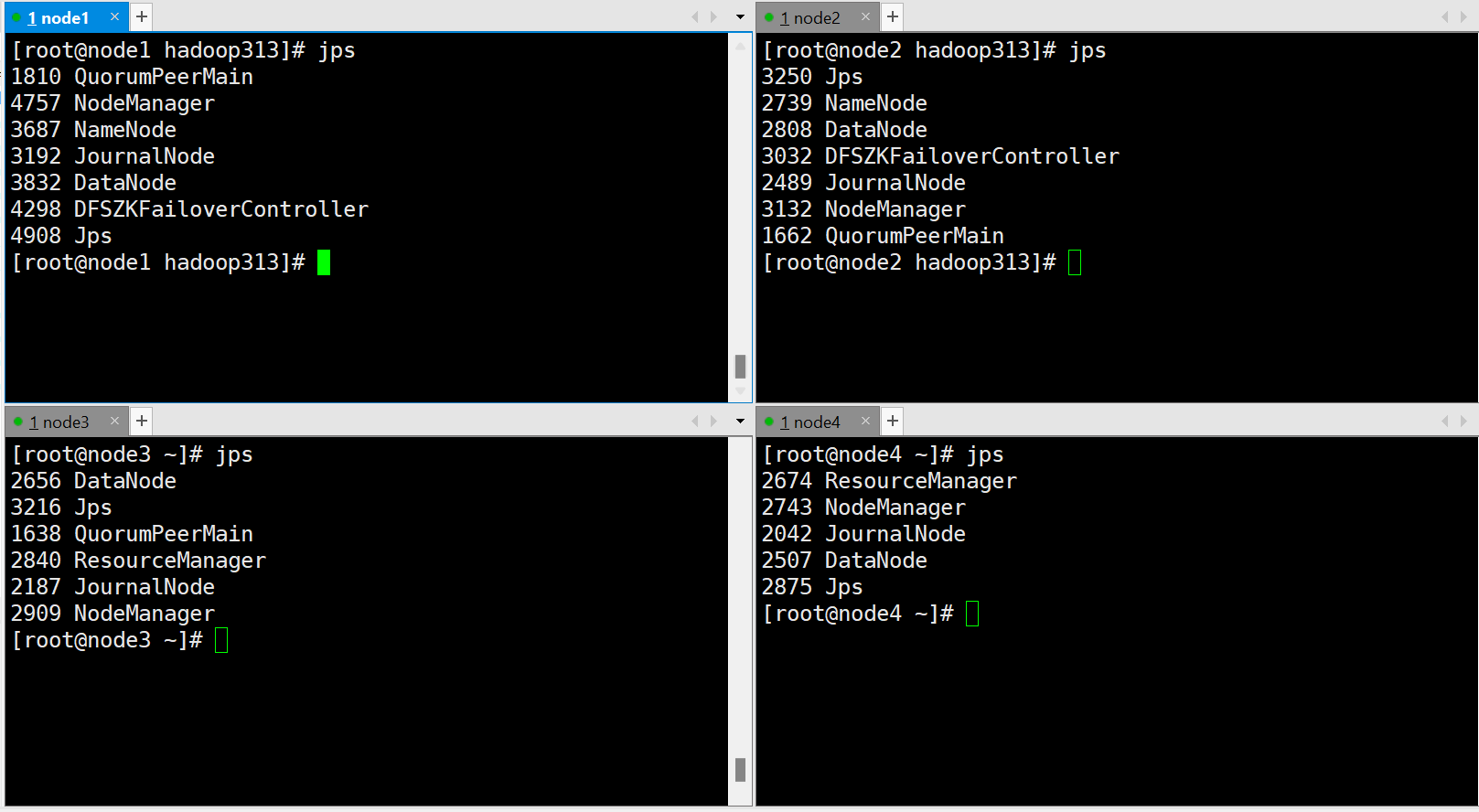
1.zookeep配置
| 1.1 安装4台虚拟机 (1)按照如下设置准备四台虚拟机,其中三台作为zookeeper,配置每台机器相应的IP,hostname,下载vim,ntpdate配置定时器定时更新时间,psmisc(psmisc用于管理系统上运行进程,包括ps、kill、fuser、pstree等命令它能够更方便地使用Linux操作系统) 192.168.142.136 node1 zookeeper 192.168.142.137 node2 zookeeper 192.168.142.138 node3 zookeeper 192.168.142.139 node4 (2)四台机器vim /etc/hosts追加4台主机IP和hostname (3)配置4台机器之间的免密通信:例如在node1上拷贝公钥至node2,node3,node4上 |
| 1.2 在四台机器上安装jdk并配置环境变量 环境变量文件可通过scp命令复制到其他三台机器 |
| 1.3 修改配置文件 (1)配置sysctl.conf文件:vim /etc/sysctl.conf文件末尾追加以下内容 vm.swappiness=0 vm.overcommit_memory=1 vm.overcommit_ratio=80
修改完成后,通过scp命令拷贝至其他3台机器 scp /etc/sysctl.conf root@node2:/etc/ scp /etc/sysctl.conf root@node3:/etc/ scp /etc/sysctl.conf root@node4:/etc/ (2)编辑文件:vim /etc/security/limits.conf 添加以下内容 hadoop soft nofile 16384 hadoop hard nofile 65536 hadoop soft nproc 16384 hadoop hard nproc 65536
修改完成后,通过scp命令拷贝至其他3台机器 |
| 1.4 安装zookeeper (1)解压至/opt/soft目录下,并改名为zk345
(2)cd /opt/soft/zk345/conf切换目录 1)拷贝目录下文件:cp zoo_sample.cfg zoo.cfg 2)编辑zoo.cfg文件:vim ./zoo.cfg dataDir=/opt/soft/zk345/tmp/zookeeper dataLogDir=/opt/soft/zk345/tmp/logs
server.0=192.168.142.136:2287:3387 server.1=192.168.142.137:2287:3387 server.2=192.168.142.138:2287:3387
server.A=B:C:D。 A是一个数字,表示这个是第几号服务器; B是这个服务器的IP地址; C是这个服务器与集群中的Leader服务器交换信息的端口; D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。 集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。 (3)创建目录:mkdir -p /opt/soft/zk345/tmp/zookeeper 在该目录下创建myid文件,文件内容为0 (4)配置环境变量:vim /etc/profile #zk export ZOOKEEPER_HOME=/opt/soft/zk345 export PATH=$PATH:$ZOOKEEPER_HOME/bin
配置完成后拷贝到其他三台机器上,并source更新 (5)配置完成后将zk345文件复制到node2和node3上 scp -r /opt/soft/zk345/ root@node2:/opt/soft/ scp -r /opt/soft/zk345/ root@node3:/opt/soft/ 复制完成后将node2和node3上的myid内容分别改为1和2 (6)配置完成后在node1,2,3上启动zkServer:zkServer.sh start 注:如果出现错误,在zk345目录下查看zookeeper.out文件内输出的错误信息,若发现不能自动创建logs文件夹,手动创建文件夹:mkdir -p /opt/soft/zk345/tmp/logs (7)完成启动zookeeper服务,并查看状态:zkServer.sh status
|







2.配置hadoop
| 安装hadoop,配置6个文件
|
| 确保三台zk集群正常启动 zkServer.sh start/stop/status |
| 启动journalnode 四台机器上执行:hdfs –daemon start journalnode |
| 初始化node1,node2 hadoop namenode -format会生成data目录 同步nn1和nn2拷贝data文件夹至node2机器:scp -r ./data/ root@node2:/opt/soft/hadoop313/ |
| node1初始化hdfs zkfc -formatZK |
| 启动hadoop
|