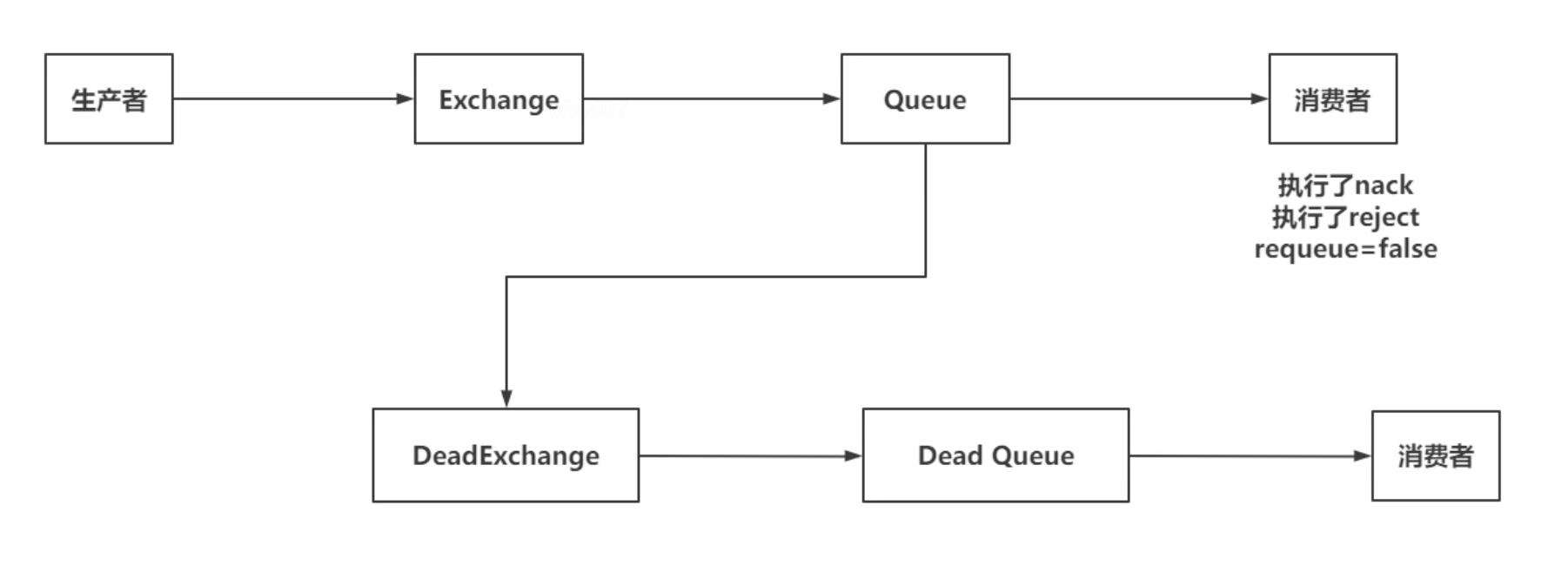
1. 计算数据集的香农熵
from numpy import *
import numpy as np
import pandas as pd
from math import log
import operator #计算数据集的香农熵
def calcShannonEnt(dataSet): numEntries=len(dataSet) labelCounts={} #给所有可能分类创建字典 for featVec in dataSet: currentLabel=featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel]=0 labelCounts[currentLabel]+=1 shannonEnt=0.0 #以2为底数计算香农熵 for key in labelCounts: prob = float(labelCounts[key])/numEntries shannonEnt-=prob*log(prob,2) return shannonEnt 香农熵公式:

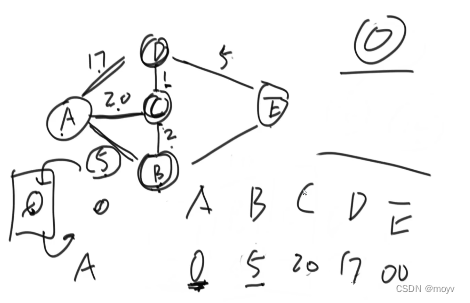
数据集:
 2. 对离散变量划分数据集
2. 对离散变量划分数据集
#对离散变量划分数据集,取出该特征取值为value的所有样本
def splitDataSet(dataSet,axis,value): retDataSet=[] for featVec in dataSet: if featVec[axis]==value: reducedFeatVec=featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet 这个函数用于划分数据集。它的作用是从给定的数据集中,根据指定的特征和取值,提取出符合条
件的样本集合。函数的输入参数包括数据集(dataSet)、特征的索引(axis)和特征取值
(value)。在函数内部,通过遍历数据集中的每个样本(featVec),判断该样本在指定特征上的
取值是否与给定的取值相等。如果相等,则将该样本添加到结果集合(retDataSet)中。为了将样
本添加到结果集合中,需要先创建一个新的样本(reducedFeatVec),它是将原样本中指定特征
的取值去除后的结果。具体做法是通过切片操作将特征索引之前和之后的部分合并起来,形成新的
样本。最后,将新样本添加到结果集合中。最后,函数返回结果集合(retDataSet),其中包含了
所有符合条件的样本。
3. 对连续变量划分数据集
#对连续变量划分数据集,direction规定划分的方向,
#决定是划分出小于value的数据样本还是大于value的数据样本集
def splitContinuousDataSet(dataSet,axis,value,direction): retDataSet=[] for featVec in dataSet: if direction==0: if featVec[axis]>value: reducedFeatVec=featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) else: if featVec[axis]<=value: reducedFeatVec=featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet 这是一个用于划分连续变量数据集的函数。它接受四个参数:dataSet(数据集),axis(要划分
的特征的索引),value(划分的阈值),direction(划分的方向)。函数的作用是根据给定的方
向和阈值,将数据集划分为两个子集。如果direction为0,则将大于阈值的样本划分到一个子集
中;如果direction不为0,则将小于等于阈值的样本划分到一个子集中。
在函数的实现中,通过遍历数据集中的每个样本,根据给定的方向和阈值进行划分。如果样本的特
征值大于阈值且方向为0,将该样本的特征值从划分特征的位置上移除,并将剩余的特征值组成一
个新的样本,添加到划分后的子集中。如果样本的特征值小于等于阈值且方向不为0,同样进行相
同的操作。最后,返回划分后的子集。
4. 选择划分方式
#选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet,labels): numFeatures=len(dataSet[0])-1 baseEntropy=calcShannonEnt(dataSet) bestInfoGain=0.0 bestFeature=-1 bestSplitDict={} for i in range(numFeatures): featList=[example[i] for example in dataSet] # print(featList)#对连续型特征进行处理 if type(featList[0]).__name__=='float' or type(featList[0]).__name__=='int': #产生n-1个候选划分点 sortfeatList=sorted(featList) splitList=[] for j in range(len(sortfeatList)-1): splitList.append((sortfeatList[j]+sortfeatList[j+1])/2.0) bestSplitEntropy=10000 slen=len(splitList) #求用第j个候选划分点划分时,得到的信息熵,并记录最佳划分点 for j in range(slen): value=splitList[j] newEntropy=0.0 subDataSet0=splitContinuousDataSet(dataSet,i,value,0) subDataSet1=splitContinuousDataSet(dataSet,i,value,1) prob0=len(subDataSet0)/float(len(dataSet)) newEntropy+=prob0*calcShannonEnt(subDataSet0) prob1=len(subDataSet1)/float(len(dataSet)) newEntropy+=prob1*calcShannonEnt(subDataSet1) if newEntropy<bestSplitEntropy: bestSplitEntropy=newEntropy bestSplit=j #用字典记录当前特征的最佳划分点 bestSplitDict[labels[i]]=splitList[bestSplit] infoGain=baseEntropy-bestSplitEntropy #对离散型特征进行处理 else: uniqueVals=set(featList) newEntropy=0.0 #计算该特征下每种划分的信息熵 for value in uniqueVals: subDataSet=splitDataSet(dataSet,i,value) prob=len(subDataSet)/float(len(dataSet)) print(prob)newEntropy+=prob*calcShannonEnt(subDataSet) infoGain=baseEntropy-newEntropy if infoGain>bestInfoGain: bestInfoGain=infoGain bestFeature=i #若当前节点的最佳划分特征为连续特征,则将其以之前记录的划分点为界进行二值化处理 #即是否小于等于bestSplitValue if type(dataSet[0][bestFeature]).__name__=='float' or type(dataSet[0][bestFeature]).__name__=='int': bestSplitValue=bestSplitDict[labels[bestFeature]] labels[bestFeature]=labels[bestFeature]+'<='+str(bestSplitValue) for i in range(shape(dataSet)[0]): if dataSet[i][bestFeature]<=bestSplitValue: dataSet[i][bestFeature]=1 else: dataSet[i][bestFeature]=0 return bestFeature numFeatures=len(dataSet[0])-1:计算数据集中特征数量,减去1是因为最后一列通常是标签列。
baseEntropy=calcShannonEnt(dataSet):计算整个数据集的基本熵。
bestInfoGain=0.0:初始化最佳信息增益为0。bestFeature=-1:初始化最佳划分特征的索引为-1。
bestSplitDict={}:创建一个空字典,用于记录连续特征的最佳划分点。
遍历每个特征,featList=[example[i] for example in dataSet]:获取数据集中第i个特征所有取值。
if type(featList[0]).__name__=='float' or ... :判断特征是否为连续型特征。
sortfeatList=sorted(featList):对连续型特征的取值进行排序。
splitList=[]:创建一个空列表,用于存储候选划分点。
for j in range(len(sortfeatList)-1):遍历排序后的特征取值列表,生成n-1个候选划分点。
splitList.append((sortfeatList[j]+sortfeatList[j+1])/2.0):将相邻特征值的平均值作为候选划分点。
bestSplitEntropy=10000:初始化最佳划分点的信息熵为一个较大的值。
slen=len(splitList):获取候选划分点的数量。for j in range(slen):遍历每个候选划分点。
value=splitList[j]:获取当前候选划分点的值。newEntropy=0.0:初始化划分后的信息熵为0。
subDataSet0=splitContinuousDataSet(dataSet,i,value,0):根据当前候选划分点将数据集划
分为小于等于该值的子集。subDataSet1=splitContinuousDataSet(dataSet,i,value,1):根据当前候
选划分点将数据集划分为大于该值的子集。
prob0=len(subDataSet0)/float(len(dataSet)):计算小于等于划分点的子集在整个数据集中的
概率。newEntropy+=prob0*calcShannonEnt(subDataSet0):计算小于等于划分点的子集的信息
熵,并加权求和。prob1=len(subDataSet1)/float(len(dataSet)):计算大于划分点的子集在整个数
据集中的概率。newEntropy+=prob1*calcShannonEnt(subDataSet1):计算大于划分点的子集的
信息熵,并加权求和。
if newEntropy<bestSplitEntropy:如果划分后的信息熵小于当前最佳划分点的信息熵。
bestSplitEntropy=newEntropy:更新最佳划分点的信息熵。
bestSplit=j:记录当前最佳划分点的索引。
bestSplitDict[labels[i]]=splitList[bestSplit]:用字典记录当前特征的最佳划分点。
infoGain=baseEntropy-bestSplitEntropy:计算当前特征的信息增益。
如果特征是离散型特征,uniqueVals=set(featList):获取特征的唯一取值。newEntropy=0.0:
初始化划分后的信息熵为0。遍历每个离散特征取值。subDataSet=splitDataSet(dataSet,i,value):
根据当前特征取值将数据集划分为子集。prob=len(subDataSet)/float(len(dataSet)):计算当前特征
取值的概率。newEntropy+=prob*calcShannonEnt(subDataSet):计算当前特征取值的信息熵,并
加权求和。infoGain=baseEntropy-newEntropy:计算当前特征的信息增益if infoGain >
bestInfoGain:如果当前特征的信息增益大于当前最佳信息增益。bestInfoGain=infoGain:更新最
佳信息增益。bestFeature=i:记录当前最佳划分特征的索引。
如果当前最佳划分特征是连续型特征。bestSplitValue=bestSplitDict[labels[bestFeature]]:获
取当前最佳划分特征的最佳划分点labels[bestFeature] = labels[bestFeature] + '<=' + str
(bestSplitValue):将当前最佳划分特征的标签更新为带有最佳划分点的条件。遍历数据集中的每个
样本。if dataSet[i][bestFeature]<=bestSplitValue:如果当前样本的最佳划分特征的取值小于等于
最佳划分点。dataSet[i][bestFeature]=1:将当前样本的最佳划分特征的取值设置为1。如果当前样
本的最佳划分特征的取值大于最佳划分点。dataSet[i][bestFeature]=0:将当前样本的最佳划分特
征的取值设置为0。返回最佳划分特征的索引。
5. 递归构造决策树
#特征若已经划分完,节点下的样本还没有统一取值,则需要进行投票
def majorityCnt(classList): classCount={} for vote in classList: if vote not in classCount.keys(): classCount[vote]=0 classCount[vote]+=1 return max(classCount) #主程序,递归产生决策树
def createTree(dataSet,labels,data_full,labels_full): classList=[example[-1] for example in dataSet] if classList.count(classList[0])==len(classList): return classList[0] if len(dataSet[0])==1: return majorityCnt(classList) bestFeat=chooseBestFeatureToSplit(dataSet,labels) bestFeatLabel=labels[bestFeat] myTree={bestFeatLabel:{}} featValues=[example[bestFeat] for example in dataSet] uniqueVals=set(featValues) if type(dataSet[0][bestFeat]).__name__=='str': currentlabel=labels_full.index(labels[bestFeat]) featValuesFull=[example[currentlabel] for example in data_full] uniqueValsFull=set(featValuesFull) del(labels[bestFeat]) #针对bestFeat的每个取值,划分出一个子树。 for value in uniqueVals: subLabels=labels[:] if type(dataSet[0][bestFeat]).__name__=='str': uniqueValsFull.remove(value) myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),subLabels,data_full,labels_full) if type(dataSet[0][bestFeat]).__name__=='str': for value in uniqueValsFull: myTree[bestFeatLabel][value]=majorityCnt(classList) return myTree classList=[example[-1] for example in dataSet]:创建一个列表classList,其中包含数据集dataSet
中每个样本的类别标签。
if classList.count(classList[0])==len(classList):检查classList中的类别标签是否都相同。如果是,
则返回该类别标签作为叶子节点的类别。
if len(dataSet[0])==1:检查数据集dataSet是否只剩下一个特征。如果是,则返回classList中出现
次数最多的类别标签作为叶子节点的类别。
bestFeat=chooseBestFeatureToSplit(dataSet,labels):调用函数chooseBestFeatureToSplit,选择
最佳的特征进行划分,并将其索引保存在bestFeat中。
bestFeatLabel=labels[bestFeat]:根据bestFeat的索引,获取特征标签labels中对应的特征名称。
myTree={bestFeatLabel:{}}:创建一个字典myTree,以bestFeatLabel作为键,空字典作为值。这
个字典将用于构建决策树。
featValues=[example[bestFeat] for example in dataSet]:创建一个列表featValues,其中包含数据
集dataSet中每个样本在bestFeat特征上的取值。
uniqueVals=set(featValues):将featValues转换为集合uniqueVals,以获取bestFeat特征的唯一取
值。
if type(dataSet[0][bestFeat]).__name__=='str':检查bestFeat特征的数据类型是否为字符串。
如果是,则执行以下操作:
currentlabel=labels_full.index(labels[bestFeat]):获取完整特征标签列表labels_full中labels
[bestFeat]的索引,并将其保存在currentlabel中;
featValuesFull=[example[currentlabel] for example in data_full]:创建一个列表
featValuesFull,其中包含完整数据集data_full中每个样本在currentlabel特征上的取值;
uniqueValsFull=set(featValuesFull):将featValuesFull转换为集合uniqueValsFull,以获取
currentlabel特征的唯一取值。
del(labels[bestFeat]):删除labels中索引为bestFeat的特征标签,因为该特征已经被用于划分。
for value in uniqueVals:对于uniqueVals中的每个取值,执行以下操作:
subLabels=labels[:]:创建一个新的特征标签列表subLabels,并将labels的值复制给它。
if type(dataSet[0][bestFeat]).__name__=='str':如果bestFeat特征的数据类型为字符串,执行
以下操作:uniqueValsFull.remove(value):从uniqueValsFull中移除当前取值value。
myTree[bestFeatLabel[value] =createTree(splitDataSet(dataSet,bestFeat,value),subLabels,
data_ full,labels_full):递归调用createTree函数,传入划分后的子数据集、子特征标签列表以及完
整数据集和特征标签列表,并将返回的子树存储在myTree中。
if type(dataSet[0][bestFeat]).__name__=='str':如果bestFeat特征的数据类型为字符串,执行
以下操作:for value in uniqueValsFull::对于uniqueValsFull中的每个取值,执行以下操作:
myTree[bestFeatLabel][value]=majorityCnt(classList):将叶子节点的类别标签设置为classList中
出现次数最多的类别标签。
最后,返回构建好的决策树。
df=pd.read_csv('watermelon_3a.csv')
data=df.values[:,1:].tolist()
data_full=data[:]
labels=df.columns.values[1:-1].tolist()
labels_full=labels[:]
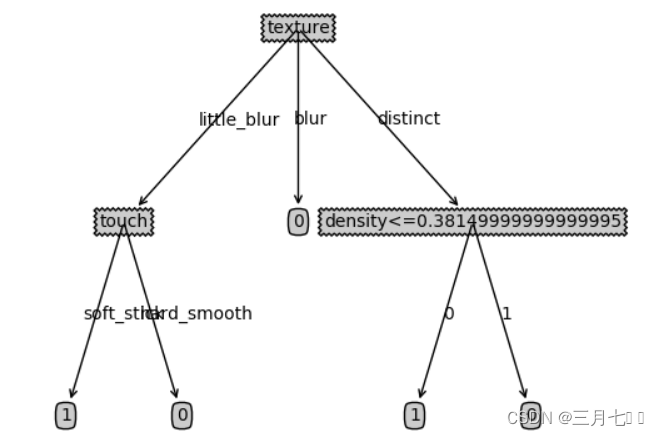
myTree=createTree(data,labels,data_full,labels_full) 6. 画树
import matplotlib.pyplot as plt
decisionNode=dict(boxstyle="sawtooth",fc="0.8")
leafNode=dict(boxstyle="round4",fc="0.8")
arrow_args=dict(arrowstyle="<-")#计算树的叶子节点数量
def getNumLeafs(myTree):numLeafs=0firstStr=list(myTree.keys())[0]secondDict=myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__=='dict':numLeafs+=getNumLeafs(secondDict[key])else: numLeafs+=1return numLeafs#计算树的最大深度
def getTreeDepth(myTree):maxDepth=0firstStr=list(myTree.keys())[0]secondDict=myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__=='dict':thisDepth=1+getTreeDepth(secondDict[key])else: thisDepth=1if thisDepth>maxDepth:maxDepth=thisDepthreturn maxDepth#画节点
def plotNode(nodeTxt,centerPt,parentPt,nodeType):createPlot.ax1.annotate(nodeTxt,xy=parentPt,xycoords='axes fraction',\xytext=centerPt,textcoords='axes fraction',va="center", ha="center",\bbox=nodeType,arrowprops=arrow_args)#画箭头上的文字
def plotMidText(cntrPt,parentPt,txtString):lens=len(txtString)xMid=(parentPt[0]+cntrPt[0])/2.0-lens*0.002yMid=(parentPt[1]+cntrPt[1])/2.0createPlot.ax1.text(xMid,yMid,txtString)def plotTree(myTree,parentPt,nodeTxt):numLeafs=getNumLeafs(myTree)depth=getTreeDepth(myTree)firstStr=list(myTree.keys())[0]cntrPt=(plotTree.x0ff+(1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.y0ff)plotMidText(cntrPt,parentPt,nodeTxt)plotNode(firstStr,cntrPt,parentPt,decisionNode)secondDict=myTree[firstStr]plotTree.y0ff=plotTree.y0ff-1.0/plotTree.totalDfor key in secondDict.keys():if type(secondDict[key]).__name__=='dict':plotTree(secondDict[key],cntrPt,str(key))else:plotTree.x0ff=plotTree.x0ff+1.0/plotTree.totalWplotNode(secondDict[key],(plotTree.x0ff,plotTree.y0ff),cntrPt,leafNode)plotMidText((plotTree.x0ff,plotTree.y0ff),cntrPt,str(key))plotTree.y0ff=plotTree.y0ff+1.0/plotTree.totalDdef createPlot(inTree):fig=plt.figure(1,facecolor='white')fig.clf()axprops=dict(xticks=[],yticks=[])createPlot.ax1=plt.subplot(111,frameon=False,**axprops)plotTree.totalW=float(getNumLeafs(inTree))plotTree.totalD=float(getTreeDepth(inTree))plotTree.x0ff=-0.5/plotTree.totalWplotTree.y0ff=1.0plotTree(inTree,(0.5,1.0),'')plt.show()plotNode函数用于绘制节点。它接受节点文本(nodeTxt)、中心点(centerPt)、父节点(parentPt)和节
点类型(nodeType)作为参数。在函数内部,它使用createPlot.ax1.annotate()函数来绘制节点文
本。
createPlot函数用于创建并显示一个图形。它接受一个树对象(inTree)作为参数。在函数内部,它创
建了一个图形对象(fig),清除了图形对象中的内容,然后创建了一个子图对象(createPlot.ax1)。接
下来,它调用了plotTree函数来绘制树的节点,并使用plt.show()显示图形。
plotMidText函数用于在箭头上绘制文字。它接受三个参数:cntrPt表示箭头的中心点坐标,
parentPt表示箭头的起始点坐标,txtString表示要绘制的文字。在函数内部,它计算了文字的位置
坐标,并使用createPlot.ax1.text()函数在图形上绘制文字。
plotTree函数用于绘制树的节点和箭头。它接受三个参数:myTree表示树的字典表示,parentPt表
示父节点的坐标,nodeTxt表示节点的文本。在函数内部,它首先获取树的叶子节点数和深度,然
后计算当前节点的位置坐标。接下来,它调用plotMidText函数在箭头上绘制文字,调用plotNode函
数绘制节点。然后,它遍历树的子节点,如果子节点是字典类型,则递归调用plotTree函数绘制子
树;如果子节点是叶子节点,则调用plotNode函数绘制叶子节点,并使用plotMidText函数在箭头上
绘制文字。最后,它更新plotTree.y0ff的值,以便绘制下一层的节点。
遇到的问题:createPlot.ax1 是什么意思?
在这句代码中,createPlot是函数类型(function),而createPlot.ax1是一个
matplotlib.axes._axes.Axes。createPlot.ax1是一个有效的变量名,而将其替换为
createPlot_ax1会导致报错。在代码中,createPlot.ax1是一个全局变量,用于引用子图对象。
功能有点类似于类的成员变量,为了共享createPlot.ax1。函数也是对象,给一个对象绑定一个属
性就是这样的:函数对象本身就有很多属性,__name__,__doc__等等。自己绑定的要有意义,没
意义的就不需要。
def f():passf.a = 1
print(f.a) # 1createPlot(myTree)