Linux环境要求
jdk1.8及以上
python2
准备工作
Linux安装jdk
yum install -y java-1.8.0-openjdk.x86_64
查看是否安装成功
java -version
linux安装python
yum install -y python
查看python版本号,判断是否安装成功
python --version
下载DataX:
DataX压缩包导入,解压缩
tar -zxvf datax.tar.gz
编写同步Job
在datax/job下,json格式,具体内容及主要配置含义如下
mysqlreader为读取mysql数据部分,配置mysql相关信息
username,password为数据库账号密码
querySql:需要查询数据的sql,也可通过colums指定需要查找的字段(querySql优先级高)
elasticsearchwriter部分为数据写入ES部分,配置ES相关信息,
endpoint为ES地址,index为索引,columns为需要写入列的信息,其余配置选填
坑!:若运行时提示mysql连接失败,且账号密码,ip,端口号都没问题的情况下,需要像文中一样在jdbcUrl的内容后面加上useSSL=false"
vim /opt/software/datax/job/job.json
将内容换成以下内容
{"job": {"setting": { "speed": {"channel": 1},"errorLimit": {"percentage": 0}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","connection": [{"querySql": ["select * from user_t"],"jdbcUrl": ["jdbc:mysql://数据库地址:3306/mysql?useSSL=false"]}]}},"writer": {"name": "elasticsearchwriter","parameter": {"endpoint":"http://ES地址:9200","accessId":"","accessKey":"","index": "user-demo","cleanup": false,"discovery":false,"column": [{"name": "id","type": "id"},{"name": "userName","type": "text"},{"name": "address","type": "text"}]}}}]}}配置好之后执行命令:
python /opt/software/datax/bin/datax.py /opt/software/datax/job/job.json
注意换成自己的datax路径
正常情况下输出一大堆之后会是这样,由于我在mysql表中插了三条测试数据
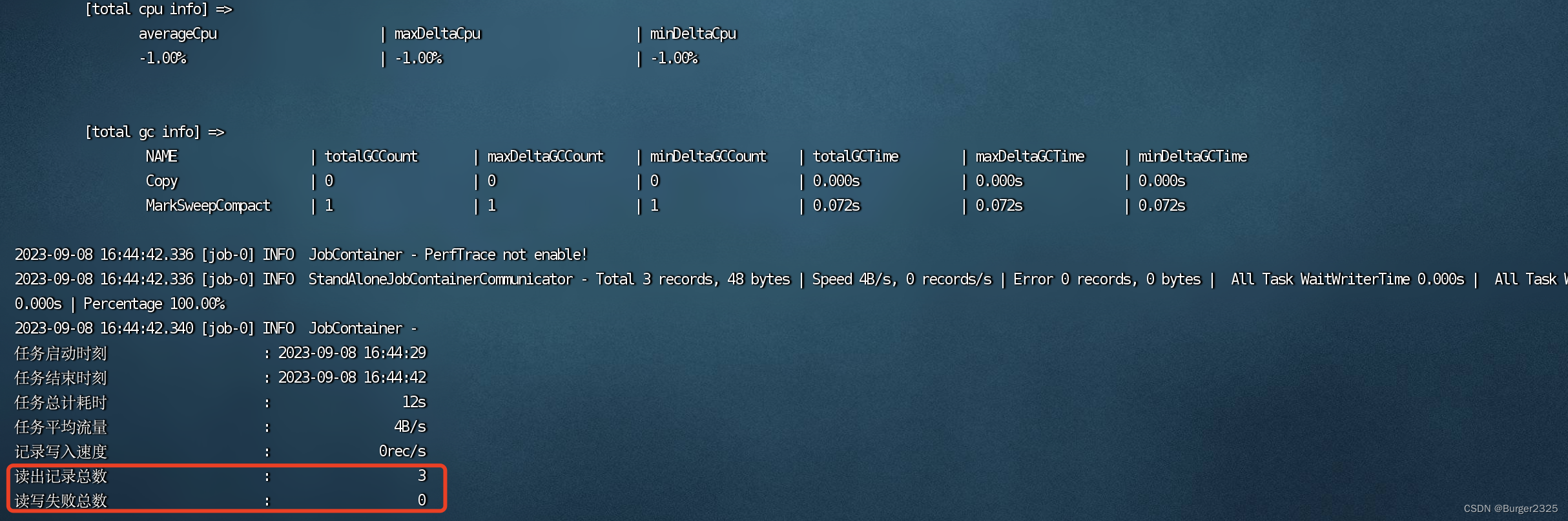 完成操作
完成操作