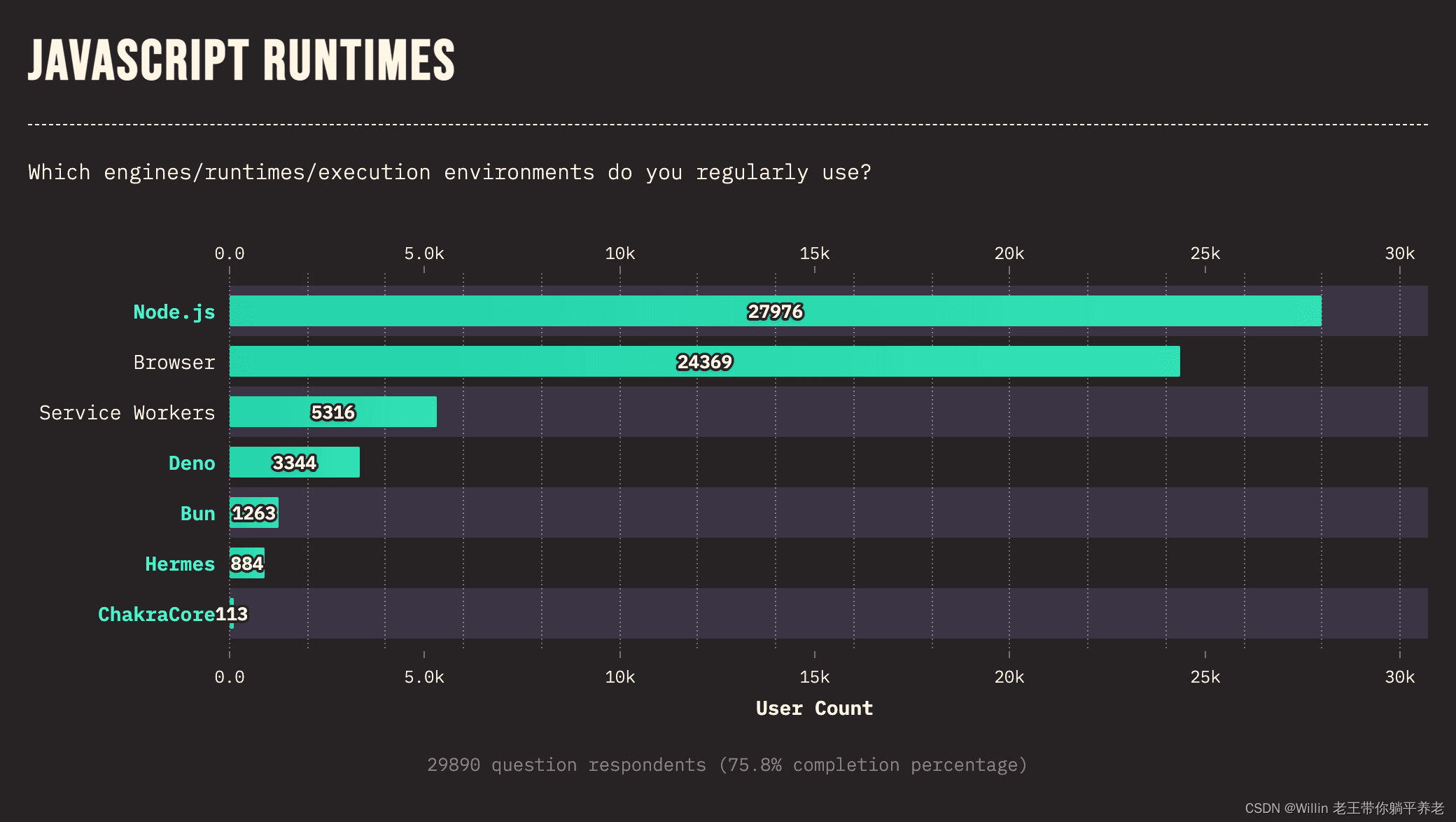
本文主要讲述了Yolov5如何训练自定义的数据集,以及使用GPU训练,涵盖报错解决,案例是检测图片中是否有救生圈。 最后的效果图大致如下:
| 效果图1 | 效果图2 |
|---|---|
|
|
|


前言
系列文章
1、详细讲述Yolov5从下载、配置及如何使用GPU运行
2、Labelimg标注自己的数据集,及如何划分训练集和验证集,应用于Yolov5
上一篇文章中,已经介绍了该如何标注自己的数据集,以及该如何给他们分类,接下来的话,就是根据我们已经标注好的数据集来进行训练啦。
将我们之前划分好的数据集放入项目中:

补充:通过文件夹将数据集复制放进去的,pycharm可以索引的更快,不然会卡很久。
一、修改配置文件
我们需要指定数据集的位置,首先就是要修改 coco128.yaml 配置文件
1.1、修改 coco128.yaml 配置文件
我们复制data 文件夹下 coco128.yaml 配置文件,并重命名为 blog_demo.yaml

1.2、修改 yolov5s.yaml 配置文件
我们复制 models 文件夹下 yolov5s.yaml 配置文件,并重命名为 yolov5s_blog.yaml

参数的细节可能需要各位朋友自己去了解啦,我这里只是将类别数目修改成和data/blog_demo.yaml文件对应。
二、了解 train.py 参数
此处暂时不做深究,我们当前的任务是跑通整个代码。
主要是了解截图里面部分参数,这主要是因为训练的时候,不同的机器硬件参数不同,能做的事情也不同,所以相应需要调整,尽可能的把性能发挥到极致。

weigths: 指的是训练好的网络模型,用来初始化网络权重cfg:为configuration的缩写,指的是网络结构,一般对应models文件夹下的xxx.yaml文件data:训练数据路径,一般为data文件夹下的xxx.yaml文件- hyp: 训练网络的一些超参数设置,(一般用不到)
epochs:设置训练的轮数(自己电脑上一般建议先小一点,测试一下,看跑一轮要多久)batch-size:每次输出给神经网络的图片数,(需要根据自己电脑性能进行调整)img-size:用于分别设置训练集和测试集的大小。两个数字前者为训练集大小,后者为测试集大小- rect: 是否采用矩形训练
resume: 指定之前训练的网络模型,并继续训练这个模型nosave: 只保留最后一次的网络模型notest:只在最后一次进行测试- noautoanchor:是否采用锚点
- evolve:是否寻找最优参数
- bucket:这个参数是 yolov5 作者将一些东西放在谷歌云盘,可以进行下载
- cache-images:是否对图片进行缓存,可以加快训练
- image-weights:测试过程中,图像的那些测试地方不太好,对这些不太好的地方加权重
device:训练网络的设备cpu还是gpu- multi-scale:训练过程中对图片进行尺度变换
- single-cls:训练数据集是单类别还是多类别
- adam:是否采用adam
- sync-bn:生效后进行多 GPU 进行分布式训练
- local_rank:DistributedDataParallel 单机多卡训练,一般不改动
workers: 多线程训练project:训练结果保存路径- name: 训练结果保存文件名
- exist-ok: 覆盖掉上一次的结果,不新建训练结果文件
- quad:在dataloader时采用什么样的方式读取我们的数据
- linear-lr:用于对学习速率进行调整,默认为 false,含义是通过余弦函数来降低学习率,生效后按照线性的方式去调整学习率
- save_period:用于记录训练日志信息,int 型,默认为 -1
- label-smoothing: 对标签进行平滑处理,防止过拟合
- freeze:冻结哪些层,不去更新训练这几层的参数
- save-period:训练多少次保存一次网络模型
注意:参数含default的为默认值,可以直接在文件进行修改,那么运行时直接python train.py也可;直接在命令行指定也可以。
含action的一般为'store_true',使用该参数则需要在命令行指定。
三、训练数据集
可以使用命令行,也可以修改train.py代码,我为了方便测试,就直接使用命令行啦
bash
复制代码
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s_blog.yaml --data data/blog_demo.yaml --epochs 100 --batch-size 16 --multi-scale --device 0
接下来就是我的报错踩坑过程啦。
3.1、报错1:AttributeError: module 'numpy' has no attribute 'int'.
错误如下图,这个很好解决,主要是由于 numpy 的版本引起的。我们换个版本即可。

yolo官方 requirements.txt 指定的 numpy 版本≥1.18.5,当你执行pip install -r requirements.txt命令时,他默认安装为1.24,但是再numpy版本更新时numpy.int在NumPy 1.20中已弃用,在NumPy 1.24中已删除。下面给2个解决方案:
1、重新安装numpy
pip uninstall numpy pip install numpy==1.22 -i <https://pypi.tuna.tsinghua.edu.cn/simple

2、修改当前项目模块中的 numpy 的源码
找到报错地方,将numpy.int更改为numpy.int_
我采取的方式是重新安装 numpy ,咋简单咋来。
接着重新尝试,还有坑….
3.2、报错2:OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "E:\environment\anaconda\envs\yolov5_6.1_demo_py3.8\lib\site-packages\torch\lib\nvfuser_codegen.dll" or one of its dependencies.

解决方案:
1、最简单的,关闭吃内存的软件,或者把pycharm重启试试看,不能行继续往下看。
2、调整虚拟内存啦。
打开系统高级设置


还有可能你调整了这个虚拟内存大小,仍然会报这个错误,那就接着看第三个解决方案。
3、在命令行中设置 -workers=0 ,这个是设置多线程的参数,在个人机器上,这个参数到底设置多少,一般和 --batch-size 8 相挂钩,如果batch-size设置的小,workers可以试着调大一点,2,4等等,一步一步的测试,一步一步的调整,看看有没有到训练瓶颈。也可以调大 batch-size 到16、32,当然具体的参数大小还是需要自己测试。
如果在命令行种设置 --workers=0 仍然运行失败,修改 [datasets.py](<http://datasets.py>) 文件的第119行,直接改成
num_workers=0,一般来说,改了这里,大概率是没问题啦。

再推荐一篇文章,pytorch中DataLoader的num_workers参数详解与设置大小建议
要是还不行的话,我的建议是直接 加钱,换电脑,哈哈哈哈
踩到这里,要是还有的话,建议评论一下,贴一下错误,复述一下步骤,我看看你还有踩到了啥。
因为版本的坑,自我感觉踩的挺深的,去掉版本问题,才只有两个报错信息。
bash
复制代码
### 3.3、raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids\_str)) from e raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str)) from e RuntimeError: DataLoader worker (pid(s) 64752) exited unexpectedly
这个也是我在我其中一个虚拟环境种爆出来的问题,我真的麻啦。
解决方法还是一样的,修改 datasets.py 的文件种的第119行,将num_workers直接设置为0。
3.4、开始使用自己的数据集训练
改完上面的错误,我们的训练终于开始啦。
bash
复制代码
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s_blog.yaml --data data/blog_demo.yaml --epochs 100 --batch-size 8 --multi-scale --device 0
后面的参数啥的,完全可以根据自己电脑的性能来进行设置,就比如这个--batch-size 8 ,你要是显存大,完全可以改成 16、32、64等等。

训练完成后,会出现run/train文件夹下出现一个expn的文件夹,看最新的那个就是最近一次训练的结果。

weights 文件夹下就是通过训练出来的权重文件,best.pt 是最好的,last.pt 是最后一次。
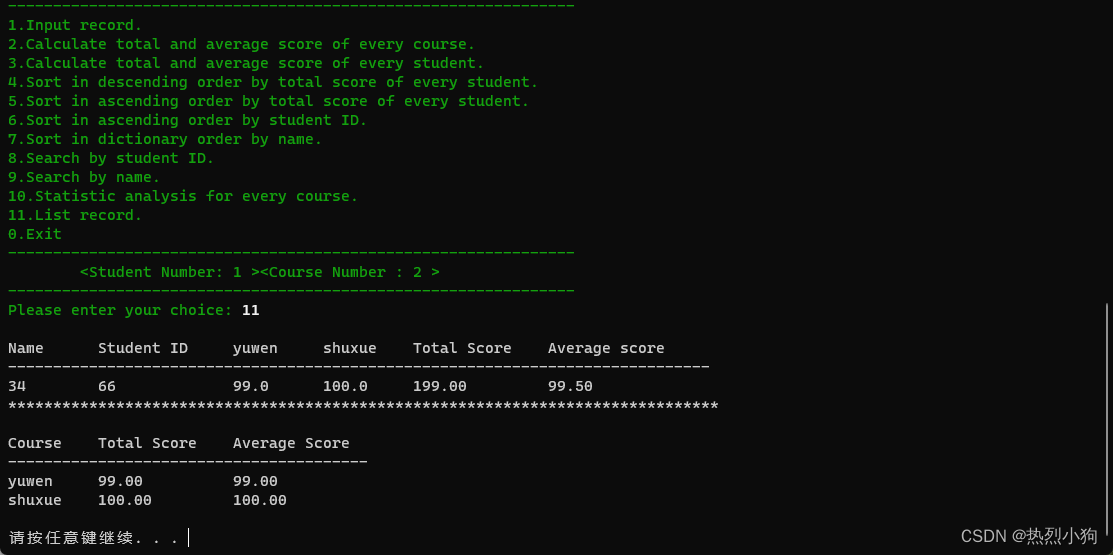
我们可以拿去测一下,看看效果(我这种十几张数据的,十轮训练,坦白说后面都不一定检测的出来)
3.5、测试训练出来的权重效果
将 best.pt 文件复制到weights 文件夹下,然后我在网上再随便找了一张不是我们数据集的救生圈图片放到了根目录下,执行下面命令进行测试
bash
复制代码
python detect.py --weights weights/best.pt --source life_buoy.jpg
写到这个地方的时候,有点糟糕,数据量太小,然后训练轮数,太少,导致这十轮训练出来的数据,直接就没效果,然后我重新了标注了100来张照片,重新训练了100轮,重新训练了一个 best.pt 文件。(没有数据量真没法玩,比较难受) 效果大致为以下这样:

后面的内容主要是补充了一下可能会遇到的错误,以及笔者个人的一些自言自语。
如果给了你帮助的话,记得给作者点个赞,评论一下,分享一下属于你的成功的喜悦,让写这篇文章的我,也与你一起快乐一下吧。
3.6、另外可能会遇到的报错
报错1:AttributeError: 'FreeTypeFont' object has no attribute 'getsize’
pip uninstall pillow
pip install Pillow==9.5 -i <https://pypi.tuna.tsinghua.edu.cn/simple>
pip show Pillow 查看依赖包版本
报错2:OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
我之前确实遇到了,后面专门写这个项目的时候,又没让我遇上了,应该还是版本问题,但是也先贴出来吧。

在pycharm里调试程序时可以直接通过在程序前添加这两个语句解决
bash
复制代码
import os os.environ['KMP_DUPLICATE_LIB_OK']='TRUE
四、补充:关于yolov5训练时参数workers和batch-size的理解
后面我自己在又一次训练时,又开始好奇 num_workers 和 batch-size 这两者的关系啦,细细的拜读了几位博主的博客,后在下面的这篇文章中找到了一些比较好的理解,大家可以阅读一下。
本小章节内容主要来自于: 关于yolov5训练时参数workers和batch-size的理理解 -作者:flamebox
如何让训练达到我们电脑的瓶颈,只能是一步一步的测试,然后去调整相关的参数。
最后
这个系列主要是想给自己一个记录,写在文档里也是写,发布博客也是写,前面几篇比较容易,后面会慢慢加深的。慢慢来吧。
越是容易写的文章,写起来越是麻烦。对版本问题真的很无赖,只能选择低版本的或者去踩坑。

![[VSCode] 替换掉/去掉空行](https://img-blog.csdnimg.cn/f7d004f2c4d74e63b2121af213b8230b.png)