python技术面试题
1、简述django FBV和CBV
FBV是基于函数编程,CBV是基于类编程,本质上也是FBV编程,在Djanog中使用CBV,则需要继承View类,在路由中指定as_view函数,返回的还是一个函数
在DRF中的使用的就是CBV编程
2、django中的F和Q函数的作用
在Django ORM中,F是一个用于数据库查询的特殊对象,用于执行基于数据库字段之间的比较和操作
在Django ORM中,Q对象是用于构建复杂查询条件的工具,它提供了逻辑操作符(如AND、OR、NOT)来组合多个查询条件。
3、django的模板中filter、simple_tag、inclusion_tag的区别
在Django模板中,filter、simple_tag和inclusion_tag都是用于自定义模板标签和过滤器的方法,但它们在功能和使用方式上有一些区别:Filter(过滤器):参数:1-2个
过滤器是用于在模板中处理变量的函数,可以对变量进行一些简单的处理或转换。
过滤器可以通过管道(|)将其应用于变量,以修改变量的输出结果。
过滤器通常用于对字符串、日期、数字等数据进行格式化或转换。
Django提供了一些内置的过滤器,例如date、lower、upper等,同时也支持自定义过滤器。Simple Tag(简单标签):参数:无限制
简单标签是一种自定义模板标签,它是一个Python函数,接受参数并生成一些输出。
简单标签可以在模板中以类似于函数调用的方式使用,并将标签的返回值插入到模板中。
简单标签通常用于执行一些简单的逻辑操作,生成动态内容,并将其嵌入到模板中。Inclusion Tag(包含标签):参数:无限制
包含标签也是一种自定义模板标签,它是一个Python函数,用于生成包含其他模板的片段。
包含标签接受参数,并使用指定的参数渲染其他模板。
包含标签通常用于将公共的模板片段(如导航栏、页脚等)封装为可重用的组件,并在多个模板中使用。
4、select_related和prefetch_related的区别和使用场景?
"select_related" 和 "prefetch_related" 都是 Django ORM 提供的用于优化数据库查询的方法,但它们的作用和使用场景略有不同。1. **select_related**:- 作用:通过使用 "select_related" 方法,Django 会在查询时使用 SQL 的 JOIN 操作,将外键关联的对象一并获取,从而在单次查询中获取所有相关数据。- 使用场景:适用于 ForeignKey 和 OneToOneField 等外键关联的查询。当你需要在一个查询中获取主对象和关联对象的数据时,可以使用 "select_related" 来避免多次数据库查询,提高性能。- 注意事项:"select_related" 适合于外键关联,但如果涉及多对多关系或反向关联,性能可能不如 "prefetch_related",因为 "select_related" 会产生多个 JOIN 操作,可能导致性能下降。2. **prefetch_related**:- 作用:"prefetch_related" 用于优化查询涉及多对多关系和反向关联(例如 ManyToManyField 和 Reverse ForeignKey)的情况。它会在单次查询中获取所有相关数据,避免了 N+1 查询问题。- 使用场景:适用于优化多对多关系和反向关联的查询。当你需要在查询中获取主对象及其关联对象的数据,并且涉及多对多关系或反向关联时,可以使用 "prefetch_related"。- 注意事项:"prefetch_related" 可以显著提高性能,但需要注意不要过度使用,以免导致不必要的资源消耗。综合使用场景和注意事项,可以根据查询需求选择适当的方法:- 如果查询涉及到外键关联,并且你需要获取主对象和关联对象的数据,可以考虑使用 "select_related"。
- 如果查询涉及到多对多关系或反向关联,并且你需要获取主对象及其关联对象的数据,可以考虑使用 "prefetch_related"。最佳实践是根据数据模型和具体查询需求来选择使用哪种方法,以达到最佳性能和资源利用。
5、简述python中的垃圾回收机制
Python 的垃圾回收机制是自动的,而非强制的,Python 在解释程序执行时,使用了类似于引用计数的技术来实现垃圾回收。Python采用的是一种简单的技术:当程序中的某个变量对象引用计数为0时, Python就会将其释放掉,但这种技术会造成一些问题,比如循环引用等。因此,Python还有其他垃圾回收的方法,比如标记清除、分代回收等。Python 的垃圾回收机制主要靠引用计数来实现。每个对象有一个引用计数,表示有多少引用指向这个对象。当引用计数降为0时,说明没有任何变量名引用这个对象了,这个对象就可以被垃圾回收器回收。垃圾回收器周期性地执行检查,以确定哪些对象已经过时,然后将它们从内存中删除。垃圾回收机制的关键在于「引用计数」。Python 中的任何变量都是对某个对象的引用,当变量不再使用一个对象时,Python 就会减少该对象的引用计数,当引用计数降为 0 时,Python 就可以回收这个对象了。以下是 Python 自动垃圾回收机制的原理:
1.引用计数
Python 中的一个对象对应一个结构体 PyObejct,结构体中保存了对对象所包含的数据的引用,以及引用对象的类型信息。每个对象都会统计这个对象的引用计数,引用计数要求有人来进行维护,Python 需要在代码中将这个对象打上标记,来作为引用 Python 对象的一个位置变量,在对象不再被使用时,引用计数减 1,引用计数为 0 时,释放所占的内存空间。一般引用计数递增函数如下:PyObject *py_incref(PyObject *op) {op->ob_refcnt += 1;return op;}
一般引用计数递减函数如下:void py_decref(PyObject *op) {op->ob_refcnt -= 1;if (op->ob_refcnt == 0) {PyObject_GC_Untrack(op);op->ob_type->tp_clear(op);op->ob_type->tp_free(op);}}引用计数的缺陷:如果对象之间存在循环引用,那么这些对象的引用计数永远不会降为 0,垃圾回收器就无法回收它们所占用的内存。对于这种情况,Python 的垃圾回收机制采用了另一个算法——标记清除算法。2.标记清除
标记清除算法分为两个阶段:第一阶段:标记
从根对象开始,自上而下地遍历所有对象。标记 根对象。如果一个对象没有标记,就递归地遍历这个对象所有可达的子对象,并标记。这个过程中,被标记的对象的引用计数因为被标记而增加,未被标记的对象引用计数不改变。第二阶段:
从堆的起始地址开始,依次对每个内存地址进行遍历,对于没有被标记的对象,说明它没有被引用,可以被回收。如果一个对象被回收,那么这个对象所指向的其他对象也会被递归回收。这样做的好处在于,标记清除算法能够解决循环引用的问题,因为只有可达的对象会被标记,不可达(孤岛)的对象永远不会被访问到,自然就不会被标记,最终被回收。但是,标记清除算法也有缺点,会产生内存碎片。3.分代回收Python 的垃圾回收机制中还有一种高级算法:分代回收。这个是因为,Python 中有一些对象被使用较少,有一些对象被使用较多,可以根据对象的历史使用情况把对象划分成几代。一般情况下,新创建的对象会被划分到第一代,第一代对象的存活时间较短,如果一个对象在第一代中存活了一段时间,那么它会被划分到第二代中,第二代对象的存活时间较长,同样地,如果一个对象在第二代中存活了一段时间,那么它会被划分到第三代中,第三代对象的存活时间更长。Python 的垃圾回收机制主要运用在这三种算法之间,引用计数算法提高了回收垃圾对象的效率,标记清除算法保证了循环引用的完美处理,分代回收算法是为了增加垃圾回收的效率。在 Python 中,可通过 sys 模块中的 getrefcount 函数来获取对象的引用计数:import sysvariable = 'hello'print(sys.getrefcount(variable)) #输出2,因为该函数会隐式引用变量一次可以通过手动打印变量的引用计数来观察垃圾回收机制的工作过程:import sysclass MyClass:def __del__(self):print("MyClass instance deleted")def foo():obj = MyClass()print(sys.getrefcount(obj))foo()
输出结果如下:2MyClass instance deleted
从上面的输出结果可以看出,在函数执行结束后, MyClass 实例被删除,说明垃圾回收机制已经发现并收回了这个实例对象。从以上内容可以看出,Python 的自动垃圾回收机制是一种简单和高效的内存管理技术,它通过引用计数、标记清除以及分代回收等多种算法来管理内存分配与回收。内存管理对于编程语言来说非常重要,Python 的内存管理机制优良,使用者可以高效率地进行 Python 编程,同时也可以轻松地避免内存泄漏等不必要的麻烦。6、python实现算法实现代码全排列
# 使用深度优先
def permute(nums):def dfs(start):if start == len(nums):result.append(nums[:])returnfor i in range(start, len(nums)):nums[start], nums[i] = nums[i], nums[start]dfs(start + 1)nums[start], nums[i] = nums[i], nums[start] # 恢复原始状态result = []dfs(0)return result# 测试
nums = [1, 2, 3]
permutations = permute(nums)
for perm in permutations:print(perm)
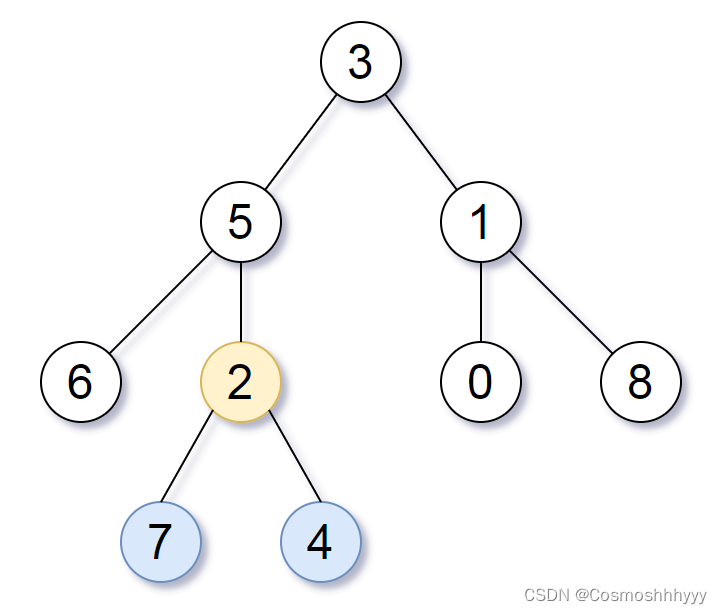
7、给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1: 输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]] 示例 2: 输入:nums = [] 输出:[] 示例 3: 输入:nums = [0] 输出:[]
def threeSum(nums):n = len(nums)if n < 3:return []nums.sort()res = []for i in range(n-2):if i > 0 and nums[i] == nums[i-1]:continueleft = i + 1right = n - 1while left < right:total = nums[i] + nums[left] + nums[right]if total == 0:res.append([nums[i], nums[left], nums[right]])while left < right and nums[left] == nums[left+1]:left += 1while left < right and nums[right] == nums[right-1]:right -= 1left += 1right -= 1elif total < 0:left += 1else:right -= 1return res8、给定一个二维数组arr,数组中的元素都是0或1, 素有相邻元素都为1的为连通区域,找到最大的连通区域
# 要找到二维数组 arr 中最大的连通区域,可以使用深度优先搜索(DFS)或广度优先搜索(BFS)的算法来解决
def max_connected_area(arr):if not arr:return 0rows = len(arr)cols = len(arr[0])max_area = 0def dfs(row, col):if row < 0 or row >= rows or col < 0 or col >= cols or arr[row][col] != 1:return 0area = 1arr[row][col] = -1 # 标记已访问过的区域为-1# 递归搜索上下左右四个方向area += dfs(row - 1, col) # 上area += dfs(row + 1, col) # 下area += dfs(row, col - 1) # 左area += dfs(row, col + 1) # 右return areafor row in range(rows):for col in range(cols):if arr[row][col] == 1:max_area = max(max_area, dfs(row, col))return max_area# 示例用法
arr = [[1, 1, 0, 0, 0],[1, 1, 0, 0, 1],[0, 0, 1, 1, 0],[0, 0, 0, 1, 1],
]
max_area = max_connected_area(arr)
print(max_area) # 输出:59、lambda函数和普通函数有什么区别?
lambda函数和普通函数的主要区别在于它们的定义方式和使用场景。
定义方式
普通函数使用def关键字来定义,通常可以包含多行代码块和函数体内的其他语句。而lambda函数使用lambda关键字来定义,只能包含一个单行表达式作为函数体,不能包含多行代码块。
使用场景
普通函数通常用于实现复杂的逻辑或算法,或者需要被多次调用的函数。而lambda函数通常用于实现简单的函数,特别是在需要将函数作为参数传递给其他函数或方法时,比如filter()、map()和reduce()等高阶函数。此外,在需要编写一些快速的临时函数时,使用lambda函数也很方便。
例如,以下是一个使用普通函数实现的加法函数:
def add(x, y):return x + y
而以下是同样的函数使用lambda函数实现的方式:
add = lambda x, y: x + y
可以看到,lambda函数的定义方式更加简洁,适用于一些简单的场景。而普通函数则更加灵活,适用于更加复杂的场景。
10、赋值、浅拷贝、深拷贝
import copyd = {'1': [1, 1, 1], '2': 2}
copy1 = d
copy2 = d.copy()
copy3 = copy.copy(d)
copy4 = copy.deepcopy(d)d['1'][0] = 3 d['2'] = 3 print(copy1, copy2, copy3, copy4)'''
打印结果分比为{'1': [3, 1, 1], '2': 3} {'1': [3, 1, 1], '2': 2} {'1': [3, 1, 1], '2': 2} {'1': [1, 1, 1], '2': 2}
'''
方法1:赋值引用,copy1和d指向同一个对象
方法2:浅复制,复制生成新对象copy2,但是只复制一层,[1, 1, 1]为两者共同子对象,
方法3:浅复制,调用copy模块中的方法,同方法2
方法3:深复制,复制生成新对象copy4,并且递归复制所有子对象,所以d中原来指向[1, 1, 1]的改动不会影响深复制生成的子对象[1, 1, 1]
赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的deep.deepcopy()函数}
a = {'1':1,'2':2,'3':[1,2],4:'abc'}
b = a.copy()和b=copy.copy(a)都属于浅拷贝
当a/b中的不可改变数据:int类型、string类型、tuple类型发生改变时候,不影响到另一个。
但其它的情况下,如更改列表元素,会发生互相影响。
举例:
①不可变数据改变举例
对int改变:
a = {'1':1,'2':2,'3':[1,2],'4':'abc'}b = a.copy()a['1']=250print(a)print(b)out: '''
{'1': 250, '2': 2, '3': [1, 2], '4': 'abc'}
{'1': 1, '2': 2, '3': [1, 2], 4: 'abc'}
'''
对string改变:
a = {'1':1,'2':2,'3':[1,2],'4':'abc'}b = a.copy()a['4']='def'print(a)print(b)out: '''
{'1': 1, '2': 2, '3': [1, 2], '4': 'def'}
{'1': 1, '2': 2, '3': [1, 2], '4': 'abc'}
'''
对tuple改变:
a = {'1':1,'2':2,'3':[1,2],'4':'abc'}b = a.copy()a['3']=[1,2,3]print(a)print(b)'''
{'1': 1, '2': 2, '3': [1, 2, 3], '4': 'abc'}
{'1': 1, '2': 2, '3': [1, 2], '4': 'abc'}
'''
②可变数据改变举例
a = {'1':1,'2':2,'3':[1,2],'4':'abc'}b = a.copy()a['3'][0]=2print(a)print(b)'''
{'1': 1, '2': 2, '3': [2, 2], '4': 'abc'}
{'1': 1, '2': 2, '3': [2, 2], '4': 'abc'}
'''
10、列举常见的请求方法?
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
11、大数据的文件读取:
①利用生成器generator;
②迭代器进行迭代遍历:for line in file;
12、迭代器和生成器的区别:
答:(1)迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个StopIteration异常
(2)生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出StopIteration异常
13、简单谈下python2和python3的区别:
1 Py3默认使用utf-8编码,python2使用ascill码
2 去除了<>,全部改用!=
3 整型除法返回浮点数,要得到整型结果,请使用//
4 去除print语句,加入print()函数实现相同的功能。同样的还有 exec语句,已经改为exec()函数
5 改变了顺序操作符的行为,例如x<y,当x和y类型不匹配时抛出TypeError而不是返回随即的 bool值
6 输入函数改变了,删除了raw_input,用input代替
7 去除元组参数解包。不能def(a, (b, c)):pass这样定义函数了『Pythonnote』
8 Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
9 新增了bytes类型,对应于2.X版本的八位串
10 迭代器的next()方法改名为__next__(),并增加内置函数next(),用以调用迭代器的__next__()方法『Pythonnote』小闫同学
11 增加了@abstractmethod和 @abstractproperty两个 decorator,编写抽象方法(属性)更加方便。
12 所以异常都从 BaseException继承,并删除了StardardError
13 去除了异常类的序列行为和.message属性
14 用 raise Exception(args)代替 raise Exception, args语法小闫同学
15 移除了cPickle模块,可以使用pickle模块代替。最终我们将会有一个透明高效的模块。
16 移除了imageop模块
17 移除了 audiodev, Bastion, bsddb185, exceptions, linuxaudiodev, md5, MimeWriter, mimify, popen2,
rexec, sets, sha, stringold, strop, sunaudiodev, timing和xmllib模块
18 移除了bsddb模块(单独发布,可以从 获取)
19 移除了new模块
20 xrange() 改名为range()
14、find和grep?:
grep命令是一种强大的文本搜索工具,grep搜索内容串可以是正则表达式,允许对文本文件进行模式查找。如果找到匹配模式,grep打印包含模式的所有行。
find通常用来再特定的目录下搜索符合条件的文件,也可以用来搜索特定用户属主的文件。
15、python 中 yield 的用法?
答:yield简单说来就是一个生成器,这样函数它记住上次返 回时在函数体中的位置。对生成器第 二次(或n 次)调用跳转至该函 次)调用跳转至该函 数。
16、描述数组、链表、队列、堆栈的区别?
数组与链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据;队列和堆栈是描述数据存取方式的概念,队列是先进先出,而堆栈是后进先出;队列和堆栈可以用数组来实现,也可以用链表实现。
17、django 中当一个用户登录 A 应用服务器(进入登录状态),然后下次请求被 nginx 代理到 B 应用服务器会出现什么影响?
如果用户在A应用服务器登陆的session数据没有共享到B应用服务器,那么之前的登录状态就没有了。
18、cookie 和session 的区别?
1.cookie:
cookie是保存在浏览器端的键值对,可以用来做用户认证
2.session:
将用户的会话信息保存在服务端,key值是随机产生的自符串,value值时session的内容
依赖于cookie将每个用户的随机字符串保存到用户浏览器上
Django中session默认保存在数据库中:django_session表flask,session默认将加密的数据写在用户的cookie中
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。请关注公众号『全栈技术精选』
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、建议:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
19、创建一个简单tcp服务器需要的流程
1.socket创建一个套接字
2.bind绑定ip和port
3.listen使套接字变为可以被动链接
4.accept等待客户端的链接
5.recv/send接收发送数据
20、 new init 的区别
__init__为初始化方法 __new__方法是真正的构造函数
__new__是实例创建之前被调用 ,它的任务是创建并返回该实例
__init__是在实例被创建后调用,然后设置对象属性的一些初始值
总结:new方法在init方法之前被调用,并且new方法的返回值将传递给init方法作为第一个参数,最后init给这个实例设置一些参数
21、关于 静态类型, 动态类型 和 强类型,弱类型 :
静态,动态之分是 看是否后期可以动态修改。c后期的类型不能改,所以它是静态。Python后期的类型可以修改 ,故动态类型。
强,弱类型之分是 看不同类型之间是否可以 运算。 js 中可以 “a” +1 = “a1” ,所以它是弱类型,Python中则直接报错。故Python是强类型的语言。
总结:Python是动态类型,强类型的语言。
22、pass的作用?
pass 不做任何事情,一般用做占位语句。
pass 空语句,是为了保持程序结构的完整性
23、写一个简单的python socket编程
python 编写server的步骤:1第一步是创建socket对象。调用socket构造函数。如:socket = socket.socket(family, type )family参数代表地址家族,可为AF_INET或AF_UNIX。AF_INET家族包括Internet地址,AF_UNIX家族用于同一台机器上的进程间通信。type参数代表套接字类型,可为SOCK_STREAM(流套接字)和SOCK_DGRAM(数据报套接字)。2.第二步是将socket绑定到指定地址。这是通过socket对象的bind方法来实现的:socket.bind( address )由AF_INET所创建的套接字,address地址必须是一个双元素元组,格式是(host,port)。host代表主机,port代表端口号。如果端口号正在使用、主机名不正确或端口已被保留,bind方法将引发socket.error异常。3.第三步是使用socket套接字的listen方法接收连接请求。socket.listen( backlog )backlog指定最多允许多少个客户连接到服务器。它的值至少为1。收到连接请求后,这些请求需要排队,如果队列满,就拒绝请求。4.第四步是服务器套接字通过socket的accept方法等待客户请求一个连接。connection, address =socket.accept()调用accept方法时,socket会时入“waiting”状态。客户请求连接时,方法建立连接并返回服务器。accept方法返回一个含有两个元素的元组(connection,address)。第一个元素connection是新的socket对象,服务器必须通过它与客户通信;第二个元素address是客户的Internet地址。\5. 第五步是处理阶段,服务器和客户端通过send和recv方法通信(传输数据)。服务器调用send,并采用字符串形式向客户发送信息。send方法返回已发送的字符个数。服务器使用recv方法从客户接收信息。调用recv 时,服务器必须指定一个整数,它对应于可通过本次方法调用来接收的最[大数据](http://lib.csdn.net/base/hadoop)量。recv方法在接收数据时会进入“blocked”状态,最后返回一个字符串,用它表示收到的数据。如果发送的数据量超过了recv所允许的,数据会被截短。多余的数据将缓冲于接收端。以后调用recv时,多余的数据会从缓冲区删除(以及自上次调用recv以来,客户可能发送的其它任何数据)。\6. 传输结束,服务器调用socket的close方法关闭连接。
python编写client的步骤:1. 创建一个socket以连接服务器:socket= socket.socket( family, type )2.使用socket的connect方法连接服务器。对于AF_INET家族,连接格式如下:socket.connect((host,port) )host代表服务器主机名或IP,port代表服务器进程所绑定的端口号。如连接成功,客户就可通过套接字与服务器通信,如果连接失败,会引发socket.error异常。3. 处理阶段,客户和服务器将通过send方法和recv方法通信。4. 传输结束,客户通过调用socket的close方法关闭连接。
24、什么是面向对象的mro?
在面向对象编程中,MRO(Method Resolution Order,方法解析顺序)是指确定在多继承情况下,当一个类调用一个方法时,方法解析的顺序。MRO决定了在多继承中,每个类的方法被调用的顺序,以及如何处理方法的冲突。
MRO的计算是通过使用C3线性化算法来实现的。C3线性化算法通过合并所有父类的方法解析顺序列表,创建一个新的列表,确保在调用方法时不会破坏方法解析的顺序。C3算法遵循以下三个原则:
1.子类优先原则(Child First)
如果一个类是另一个类的子类,那么子类的方法应该优先于父类的方法被调用。
2.多继承顺序原则(Multiple Inheritance Order)
在多继承的情况下,当选择下一个类的方法时,应该优先选择第一个基类的方法。
3.一致性原则(Consistency)
如果一个类是多个类的父类,那么这些类的顺序在新列表中的顺序应该被保持。
通过使用C3线性化算法计算MRO,可以确保在多继承的情况下,方法解析的顺序是一致的,并且遵循上述原则。这有助于避免潜在的冲突和歧义,并提供清晰的方法调用顺序。
下面是一个示例来说明MRO的计算过程:
假设有以下类定义:
class A:passclass B(A):passclass C(A):passclass D(B, C):pass
根据C3线性化算法,计算D类的MRO顺序:
1.首先,将类D添加到MRO列表中:D
2.接下来,将D的父类B的MRO列表(B, A)合并到MRO列表中:D, B, A
3.再将D的另一个父类C的MRO列表(C, A)合并到MRO列表中,遵循子类优先原则和多继承顺序原则:D, B, C, A
4.最后,将A的MRO列表(A)合并到MRO列表中:D, B, C, A
因此,类D的MRO顺序为D, B, C, A。这意味着在调用D类的方法时,首先会查找D类自身的方法,然后是B类的方法,接着是C类的方法,最后是A类的方法。
通过MRO的计算,可以保证在多继承的情况下,方法解析的顺序是一致的,并且遵循一定的优先级和原则,从而确保程序的正确性和可预测性。
25、列举django的内置组件
分页器
Form
modelForm
orm
cookie和session
中间件
信号
26、中间件中5个常用方法与内置中间件剖析
26.1 init方法要调用父类方法
init方法在启动服务的时候执行一次
26.2 process_request(self,request)
请求进入中间件后,第一个执行的方法
返回值有两个:Response|None
返回Response,不会再执行视图函数,而是调到process_response方法(此处有坑,最后说)
返回None,或者不return,继续运行
26.3 process_view(self,request,func,*args,**kwargs)
运行完process_request后,就运行这个
func是要执行的视图函数,所以:response = func(request) return response,可以得到视图函数的结果
如果调用了func(request)方法,如果不return response的话,视图函数还会执行一次,所以要不就不调用,调用就return
如果手动调用了func(request)方法,视图函数中的异常不会被process_exception(self,request,exception)接收
26.4 process_response(self,request,response)
每次返回response的时候必经的方法
必须return 一个 response,否则页面显示啥?
26.5 process_template_response(self,request,response)
官方说当视图函数的返回结果是return render(request,‘xxx.html’,context)的时候,走process_template_response包装返回的响应,但我测试,发现不会调用这个方法,模板渲染返回的response也会调用process_response这个方法,可能是版本的问题吧,另外这个方法使用的情况真的比较少
26.6 process_exception(self,request,exception)
视图函数中出现了异常,接受异常的信息
但如果视图函数时通过上面所说,在process_view中手动调用了func(request),则process_exception方法不会被调用接收异常信息
27、Django 中session的运行机制是什么
django的session存储可以利用中间件来实现。
需要在 settings.py 文件中注册APP、设置中间件用于启动。
设置存储模式(数据库/缓存/混合存储)和配置数据库缓存用于存储,生成django_session表单用于读写。
28、Django中如何加载初始化数据?
Django在创建对象时在调用save()方法后,ORM框架会把对象的属性写入到数据库中,实现对数据库的初始化。
通过操作对象,查询数据库,将查询集返回给视图函数,通过模板语言展现在前端页面。
29、简述Django下的(内建)缓存机制
Django根据设置的缓存方式,浏览器第一次请求时,cache会缓存单个变量或整个网页等内容到硬盘或者内存中,同时设置response头部。
当浏览器再次发起请求时,附带f-Modified-Since请求时间到Django。
Django发现f-Modified-Since会先去参数之后,会与缓存中的过期时间相比较,如果缓存时间比较新,则会重新请求数据,并缓存起来然后返回response给客户端。
如果缓存没有过期,则直接从缓存中提取数据,返回给response给客户端。
30、Django路由系统中include是干嘛用的?
include用作路由转发,通常,我们会在每个app里,各自创建一个urls.py路由模块,然后从根路由出发,将app所属的url请求,全部转发到相应的urls.py模块中。
31、命令和make migrate 和make migrations的差别?(初级)
make migrations:生成迁移文件
migrate:执行迁移
32、列举几个减少数据库查询次数的方法
- 利用Django queryset的惰性和自带缓存的特性
- 使用select_related和prefetch_related方法在数据库层面进行Join操作
- 使用缓存
33、Django的request对象是在什么时候创建的?
当请求一个页面时, Django会建立一个包含请求元数据的HttpRequest对象。
当Django加载对应的视图时, HttpRequest对象将作为视图函数的第一个参数,另外每个视图会返回一个HttpResponse对象。
34、Django orm 中所有的方法(QuerySet对象的所有方法)
django的ORM框架提供的查询数据库表数据的方法很多,不同的方法返回的结果也不太一样,不同方法都有各自对应的使用场景。
主要常用的查询方法个数是13个,按照特点分为这4类:
方法返回值是可迭代对象QuerySet:
all():
通过ORM框架提供的【all() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
filter():
【filter() 】方法的返回值是一个可迭代对象QuerySet类型数据,返回值都是符合查询条件的数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
exclude():
①.【exclude() 】方法的返回值也是一个可迭代对象QuerySet,返回值都是不符合查询条件的数据。②.【exclude() 】方法在实际开发中基本少用,基本都采用【filter()】方法。③.【exclude() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
order_by():
①.【order_by() 】方法的返回值也是一个可迭代对象QuerySet,返回值都是符合排序条件的数据。②.【order_by() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。③.入参的相关注意点:参数的字段名要加引号。
如果要实现降序功能,要在字段名前面加个负号【-】。
reverse():
①.【reverse() 】方法的返回值也是一个可迭代对象QuerySet,【reverse() 】方法用于对查询结果进行反转。②.【reverse() 】方法在实际开发中基本少用,基本都采用【order_by()】方法。③.【reverse() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
values():
①.【values() 】方法的返回值也是一个可迭代对象QuerySet,【values() 】方法用于查询部分字段或者全部字段的数据。②.如果要查询全部字段的数据,【values() 】方法的入参字段数要为0;③.【values() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都不是模型类的对象而是可迭代的字典噢,字典里的键是表字段,值是表字段对应的数据。
values_list():
①.【values_list() 】方法的返回值也是一个可迭代对象QuerySet,但【values_list() 】方法用于查询部分字段或者全部字段的数据。②.如果要查询全部字段的数据,【values_list() 】方法的入参字段数要为0;③.【values_list() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都不是模型类的对象而是元祖哦,元组里放的是查询表字段对应的数据。
distinct():
①.【distinct()】方法的返回值也是一个可迭代对象QuerySet。②.【distinct()】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都不是模型类的对象,而是每个元祖,元组里放的是查询字段对应的数据。③.【distinct()】方法对模型类的对象去重没有意义,因为每个对象都是一个不一样的存在。所以【distinct()】方法一般是跟 【values】方法 或者 【values_list】方法 一起使用,但如果跟【all()】方法一起使用是产生不了去重的效果。④.【distinct()】方法的作用:用于对数据进行去重。
方法返回值是单个对象:
get():
①.【get()】方法的返回值是一个模型类的对象。②.【get()】方法用于查询符合条件的返回模型类的对象且符合条件的对象只能为一个,如果符合筛选条件的对象超过了一个或者没有一个都会抛出错误。
first():
①.【first()】方法返回符合查询条件的结果里的第一条数据且返回的数据是模型类的对象。
last();
①.【last()】方法返回符合查询条件的结果里的最后一条数据且返回的数据是模型类的对象。
方法返回值是布尔值:
exists():
①.【exists()】方法用于判断查询的结果 QuerySet 列表里是否有数据。②.【exists()】方法返回值的数据类型是布尔值,有数据则返回值为true,没有数据则返回值为false。
方法返回值是数字:
count():
①.【count()】方法用于查询数据的数量且返回的数据是整数。
35、F和Q的作用?
F()作用介绍:
操作数据表中的某列值,F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用,不用获取对象放在内存中再对字段进行操作,直接执行原生产sql语句操作。
Q方法:
作用:对对象进行复杂查询,并支持&(and),|(or),~(not)操作符。
36、django的Model中的ForeignKey字段中的on_delete参数有什么作用
on_delete解释: 当子表中的某条数据删除后,关联的外键操作。
删除关联表中的数据时,当前表与其关联的field的操作
django2.0之后,表与表之间关联的时候,必须要写on_delete参数,否则会报异常
1. SET_NULL
on_delete = models.SET_NULL
置空模式,删除时,外键字段被设置为空,前提就是blank=True, null=True,定义该字段时,允许为空。
删除关联数据(子表),与之关联的值设置默认值为null(父表中)
2.CASCADE
表示级联删除
- 当关联表(子表)中的数据删除时,与其相对应的外键(父表)中的数据也删除
on_delete = models.CASCADE
3.其他
on_delete = None: 删除关联表的数据时,当前表与关联表的filed的行为。
on_delete = models.DO_NOTHING: 你删你的,父亲(外键)不想管你
on_delete = models.PROTECT: 保护模式,如采用这个方法,在删除关联数据时会抛出ProtectError错误
on_delete = models.SET_DEFAULT: 设置默认值,删除子表字段时,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。
on_delete = models.SET(值): 删除关联数据时,自定义一个值,该值只能是对应指定的实体
37、django下的csrf防御机制
token防御的整体思路是:
- 第一步:后端随机产生一个token,把这个token保存在SESSION状态中;同时,后端把这个token交给前端页面;
- 第二步:下次前端需要发起请求(比如发帖)的时候把这个token加入到请求数据或者头信息中,一起传给后端;
- 第三步:后端校验前端请求带过来的token和SESSION里的token是否一致;
1、Django下的CSRF预防机制
django 第一次响应来自某个客户端的请求时,会在服务器端随机生成一个 token,把这个 token 放在 cookie 里。然后每次 POST 请求都会带上这个 token,
这样就能避免被 CSRF 攻击。
在 templete 中, 为每个 POST form 增加一个 {% csrf_token %} tag. 如下:
-
在返回的 HTTP 响应的 cookie 里,django 会为你添加一个 csrftoken 字段,其值为一个自动生成的 token
-
在所有的 POST 表单模板中,加一个{% csrf_token %} 标签,它的功能其实是给form增加一个隐藏的input标签,如下
,而这个csrf_token = cookie.csrftoken,在渲染模板时context中有context[‘csrf_token’] = request.COOKIES[‘csrftoken’]
-
在通过表单发送POST到服务器时,表单中包含了上面隐藏了crsrmiddlewaretoken这个input项,服务端收到后,django 会验证这个请求的 cookie 里的 csrftoken 字段的值和提交的表单里的 csrfmiddlewaretoken 字段的值是否一样。如果一样,则表明这是一个合法的请求,否则,这个请求可能是来自于别人的 csrf 攻击,返回 403 Forbidden.
-
在通过 ajax 发送POST请求到服务器时,要求增加一个x-csrftoken header,其值为 cookie 里的 csrftoken 的值,服务湍收到后,django会验证这个请求的cookie里的csrftoken字段与ajax post消息头中的x-csrftoken header是否相同,如果相同,则表明是一个合法的请求
具体实现方法:
django为用户实现防止跨站请求伪造的功能,通过中间件 django.middleware.csrf.CsrfViewMiddleware 来完成。而对于django中设置防跨站请求伪造功能有分为全局和局部。
全局:
中间件 django.middleware.csrf.CsrfViewMiddleware
局部:
- @csrf_protect,为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置全局中间件。
- @csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
注:from django.views.decorators.csrf import csrf_exempt,csrf_protect
2、原理
在客户端页面上添加csrftoken, 服务器端进行验证,服务器端验证的工作通过’django.middleware.csrf.CsrfViewMiddleware’这个中间层来完成。在django当中防御csrf攻击的方式有两种:
1.在表单当中附加csrftoken
2.通过request请求中添加X-CSRFToken请求头。
注意:Django默认对所有的POST请求都进行csrftoken验证,若验证失败则403错误侍候。
38、django的Form和ModeForm的作用?
Form作用:
1.在前端生成HTML代码
2.对数据作有效性校验
3.返回校验信息并展示
ModeForm:根据模型类生成From组件,并且可以操作数据库
39、django的模板中filter和simple_tag的区别?
自定义filter:{undefined{ 参数1|filter函数名:参数2 }}
- 可以与if标签来连用
- 自定义时需要写两个形参
simple_tag:{% simple_tag函数名 参数1 参数2 %}
- 可以传多个参数,没有限制
- 不能与if标签来连用
40、使用orm和原生sql的优缺点?
1.orm的开发速度快,操作简单。使开发更加对象化
执行速度慢。处理多表联查等复杂操作时,ORM的语法会变得复杂
2.sql开发速度慢,执行速度快。性能强
41、 什么是RPC?
远程过程调用 (RPC) 是一种协议,程序可使用这种协议向网络中的另一台计算机上的程序请求服务
1.RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。
2.首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。
3.在服务器端,进程保持睡眠状态直到调用信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,
4.最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
42、django rest framework框架中都有那些组件?
1.序列化组件:serializers 对queryset序列化以及对请求数据格式校验
2.路由组件routers 进行路由分发
3.视图组件ModelViewSet 帮助开发者提供了一些类,并在类中提供了多个方法
4.认证组件 写一个类并注册到认证类(authentication_classes),在类的的authticate方法中编写认证逻
5.权限组件 写一个类并注册到权限类(permission_classes),在类的的has_permission方法中编写认证逻辑。
6.频率限制 写一个类并注册到频率类(throttle_classes),在类的的allow_request/wait 方法中编写认证逻辑
7.解析器 选择对数据解析的类,在解析器类中注册(parser_classes)
8.渲染器 定义数据如何渲染到到页面上,在渲染器类中注册(renderer_classes)
9.分页 对获取到的数据进行分页处理, pagination_class
10.版本 版本控制用来在不同的客户端使用不同的行为
在url中设置version参数,用户请求时候传入参数。在request.version中获取版本,根据版本不同 做不同处理
43、简述 django rest framework框架的认证流程
1.用户请求走进来后,走APIView,初始化了默认的认证方法
2.走到APIView的dispatch方法,initial方法调用了request.user
3.如果我们配置了认证类,走我们自己认证类中的authentication方法
44、django rest framework如何实现的用户访问频率控制
使用IP/用户账号作为键,每次的访问时间戳作为值,构造一个字典形式的数据,存起来,每次访问时对时间戳列表的元素进行判断,把超时的删掉,再计算列表剩余的元素数就能做到频率限制了
匿名用户:使用IP控制,但是无法完全控制,因为用户可以换代理IP登录用户:使用账号控制,但是如果有很多账号,也无法限制
45、什么是跨域以及解决方法:
跨域:
浏览器从一个域名的网页去请求另一个域名的资源时,浏览器处于安全的考虑,不允许不同源的请求
同源策略:
- 协议相同
- 域名相同
- 端口相同
处理方法:
1.通过JSONP跨域
JSON是一种数据交换格式
JSONP是一种非官方的跨域数据交互协议
jsonp是包含在函数调用中的json
script标签不受同源策略的影响,手动创建一个script标签,传递URL,同时传入一个回调函数的名字
服务器得到名字后,返回数据时会用这个函数名来包裹住数据,客户端获取到数据之后,立即把script标签删掉
2.cors:跨域资源共享
使用自定义的HTTP头部允许浏览器和服务器相互通信
(1.如果是简单请求,直接设置允许访问的域名:
允许你的域名来获取我的数据
response[‘Access-Control-Allow-Origin’] = “*”
(2.如果是复杂请求,首先会发送options请求做预检,然后再发送真正的PUT/POST…请求
因此如果复杂请求是PUT等请求,则服务端需要设置允许某请求
如果复杂请求设置了请求头,则服务端需要设置允许某请求头
简单请求:
一次请求
非简单请求:
两次请求,在发送数据之前会先发一次请求用于做“预检”,
只有“预检”通过后才再发送一次请求用于数据传输。
只要同时满足以下两大条件,就属于简单请求。
(1) 请求方法是以下三种方法之一:HEAD GET POST
(2)HTTP的头信息不超出以下几种字段:
Accept
Accept-Language
Content-LanguageLast-Event-ID
Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、 text/plain
JSONP和CORS:
1.JSONP只能实现GET请求,而CORS支持所有类型的HTTP请求
2.jsonp需要client和server端的相互配合
3.cors在client端无需设置,server端需要针对不同的请求,来做head头的处理
46、如何实现用户的登陆认证
1.cookie session
2.token 登陆成功后生成加密字符串
3.JWT:json wed token缩写 它将用户信息加密到token中,服务器不保存任何用户信息
服务器通过使用保存的密钥来验证token的正确性
47、OSI、TCP/IP、五层协议的体系结构以及各层协议
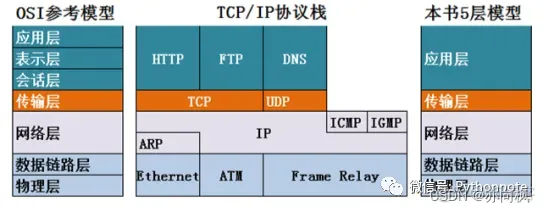
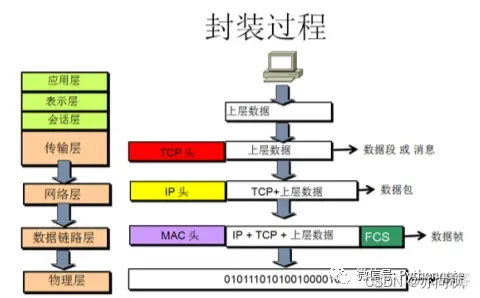
OSI分层(7层):物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
TCP/IP分层(4层):网络接口层、网际层、运输层、应用层。
五层协议(5层):物理层、数据链路层、网络层、运输层、应用层。
每一层的协议如下:
物理层:RJ45、CLOCK、IEEE802.3(中继器,集线器,网关)
数据链路:PPP、FR、HDLC、VLAN、MAC (网桥,交换机)
网络层:IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP (路由器)
传输层:TCP、UDP、SPX
会话层:NFS、SQL、NETBIOS、RPC
表示层:JPEG、MPEG、ASII
应用层:FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS
每一层的作用如下:
物理层:通过媒介传输比特,确定机械及电气规范(比特 Bit)
数据链路层:将比特组装成帧和点到点的传递(帧 Frame)
网络层:负责数据包从源到宿的传递和网际互连(包 PackeT)
传输层:提供端到端的可靠报文传递和错误恢复(段 Segment)
会话层:建立、管理和终止会话(会话协议数据单元 SPDU)
表示层:对数据进行翻译、加密和压缩(表示协议数据单元 PPDU)
应用层:允许访问 OSI 环境的手段(应用协议数据单元 APDU)
48、ARP是地址解析协议,简单语言解释一下工作原理
地址解析协议,即 ARP(Address Resolution Protocol),是根据 IP 地址获取物理地址的一个 TCP/IP 协议。
1.首先,每个主机都会在自己的 ARP 缓冲区中建立一个 ARP 列表,以表示 IP 地址和 MAC 地址之间的对应关系。
2.当源主机要发送数据时,首先检查ARP列表中是否有对应 IP 地址的目的主机的 MAC 地址,如果有,则直接发送数据,如果没有,就向本网段的所有主机发送 ARP 数据包,该数据包包括的内容有:源主机IP地址,源主机 MAC 地址,目的主机的 IP 地址
3.当本网络的所有主机收到该 ARP 数据包时,首先检查数据包中的 IP 地址是否是自己的 IP 地址,如果不是,则忽略该数据包,如果是,则首先从数据包中取出源主机的 IP 和 MAC 地址写入到 ARP 列表中,如果已经存在,则覆盖,然后将自己的 MAC 地址写入 ARP 响应包中,告诉源主机自己是它想要找的 MAC 地址。
4.源主机收到 ARP 响应包后。将目的主机的 IP 和 MAC 地址写入 ARP 列表,并利用此信息发送数据。如果源主机一直没有收到 ARP 响应数据包,表示 ARP 查询失败。
注意:广播(255.255.255.255)发送 ARP 请求,单播发送 ARP 响应。
49、DNS域名系统,简单描述其工作原理。
当 DNS 客户机需要在程序中使用名称时,它会查询 DNS 服务器来解析该名称。客户机发送的每条查询信息包括三条信息:包括:指定的 DNS 域名,指定的查询类型,DNS 域名的指定类别。基于 UDP 服务,端口53. 该应用一般不直接为用户使用,而是为其他应用服务,如 HTTP,SMTP等在其中需要完成主机名到IP地址的转换。
50、面向连接和非面向连接的服务的特点是什么?
面向连接的服务,通信双方在进行通信之前,要先在双方建立起一个完整的可以彼此沟通的通道,在通信过程中,整个连接的情况一直可以被实时地监控和管理。
非面向连接的服务,不需要预先建立一个联络两个通信节点的连接,需要通信的时候,发送节点就可以往网络上发送信息,让信息自主地在网络上去传,一般在传输的过程中不再加以监控。
51、TCP的三次握手过程?为什么会采用三次握手,若采用二次握手可以吗?
答:建立连接的过程是利用客户服务器模式,假设主机 A 为客户端,主机 B 为服务器端。
(1)TCP 的三次握手过程:主机 A 向 B 发送连接请求;主机 B 对收到的主机 A 的报文段进行确认;主机 A 再次对主机 B 的确认进行确认。
(2)采用三次握手是为了防止失效的连接请求报文段突然又传送到主机 B,因而产生错误。失效的连接请求报文段是指:主机 A 发出的连接请求没有收到主机 B 的确认,于是经过一段时间后,主机 A 又重新向主机 B 发送连接请求,且建立成功,顺序完成数据传输。考虑这样一种特殊情况,主机 A 第一次发送的连接请求并没有丢失,而是因为网络节点导致延迟达到主机 B,主机 B 以为是主机 A 又发起的新连接,于是主机 B 同意连接,并向主机 A 发回确认,但是此时主机 A 根本不会理会,主机 B 就一直在等待主机 A 发送数据,导致主机 B 的资源浪费。(这就是缺少第三次握手( A 再给 B 确认))
(3)采用两次握手不行,原因就是上面说的实效的连接请求的特殊情况。
就是说如果只进行两次握手,那么就存在以下问题:1.如果只进行两次握手,那么服务器只能确认客户端的请求,但是客户端无法确认服务器是否已经收到自己的请求,从而无法保证连接的可靠性。2.可能存在历史连接的延续。假设客户端发送一个连接请求,但是由于某种原因导致服务器没有收到请求,客户端可能会认为连接已经建立,但是服务器并不知道。如果后来有其他客户端向服务器发送请求,而请求中恰好包含了与之前客户端相同的源地址和端口号,那么服务器就会误认为这是之前客户端发送的请求,从而建立连接,这就导致了历史连接的延续,可能会给网络带来安全隐患。因此,为了保证连接的可靠性和安全性,TCP采用了三次握手的方式建立连接。
52、Mysql中有哪几种锁?
MyISAM 支持表锁,InnoDB 支持表锁和行锁,默认为行锁。
表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量 最低。
行级锁:开销大,加锁慢,会出现死锁。锁力度小,发生锁冲突的概率小,并发度最高。
53、Mysql支持事务吗?
在缺省模式下,MYSQL 是 autocommit 模式的,所有的数据库更新操作都会即时提交,所 以在缺省情况下,mysql 是不支持事务的。但是如果你的 MYSQL 表类型是使用 InnoDB Tables 或 BDB tables 的话,你的 MYSQL 就可以 使用事务处理,使用 SET AUTOCOMMIT=0 就可以使 MYSQL 允许在非 autocommit 模式,在非 autocommit 模式下,你必须使用 COMMIT 来提交你的更改,或者用 ROLLBACK 来回滚你的 更改。更多精彩文章请关注公众号『Pythonnote』或者『全栈技术精选』
示例如下:
START TRANSACTION;
SELECT @A:=SUM(salary) FROM table1 WHERE type=1;
UPDATE table2 SET summmary=@A WHERE type=1;
COMMIT;
54、Mysql查询是否区分大小写?
不区分。
55、列设置为 AUTO INCREMENT 时,如果在表中达到最大值,会发生什么情况?
答:它会停止递增,任何进一步的插入都将产生错误,因为密钥已被使用。
56、一张表,里面有 ID 自增主键,当 insert 了 17 条记录之后,删除了第 15,16,17 条记录, 再把 Mysql 重启,再 insert 一条记录,这条记录的 ID 是 18 还是 15 ?
如果表的类型是 MyISAM,那么是 18。因为 MyISAM 表会把自增主键的最大 ID 记录到数据文件里,重启 MySQL 自增主键的最大ID 也不会丢失。
如果表的类型是 InnoDB,那么是 15。InnoDB 表只是把自增主键的最大 ID 记录到内存中,所以重启数据库或者是对表进行 OPTIMIZE 操作,都会导致最大 ID 丢失。
57、数据库三范式是什么?
第一范式(1NF):字段具有原子性,不可再分。(所有关系型数据库系 统都满足第一范式数据库表中的字段都是单一属性的,不可再分)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足 第二范式(2NF)必须先满足第一范式(1NF)。要求数据库表中的每 个实例或行必须可以被惟一地区分。通常需要为表加上一个列,以存储 各个实例的惟一标识。这个惟一属性列被称为主关键字或主键。
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
所以第三范式具有如下特征:
- 每一列只有一个值
- 每一行都能区分
- 每一个表都不包含其他表已经包含的非主关键字信息
58、mysql 的复制原理以及流程?
答:Mysql 内建的复制功能是构建大型,高性能应用程序的基础。将 Mysql 的数据 分布到多个系统上去,这种分布的机制,是通过将 Mysql 的某一台主机的数据 复制到其它主机(slaves)上,并重新执行一遍来实现的。* 复制过程中一 个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将 更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志 可以记录发送到从服务器的更新。当一个从服务器连接主服务器时,它通知主 服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生 的任何更新,然后封锁并等待主服务器通知新的更新。 过程如下 :1. 主服务器 把更新记录到二进制日志文件中。 2. 从服务器把主服务器的二进制日志拷贝 到自己的中继日志(replay log)中。 3. 从服务器重做中继日志中的时间, 把更新应用到自己的数据库上。
59、mysql 中 myISAM与 innodb 的区别?
- 事务支持 > MyISAM:强调的是性能,每次查询具有原子性,其执行数 度比 InnoDB 类型更快,但是不提供事务支持。> InnoDB:提供事 务支持事务,外部键等高级数据库功能。具有事务(commit)、回滚 (rollback)和崩溃修复能力(crash recovery capabilities)的事务安全 (transaction-safe (ACID compliant))型表。
- InnoDB 支持行级锁,而 MyISAM 支持表级锁. >> 用户在操作 myisam 表时,select,update,delete,insert 语句都会给表自动 加锁,如果加锁以后的表满足 insert 并发的情况下,可以在表的尾部插 入新的数据。
- InnoDB 支持 MVCC, 而 MyISAM 不支持。
- InnoDB支持外键,而MyISAM不支持。
- 表主键 > MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。> InnoDB:如果没有设定主键或者非空唯一索引,就会 自动生成一个
- 字节的主键(用户不可见),数据是主索引的一部分,附 加索引保存的是主索引的值。 6.InnoDB不支持全文索引,而MyISAM支持。
- 可移植性、备份及恢复 > MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进 行操作。> InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十 G 的时候就相对痛苦了。
- 存储结构 > MyISAM:每个 MyISAM 在磁盘上存储成三个文件。第一 个文件的名字以表的名字开始,扩展名指出文件类型。.frm 文件存储表 定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名 是.MYI (MYIndex)。> InnoDB:所有的表都保存在同一个数据文件 中(也可能是多个文件,或者是独立的表空间文件),InnoDB 表的大 小只受限于操作系统文件的大小,一般为 2GB。
60、MySQL 中 InnoDB 支持的四种事务隔离级别名称,以及逐级之间的区 别?
- Read Uncommitted(读取未提交内容) >> 在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
- Read Committed(读取提交内容) >> 这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的 commit,所以同一 select 可能返回不同结果。
- Repeatable Read(可重读) >> 这是 MySQL 的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读(Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影”行。InnoDB 和 Falcon 存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control 间隙锁)机制解决了该问题。注:其实多版本只是解决不可重复读问题,而加上间隙锁(也就是它这里所谓的并发控制)才解决了幻读问题。
- Serializable(可串行化) >> 这是最高的隔离级别,它通过强制事务 排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个 读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。

61、什么是索引?请简述常用的索引有哪些种类?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则在表中搜索所有的行相比,索引有助于更快地获取信息
通俗的讲,索引就是数据的目录,就像看书一样,假如我想看第三章第四节的内容,如果有目录,我直接翻目录,找到第三章第四节的页码即可。如果没有目录,我就需要将从书的开头开始,一页一页翻,直到翻到第三章第四节的内容。
1、MySQL索引的分类
我们根据对以列属性生成的索引大致分为两类:
单列索引:以该表的单个列,生成的索引树,就称为该表的单列索引
组合索引:以该表的多个列组合,一起生成的索引树,就称为该表的组合索引。
2、单列索引又有具体细的划分:
主键索引:以该表主键生成的索引树,就称为该表的主键索引。
唯一索引:以该表唯一列生成的索引树,就称为该表的唯一索引。
普通索引:以该表的普通列(非主键,非唯一列)生成的索引树,就称为该表的普通索引。
全文索引
62、索引是个什么样的数据结构呢?
答:索引的数据结构和具体存储引擎的实现有关, 在MySQL中使用较多的索引有Hash索引,B+树索引等。
而我们经常使用的InnoDB存储引擎的默认索引实现为:B+树索引。
63、Hash索引和B+树所有有什么区别或者说优劣呢?
答:首先要知道Hash索引和B+树索引的底层实现原理:
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。
B+树底层实现是多路平衡查找树,对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。
那么可以看出他们有以下的不同:
hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
hash索引不支持使用索引进行排序,原理同上。
hash索引不支持模糊查询以及多列索引的最左前缀匹配.原理也是因为hash函数的不可预测,AAAA和AAAAB的索引没有相关性。
hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
hash索引虽然在等值查询上较快,但是不稳定,性能不可预测。当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。而不需要使用hash索引。
64、上面提到了B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据,什么是聚簇索引?
答:在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引.。在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引,如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询。
65、非聚簇索引一定会回表查询吗?
答:不一定。这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
66、对MySQL的锁了解吗?
答:当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制。
就像酒店的房间,如果大家随意进出,就会出现多人抢夺同一个房间的情况,而在房间上装上锁,申请到钥匙的人才可以入住并且将房间锁起来,其他人只有等他使用完毕才可以再次使用。
67、MySQL都有哪些锁呢?像上面的例子进行锁定岂不是有点阻碍并发效率了?
答:从锁的类别上来讲,有共享锁和排他锁。
共享锁:又叫做读锁,当用户要进行数据的读取时,对数据加上共享锁,共享锁可以同时加上多个。
排他锁:又叫做写锁,当用户要进行数据的写入时,对数据加上排他锁,排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。
用上面的例子来说就是用户的行为有两种,一种是来看房,多个用户一起看房是可以接受的。一种是真正的入住一晚,在这期间,无论是想入住的还是想看房的都不可以。锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁。他们的加锁开销从大大小,并发能力也是从大到小。
68、MySQL的binlog有有几种录入格式?分别有什么区别?
答:有三种格式,statement,row和mixed。
statement模式下,记录单元为语句。即每一个sql造成的影响会记录,由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
row级别下,记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大。
mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
69、一条sql执行过长的时间,你如何优化,从哪些方面?
1、查看 sql 是否涉及多表的联表或者子查询,如果有,看是否能进行业务拆分,相关字段冗余或者合并成临时表(业务和算法的优化)。
2、涉及链表的查询,是否能进行分表查询,单表查询之后的结果进行字段整合。
3、如果以上两种都不能操作,非要链表查询,那么考虑对相对应的查询条件做索引。加快查询速度。
4、针对数量大的表进行历史表分离(如交易流水表)。
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,mysql 有自带的 binlog 实现主从同步。
6、explain 分析 sql 语句,查看执行计划,分析索引是否用上,分析扫描行数等等。
7、查看 mysql 执行日志,看看是否有其他方面的问题。
上面我将 explain 关键字加粗显示,就是很多面试官他并不直接问你 sql 优化,他会问你知道什么是 mysql 的执行计划吗?其实就是想考你知不知道 explain 关键字,所以乡亲们对 explain 这个不了解的,还需要自己线下去网上查看学习一下哦。
70、Redis支持哪几种数据类型?
答:Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
还有一些数据结构如HyperLogLog、Geo、Pub/Sub等,我们也最好知道,另外像Redis Module,像BloomFilter,RedisSearch,Redis-ML等,能有个印象,哪怕知其然不知其所以然也比听都没听过好点。
71、Redis有哪几种淘汰策略?
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
no-eviction:当内存不足以容纳新写入数据时,新写入操作会报错。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
注意这里的6种机制,volatile和allkeys规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的lru、ttl以及random是三种不同的淘汰策略,再加上一种no-enviction永不回收的策略。
使用策略规则:
-
如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru
-
如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
72、为什么 Redis 需要把所有数据放到内存中?
答:Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征,如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的 性能。
在内存越来越便宜的今天,redis 将会越来越受欢迎, 如果设置了最大使用的内存,则数据已有记录数达 到内存限值后不能继续插入新值。
73、Redis 有哪些适合的场景?
(1)会话缓存(Session Cache)
最常用的一种使用 Redis 的情景是会话缓存(sessioncache),用 Redis 缓存会话比其他存储(如Memcached)的优势在于:Redis 提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的 购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用 Redis 来缓存会话的文档。甚至广为 人知的商业平台 Magento 也提供 Redis 的插件。
(2)全页缓存(FPC)
除基本的会话 token 之外,Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实 例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地FPC。
再次以 Magento 为例,Magento 提供一个插件来使用 Redis 作为全页缓存后端。此外,对 WordPress 的用户来说,Pantheon 有一个非常好的插件 wp-redis,这个插件能帮助你以最快 速度加载你曾浏览过的页面。
(3)队列
Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列 平台来使用。Redis 作为队列使用的操作,就类似于本地程序语言(如 Python)对 list 的 push/pop操作。
如果你快速的在 Google 中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的 就是利用 Redis 创建非常好的后端工具,以满足各种队列需求。例如,Celery 有一个后台就是使用Redis 作为 broker,你可以从这里去查看。
(4)排行榜/计数器
Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(SortedSet)也使 得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的 10 个用户–我们称之为“user_scores”,我们只需要像 下面一样执行即可: 当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执 行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games 就是一个很好的例子,用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的,你可 以在这里看到。
(5)发布/订阅
最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见 人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用 Redis 的发布/订阅功能来建 立聊天系统!
74、说说 Redis 哈希槽的概念?
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通 过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
edis 集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有 N-1 个复制品。
75、Redis 集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
76、Redis 集群之间是如何复制的?
答:异步复制
77、Redis 中的管道有什么用?
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应,这样就可以将多个命令发送到服务 器,而不用等待回复,最后在一个步骤中读取该答复。这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多 POP3 协议已经实现支持这个功 能,大大加快了从服务器下载新邮件的过程。
78怎么理解 Redis 事务?
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行,事务在执行的过程中,不会 被其他客户端发送来的命令请求所打断。
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
79、Redis 事务相关的命令有哪几个?
MULTI、EXEC、DISCARD、WATCH
MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
EXEC:执行事务中的所有操作命令。
DISCARD:取消事务,放弃执行事务块中的所有命令。
WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
UNWATCH:取消WATCH对所有key的监视。
80、Redis key 的过期时间和永久有效分别怎么设置?
EXPIRE 和 PERSIST 命令
81、Redis 如何做内存优化?
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该 尽可能的将你的数据模型抽象到一个散列表里面。比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的 key,而是 应该把这个用户的所有信息存储到一张散列表里面。
82、Redis 回收进程如何工作的?
一个客户端运行了新的命令,添加了新的数据。Redi 检查内存使用情况,如果大于 maxmemory 的限制, 则根据设定好的策略进行回收。一个新的命令被执行,等等。所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限 制就会被这个内存使用量超越。
83、Redis集群最大节点个数是多少?
答:16384个。
83、Redis集群如何选择数据库?
答:Redis集群目前无法做数据库选择,默认在0数据库。
84、Redis的内存用完了会发生什么?
答:如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以将Redis当缓存来使用配置淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
85、如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
答:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
86、如果有大量的key需要设置同一时间过期,一般需要注意什么?
答:如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
87、Redis 集群方案应该怎么做?都有哪些方案?
codis:目前用的最多的集群方案,基本和 twemproxy 一致的效果,但它支持在节点数量改变情况下,旧节点数据可恢复到新 hash 节点。
redis cluster3.0 自带的集群,特点在于他的分布式算法不是一致性 hash,而是 hash 槽的概念,以及自身支持节点设置从节点。具体看官方文档介绍。
在业务代码层实现,起几个毫无关联的 redis 实例,在代码层,对 key 进行 hash 计算,然后去对应的redis 实例操作数据。这种方式对 hash 层代码要求比较高,考虑部分包括,节点失效后的替代算法方案,数据震荡后的自动脚本恢复,实例的监控,等等。
88、使用过 Redis 分布式锁么,它是怎么实现的?
答:先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。
89、如果在 setnx 之后执行 expire 之前进程意外 crash 或者要重启维护了,那会怎么样?
答:set 指令有非常复杂的参数,这个应该是可以同时把 setnx 和 expire 合成一条指令来用的!
90、使用过 Redis 做异步队列么,你是怎么用的?有什么缺点?
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。
缺点:在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 rabbitmq 等。
能不能生产一次消费多次呢?
使用 pub/sub 主题订阅者模式,可以实现 1:N 的消息队列。
91、缓存穿透、缓存击穿、缓存雪崩解决方案?
缓存穿透:指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将 导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。
解决方案:
1.查询返回的数据为空,仍把这个空结果进行缓存,但过期时间会比较短;
2.布 隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据 会被这个 bitmap 拦截掉,从而避免了对 DB 的查询。
缓存击穿:对于设置了过期时间的 key,缓存在某个时间点过期的时候,恰好这时间点对 这个 Key 有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并 回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案:
1.使用互斥锁:当缓存失效时,不立即去load db,先使用如Redis的setnx去设 置一个互斥锁,当操作成功返回时再进行load db的操作并回设缓存,否则重试get缓存的 方法。
2.永远不过期:物理不过期,但逻辑过期(后台异步线程去刷新)。
缓存雪崩:设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部 转发到 DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多 key,击穿是某一个key 缓存。
解决方案:
将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值, 比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效 的事件。
92、为什么redis单线程还是那么快?
答:redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
93、使用 redis 如何设计分布式锁?说一下实现思路?使用 zk 可以吗?如何实现?这两种有什 么区别?
redis:
1.线程 A setnx(上锁的对象,超时时的时间戳 t1),如果返回 true,获得锁。
2.线程 B 用 get 获取 t1,与当前时间戳比较,判断是是否超时,没超时 false,若超时执行第 3 步。
3.计算新的超时时间 t2,使用 getset 命令返回 t3(该值可能其他线程已经修改过),如果t1==t3,获得锁,如果 t1!=t3 说明锁被其他线程获取了。4.获取锁后,处理完业务逻辑,再去判断锁是否超时,如果没超时删除锁,如果已超时, 不用处理(防止删除其他线程的锁)。
zk:
1.客户端对某个方法加锁时,在 zk 上的与该方法对应的指定节点的目录下,生成一个唯一 的瞬时有序节点 node1。
2.客户端获取该路径下所有已经创建的子节点,如果发现自己创建的 node1 的序号是最小 的,就认为这个客户端获得了锁。
3.如果发现 node1 不是最小的,则监听比自己创建节点序号小的最大的节点,进入等待。
4.获取锁后,处理完逻辑,删除自己创建的 node1 即可。
区别:zk 性能差一些,开销大,实现简单。
94、知道 redis 的持久化吗?底层如何实现的?有什么优点缺点?
RDB(Redis DataBase:在不同的时间点将 redis 的数据生成的快照同步到磁盘等介质上):内存 到硬盘的快照,定期更新。缺点:耗时,耗性能(fork+io 操作),易丢失数据。AOF(Append Only File:将redis所执行过的所有指令都记录下来,在下次redis重启时,只 需要执行指令就可以了):写日志。缺点:体积大,恢复速度慢。
bgsave 做镜像全量持久化,aof 做增量持久化。因为 bgsave 会消耗比较长的时间,不够实 时,在停机的时候会导致大量的数据丢失,需要 aof 来配合,在 redis 实例重启时,优先使 用 aof 来恢复内存的状态,如果没有 aof 日志,就会使用 rdb 文件来恢复。Redis 会定期做aof 重写,压缩 aof 文件日志大小。Redis4.0 之后有了混合持久化的功能,将 bgsave 的全量 和 aof 的增量做了融合处理,这样既保证了恢复的效率又兼顾了数据的安全性。bgsave 的 原理,fork 和 cow, fork 是指 redis 通过创建子进程来进行 bgsave 操作,cow 指的是 copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据 会逐渐和子进程分离开来。
95、为什么要做Redis分区?
答:分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
96、你知道有哪些Redis分区实现方案?
答:客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
1.代理分区意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
2.查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
97、Redis分区有什么缺点?
涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
同时操作多个key,则不能使用Redis事务。
分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集(The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set)。
当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis实例和主机同时收集RDB / AOF文件。
分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
98、Redis持久化数据和缓存怎么做扩容?
答:如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
99、redis的并发竞争问题如何解决?
答:Redis为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争,但是在Jedis客户端对Redis进行并发访问时会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。
对此有2种解决方法:
1.客户端角度,为保证每个客户端间正常有序与Redis进行通信,对连接进行池化,同时对客户端读写Redis操作采用内部锁synchronized。2.服务器角度,利用setnx实现锁。
注:对于第一种,需要应用程序自己处理资源的同步,可以使用的方法比较通俗,可以使用synchronized也可以使用lock;第二种需要用到Redis的setnx命令,但是需要注意一些问题。
100、简述redis的哨兵模式
答:哨兵是对redis进行实时的监控,主要有两个功能。
监测主数据库和从数据库是否正常运行。
当主数据库出现故障的时候,可以自动将一个从数据库转换为主数据库,实现自动切换。
101、redis的哨兵的监控机制是怎样的?
答:哨兵监控也是有集群的,会有多个哨兵进行监控,当判断发生故障的哨兵达到一定数量的时候才进行修复。一个健壮的部署至少需要三个哨兵实例。
1.每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令
2.如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
3.如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4.当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线
5.在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令
6.当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
7.若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
102、说出request里面几个常用的属性
a)查询参数 args:url地址上最后面传给服务器的参数
b)请求数据data:就是客户端发送给服务器的原始数据(raw原始数据)
c)上传的文件 files:前端上传给后台发送的文件是什么
d)表单 form: 就是表单数据
e)Cookie:浏览器状态保持的一种
联想回答:
request是什么?request是请求的意思,请求方式常用的有get和post,get请求,get请求向后台取,post向后台传,post安全,请求信息不像get请求那样暴露在url地址上,比较安全,http协议默认post请求是安全的,所以需要csrf验证(讲到这可以说什么是csrf验证,如何解决,解决的原理是什么),同时request也是flask请求上下文的一种,什么是上下文?就是一个保存了前端和后台连接状态的容器,他里面存放了什么呢,回归正题,就是上面的几个属性(绕一圈子,再回来,第一面试官觉得你能侃,能聊,知识面不错,印象加分)
103、说出HTTP状态保持的原理
a)在用户登录之后,服务器返回响应的时候会在响应中添加上cookie
b)浏览器接收到cookie之后会自动保存
c)当用户再次请求其他网页的时候,浏览器会自动带上之前保存的cookie
d)服务器接收到请求之后可以到 request 对象中取到cookie 判断当前用户是否登录
联想回答:
HTTP是无状态的,就是连接时数据互通,关闭后就是永别,永久性失忆,为啥是无状态的呢?因为浏览器和服务器之间用的是socket通信的啊,一旦关闭浏览器,四次挥手之后就销毁所有交互信息(谈谈tcp三次握手,四次挥手)那么让浏览器跟服务器之间保持状态的方法是什么呢,cookie和session区别:cookie保 存在浏览器,每次访问网站都会将本地保存cookies值(用户个人信息)发送到网站,不安全,每个域名下的cookie独立存在,互不干扰。seesion依赖cookie存在,但它保存在服务器上,比cookie更安全,细节:session存的数字不会转成字符串,而cookie存值会转为字符串
104、说出CSRF 攻击的原理和防范措施
a)攻击原理:
i.用户C访问正常网站A时进行登录,浏览器保存A的cookie
ii.用户C再访问攻击网站B,网站B上有某个隐藏的链接或者图片标签会自动请求网站A的URL地址,例如表单提交,传指定的参数
iii.而攻击网站B在访问网站A的时候,浏览器会自动带上网站A的cookie
iv.所以网站A在接收到请求之后可判断当前用户是登录状态,所以根据用户的权限做具体的操作逻辑,造成网站攻击成功
b)防范措施:
i.在指定表单或者请求头的里面添加一个随机值做为参数
ii.在响应的cookie里面也设置该随机值
iii.那么用户C在正常提交表单的时候会默认带上表单中的随机值,浏览器会自动带上cookie里面的随机值,那么服务器下次接受到请求之后就可以取出两个值进行校验
iv.而对于网站B来说网站B在提交表单的时候不知道该随机值是什么,所以就形成不了攻击
联想回答:
什么是csrf攻击?简单来说就是: 你访问了信任网站A,然后A会用保存你的个人信息并返回给你的浏览器一个cookie,然后呢,在cookie的过期时间之内,你去访问了恶意网站B,它给你返回一些恶意请求代码,要求你去访问网站A,而你的浏览器在收到这个恶意请求之后,在你不知情的情况下,会带上保存在本地浏览器的cookie信息去访问网站A,然后网站A误以为是用户本身的操作,导致来自恶意网站C的攻击代码会被执:发邮件,发消息,修改你的密码,购物,转账,偷窥你的个人信息,导致私人信息泄漏和账户财产安全收到威胁
如何解决?在psot请求时,form表单或ajax里添加csrf_token(实际项目代码里就是如此简单)
解决原理:添加csrf_token值后,web框架会在响应中自动帮我们生成cookie信息,返回给浏览器,同时在前端代码会生成一个csrf_token值,然后当你post提交信息时,web框架会自动比对cookie里和前端form表单或ajax提交上来的csrf_token值,两者一致,说明是当前浏览器发起的正常请求并处理业务逻辑返回响应,那么第三方网站拿到你的cookie值为什么不能验证通过呢?因为他没你前端的那个随机生成的token值啊,他总不能跑到你电脑面前查看你的浏览器前端页面自动随机生成的token值吧
注意:你打开浏览器访问某个url(页面),默认是get请求,也就是说,你只要访问了url,对应的视图函数里只要不是if xx == post的逻辑就会执行,所以你打开页面,他会先生成cookie(token)值,返回给浏览器, 然后你提交表单,或者发ajax请求时,会将浏览器的cookie信息(token值)发送给服务器进行token比对,这个过程相对于你发起了两次请求,第一次是get,第二次才是post,搞清楚这个,你才能明白csrf怎么比对的
![[E2E Test] Python Behave Selenium 一文学会自动化测试](https://img-blog.csdnimg.cn/63523df800b547af9d30f35f44e83dd5.png)