客户端发现pod并与之通信
pod需要一种寻找其他pod的方法来使用其他pod提供的服务,不像在没有Kubernetes的世界,系统管理员要在用户端配置文件中明确指出服务的精确IP地址 或者主机名来配置每个客户端应用,但同样的方法在Kubernetes中不适用
-
pod是短暂的: 他们随时会启动或关闭,无论是给其他pod提供空间而从节点被移除,或者是减少了pod的数量,又或者是因为集群中存在节点异常
-
Kubernetes在pod启动前会给已经调度到节点上的pod分配IP地址——因此客户端不能提前知道供应的pod IP地址
-
水平伸缩意味着多个pod可能会提供相同的服务——每个pod都有自己的IP地址,所有pod可以通过一个单一的IP地址进行访问
介绍服务
Kubernetes服务是一种为一组功能相同的pod提供单一不变接入点的资源。K8s会通过网络插件为服务分配IP和端口,并且IP和端口不会发生变化。可以通过访问服务的IP或者服务名连接到提供服务的pod,这样提供服务的pod可以根据需要移动或删除,而不会影响外部客户端访问
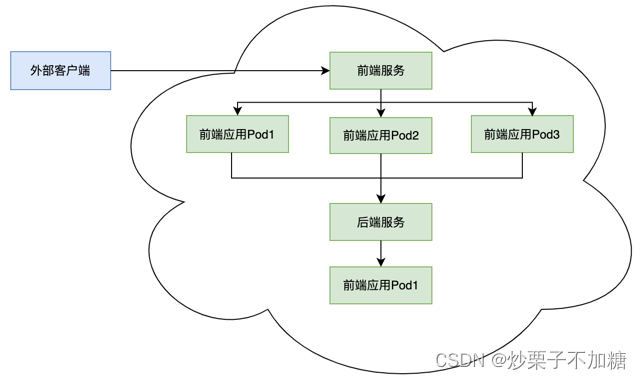
通过为前端应用pod提供前端服务资源,外部客户可以通过前端服务访问到前端应用pod,即使前端应用pod被移除后重新创建导致IP发生变化,也可以通过服务路由到新的前端应用pod,而前端服务可以通过节点IP、端口等方式提供稳定的外部访问,同时前端服务资源会分配一个稳定的内部IP,内部pod可以通过稳定的内部IP访问前端服务并路由到前端应用pod。前端应用pod要访问后端pod,也可以为后端pod提供服务资源,前端应用pod只需要通过后端服务的内部固定IP, 就可以访问到后端应用pod
为应用pod创建服务提供稳定访问入口
可以为一组应用pod创建服务资源,其它外部客户端或内部pod可以通过服务访问到应用pod,并且服务资源提供负载均衡的能力。但服务资源如何确定其需要负载均衡的pod?类似rc资源与其控制pod的关联方式,服务资源同样通过标签选择器确定其需要负载均衡的pod
通过YAML描述文档来创建服务
除了前面提到的kubectl expose命令创建服务暴露pod,还可以通过service资源描述文件创建service。如下创建名为kubia-svc.yaml文件
apiVersion: v1
kind: Service
metadata:name: kubia
spec:ports:- port: 80 #该服务的端口targetPort: 8080 #服务将连接转发到的容器端口selector:app: kubia #具有app=kubia标签的pod都属于该服务
-
该yaml文件创建一个名为kubia的服务,它将在端口80接收请求并将连接路由到具有标签选择器app=kubia的pod的8080端口上
-
使用kubectl create或kubectl apply可以根据上面描述文件创建服务资源
使用一下命令列出所有服务资源
kubectl get svc -n 命名空间名称
从内部集群测试服务
可以通过以下几种方法向服务发送请求:
-
创建一个pod,将请求发送到服务器的集群IP并记录响应,可以通过查看pod日志检查服务的响应
-
使用ssh远程登录到其中一个kubernetes节点上,然后使用curl命令
-
通用kubectl exec命令在一个已经存在的pod中执行curl命令
在运行的容器中远程执行命令
可以使用kubectl exec命令远程地在一个已经存在的pod容器上执行任何命令,可以方便的了解pod内容、状态、环境。
kubectl exec pod名 -- curl -s IP地址
注: 双横杠(–)代表着kubectl命令项的结束,在双横杠之后的内容是指在pod内部需要执行的命令。如果后面需要执行的命令没有以横杠开始的参数, 也可以不用使用–
整个请求流程:curl请求服务在集群内的Ip地址及默认80端口,K8s集群服务代理截取请求,并通过负载策略选取其管理的pod中的一个,将请求重定向到选取的提供服务的pod,pod接收请求并由运行的应用处理请求,返回处理的pod名称信息响应到curl,curl将返回信息打印到标准输出
配置服务上的会话亲和性
通过请求被服务均匀的路由到pod,即使是同一个客户端发出的多次请求,也回分散在多个pod处理,而不是一个,这通常是符合预期的。但如果希望特定客户端所产生的所有请求每次都指向同一个pod,可以设置服务sessionAffinity属性为ClientIP (默认None ,随机指向pod 中的一个),这对有会话亲和性需求 的应用是必须的
apiVersion: v1
kind: Service
spec:sessionAffinity: ClientIPsessionAffinityConfig:clientIP:timeoutSeconds: 10...
-
sessionAffinity:默认None,当设置为ClientIP则根据IP会话亲和,来自同一个client IP的所有请求都会被转发至同一个pod。除这两种之外不支持其他类型的会话亲和性。K8s服务不再HTTP层面上工作,服务处理TCP和UDP包,并不关心其中负载,因此不支持cookie会话亲和性,cookie是HTTP协议的一部分
-
sessionAffinityConfig.clientIP.timeoutSeconds:配置会话亲和的有效时间时间,单位秒,默认3小时
同一个服务暴露多个端口
可以在一个服务中暴露多个端口,无需创建多个服务。但在创建一个有多个端口的服务的时候,必须给每个端口指定名字
apiVersion: v1
kind: Service
metadata:name: kubia
spec:ports:- name: http #端口名port: 80 #服务暴露端口targetPort: 8080 #服务转发pod接收端口- name: httpsport: 443targetPort: 8443selector: #标签选择器app: kubia
- 标签选器应用于整个服务,不能对每个端口做单独的配置。如果不同的pod有不同的端口映射关系,需要创建两个服务
使用命名的端口
在服务spec中可以用数字指定端口,也可以给端口命名,通过名称来指定端口
在pod的定义中指定pod
kind: Pod
spec:containers:- name: kubiaports:- name: httpcontainerPort: 8080- name: httpscontainerPort: 8443
- 通过spec.containers[n].ports[n].name指定容器端口名称
在服务spec中按名称引用这些端口
apiVersion: v1
kind: Service
spec:ports:- name: httpport: 80targetPort: http- name: httpsport: 443targetPort: https
-
targetPort:指定需要转发的接口,即支持直接给定端口值,也支持端口名称指定端口
-
使用端口名称引用,可以屏蔽端口变更对引用处的影响
服务发现
通过创建服务,现在就可以通过一个单一稳定的IP地址访问到pod,在服务整个生命周期内这个地址保持不变,在服务后的pod可能删除重建,它们的IP地址可能改变,数量可能增减,但是始终可以通过服务的单一不变的IP地址访问到这些pod。但如果删除service之后又重新创建service,新创建的service会分配新的集群内IP
通过环境变量发现服务
在pod开始运行的时候,Kubernetes会初始化一系列的环境变量指向现在存在的服务。如果你创建的服务早于你客户端pod的创建,pod上的进程可以根据环境变量获取服务IP地址和端口号
查看pod环境变量
kubectl exec pod名 env -n 命名空间名称
通过执行上面命令,可以看到pod中环境变量中服务相关的环境变量如下:
- {serviceName}_SERVICE_HOST: 服务IP地址
- {serviceName}_SERVICE_PORT: 服务端口号
- 服务名称中的横杠被转换为下划线,服务名称用作环境变量名称的前缀时,会转换为大写
通过DNS发现服务
在每个命名空间都包含一个kube_dns服务,这个服务运行DNS服务,在集群中其他pod都被配置成使用其作为dns(Kubernetes通过修改每个容器 /etc/resolv.conf文件实现)。运行在pod上的进程DNS查询都会被Kubernetes自身的DNS服务器响应,该服务知道系统中运行的所有服务
注:pod是否使用内部DNS服务器是根据pod中spec的dnsPolicy属性来决定
每个服务从内部DNS服务器中获取一个DNS条目,客户端的pod在知道服务名情况下可以通过全限定域名(FQDN)来访问,而不是环境变量
通过FQDN连接服务
可以通过以下方式访问其他服务:
- {serviceName}.{命名空间}.{所有集群本地服务名称中使用的可配置集群域后缀}
- 进入一个pod中执行curl http://kubia.{命名空间}.svc.cluster.local 访问名为kubia的服务
注:客户端仍然必须知道服务的端口号。如果服务使用标准端口号(例如,HTTP的80端口或Postgres的5432端口),不需指定端口,如果并不是标准端口,客户端可以从环境变量中获取端口号
如果访问的服务在同一个命名空间下,可以省略命名空间及所有集群本地服务名称中使用的可配置集群域后缀,直接用服务名指代服务
在pod容器中运行shell
登陆pod容器运行shell
kubectl exec -it pod名 bash
注:/etc/resolv.conf存储DNS解析器配置方式
无法ping通服务的原因
服务集群IP是一个虚拟IP,并且只有在与服务端口结合时才有意义
连接集群外部的服务
介绍服务endpoit
服务并不是和pod直接相连,相反有一种资源介于两者之间——它就是Endpoint资源。Endpoint资源就是暴露一个服务的IP地址和端口列表, Endpoint资源和其他Kubernetes资源一样,可以使用kubectl get来获取他的基本信息
kubectl get endpoints 服务名 -n 命名空间
尽管在spec服务中定义了pod选择器,但重定向传入连接时不会直接使用它。相反选择器用于构建IP和端口列表,然后存储在Endpoint资源中。当客户端连接到服务时,服务代理选择这些IP和端口对中的一个,并将传入连接重定向在该位置监听的服务器
可以看到endpoints资源ENDPOINTS列,列出了service资源选择器匹配的pod的IP:端口信息
手动配置服务的endpoint
服务的endpoint与服务解耦后,可以分别配置和更新他们。如果创建了不包含pod选择器的服务,Kubernetes将不会创建Endpoint资源。 这样就需要创建Endpoint资源来指定该服务的endpoint列表
要使用手工配置endpoint的方式创建服务,需要创建服务和Endpoint资源
创建没有选择器的服务
服务yaml资源描述文件如下
apiVersion: v1
kind: Service
metadata:name: external-service
spec:ports:- port: 80
-
metadata.name:服务名称,需要与Endpoints类型资源名称相同
-
spec.ports[n].port:指定服务接收请求的端口
为没有选择器的服务创建Endpoint资源
Endpoint是一个单独的资源并不是服务的一个属性。由于创建的资源中不包含选择器,相关的Endpoint资源并没有自动创建,所以必须手动创建
apiVersion: v1
kind: Endpoints
metadata:name: external-service
subsets:- addresses:- ip: 11.11.11.11- ip: 22.22.22.22ports:- port: 80
-
metadata.name:Endpoints类型资源的名称,需要与服务名称相同
-
subsets[n].addresses[n]:将服务接收的连接重定向到列出的ip
-
subsets[n].ports[n]:重定向的目标端口
服务和Endpoint资源都发布到服务器后,这样服务就可以像具有pod选择器那样的服务正常使用。在服务创建后创建的容器将包含服务的环境变量,并且与其IP:port对的所有连接都将在服务端点之间进行负载均衡
为外部服务创建别名
创建ExternalName类型的服务
要创建一个具有别名的外部服务的服务时,要将创建服务资源的一个type字段设置为ExternalName
apiVersion: v1
kind: Service
metadata:name: external-service
spec:type: ExternalNameexternalName: baidu.comports:- port: 80
-
spec.type:设置类型为ExternalName,将创建一个具有别名的外部服务
-
spec.externalName:外部可访问的完全限定域名
服务创建完成后,pod可以通过external-service.default.svc.cluster.local域名连接到外部服务,而不是使用服务的实际FQDN,这隐藏了实际的服务名及其使用该服务的pod的位置,允许修改服务定义,并且以后如果将其指向不同的服务,只需要简单修改externalName属性,或者将类型重新变回ClusterIP并为服务创建Endpoint
ExternalName服务仅在DNS级别实施-为服务创建简单的CNAME DNS记录。因此连接到服务的客户端将直接连接到外部服务,完全绕过服务代理,出于这个原因,这类服务器甚至不会获得集群IP
注:CNAME记录指向完全限定的域名而不是数字IP地址
将服务暴露给外部客户端
上面提到的暴露服务都只能在集群内部访问,如下几种方式可以在外部访问服务:
-
当类型为ClusterIP时,通过配置externalIPs为节点ip,也可以通过节点ip:服务端口访问
-
将服务的类型设置为NodePort:每个集群节点都会在节点上打开一个端口,对于NodePort服务,每个集群节点本身上打开一个端口,并将端口上接收到的流量重定向到基础服务。该服务仅在内部集群IP和端口上才可访问,但也可以通过所有节点上的专用端口访问
-
将服务的类型设置成LoadBalance,NodePort类型的一种扩展:这使得服务可以通过一个专用的负载均衡来访问,这是由Kubernetes中正在运行的云基础设施提供。负载均衡器将流量重定向到跨所有节点到节点端口。客户端通过负载均衡器的IP连接到服务
-
创建一个Ingress资源,这是一个完全不同的机制,通过一个IP地址公开多个服务:它运行在HTTP层上,因此可以提供比工作在第四层的服务更多功能
通过externalIPs设置通过集群节点访问
使用如下service资源描述文件通过节点ip访问服务
apiVersion: v1
kind: Service
metadata:name: kubia
spec:type: ClusterIPexternalIPs:- 172.23.16.213ports:- name: httpport: 33456
-
设置类型为ClusterIP
-
externalIPs指定外部IP列表,IP要求能访问到K8s集群节点
-
可以通过访问维护的节点IP+服务端口访问到服务,并将请求发送到服务管理的pod
使用NodePort类型服务
创建NodePort服务,可以让Kubernetes在其所有节点上保留一个端口(所有节点都使用相同的端口号),并将传入的连接转发给作为服务部分的pod
这与常规服务类似(他们的实际类型是ClusterIP),但是不仅可以通过服内部集群IP访问NodePort服务,还可以通过节点的IP和预留节点端点访问NodePort服务
创建NodePort类型服务
创建NodePart服务YAML
apiVersion: v1
kind: Service
metadate:name: kubia-nodeport
spec:type: NodePortports:- port: 80targetPort: 8080nodePort: 30123 #通过集群节点的30123端口可以访问该服务selector:app: kubia
-
spec.type: 将类型设置为NodePort
-
spec.ports[n].port:服务端口号
-
spec.ports[n].targetPort:目标pod端口号
-
spec.ports[n].nodePort: 指定该服务绑定的所有集群节点的节点端口。指定端口不是强制的。如果忽略它,Kubernetes将选择一个随机端口
查看NodePort类型的服务
查看NodePort服务的基础信息
kubectl get svc 服务名 -n 命名空间名称
EXTERNAL-IP列为nodes,表明服务可通过任何集群节点的IP地址访问。PORT列显示服务的集群内端口/节点端口,可通过以下方式访问服务:
-
内部集群IP:服务内部端口号
-
节点IP:节点端口
更改防火墙规则,让外部客户端访问我们的NodePort服务
设置防火墙,以允许外部连接到该端口上的节点
查看节点IP地址
kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="ExternalIP")].address}'
通过指定kubectl的JSONPath,使得其只输出需要的信息
-
浏览item属性中的所有元素
-
对于每个元素,输入status属性
-
过滤addresses属性的元素,仅包含那些具有将type属性设置为ExternalIP的元素
-
最后打印过滤元素的address属性
现在可以通过访问任何节点上的30123端口访问到pod
通过负载均衡器将服务暴露出
通过创建Load Badancer类型服务创建一个负载均衡器服务,提供自己独一无二的可公开访问IP,将所有连接重定向到服务。 如果Kubernetes在不支持 Load
Badancer服务的环境运行,则不会调用负载均衡器,该服务将表现的像一个NodePort服务。Load Badancer服务是NodePort服务的扩展,也可以通过 节点IP+节点端口访问
创建LoadBalance服务
创建负载均衡器服务YAML
apiVerion: v1
kind: Service
metadata:name: kubia-loadbalancer
spec:type: loadBalancerports:- port: 80targetPort: 8080selector:app: kubia
如果没有指定特定的节点端口,kubernetes将会选择一个端口
通过负载均衡器连接服务
创建服务后,云基础框架需要一段时间才能创建负载均衡器并将其IP地址写入服务对象,列为服务的外部IP地址
kubectl get svc kubia-loadbalancer
EXTERNAL-IP列为负载均衡IP地址,可以通过该IP地址访问该服务。不必通过关闭防火墙来访问服务
会话亲和性和Web浏览器
通过网络浏览器访问服务,发现请求都被同一个pod处理,通过kubectl explain可以再次检查服务的会话亲和性仍然设置为None,因为浏览器使用keep-alive连接,并通过单个连接发送所有请求,服务在连接级别工作,所以当首次打开与服务的连接时,会选择一个随机集群,然后将所有属于该连接的所有网络数据包全部发送到单个集群,即使会话亲和性设置为None,用户也始终使用相同pod
了解外部连接的特性
了解并防止不必要的网络跳数
通过服务的spec部分设置externalTrafficPolicy字段设置,当外部客户端通过节点端口连接到服务时,选择当前服务节点上的pod,如果当前服务所在节点没有pod, 则连接将挂起,以阻止额外跳数。所存在的缺点
-
如果接收连接的服务没有pod,连接将挂起
-
导致跨pod的负载均衡分布不均衡
spec:externalTrafficPolicy: Local...
客户端IP是不记录的
当集群内客户端连接到服务时,支持服务的pod可以获取客户端的IP地址,但通过节点端口连接时,由于对数据包执行了源网络地址转换,因此数据包的源IP将发生更改。local外部流量策略会影响客户端IP的保留,因为在接收连接的节点和托管目标pod的节点之间没有额外的跳跃
通过Ingress暴露服务
为什么需要Ingress:Ingress只需要一个公网IP就能为许多服务提供访问,当客户端向Ingress发送HTTP请求时,Ingress会根据请求的主机名和路径决定请求转发到的服务,Ingress在网络栈的应用层操作,并且能提供基于cookie的会话亲和性
Ingress控制器
光有Ingress资源并不能提供服务,Ingress只是定义了根据主机名称+路径的路由规则,而真正去实现路由的是Ingress-controller(Ingress控制器),因此在集群中需要运行Ingress-controller才能正常使用Ingress,不同kubernetes环境使用不同的控制器实现。目前主要的Ingress-controller有如下 两种
-
基于nginx的ingress-controller
-
基于traefix的ingress-controller
nginx-ingress-controller分为K8S社区官方提供的版本和nginx提供的版本
nginx ingress controller工作原理
ingress controller通过与K8s的API进行交互,动态感知K8s集群中ingress服务规则的变化,读取这些规则,并按照规则转发到对应的K8s service上。 在nginx ingress
controller中,会将这些ingress规则生成对应的nginx配置,并将配置动态写入nginx-ingress-controller运行容器的nginx配置 文件中,然后重新加载,使配置生效
安装nginx ingress controller
kubectl apply -f 运行如下配置文件,将在ingress-nginx命名空间下部署nginx ingress controller
apiVersion: v1
kind: Namespace
metadata:name: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---kind: ConfigMap
apiVersion: v1
metadata:name: nginx-configurationnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---
kind: ConfigMap
apiVersion: v1
metadata:name: tcp-servicesnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---
kind: ConfigMap
apiVersion: v1
metadata:name: udp-servicesnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---
apiVersion: v1
kind: ServiceAccount
metadata:name: nginx-ingress-serviceaccountnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:name: nginx-ingress-clusterrolelabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx
rules:- apiGroups:- ""resources:- configmaps- endpoints- nodes- pods- secretsverbs:- list- watch- apiGroups:- ""resources:- nodesverbs:- get- apiGroups:- ""resources:- servicesverbs:- get- list- watch- apiGroups:- ""resources:- eventsverbs:- create- patch- apiGroups:- "extensions"- "networking.k8s.io"resources:- ingressesverbs:- get- list- watch- apiGroups:- "extensions"- "networking.k8s.io"resources:- ingresses/statusverbs:- update---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:name: nginx-ingress-rolenamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx
rules:- apiGroups:- ""resources:- configmaps- pods- secrets- namespacesverbs:- get- apiGroups:- ""resources:- configmapsresourceNames:- "ingress-controller-leader-nginx"verbs:- get- update- apiGroups:- ""resources:- configmapsverbs:- create- apiGroups:- ""resources:- endpointsverbs:- get---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:name: nginx-ingress-role-nisa-bindingnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: nginx-ingress-role
subjects:- kind: ServiceAccountname: nginx-ingress-serviceaccountnamespace: ingress-nginx---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:name: nginx-ingress-clusterrole-nisa-bindinglabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: nginx-ingress-clusterrole
subjects:- kind: ServiceAccountname: nginx-ingress-serviceaccountnamespace: ingress-nginx---apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-ingress-controllernamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx
spec:replicas: 1selector:matchLabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxtemplate:metadata:labels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxannotations:prometheus.io/port: "10254"prometheus.io/scrape: "true"spec:hostNetwork: trueterminationGracePeriodSeconds: 300serviceAccountName: nginx-ingress-serviceaccountcontainers:- name: nginx-ingress-controllerimage: registry.aliyuncs.com/google_containers/nginx-ingress-controller:0.29.0args:- /nginx-ingress-controller- --configmap=$(POD_NAMESPACE)/nginx-configuration- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services- --udp-services-configmap=$(POD_NAMESPACE)/udp-services- --publish-service=$(POD_NAMESPACE)/ingress-nginx- --annotations-prefix=nginx.ingress.kubernetes.iosecurityContext:allowPrivilegeEscalation: truecapabilities:drop:- ALLadd:- NET_BIND_SERVICErunAsUser: 101env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespaceports:- name: httpcontainerPort: 80protocol: TCP- name: httpscontainerPort: 443protocol: TCPlivenessProbe:failureThreshold: 3httpGet:path: /healthzport: 10254scheme: HTTPinitialDelaySeconds: 10periodSeconds: 10successThreshold: 1timeoutSeconds: 10readinessProbe:failureThreshold: 3httpGet:path: /healthzport: 10254scheme: HTTPperiodSeconds: 10successThreshold: 1timeoutSeconds: 10lifecycle:preStop:exec:command:- /wait-shutdown---apiVersion: v1
kind: LimitRange
metadata:name: ingress-nginxnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx
spec:limits:- min:memory: 90Micpu: 100mtype: Container
- spec.template.spec.hostNetwork:指定使用主机网络,可通过主机IP访问到控制器。之后在本地hosts文件中指定域名与Ingress控制器IP映射关系时维护的就是Ingress控制器的监听IP
除使用如上方式安装nginx ingress controller 也可以使用kubeadm-ha部署K8s集群默认就会安装nginx ingress controller
创建Ingress资源
创建Ingress资源YAML
apiVersion: extensions/v1beta1
kind: Ingress
metadata:name: kubia
spec:rules:- host: kubia.example.comhttp:paths:- path: /backend:serviceName: kubia-nodeportservicePort: 80
-
spec.rules[0].host: Ingress将域名kubia.example.com映射到你的服务
-
spec.rules[0].http.paths[0].backend: 将所有请求发送到kubia-nodeport服务80端口
-
除上面给出的extensions/v1beta1下的Ingress定义外,还有networking/v1beta1及networking/v1下Ingress的定义,其配置略有区别,详情看 Kubernetes源码
通过Ingress访问服务
通过域名访问服务,需要确保域名解析为Ingress控制器的IP
通过kubeadm在私有主机上搭建的集群
对于在自己主机上搭建的K8s集群,需要将域名解析成集群节点IP地址,可以维护每个集群节点IP与域名的映射关系,也可以维护部分
通过修改/etc/hosts文件添加域名解析
// 修改/etc/hosts
sudo vim /etc/hosts// 添加Ingress中配置域名与集群IP的映射
集群节点1的IP地址 kubia.example.com
集群节点2的IP地址 kubia.example.com
通过域名访问服务
curl http://kubia.example.com/
云厂商提供的K8s集群
获取Ingress的IP地址
kubectl get ingresses
确保Ingress中配置的Host指向Ingress的IP地址
通过配置DNS服务器将域名解析为Ingress的IP地址。在/etc/hosts中配置即可
了解Ingress的工作原理
客户端通过对域名执行DNS查找,DNS服务器返回Ingress控制器的IP,客户端向Ingress控制器发送HTTP请求,并设置Host头中指定域名,控制器从该头部信息确定客户端尝试访问哪个服务,通过与该服务关联的Endpoint对像查看pod IP,并将客户端的请求转发给其中一个pod
通过相同的Ingress暴露多个服务
Ingress的规范中rules和paths都是数组,因此他们可以包含多个条目。一个Ingress可以将多个主机和路径映射到多个服务
将不同的服务映射到相同主机的不同路径
- host: kubia.example.comhttp:paths:- path: /kubia #对kubia.example.com/kubia的请求将会转发至kubia服务backend:serviceName: kubiaservicePort: 80- path: /foo #对kubia.example.com/bar的请求将转发至bar服务backend:serviceName: barservicePort: 80
- http.paths[n].path:指定子路径。通过host/path可访问子路径下对应服务
将不同的服务映射到不同主机上
spec:rules:- host: foo.example.com #对foo.example.com的请求将会转发至foo服务http:paths:- path: /backend:serviceName: fooservicePort: 80- host: bar.example.com #对bar.example.com的请求将转发至bar服务http:paths:- path: /backend:serviceName: barservicePort: 80
- 根据请求中的Host头,控制器收到的请求将被转发到foo服务或bar服务。DNS需要将foo.example.com和bar.example.com域名都指向Ingress控制器的IP地址
配置Ingress处理TLS传输
为Ingress创建TLS认证
当客户端创建到Ingress控制器的TLS连接时,控制器将终止TLS连接,客户端和控制器之间的通信是加密的,控制器与后端pod之间的通信则不是,运行在pod上的应用程序不需要支持TLS。例如,如果pod运行web服务器,则它只能接收HTTP通信,并让Ingress控制器负责处理与TLS相关的所有内容,要使控制器能够这样做,需要将证书和私钥附加到Ingress,这两个必需资源存储在称为Secret的Kubernetes资源中,然后在Ingress manifest中引用它
首先需要创建私钥和证书
openssl genrsa -out tls.key 2048
openssl req -new -x509 -key tls.key -out tls.cert -days 360 -subj /CN=kubia.example.com
-
上述命令将产生tls.key文件以及基于tls.key产生的tls.cert文件(即CA证书)
-
tls.key存储的是私钥需要妥善保管
-
tls.cert即CA证书由CA机构颁发,包含服务站点名称、公钥,用于验证公钥,防止黑客恶意串改公钥
将敏感的私钥信息存储到secret
kubectl create secret tls tls-secret --cert=tls.cert --key=tls.key -n 名称空间
-
在指定命名空间下创建名为tls-secret的tls secret
-
通过如下命令可以在指定命名空间下查看创建的secret内容。data.tls.key为base64编码过后的tls.key文件;data.tls.crt为base64编码过后的tls.cert文件
kubectl get secret tls-secret -n 命名空间名称 -o yaml
修改之前编写的Ingress资源描述文件,使用secret中存储的tls密钥、证书提供HTTPS服务
apiVersion: extensions/v1beta1
kind: Ingress
metadata:name: kubia
spec:tls:- hosts:- kubia.example.comsecretName: tls-secretrules:- host: kubia.example.comhttp:paths:- path: /abackend:serviceName: kubiaservicePort: 33456- path: /bbackend:serviceName: kubiaservicePort: 33457
-
tls.hosts[n]:主机列表,必须是在CA证书中主机列表中
-
tls.secretName:指定使用的secret
使用kubectl apply命令更新上述资源描述文件到K8s集群中并生效。在浏览器中输入https://kubia.example.com/a即可访问资源。由于上述tls密码证书为自签名,因此浏览器会认为是不安全的证书,需要手动点击"继续访问"才能访问到资源。通过向CA认证机构申请tls证书,则是被浏览器认可的,具体申请认证过程可以自行搜索
就绪探针
当pod的标签与服务的pod选择器相匹配时,经由服务的请求就会转发到其管理的pod,但如果pod启动需要消耗较长时间才能启动完成处理请求,那就会导致某些路由到这个pod的请求无法得到响应,而让用户无法正常使用功能。因此需要在pod成功启动并可以接收请求时,才能让服务将用户请求转发过来,这也就是就绪探针的作用
就绪探针介绍
与存活探针类似,K8s也支持通过就绪探针探测容器是否准备就绪可以接收请求。就绪探针会定期执行,通常探测标准是检查容器中应用是否可以正常响应某个请求、或者特定的URL路径,这些请求执行的检查逻辑由应用开发人员提供,当检查确定应用已经完全启动可以对外提供服务时就可以返回成功,这时认为应用已经就绪,可以正常响应用户请求。当然对于简单的应用也可以检查端口是否可访问,例如Spring Cloud微服务应用可以通过探测其服务端口是否正常响应判断其是否启动成功,这种探测只能针对启动后就能立即响应服务的应用,对于哪些启动后还需要执行一些初始化操作的应用就不太适用了,还是需要开发人员提供接口检查是否就绪
就绪探针有三种类型:
-
Exec探针,执行进程的地方,容器的状态由进程的退出状态代码确定
-
HTTP GET探针,相容器发送HTTP GET请求,通过响应的HTTP状态码判断容器是否准备就绪
-
TCP socket探针,打开一个TCP连接到容器的指定端口,如果连接建立,则认为容器以准备就绪
容器启动时,可以配置一个初始等待时间,经过初始等待时间之后才开始执行第一次就绪探测,之后会周期性执行就绪探针。而不是容器启动就开始进行就绪探测,因为应用启动通常是需要时间的。如果检测到pod还未就绪,则会从服务中移除该pod,以免客户请求到不能提供服务的pod,当下次探测时pod准备就绪则会将pod加入到服务负载均衡转发范围,接收客户请求
就绪探针与存活探针看似相似,但二者有一个重大区别就是,存活探针探测失败会终止或重启pod,通过运行新的pod来保持正常工作。而就绪探针不会终止或重启pod,就绪探针确保只有准备就绪的pod能接收请求
一定要注意就绪探针是判断自己是否准备就绪,而不是判断依赖的pod是否准备就绪。例如一个应用需要等到数据库可访问才能正常提供服务,一种方式是应用提供一个接口用于检查是否可以访问数据库为客户端提供服务,这时就需要定义一个就绪探针取不断探针这个接口;另一种方式是通用initContainers指定容器启动需要依赖数据库,只有当数据库服务可访问时,才能启动应用,但这种方式只能定义依赖顺序
为pod添加就绪探针
如下rs资源描述文件指定了就绪探针,执行命令kubectl apply创建rs资源
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: kubia
spec:replicas: 3selector:matchLabels:app: kubiatemplate:metadata:labels:app: kubiaspec:containers:- name: kubiaimage: luksa/kubiaports:- containerPort: 8080readinessProbe:exec:command:- ls - /var/ready
-
通过在pod模板中指定容器的就绪探针,这里指定的是exec类型的就绪探针
-
spec.template.spec.containers[n].readinessProbe: 在容器readinessProbe属性下配置就绪探针
-
spec.template.spec.containers[n].readinessProbe.exec: 指定使用exec类型的就绪探针,该探针会执行command指定列表中的命令,0的退出状态被视为正常,非零状态为不正常
-
spec.template.spec.containers[n].readinessProbe.exec.command: 指定要执行的指令列表
-
这里的就绪探针比较奇怪,但正常情况下可以通过执行命令检查服务端口是否可访问判断是否就绪
如果是通过kubectl edit命令修改rs资源添加就绪探针,对于老的pod不会生效,需要手工删除老的pod,新产生的pod会添加上就绪探针
列出pod查看当前pod列表READY列是否就绪
kubectl get pods -n 命名空间

- 可以发现pod已就绪容器为0,总容器为1,也就是说pod并不能处理请求
在pod中执行创建/var/ready文件,让就绪探针成功
kubectl exec pod名称 -n 命名空间名称 -- touch /var/ready
再次执行命令检查pod列表可以发现添加/var/ready文件的pod已就绪容器已经变为1。如果还没没有发生变化,可能是就绪探针还没有执行,默认就绪探针会每隔10秒探测一次,这些就绪探针的配置都在readinessProbe下,可以翻阅官网或者对应资源的crd文件查看
如果将/var/ready文件删除,则pod就绪容器数会再次变为0
最佳实践:
-
因该始终定义一个就绪探针,即使仅仅检查服务端口是否可访问,也是必要的。如果没有就绪探针,pod启动后几乎会立即成为服务断点,接收到客户的请求,这时客户可能会收到"连接被拒绝"错误,这是不应该的
-
不需要将停止pod的逻辑放到就绪探针中,因为只要删除pod,k8s就会从服务中移除该pod
headless服务
通过服务可以提供稳定的IP,供客户端连接到支持服务的每个pod,pod的选择遵循负载均衡策略。但如果客户端想连接到所有pod时,通过上面所说的方式显然不能达到目的。一种方式是客户端集成K8s客户端直接通过与API服务通信获取所有pod及其IP并与之通信,但这种方式会导致客户端与K8s强关联,显然不是一种好的方式。还有另一种方式,客户端通过DNS查找发现pod的IP,但通常执行DNS查询服务,返回的是服务的集群IP,而不是服务关联的应用pod IP,但可以明确告诉K8s集群不要为服务分配集群IP,这样执行DNS查询服务时将返回所有关联服务的已就绪pod的 IP
创建headless服务
如下描述文件定义了一个headless服务
apiVersion: v1
kind: Service
metadata:name: kubia-headless
spec:clusterIP: Noneports:- port: 33456targetPort: 8080selector:app: kubia
-
与普通服务的不同之处在于,此服务通过指定spec.clusterIP为None,让K8s集群不为其分配集群IP,这样此服务就变成了headless服务
-
客户端可以通过DNS查找headless服务名,获取服务管理的所有已就绪pod的IP
通过命令根据以上描述文件创建headless服务,再通过kubectl get endpoints查询服务对应的endpoint资源,可以看到所有已就绪的pod的IP列表
通过DNS查找headless服务获取所有支持pod IP
执行如下命令创建一个包含DNS查找工具的pod
kubectl run dnsutils -n 命名空间 --image=tutum/dnsutils --generator=run-pod/v1 --command -- sleep infinity
在该pod中执行如下命令查找headless服务所支持pod的IP列表
kubectl exec dnsutils -n 命名空间 nslookup kubia-headless
查询支持headless服务的所有pod,包括未就绪pod
如果想要通过DNS查找支持headless服务的所有pod的IP地址,则需要明确告诉headless服务,通过设置publishNotReadyAddresses为true让查询服务是返回所有支持pod IP。当然早期版本可以通过注解service.alpha.kubernetes.io/tolerate-unready-endpoints: "true"设置
排查服务故障
当无法通过服务IP或FQDN连接服务,亦或通过域名host访问服务,可以通过如下列表去排查问题
-
确保从集群内部连接到服务的集群IP
-
不要通过ping服务IP来判断服务是否可访问,服务无法通过集群内部ip ping通
-
如果定义就绪探针,需要确保就绪探针探测成功,未就绪的pod是无法接收请求
-
要确定某个pod是否支持服务,可以通过kubectl get endpoints来查看端点资源确认
-
如果使用FQDN无法访问到服务,可以尝试查看是否可以使用其集群IP访问
-
检查是否连接到服务公开端口,而不是目标端口
-
尝试直接连接pod IP确保pod能正常接收正确端口上到请求
-
如果无法通过pod IP访问应用,请确保应用不是仅绑定到本地主机