protobuf
- 初始protobuf
- 简单上手
- 编写protobuf
- 编译 .proto 文件
- 编写测试文件 testPB.cc
初始protobuf
Protocol Buffers 是 Google 的一种语言无关、平台无关、可扩展的序列化结构数据的 方法,它可用于(数据) 通信协议、数据存储等。
Protocol Buffers 类比于 XML,是一种灵活,高效,自动化机制的结构数据序列化 方法,但是比 XML 更小、更快、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序
ProtoBuf(全称为 Protocol Buffer )是让结构数据序列化的方法,其具有以下 特点:
• 语言无关、平台无关:即 ProtoBuf支持Java、C++、Python多种语言,支持多个平台 。
• 高效:即比XML更小、更快、更为简单。
• 扩展性 、兼容性好:你可以更新数据结构,而不影响和破坏原有的旧程序
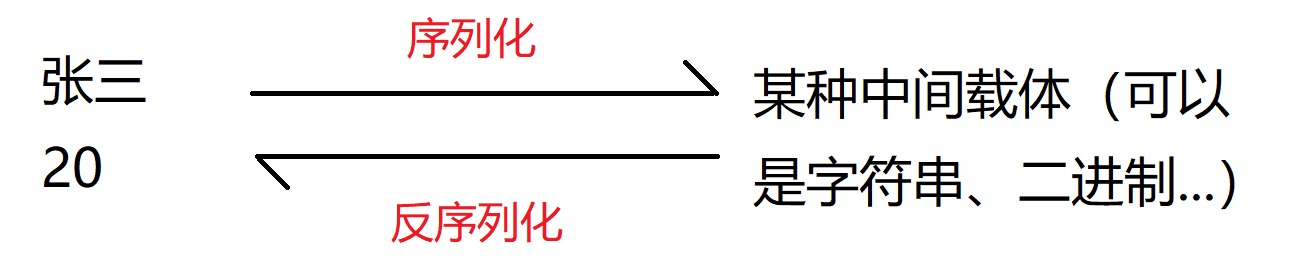
❓什么是序列化
简单上手
编写protobuf
- 编写.proto文件
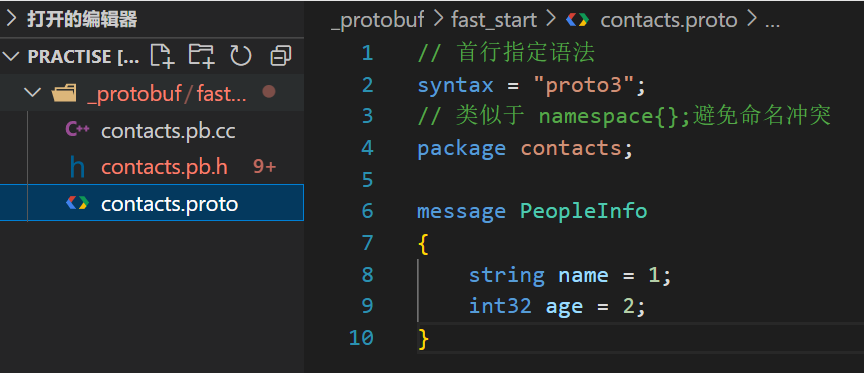
// 规定使用proto3语法标准,一定得在首行
syntax="proto3";
// 类似C++中的namespace,package是⼀个可选的声明符,能表示.proto⽂件的命名空间,在项⽬中要有唯⼀性。它的作⽤是为了避免我们定义的消息出现冲突
package=contacts;// 消息类型命名规范:使⽤驼峰命名法,首字母大写
// message 消息体名称{}
message PeopleInfo
{string name = 1;int32 age = 2;
}
在 message 中,我们可以定义其属性字段,字段定义格式为: 字段类型 字段名 = 字段唯⼀编号;
-
字段名称命名规范:全小写字母,多个字母之间用 _ 连接。
-
字段类型分为:标量数据类型和特殊类型(包括枚举、其他消息类型等)。
-
字段唯⼀编号:用来标识字段,一旦开始使用就不能够再改变。
字段唯⼀编号的范围
1 ~ 536,870,911(229-1),其中19000 ~ 19999不可用,做完保留字段
以下表格展示了标量数据类型,以及编译 .proto 文件之后自动生成的类中与之对应的字段类型。这里展示与C++语言对应的类型
| Type | Notes | C++ Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用变长编码[1]。负数的编码效率较低–若字段可能为负值,应使用 sint32 代替。 | int32 |
| int64 | 使用变长编码[1]。负数的编码效率较低–若字段可能为负值,应使用 sint64 代替。 | int64 |
| uint32 | 使用变长编码1。 | uint32 |
| uint64 | 使用变长编码1。 | uint64 |
| sint32 | 使用变长编码1。符号整型。负值的编码效率高于常规的 int32 类型。 | int32 |
| sint64 | 使用变长编码1。符号整型。负值的编码效率高于常规的 int64 类型。 | int64 |
| fixed32 | 定长 4 字节。若值常大于228则会比 uint32 更高效。 | uint32 |
| fixed64 | 定长 8 字节。若值常大于256 则会比 uint64 更高效。 | uint64 |
| sfixed32 | 定长 4 字节。 | int32 |
| sfixed64 | 定长 8 字节。 | int64 |
| bool | bool | |
| string | 包含 UTF-8 和 ASCII 编码的字符串,长度不能超过 232。 | string |
| bytes | 可包含任意的字节序列,长度不能超过 232。 | string |
编译 .proto 文件
在编写完 .proto 文件后,我们接着在终端对其进行编译
// 这里的.proto文件名称为 contacts
protoc --cpp_out=. contacts.proto
解释说明
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
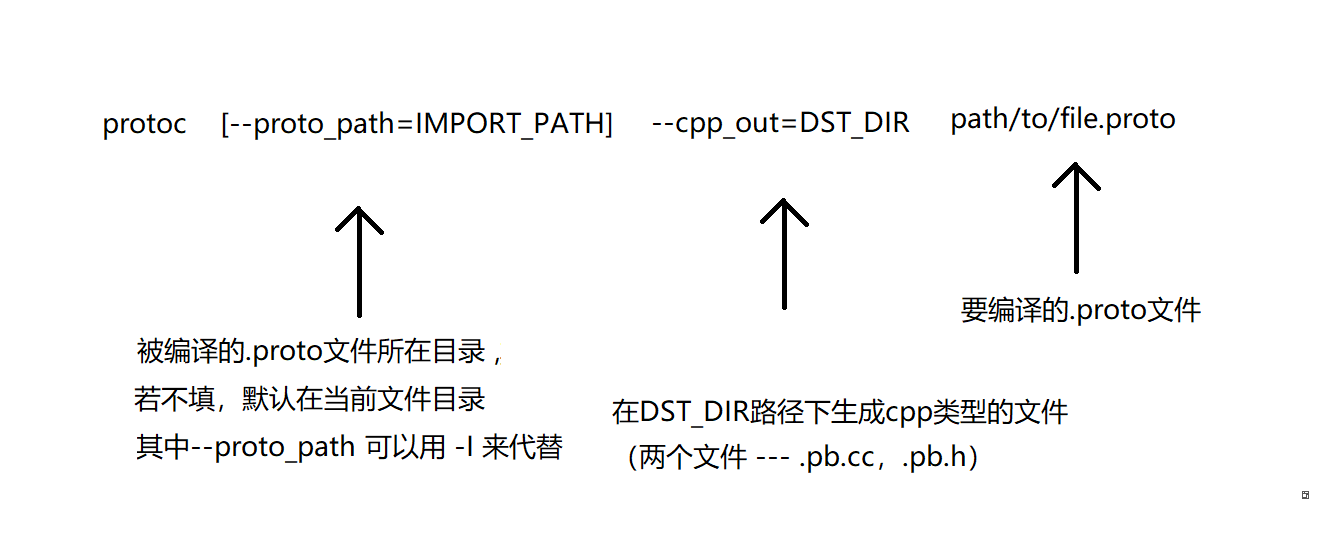
cpp_out用来生成 C++ 代码,java_out产生 Java 代码,python_out产生 python 代码,类似地还有csharp_out、objc_out、ruby_out、php_out等参数。

成功编译如下
编写测试文件 testPB.cc
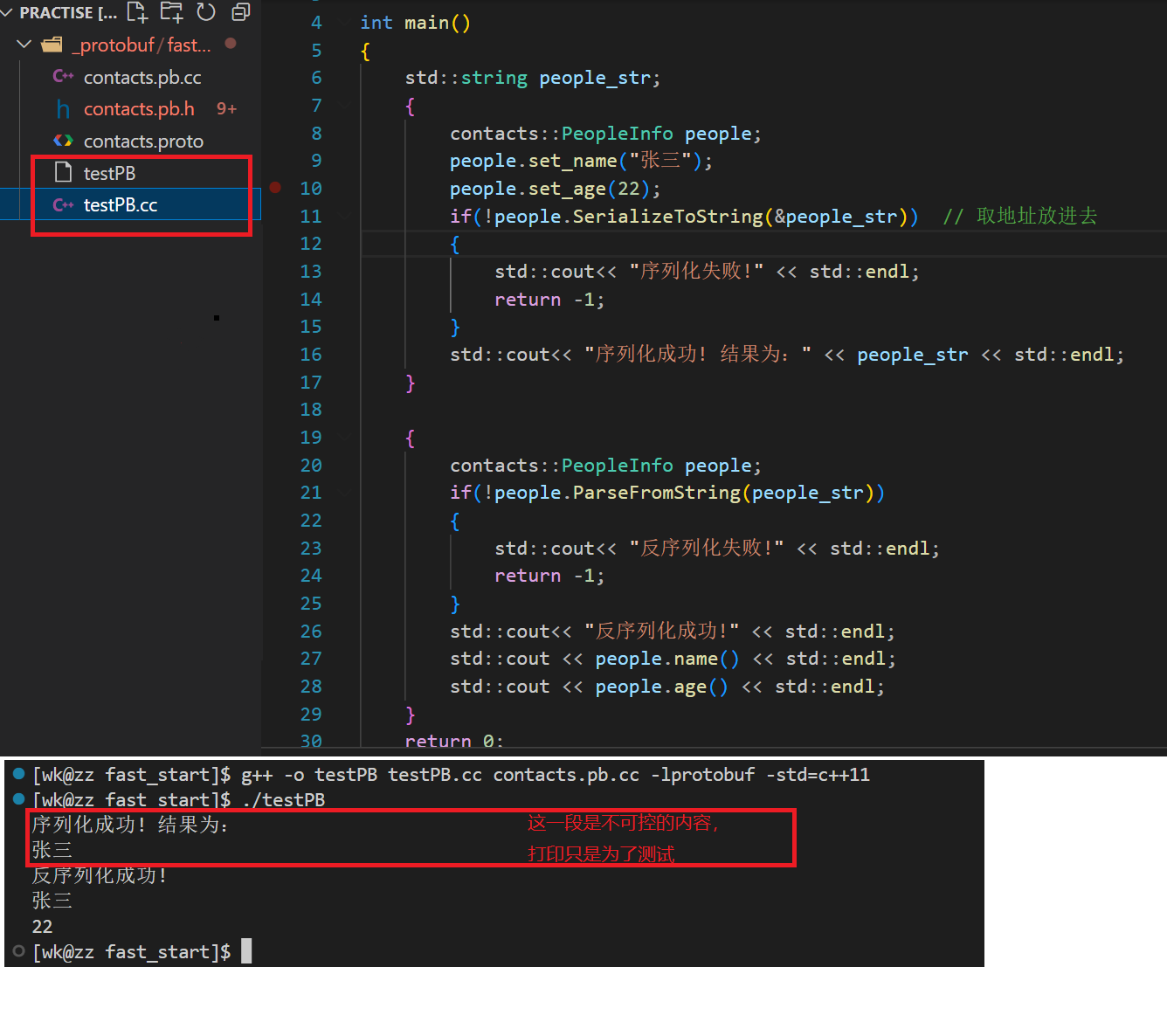
#include<iostream>
#include"contacts.pb.h"int main()
{std::string people_str;{contacts::PeopleInfo people;people.setname("张三");people.setage("22");// 序列化后的内容是二进制,people_str只是载体,用于后面反序列化if(!people.SerializeToString(&people_str)) {std::cout<< "序列化失败!" << std::endl;return -1;}std::cout<< "序列化成功! 结果为:" << people_str << std::endl;}{contacts::PeopleInfo people;// 将people_str内容反序列化成原来的内容if(!people.ParseFromString(people_str)){std::cout<< "反序列化失败!" << std::endl;return -1;}std::cout<< "反序列化成功!" << std::endl;std::cout << people.name() << std::endl;std::cout << people.age() << std::endl;}return 0;
}
- 编译,链接容易出现的坑
- 漏掉 -lprotobuf
- 漏掉 contacts.pb.cc
正确写法
g++ -o testPB testPB.cc contacts.pb.cc -lprotobuf -std=c++11
变长编码:经过protobuf 编码后,原本4字节或8字节的数可能会被变为其他字节数 ↩︎ ↩︎ ↩︎ ↩︎