目录
1 多层索引(MultiIndex)
1.1 创建多层索引
1.1.1 从元组创建多层索引
1.1.2 使用 set_index() 方法创建多层索引
1.2 访问多层索引数据
1.3 多层索引的层次切片
1.4 多层索引的重塑
2 自定义函数和映射
2.1 使用 apply() 方法进行自定义函数操作
2.2 使用 map() 方法进行映射操作
2.3 使用 applymap() 进行元素级的自定义函数操作
3 Pandas性能优化常用技巧和操作
1 多层索引(MultiIndex)
Pandas 的多层索引(MultiIndex)允许你在一个DataFrame的行或列上拥有多个层次化的索引,这使得你能够处理更复杂的数据结构,例如多维时间序列数据或具有层次结构的数据。以下是多层索引的详细说明和示例:
1.1 创建多层索引
你可以使用多种方式来创建多层索引,包括从元组、列表或数组创建,或者通过设置 set_index() 方法。以下是一些示例:
1.1.1 从元组创建多层索引
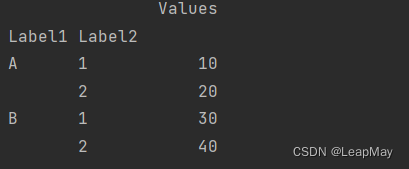
import pandas as pd# 从元组创建多层索引
index = pd.MultiIndex.from_tuples([('A', 1), ('A', 2), ('B', 1), ('B', 2)], names=['Label1', 'Label2'])# 创建带多层索引的DataFrame
data = {'Values': [10, 20, 30, 40]}
df = pd.DataFrame(data, index=index)
print(df)
1.1.2 使用 set_index() 方法创建多层索引
import pandas as pd# 创建一个普通的DataFrame
data = {'Label1': ['A', 'A', 'B', 'B'],'Label2': [1, 2, 1, 2],'Values': [10, 20, 30, 40]}
df = pd.DataFrame(data)# 使用set_index()方法将列转换为多层索引
df.set_index(['Label1', 'Label2'], inplace=True)
print(df)
1.2 访问多层索引数据
你可以使用 .loc[] 方法来访问多层索引中的数据。通过提供多个索引级别的标签,你可以精确地选择所需的数据。以下是一些示例:
# 访问指定多层索引的数据
print(df.loc['A']) # 访问Label1为'A'的所有数据
print(df.loc['A', 1]) # 访问Label1为'A'且Label2为1的数据
1.3 多层索引的层次切片
你可以使用切片操作来选择多层索引的一部分数据。如下:
# 切片操作:选择Label1为'A'到'B'的数据
print(df.loc['A':'B'])# 切片操作:选择Label1为'A'且Label2为1到2的数据
print(df.loc['A', 1:2])
1.4 多层索引的重塑
你可以使用 .stack() 和 .unstack() 方法来重塑具有多层索引的数据。.stack() 可以将列标签转换为索引级别,而 .unstack() 可以将索引级别转换为列标签。如下:
# 使用stack()方法将列标签转换为索引级别
stacked_df = df.stack()# 使用unstack()方法将索引级别转换为列标签
unstacked_df = stacked_df.unstack()
这些是关于Pandas多层索引的基本说明和示例。多层索引是处理复杂数据的重要工具,使你能够更灵活地组织和访问数据。你可以根据数据的特点和需求来选择使用多层索引的方式。
2 自定义函数和映射
在 Pandas 中,你可以使用自定义函数和映射来对数据进行转换和处理。这些方法非常有用,因为它们允许你根据自己的需求自定义数据操作。以下是有关如何在 Pandas 中使用自定义函数和映射的详细说明和示例:
2.1 使用 apply() 方法进行自定义函数操作
apply() 方法可以用于在DataFrame的行或列上应用自定义函数。你可以将一个函数应用到一列,也可以将其应用到整个DataFrame。以下是示例:
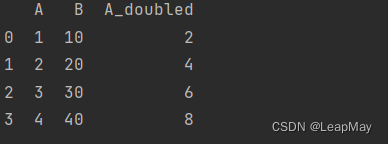
import pandas as pd# 创建一个示例DataFrame
data = {'A': [1, 2, 3, 4],'B': [10, 20, 30, 40]}
df = pd.DataFrame(data)# 自定义函数,将A列的值加倍
def double(x):return x * 2# 使用apply()将自定义函数应用到A列
df['A_doubled'] = df['A'].apply(double)print(df)
输出:
2.2 使用 map() 方法进行映射操作
map() 方法可以用于将一个Series的值映射为另一个Series的值,通常用于对某一列进行值替换或映射。以下是示例:
import pandas as pd# 创建一个示例DataFrame
data = {'A': ['foo', 'bar', 'baz'],'B': [1, 2, 3]}
df = pd.DataFrame(data)# 创建一个字典来映射A列的值
mapping = {'foo': 'apple', 'bar': 'banana', 'baz': 'cherry'}# 使用map()将A列的值映射为新的值
df['A_mapped'] = df['A'].map(mapping)print(df)
输出:
2.3 使用 applymap() 进行元素级的自定义函数操作
applymap() 方法用于对DataFrame的每个元素应用自定义函数。这是一种适用于整个DataFrame的元素级别的操作。以下是示例:
import pandas as pd# 创建一个示例DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6]}
df = pd.DataFrame(data)# 自定义函数,将每个元素乘以2
def double(x):return x * 2# 使用applymap()将自定义函数应用到整个DataFrame
df_doubled = df.applymap(double)print(df_doubled)
输出:

这些是在 Pandas 中使用自定义函数和映射的基本示例。通过使用这些方法,你可以自定义数据操作,使其满足你的需求。无论是进行数据清理、数值计算还是进行值映射,自定义函数和映射都是非常有用的工具。
3 Pandas性能优化常用技巧和操作
Pandas 性能优化是一个重要的主题,特别是当你处理大规模数据集时。以下是一些用于提高 Pandas 性能的一般性建议和技巧:
选择合适的数据结构: 在 Pandas 中,有两种主要的数据结构,DataFrame 和 Series。确保选择最适合你数据的结构。例如,如果你只需要处理一维数据,使用 Series 比 DataFrame 更高效。
避免使用循环: 尽量避免使用显式的循环来处理数据,因为它们通常比 Pandas 内置的向量化操作慢。使用 Pandas 内置的函数和方法,如
apply()、map()和groupby()来替代循环操作。使用
at和iat访问元素: 如果只需要访问单个元素而不是整个行或列,请使用.at[]和.iat[]方法,它们比.loc[]和.iloc[]更快。使用
.loc[]和.iloc[]进行切片: 使用.loc[]和.iloc[]可以实现更快的切片和索引,避免复制数据。使用.loc[]和.iloc[]进行索引: 使用.loc[]和.iloc[]索引器来访问数据,这比直接使用中括号[]更高效,特别是当你需要选择多行或多列时。适当设置内存选项: 通过设置 Pandas 的内存选项,如
pd.set_option('max_rows', None)和pd.set_option('max_columns', None),可以控制显示的最大行数和列数。这有助于防止在大型数据集上显示大量数据。合并和连接优化: 使用合适的合并和连接方法,如
pd.merge()和pd.concat(),并使用on、how和suffixes等参数来优化操作。使用合适的数据类型:尽量使用
astype()方法来显式指定数据类型,而不是让 Pandas 自动推断。这可以减少内存使用并提高性能。 Pandas 会自动为每一列选择数据类型,但你可以显式指定数据类型来减少内存使用并提高性能。使用pd.to_numeric()、pd.to_datetime()等方法将列转换为正确的数据类型。使用 HDF5 存储: 对于大型数据集,考虑将数据存储在 HDF5 格式中,以便快速读取和写入数据。
适时使用
inplace参数: 在 Pandas 中,许多方法默认不会修改原始数据,而是返回一个新的对象。如果你确定要在原始数据上进行操作而不需要创建新对象,可以使用inplace=True参数来节省内存和提高性能。并行处理: 对于大数据集,考虑使用并行计算来加速数据处理。Pandas 提供了
multiprocessing库来实现并行处理。