文章目录
- 1. 案例背景
- 2. 方案准备
- 2.1 HardFault(硬件错误异常)
- 2.2 UsageFault(用法错误异常)
- 2.3 BusFault(总线错误异常)
- 2.4 MemManage Fault(存储器管理错误异常)
- 3. 现场支持
- 3.1 现场环境
- 3.2 排查过程
- 4. 异常模拟
- 4.1 测试环境
- 4.2 测试过程
1. 案例背景
最近有个客户使用S32K146的产品在量产之后出现了三个售后件,ABBA测试之后的结果表明失效现象跟着S32K146走;同时客户反馈说试着将其中一个售后件重新烧录程序,S32K146又正常工作了。结合这两种情况,S32K146应该是没有损坏的,那就需要从软件程序方面排查了。
然后和客户的软件工程师交流了一下,使用Attaching to Running Target的方式发现程序卡死在HardFault。因为是量产产品出问题,客户强烈要求去现场处理问题,特地记录下这次处理S32K146的hard fault问题的过程,希望对读者有帮助。
2. 方案准备
在这之前,笔者还没有处理过S32K1系列发生HardFault的问题,所以需要先对S32K1系列发生HardFault的原因进行了解。推荐如下这篇文章,讲的非常细致。
- S32K1xx系列MCU的常见内核异常(Fault Exception)及处理详解(以S32K144为例介绍)
结合上面这篇文章以及ARM官方的M4内核文档Cortex -M4 Devices Generic User Guide,笔者简要整理了下S32K1发生HardFault的可能原因以及排查方式,如下文所述。
2.1 HardFault(硬件错误异常)
- HardFault的可能原因
- 停止调试关闭时发生了调试事件;
- UsageFault、BusFault、MemManage Fault未使能(Coretex-M4F内核默认状态)时发生了相应的错误导致错误升级到HardFault;
- 异常处理过程中取内核中断向量表读操作错误。
- HardFault的原因排查
造成HardFault的原因,可通过SCB模块的硬件错误状态寄存器(HFSR)进行排查,如下所示:- 原因1引起的,DEBUGEVT bit置1;
- 原因2引起的,FORCED bit置1;
- 原因3引起的,VECTTBL bit置1。

2.2 UsageFault(用法错误异常)
- UsageFault的可能原因
- 执行未定义指令,即非法指令;
- 指令执行状态错误;
- 异常返回错误;
- 尝试访问关闭或者不可用的协处理器;
- 非对齐地址访问(需要先通过SCB模块的CCR寄存器进行使能);
- 除零操作(需要先通过SCB模块的CCR寄存器进行使能)。
- UsageFault的原因排查
造成UsageFault的原因,可通过SCB模块的用法错误状态寄存器(UFSR)进行排查,如下所示:- 原因1引起的,UNDEFINSTR bit置1;
- 原因2引起的,INVSTATE bit置1;
- 原因3引起的,INVPC bit置1;
- 原因4引起的,NOCP bit置1;
- 原因5引起的,UNALIGNED bit置1;
- 原因6引起的,DIVBYZERO bit置1。

2.3 BusFault(总线错误异常)
- BusFault的可能原因
- Crossbar总线矩阵slave端口返回错误响应,当:
- a. 异常/中断入口压栈;
- b. 异常/中断返回出栈;
- c. 预取指;
- d. FPU lazy state现场保护;
- 精确总线错误;
- 不精确总线错误。
- Crossbar总线矩阵slave端口返回错误响应,当:
- BusFault的原因排查
造成BusFault的原因,可通过SCB模块的总线错误状态寄存器(BFSR)进行排查,如下所示:- 原因1.a引起的,STKERR bit置1;
- 原因1.b引起的,UNSTKERR bit置1;
- 原因1.c引起的,IBUSERR bit置1;
- 原因1.d引起的,LSPERR bit置1;
- 原因2引起的,PRECISERR bit置1;
- 原因3引起的,IMPRECISERR bit置1。

2.4 MemManage Fault(存储器管理错误异常)
- MemManage Fault的可能原因
- 尝试加载和储存内核MPU保护的地址;
- 从内核MPU保护的地址取指;
- 由MPU违规引起的压栈和出栈(函数调用或者中断/异常处理)错误;
- 硬件FPU lazy state保护触发的MPU存储器保护违规。
- MemManage Fault的原因排查
造成MemManage Fault的原因,可通过SCB模块的存储器管理错误状态寄存器(MMFSR)进行排查,如下所示:- 原因1引起的,DACCVIOL bit置1;
- 原因2引起的,IACCVIOL bit置1;
- 原因3引起的,MSTKERR或MUNSTKERR bit置1;
- 原因4引起的,MLSPERR bit置1;

UFSR、BFSR、MMFSR寄存器都是SCB模块中CFSR寄存器的子寄存器,包含关系如下,实际调试时查看CFSR寄存器即可。
如果要访问UFSR、BFSR、MMFSR这些子寄存器,可以按照如下的地址进行访问:


3. 现场支持
了解了引起HardFault的可能原因以及排查方式之后,就是按照该方法协助客户进行原因排查。
3.1 现场环境
客户的现场环境如下:
- 开发环境:IAR 8.30.1
- 调试器:Jlink V9
- MCU:S32K146
- SDK:EAR0.8.6
3.2 排查过程
- 打开和异常件对应的软件工程,使用Attach方式连接上第一个异常件的主控S32K146,如下图所示:

- 进入仿真界面后,暂停之后发现程序卡死在hard fault。
- 查看S32的SCB模块,HFSR寄存器的FORCED bit置1,说明是其它错误上升到hard fault,需要查看CFSR寄存器了解更多信息。

- CFSR寄存器的BFARVALID bit 和PRECISERR bit都置1,说明是精确总线错误造成bus fault并且捕捉保存了精确总线错误发生时的数据访问地址;再去查看BFAR寄存器,发生错误时数据访问的地址是0x100010E8。

- 使用同样的方法排查第二个异常件的主控MCU,也是精确总线错误造成的bus fault,发生错误时数据访问的地址是0x10001128。

- 接着通过IAR查看下S32K146的memory,从地址0x10001128起始的8个字节长度的flash区域数据无法查看。

- 翻阅S32K1的memory相关的应用笔记AN11983: Using the S32K1xx EEPROM Functionality – Application Note,发生错误的地址属于D-Flash,如下图所示:
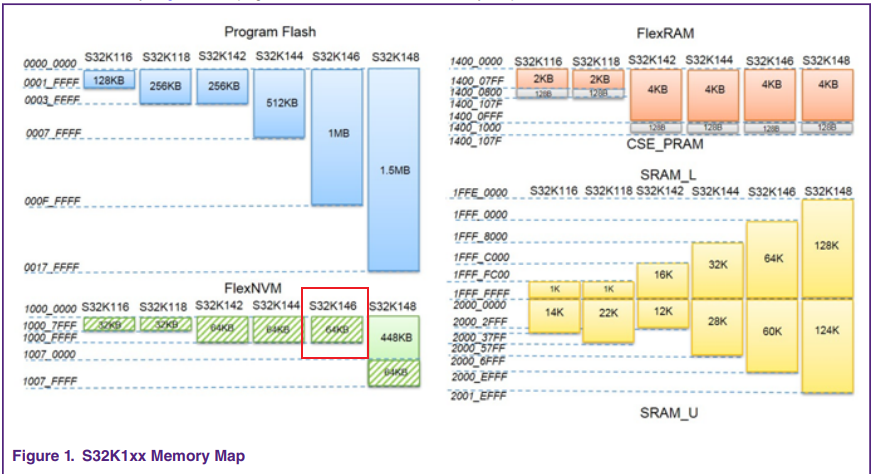
- 查阅软件代码中读写DFlash中这块地址的函数,发现在写DFLASH之前虽然进行了擦写操作,但是并没有设置擦写成功之后才能写DFlash的条件,有概率出现擦写不完全的情况下写D-Flash。同时,客户查看了其他组未出问题的产品的软件代码,在写D-Flash之前添加了比较多的条件判断,包含对擦写状态的判断。至此,该问题初步得到解决,剩下的就是优化代码并跟进后续产品的表现了。
4. 异常模拟
客户的问题虽然解决了,但是笔者还是不确定连续两次对同一块区域的Flash写不同的值,中间没有擦除动作,是否会让MCU卡在HardFault,所以使用手上的S32K144开发板进行了该情况的模拟。
4.1 测试环境
- 开发环境:S32 Design Studio for ARM 2.2
- SDK:RTM 3.0.0
- 开发板:S32K144EVB-Q100
4.2 测试过程
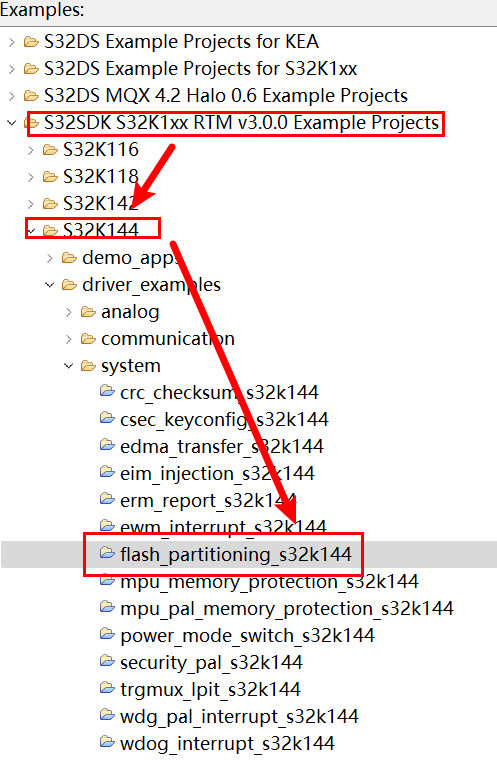
- 打开S32DS 2.2,选择自带的例程flash_partitioning_s32k144。
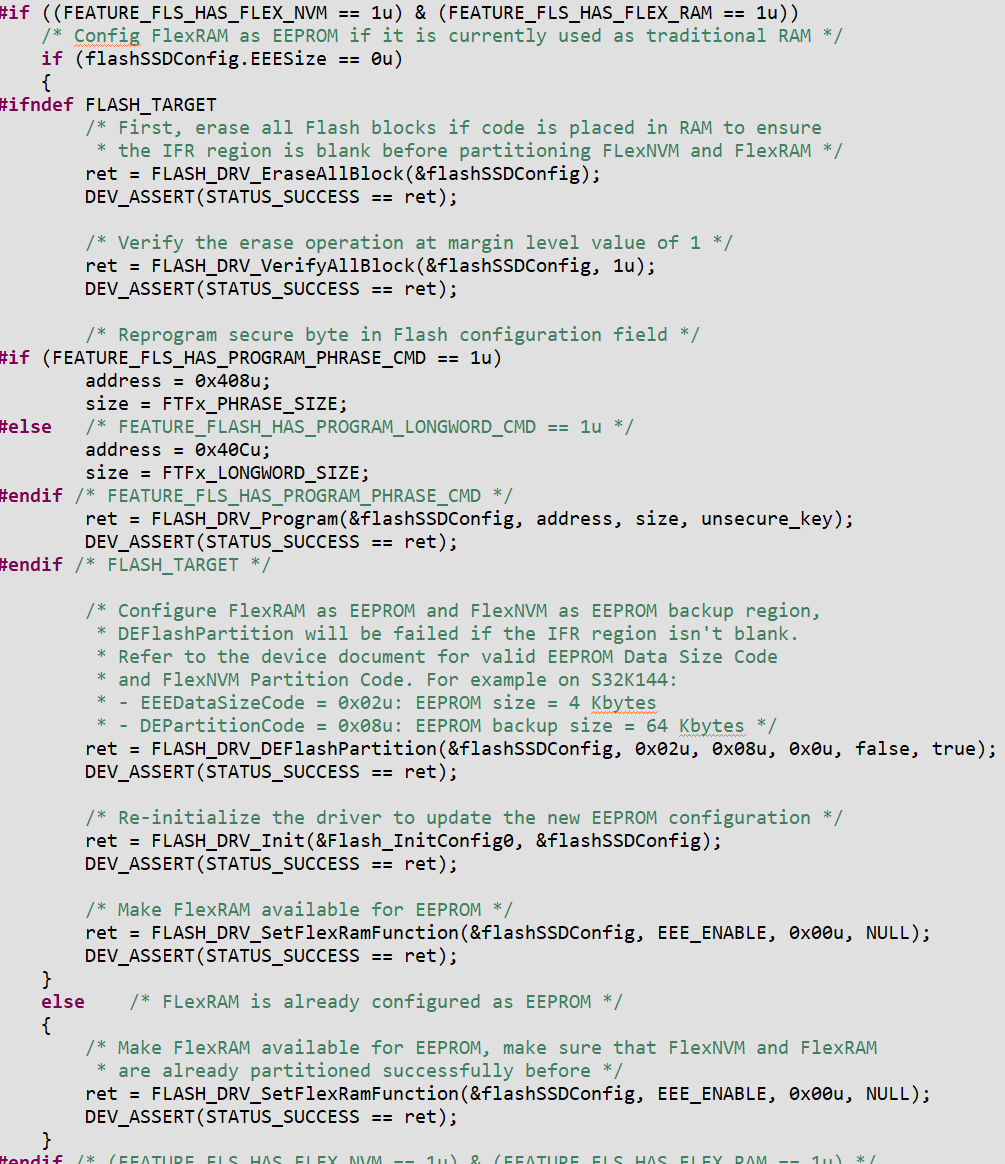
- 将初始化模拟EEPROM的部分注释掉,避免D-Flash被用作模拟EEPROM的备份区从而无法进行读写测试。
- 定义一套新数组并储存新的数据用于测试。

- 在正常的D-Flash写之后增加写入不同数据的操作。

- 编译之后进行debug,单步调试发现如果只进行写不同数据进入D-Flash,S32K144不会进入HardFault,需要再执行读D-Flash的操作,才会进入HardFault。

需要读取Flash地址的数据才会发生HardFault的原因,建议阅读下面这篇文章:
- S32K1xx系列MCU应用指南之存储器ECC功能使用详解(二)
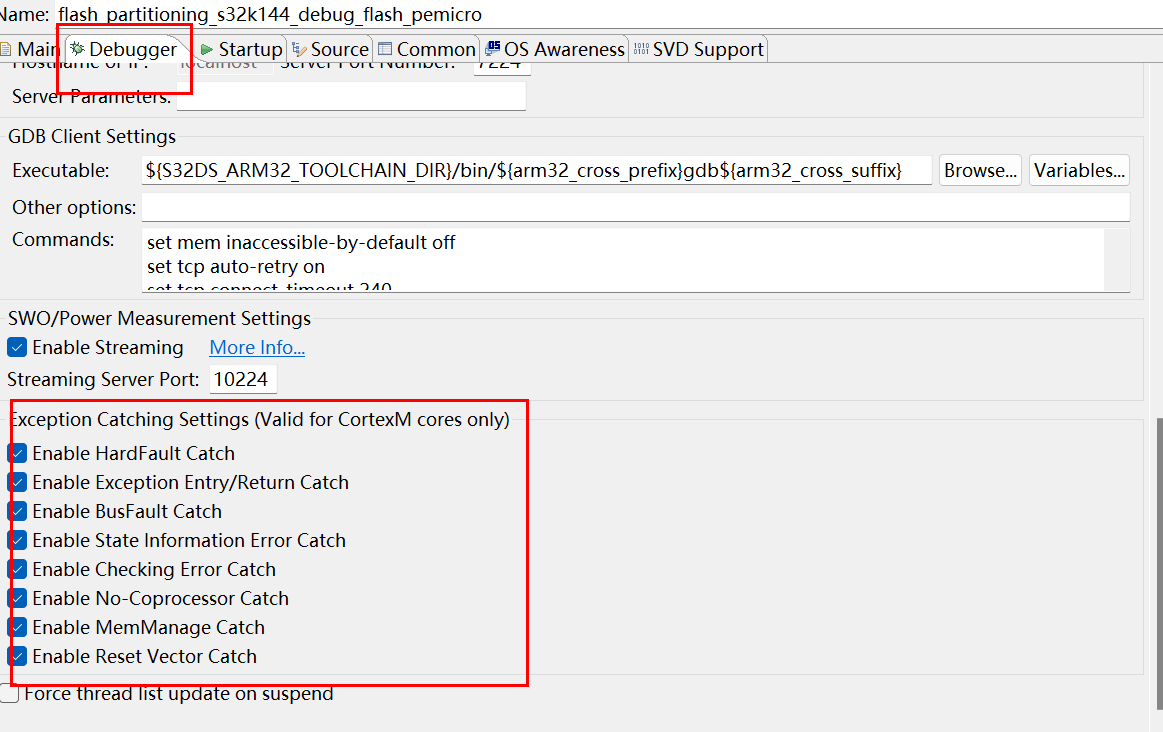
- S32DS之所以能在控制台显示比较多的MCU异常信息,是因为在调试器界面使能了异常捕捉功能,这部分功能依赖的是DEMCR寄存器,如下图所示。
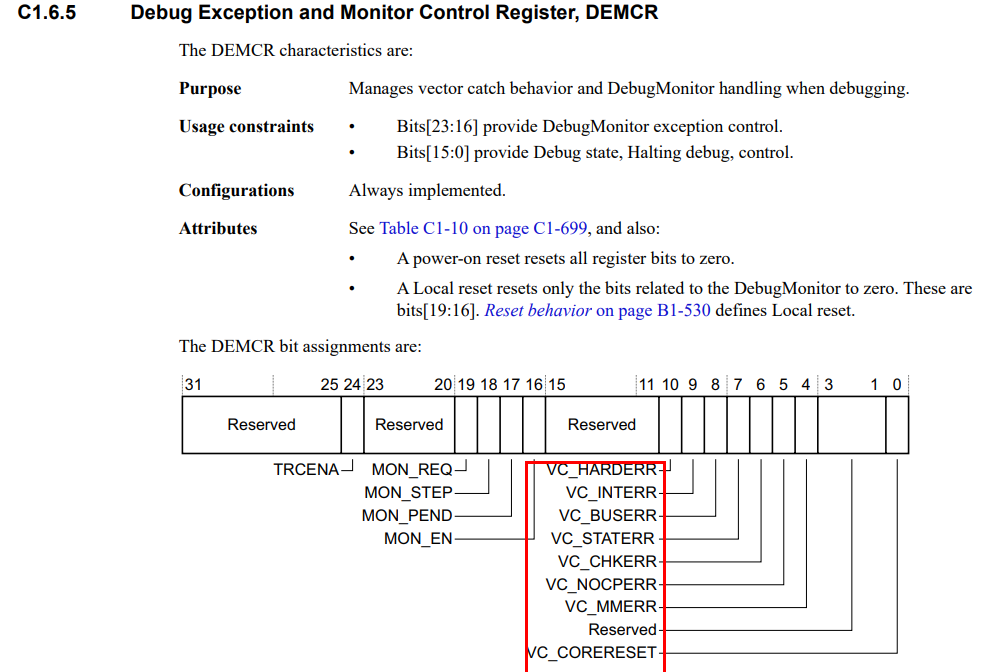
更多关于DEMCR寄存器的描述,可以查看如下这篇文档:
- Armv7-M Architecture Reference Manual
如果觉得这篇文章对你有用,不妨给个一键三连!!!