目录
一、自监督学习
二、BERT的两个问题
三、GLUE
四、BERT与Transformer的关系
五、BERT的训练方式
六、BERT的四个例子
1、语句分类(情感分析)
2、词性标注
3、立场分析
4、问答系统
七、BERT的后续
1、为什么预训练后的微调可以满足多场景
2、BERT在非自然语言领域应用
3、Multi-BERT
4、奇怪的Bias
八、GPT
一、自监督学习
为什么讲BERT要先提到自监督学习呢,因为BERT中的Mask language model思想就来自于自监督学习。
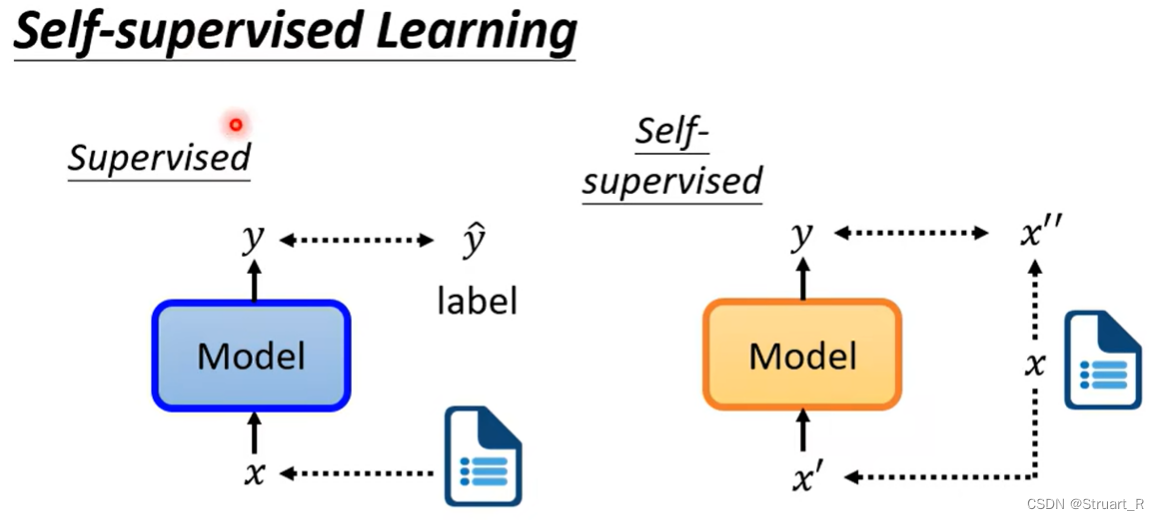
自监督学习:通过使用无标签数据,通过利用自身数据的特征、关系来训练出一个满足数据特征的模型。但其实也并非用不到标签,而是构造辅助的数据集和标签来进行训练。
二、BERT的两个问题
BERT主要研究两个问题Masking input和Next sentense prediction。
在NLP领域,做文字接龙时可以将数据集中一部分文字做随机的Mask,构造辅助的数据集和标签,来训练那些被删除掉的字或词。如下面这张图中,“湾”这个字就是被Mask掉的,可能输入是一个特殊的token,也有可能是一个随机的噪声字,输出时通过归一化后,做了一个分类,分类最高分就是我们要求训练的东西,也就是被删除的字。

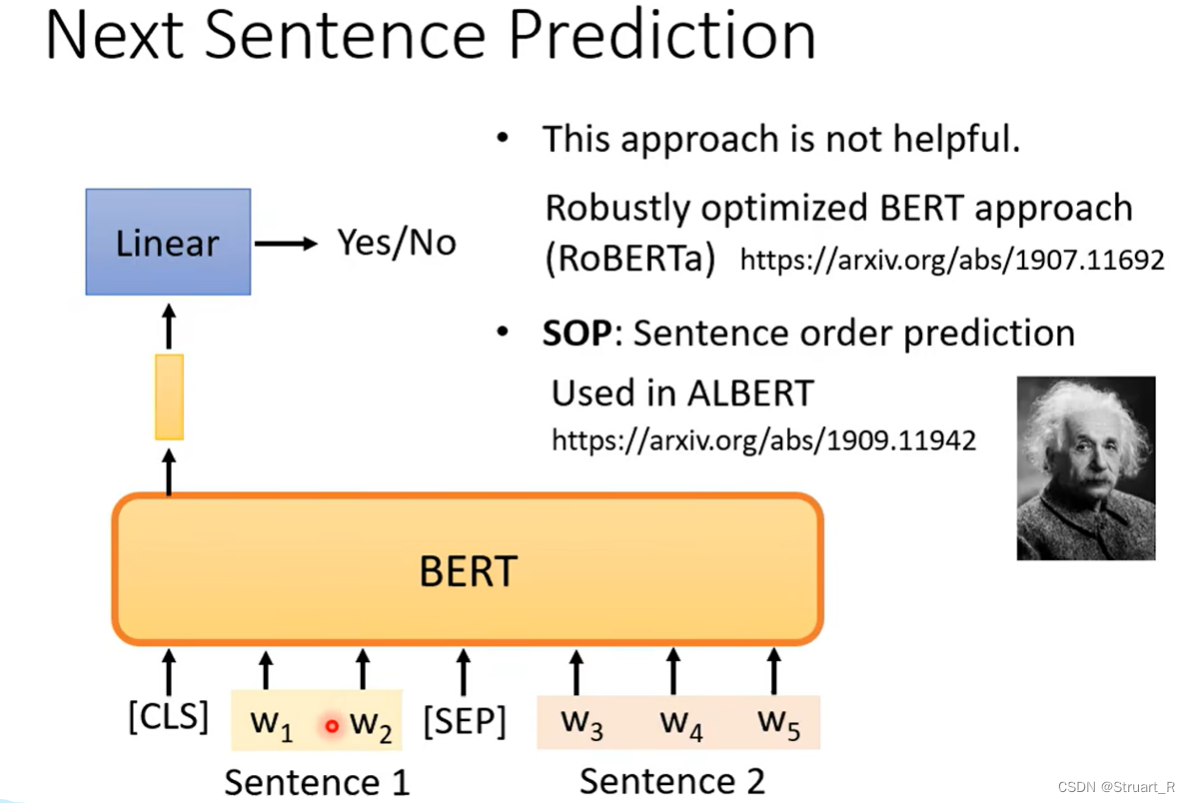
在NLP领域,还有一个句子序列是否相接正确问题。在BERT中,通过[SEP]划分两个句子,将[CLS]丢入BERT模型,再经过Linear后输出句子1和句子2是否连接的真值。但很多文献说这个方法并没有什么用。
另一个模型ALBERT使用的是SOP而不是传统BERT的NSP方法,能达到更好的预训练效果。
三、GLUE
在NLP领域分为NLU(自然语言理解)和NLG(自然语言生成)两个部分,为了寻求NLU的评判标准,诞生了GLUE(Gerenal Language Understanding Evaluation)这个涵盖多任务的自然语言理解基准和分析平台,GLUE包含CoLA、SST-2、MRPC、STS-B、QQP、MNLI、QNLI、RTE、WNLI九个任务涵盖自然语言推断、文本蕴含、情感分析等方面。

四、BERT与Transformer的关系
其实BERT也是基于Transformer的架构的一种“预训练模型”,相比于传统Transformer有几个区别:
1、BERT是双向性的,可以利用context来进行预测每个词,而传统Transformer和GPT都是利用左侧的信息。
2、预训练任务,BERT采用了Masked Language Model任务,也就是随机Mask一些词,来预测被Mask掉的词。
3、NSP,判断两个句子是否相连,理解句子与句子之间的关系。
4、数据量更大,参数更多,层次更多,模型更大,相比于传统Transformer输入一串序列,输出一串序列,BERT可以生成更高质量的文本信息。
五、BERT的训练方式
BERT训练分为两个阶段,预训练(Pre-training)和微调(Fine-tuning)。
预训练,使用大量无标签的文本进行训练,并进行MLM和NSP两个部分,来学习到通用的语言表示,包括词的级别和句子级别的信息。
微调,将带有标签的任务数据对BERT进一步训练,可以针对不同的下游任务,比如问答、情感分类等,将任务特定的输出层添加到BERT模型的顶部,利用标注数据进行监督学习。依靠不同的下游任务学习到更符合不同任务的模型。
六、BERT的四个例子
1、语句分类(情感分析)
语句分类,也就是对于某一个句子分类他的感情色彩,比如positive和negitive。
具体做法仍然是将一个句子的CLS扔入BERT中,输出向量做Linear+Softmax的归一化,得到的类别进行二分类问题。

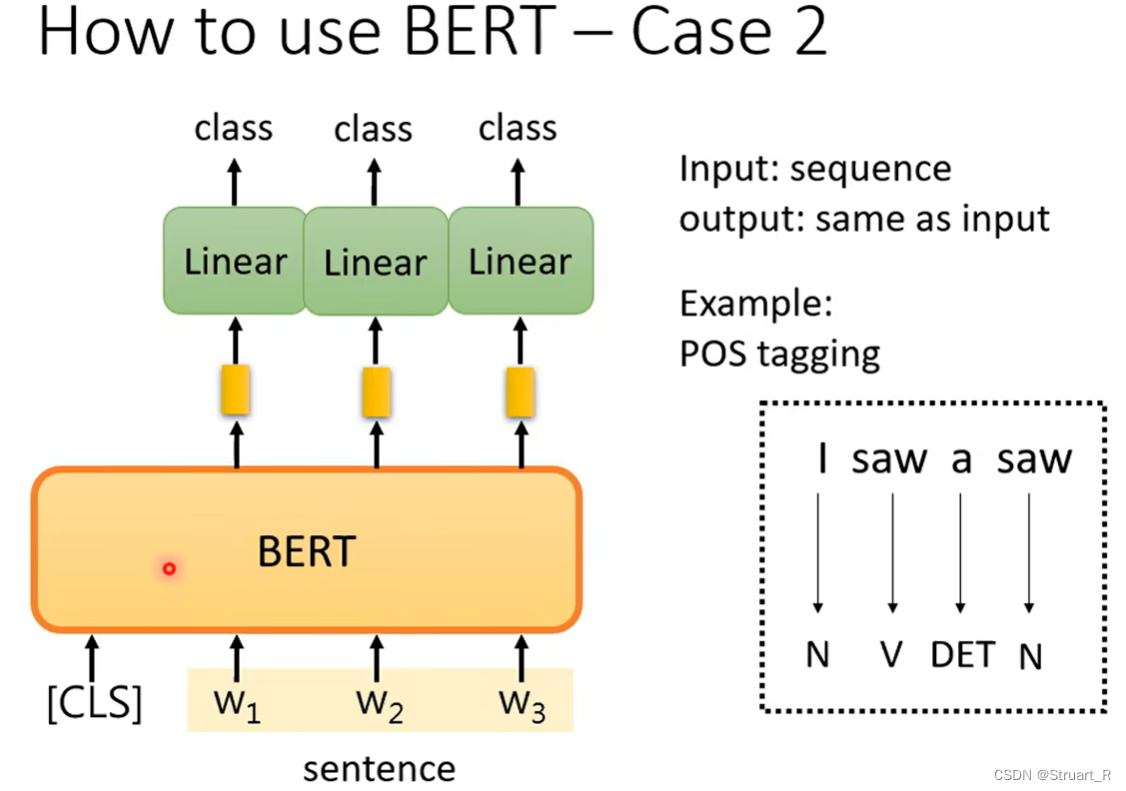
2、词性标注
对于每一个token的输出向量做Linear+Softmax操作,得到的向量进行多分类问题,来预测各个词的词性。
3、立场分析
输入两个句子,前提和假设,让模型去判断假设是与前提立场相同,或是反对,亦或是保持中立。
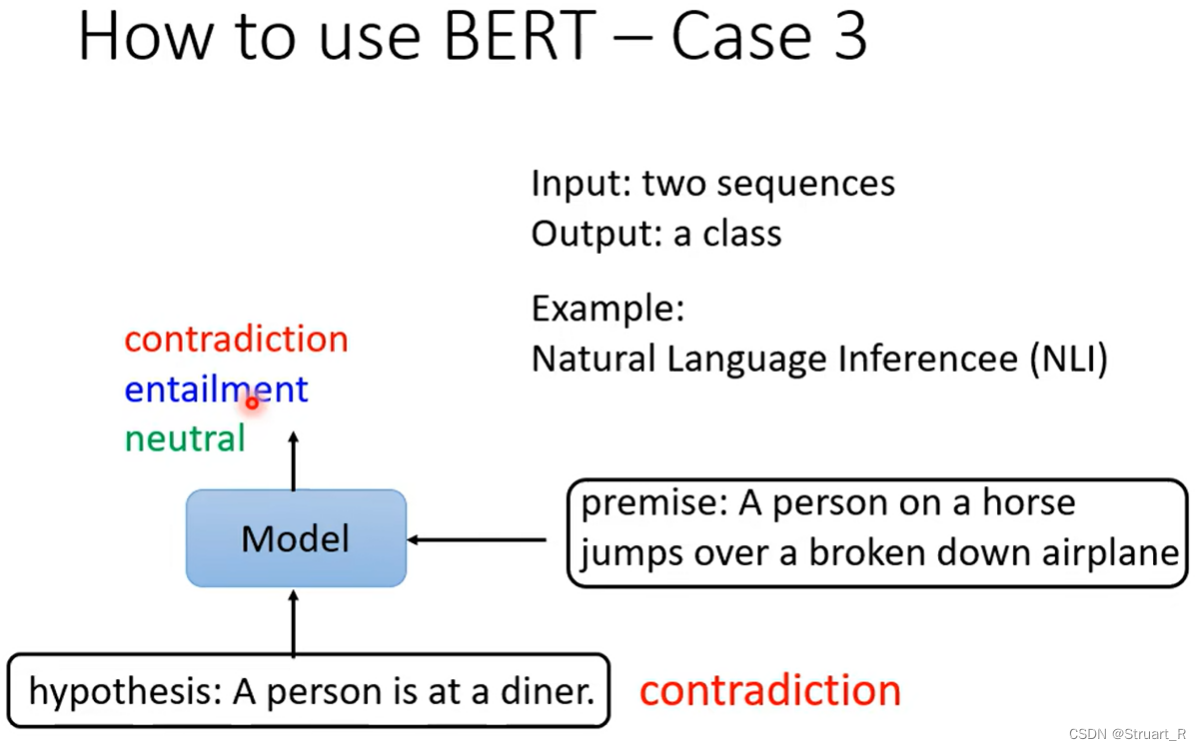
在具体操作中,仍然是将CLS作为两个句子之间的立场关系,通过CLS的输出向量进入Linear+Softmax后进行多分类操作,预测立场。 (这一点与NSP类似)
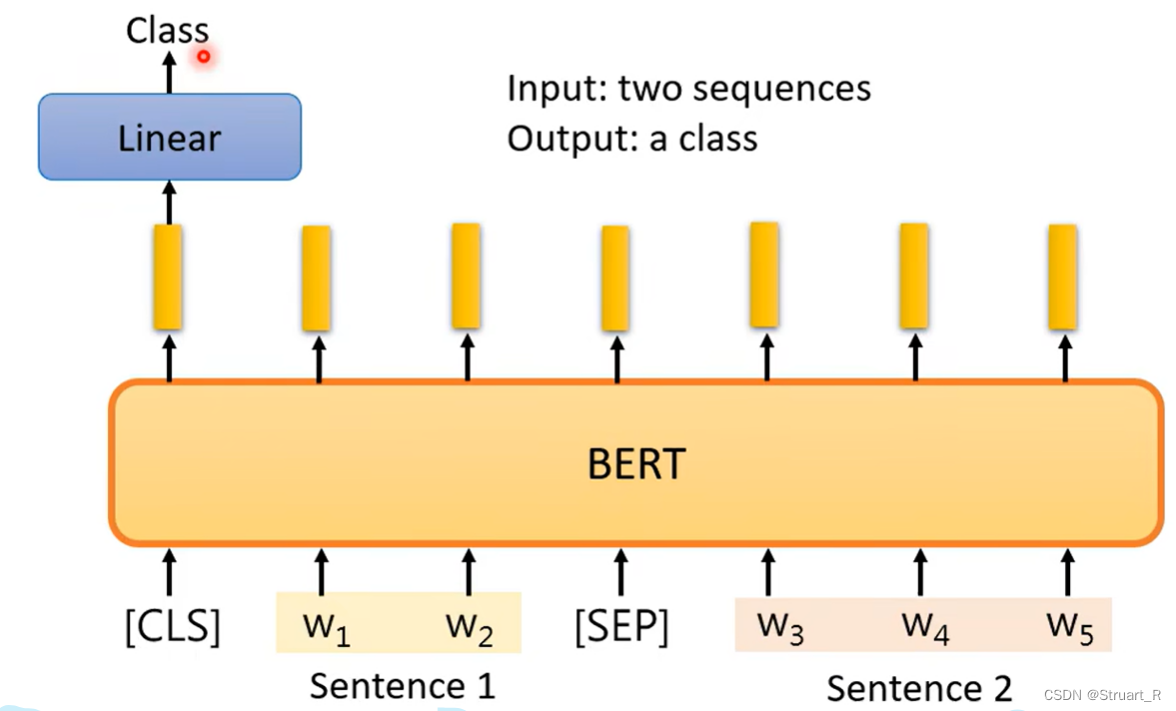
4、问答系统
通过学习已知文章库,找出某个问题的答案,答案的内容必须在文章中,也就是说截一个片段,一个词语作为答案。问答系统中,通过输入问题和文章库,输出两个值s和e,则答案就是从第s到第e个词汇的片段。

具体做法是,随机初始两个向量,为答案的开始和结束,分别在下图为橘色和蓝色框框,这个长度要与输出长度一致,通过分别和输出的向量做内积后判断最大值得到两个最大值的输出索引,分别就是s和e。


七、BERT的后续
1、为什么预训练后的微调可以满足多场景
其实感觉还是有一定的玄学因素,下图是通过测量不同语境下同一个词的余弦相似度,做了混淆矩阵证明Pre-train确实可以让BERT在无标签文本数据中学会词与词,句子之间的信息关系,这样可以迁移到不同的下游任务中。


2、BERT在非自然语言领域应用
将BERT应用于蛋白质、DNA、音乐等非自然语言领域的分类,通过每个氨基酸给定一个词汇、每一个音符给定一个词汇,将任何非文字的形式也可以转换成词向量,然后按照最开始语句分类来做。由于BERT模型在Pre-train中学习到了通用的语言表示,有一定的泛化能力,最后发现实验的效果很不错。

3、Multi-BERT
更玄学的东西。
使用中文甚至多种语言来进行Pre-train,利用Chinese+English进行微调,但测试Chinese竟然分数比单纯用Chinese的微调,竟然分数高。另外Pre-train中只是进行了完形填空,但微调做了中文的Q&A,也可以做到很好地Test Score。
这也说明了虽然不同的语言,但在Pre-train Multi-Languages时其实已经学会了其中的语义,而不只是语言,可以理解为BERT一视同仁了。

4、奇怪的Bias
通过微调学习中文的Q&A,但添加了中文微调Q&A与英文微调Q&A之间的Bias,就可以在不直接微调学习英文Q&A的情况下,得到微调学习英文Q&A的效果,间接学习!

八、GPT
GPT模型,仍然是一种无监督的进行预训练,有监督的下游任务微调的结构,是基于Transformer的一种预训练语言模型。
GPT相较于Transformer来说,使用了多次迭代12次的decoder模块(且删除了中间的Multi-Head Attention模块)
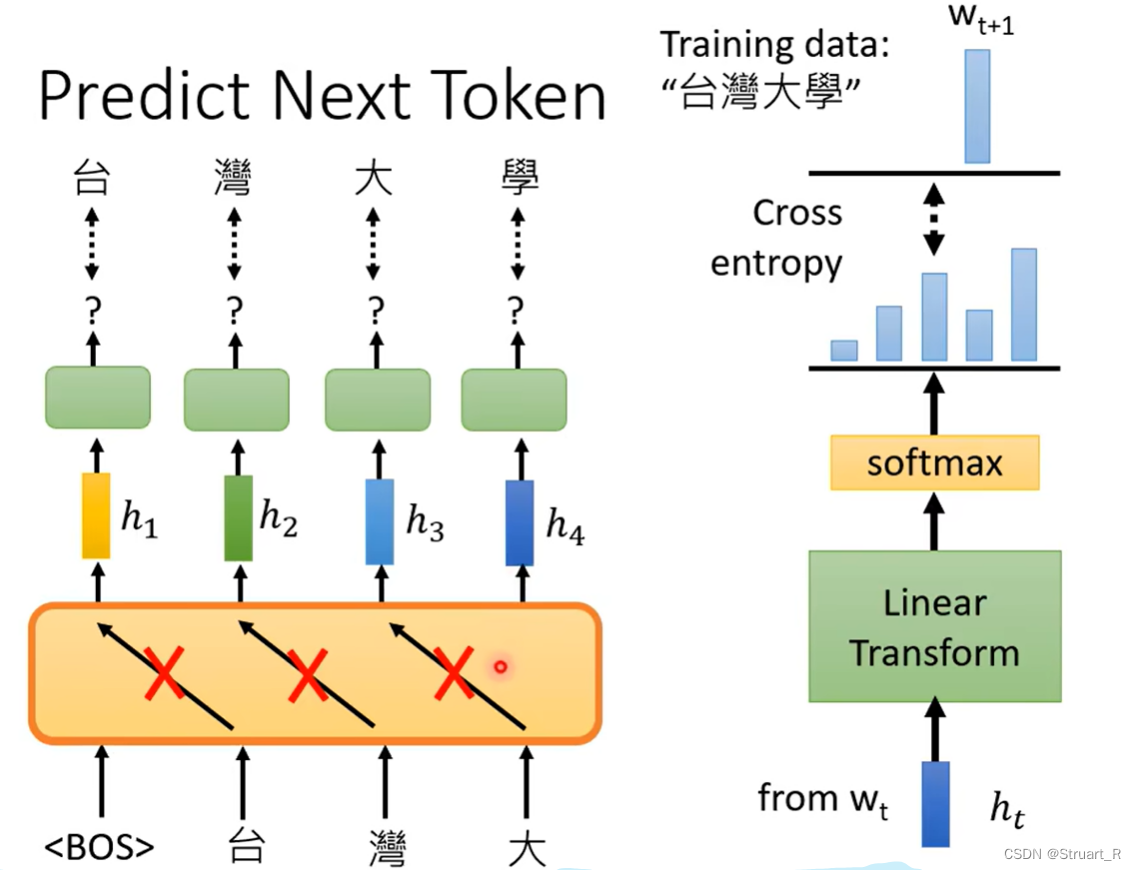
相比于BERT进行做完形填空,GPT目的是进行生成下一个token。
另外就是,GPT也是只知道上文不知道下文的注意力机制,要不然就出现了漏题的效果。
参考视频:2021 - 自监督式学习 (三) – BERT的奇闻轶事_哔哩哔哩_bilibili