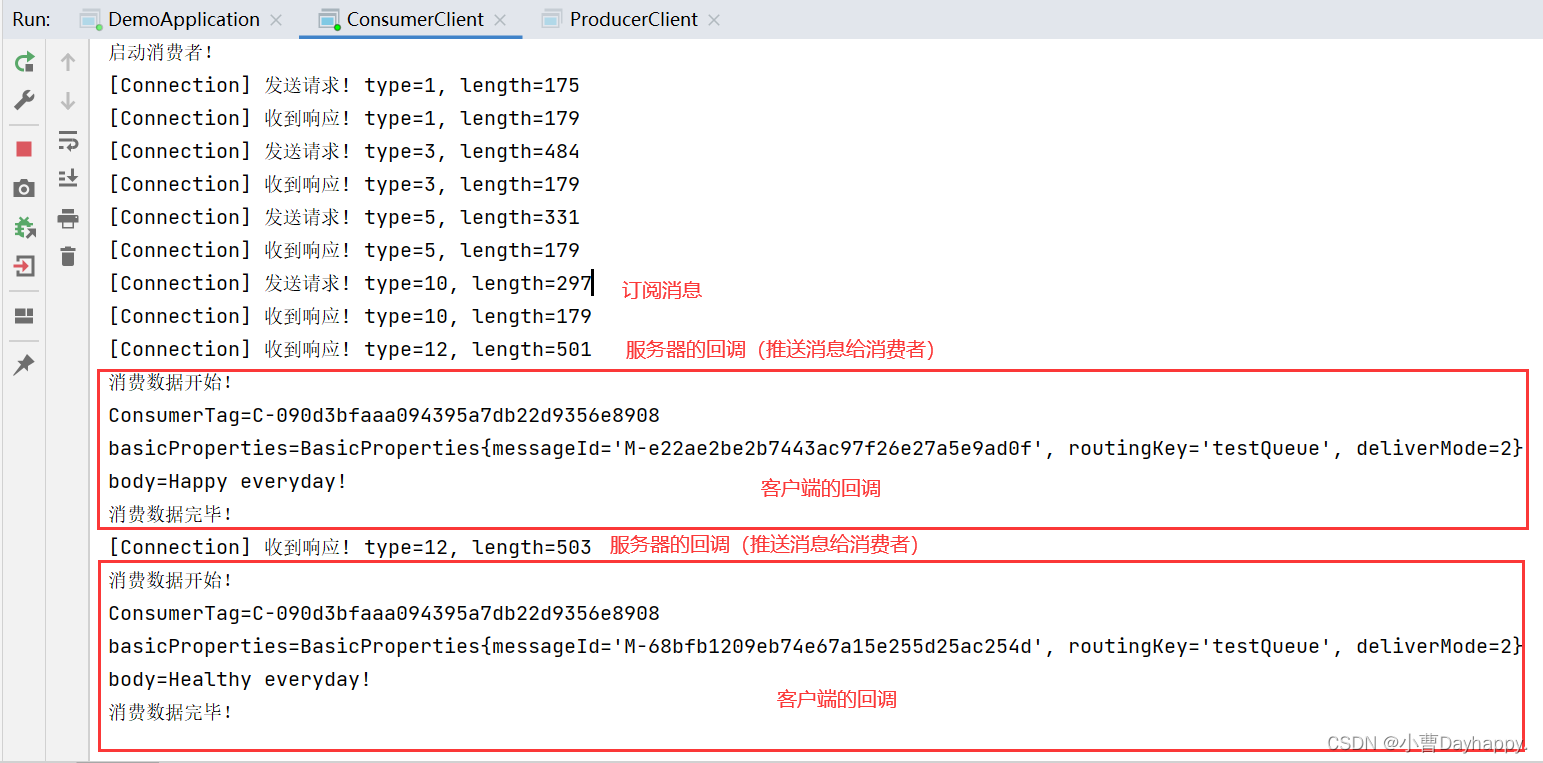
示例代码
import multiprocessingdef process_data(data):# 这里是处理单个数据的过程return data * 2# 待处理的数据
data = [1, 2, 3, 4, 5]def normal_func():# 普通处理方式result = []for obj in data:result.append(process_data(obj)return resultdef parallel_func():# 多进程处理方式pool = multiprocessing.Pool(multiprocessing.cpu_count())result = pool.map(process_data, data)pool.close()return resultif __name__ == '__main__':result = normal_func()result = parallel_func()multiprocessing.Pool 创建进程池, 传入的参数是要要使用的 CPU 内核数量, 直接用 cpu_count() 可以拿到当前硬件配置所有的 CPU 内核数.
pool.map 可以直接将处理后的结果拼接成一个 list 对象
应用在实际数据处理代码的效果对比:
- 普通处理方式, 用时 221 秒
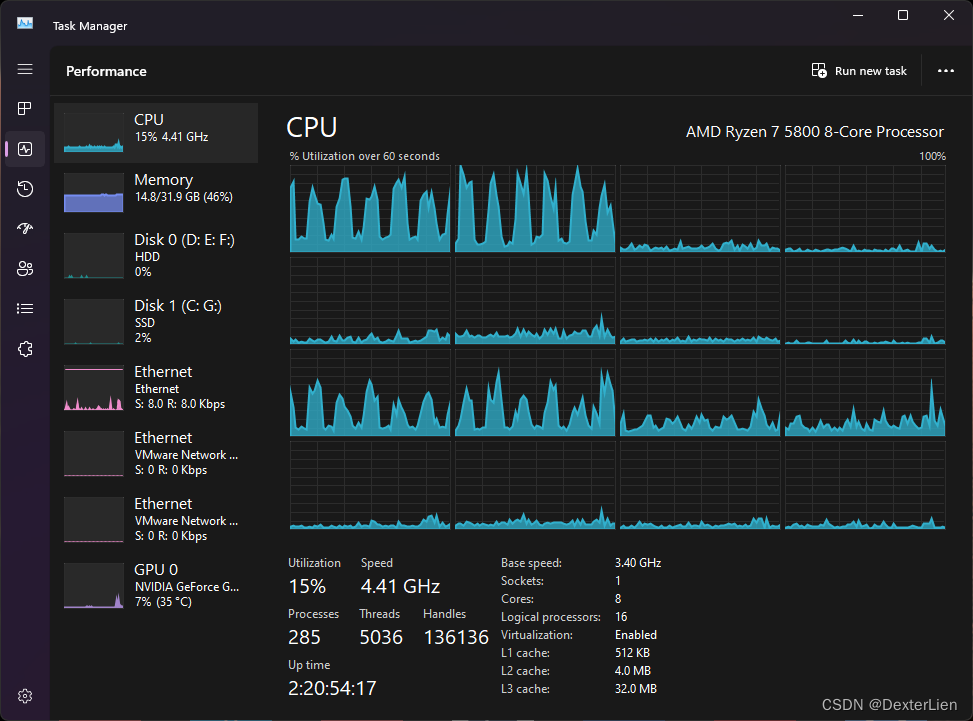
- 多进程处理方式, 用时 39 秒, 节省了 82% 的时间