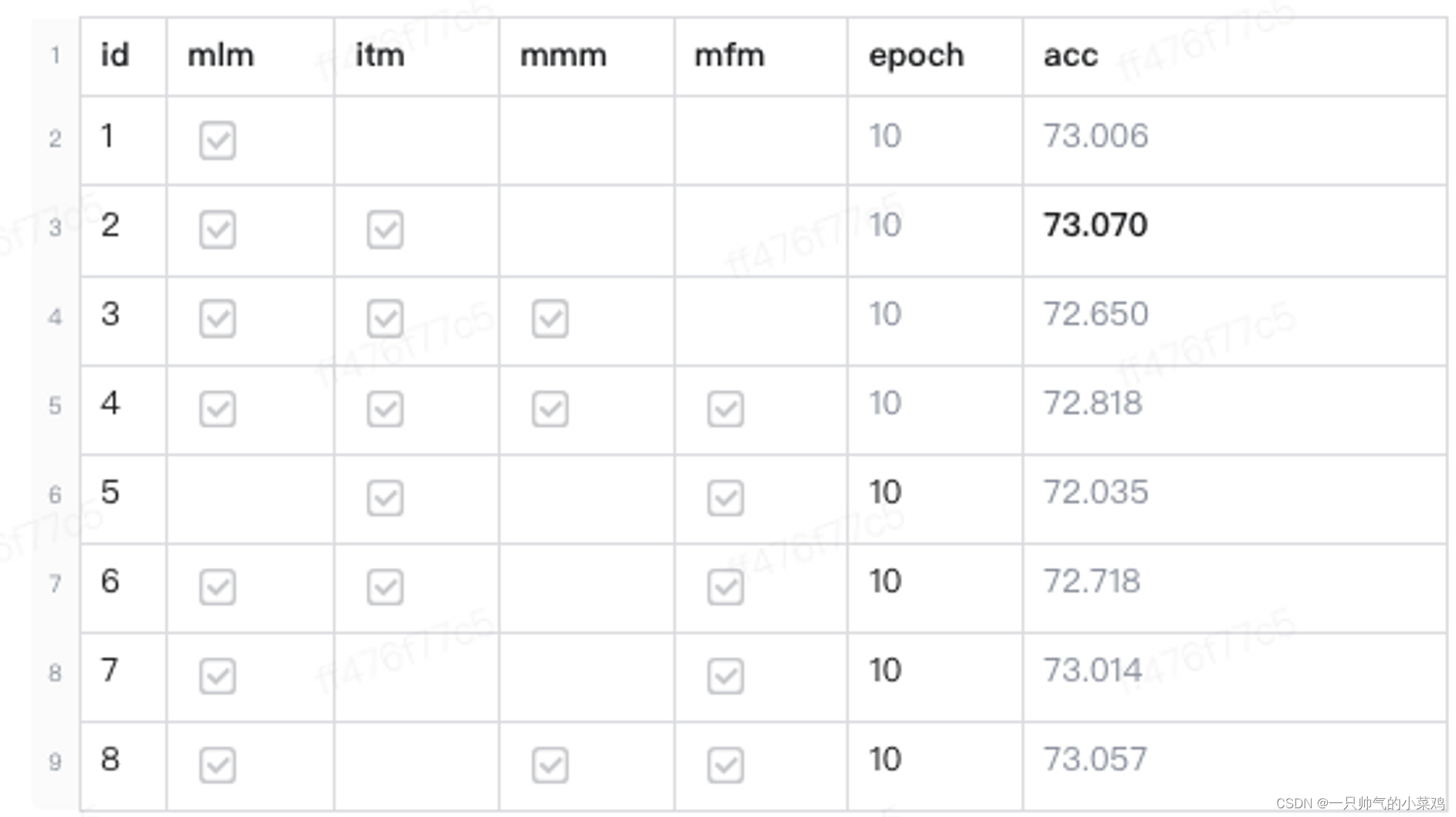
2、数据方面
1)数据准备
- 类别关系映射 + 大量人标注,累计积累了 103 w 数据
- 基于初版模型,根据top1&top2 的预测分数,捞取边界数据,提升标出率
2)数据清洗
- N 折交叉验证
- 训练早停,筛选 diff 数据
3)伪数据构造
- 知识蒸馏
- 标注数据上,使用更多帧、更大模型(clip-large)、不同模型架构,训练n 个模型
- 使用 i 得到的 n 个模型ensemble 为无标注数据打伪标签
- 在 ii 的伪标签数据上做预训练,预训练任务及伪标签分类,预训练时随机使用10/30帧的视频,以缓解预训练和微调过程不一致
- 重复 ii、iii,用最后得到的模型做微调初始化
- 在有标注数据上进行微调
- 基于检索的伪标签
- 标注数据上,训练 DML 模型并提取特征
- 无标记数据检索有标记数据,对 top10 样本进行类别投票,生成伪标签
3、后处理方面
- 不同类别给予不同的缩放系数,大类为 1,效率大于 1,使用粒子群优化算法pso搜一个也行
- 模型能力总归是有限的,根据业务需要,结合人审,制定合适的送审策略也是重要的
4、外部信号
1)结合先验特征,比如作者主垂类信息、作者兴趣点、作者认证信息、同作者发布内容等
2)结合后验信号,视频评论,点赞、完播率等