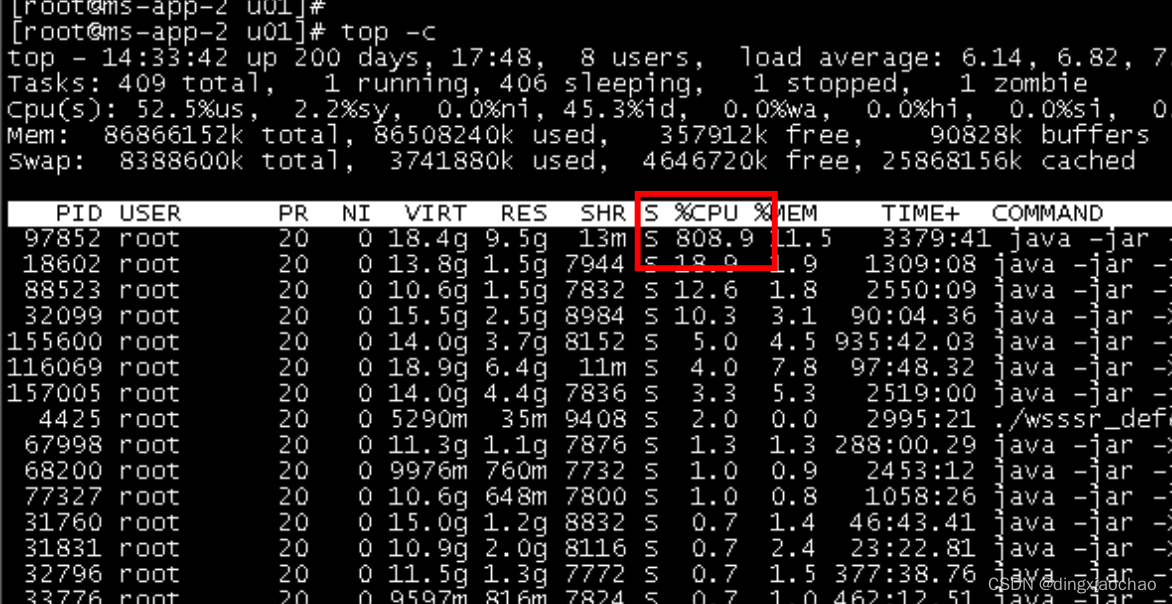
接现场运维报告某java服务CPU狂飙,服务处于卡死无响应状态
 询问现场运维什么场景造成的,答复是偶发现象,没有规律,和请求高峰期并没有关系。
询问现场运维什么场景造成的,答复是偶发现象,没有规律,和请求高峰期并没有关系。
因为服务是负载均衡的(A、B两台),临时处理让运维重启一个服务A下线服务B留作排查,因为是直接kill的,可能会出现数据丢失,需要谨慎操作。初步排查并不是内存泄露造成的(虽然内存占用很大),也使用jstack看了一下线程没有死锁情况,没招,用jmap看运行内容,由于正式环境无法直接连接调试,所以使用jmap生成hprof快照再拿到本地检查,jmap -dump:live,format=b,file=/u01/logs/dump.hprof 97852,文件的大小基本和服务运行内存保持一致,使用jprofile打开此快照
 打开后就长这个德行,基本数据类型占用都很大,直接看是看不出来什么玩意,可以使用最下面的类视图过滤器就进行过滤只关注业务代码(这里默认依赖都没有问题,也不大可能有问题,都是最简单的用法),可以使用业务包名进行过滤
打开后就长这个德行,基本数据类型占用都很大,直接看是看不出来什么玩意,可以使用最下面的类视图过滤器就进行过滤只关注业务代码(这里默认依赖都没有问题,也不大可能有问题,都是最简单的用法),可以使用业务包名进行过滤

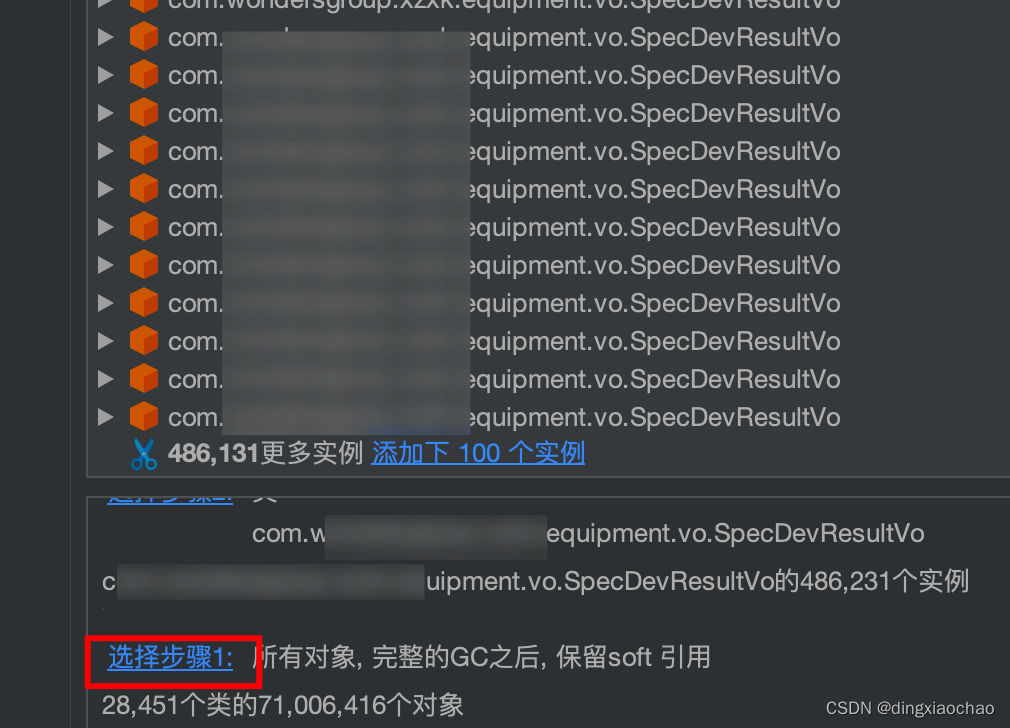
过滤后立马清晰明了,某几个bo、vo实例数巨多,我们选择当中某一个
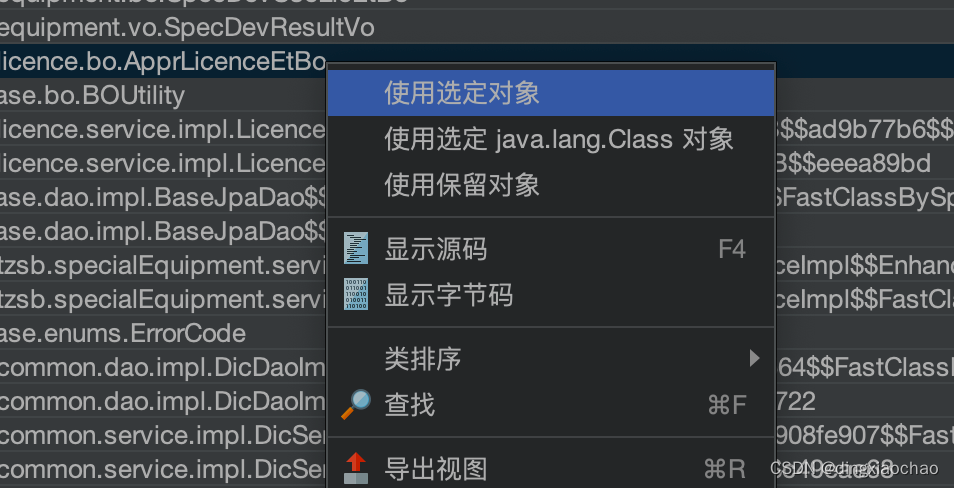
选择传入引用
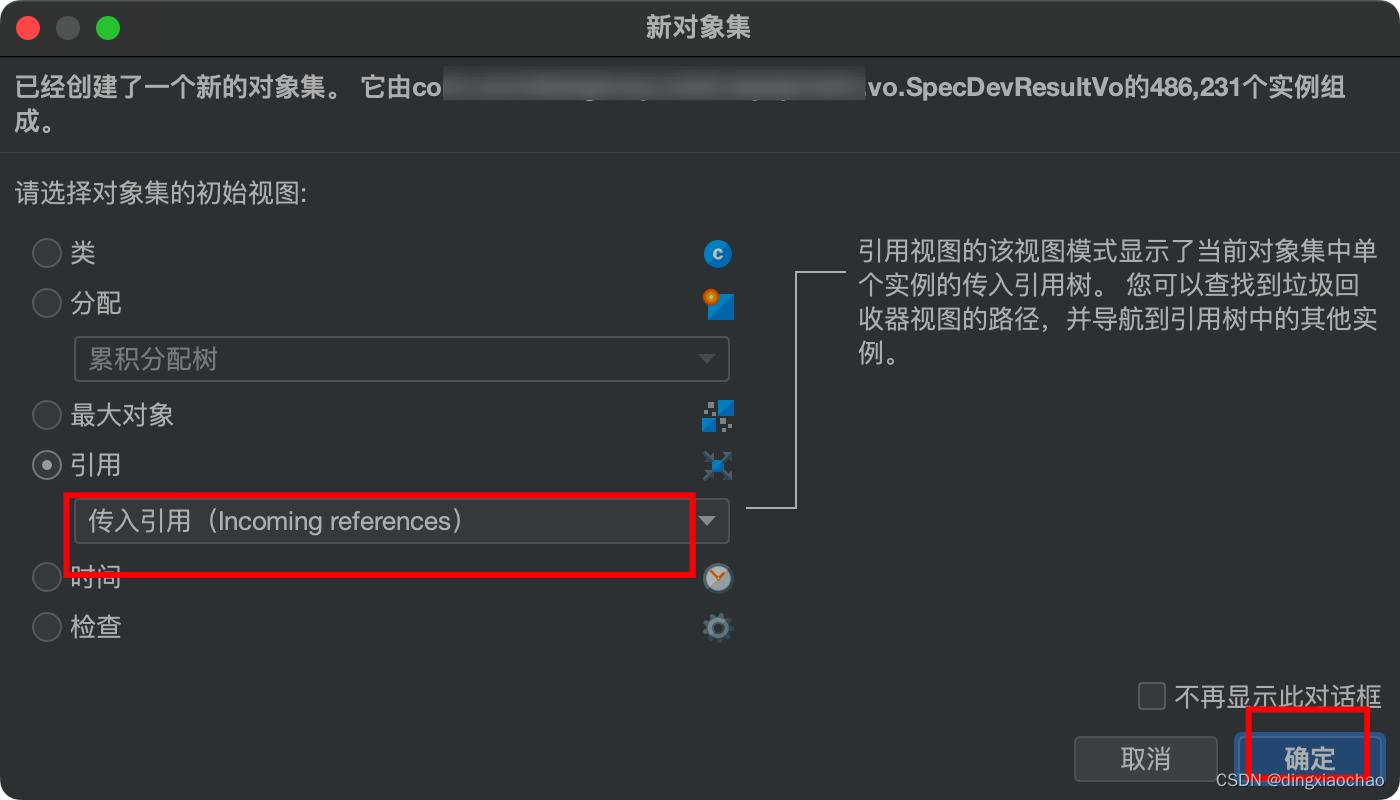
显示根路径
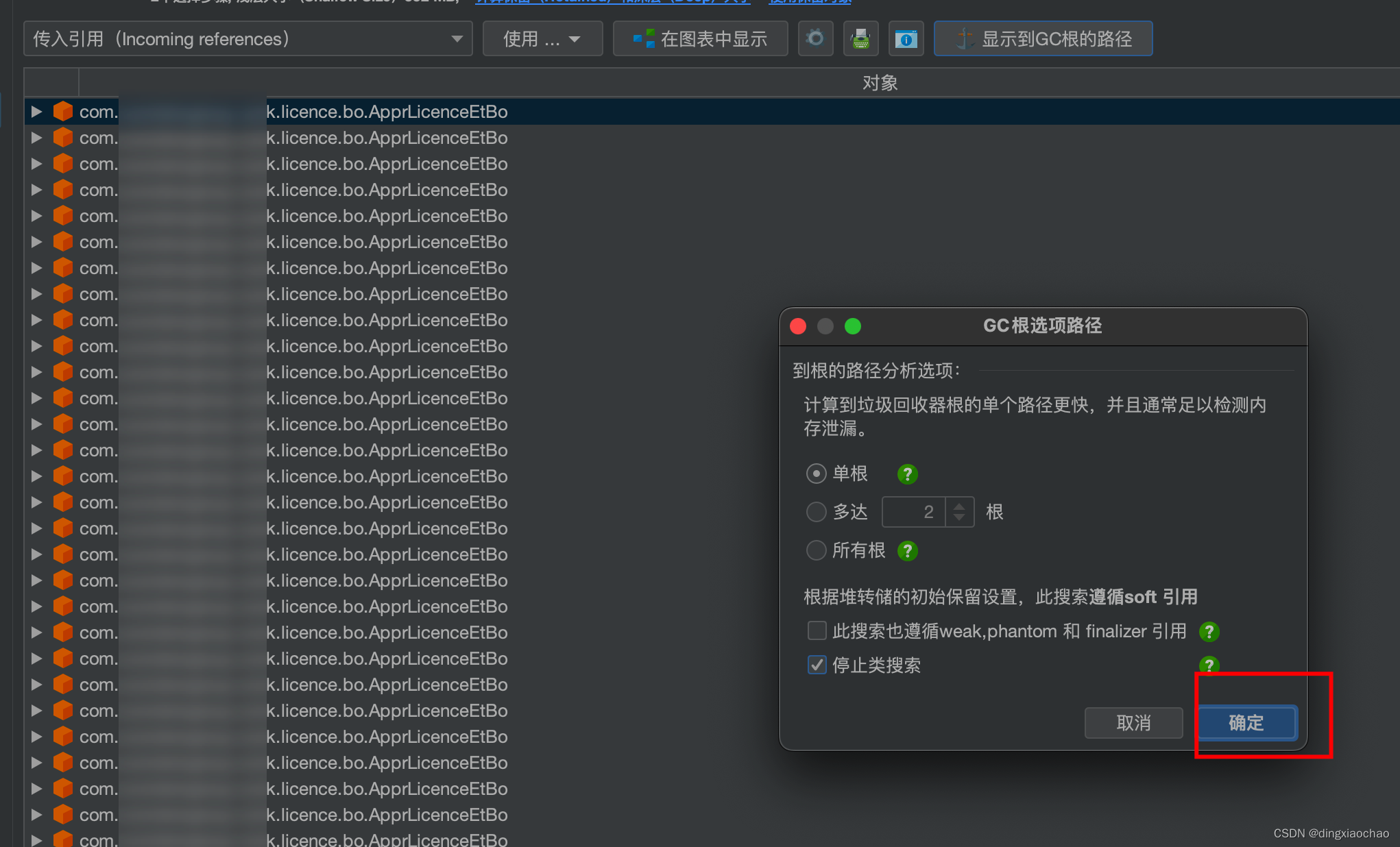
这个还不是很明显,换一个bo继续看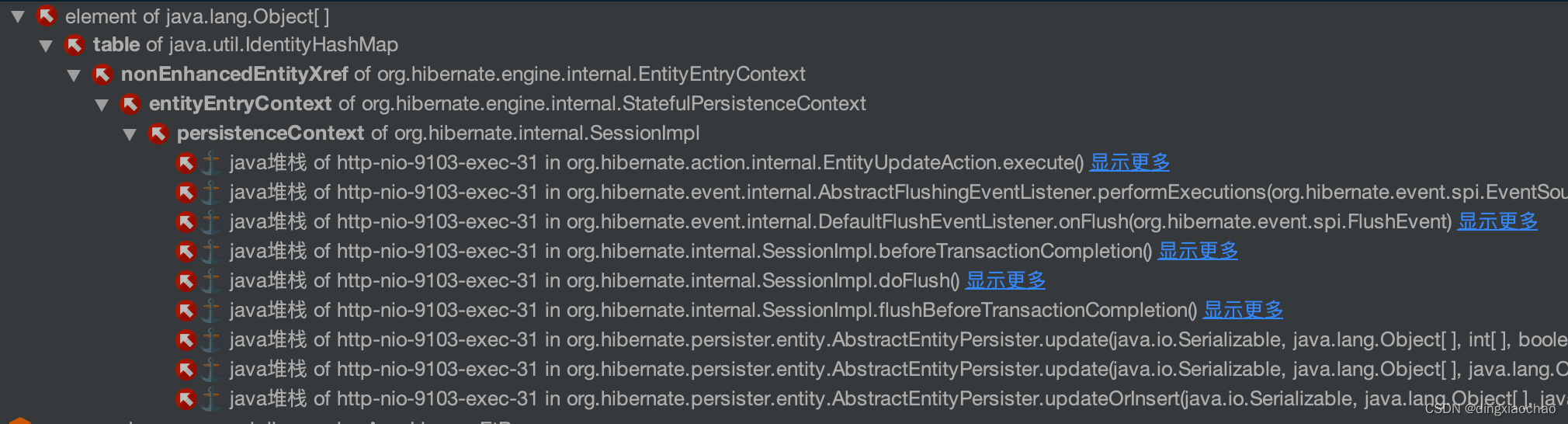
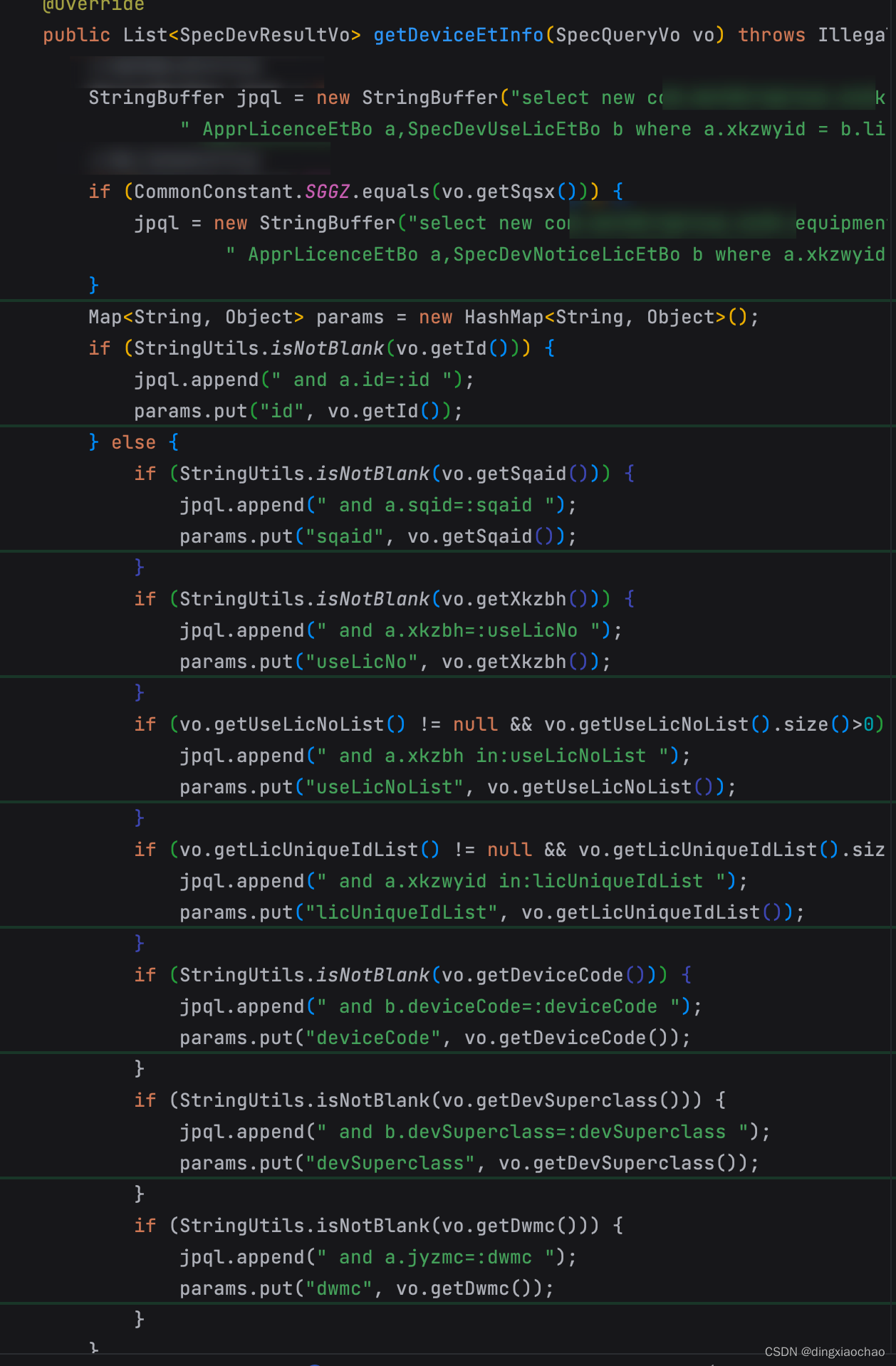
这个出现了业务代码相关的引用了,赶紧去翻代码

看了这个方法的引用,询问了一下相关开发分析了一下应该是前端调用的,大概就是根据查询条件返回list再for循环处理,这里有一个大问题,如果前端没有传查询条件,就会全表查询,让相应开发排查,前端部分查询条件是另一个对象里面的字段,可能为空,排查方式不表
这次问题不复杂,找对其实很快就能排查出来,强烈建议搞不清楚生产环境出错原因的直接拉快照或者连接生产环境排查