本文致力于让读者对以下这些模型的创新点和设计思想有一个大体的认识,从而知晓YOLOv1到YOLOv4的发展源流和历史演进,进而对目标检测技术有更为宏观和深入的认知。本文讲解的模型包括:YOLOv1,SSD,YOLOv2,YOLOv3,CenterNet,EfficientDet,YOLOv4。
R-CNN
候选区域
SPP-Net
和R-CNN最大区别是什么?
先提取特征,再对候选区域做处理?
Fast R-CNN:
并行选择性搜索算法和ConvNet提取特征
将SPPNet中的金字塔池化替换为RoI池化层
Faster R-CNN
每个候选框一个分数,就不用手工设计算法来筛选候选框了,用CNN进行候选区域的提取
二阶段目标检测算法 将目标检测作为一个 分类问题 来解决,(S1)一个模块提出一些候选框,(S2)后续的网络将其分类为目标或背景
YOLO将 目标检测问题 重构成一个 回归问题 ,直接将图片中的每个像素分类为 (1)目标、(2)边界框、 (3)不是目标(也就是背景) 这三种类型
单阶段目标检测算法
YOLOv1
YOLOv1的设计灵感来自于GoogLeNet模型,使用较小的卷积网络的级联模块。使用的具体细节是,使用GoogLeNet在ImageNet上预训练过、精度已经很高的预训练模型。在此基础上,添加随机初始化的卷积层和全连接层进行微调fine-tuning
YOLOv1在准确性和速度都远远超过当时的两阶段实时目标检测模型,但是小目标检测和密集目标检测效果不好
SSD
基于VGG-16来构建的
模型浅层的SSD(特征图的size比较大,小目标的信息被保留的比较完整)用来检测较小的目标。较深的层用来 检测较大的物体
在训练期间,SSD将每个GT框(ground truth)与具有最佳IoU的默认框匹配,( 【我猜】truth的答案标签 框 和你模型预测的 框 相匹配),并相应的训练网络,类似Muti-Box。(啥是Multi-box?)
SSD作者还使用了困难负样本挖掘和(啥是困难负样本挖掘?)大量数据增强方法
损失函数:与DPM(啥是DPM?)类似,SSD利用 定位损失 和 置信度损失 的 加权和,作为总的损失值来训练监督模型
并通过执行菲最大抑制NMS(什么是是非最大抑制,有什么用?)获得最终输出
SSD在检测小目标方面也存在困难。这个问题可以通过使用更好的backbone网络(如ResNet)来解决
YOLOv2
相比YOLOv1,YOLOv2提供了速度和准确性之间良好的平衡
YOLOv2,是YOLO系列中,首次使用了DarkNet-19作为backbone的。,
使用了BatchNormalization以提高收敛性
分类和检测系统的联合训练以增加检测类别(意思是:分类 和 打bouding box 这两个任务一起训练, 然后类别就多了? 啥叫检测类别? 识别是人,是车,是摩托?这和前面的联合训练有什么关系)
移除Fully connected层以提高速度(参数量小了,计算量小了,速度自然块 )
使用学习的anchor框(是可学习的anchor框吧?)来提高召回率recall并获得更好的先验(啥叫先验?事先就知道这些框有可能是真实的框?)
recall=TP/(TP+FN)。实际为正的样本里,预测正确的样本的比例。所有的罪犯里,有多少罪犯被你抓住了。
precision=TP/(TP+FP)。在你预测为正的样本集合里,多大比例是被正确预测的。所有你认为是犯人,被抓进Police局里人里,多少人真的是犯人
YOLOv2的作者Redmon等人,使用WordNet将分类和检测数据集,组合在层次结构中。此WordTree可以用于预测更高的上位词条件概率,从而提高系统的整体性能。(啥意思啊?不知所云!)
YOLOv3
YOLOv3是在YOLOv2基础上做增量改进,整个范式上没有太大的改进了。YOLOv3相比YOLOv2只是速度上更快了,但是上从技术上是没有突破的。
使用了比YOLOv2的backbone Darknet-19更大更深的网络Darknet-53来做backbone。 Darknet-53和Darknet-19的不同是,53增加了残差结构。缓解了因为网络过深带来的梯度消失问题,从而使得网络变得更深。
使用了 数据增强、多尺度训练 muti scale training、Batch Normalization。
分类器中的softmax层被逻辑分类器所取代。(是logistics regression吗?)
CenterNet
抛弃了传统的bouding box这种对目标object进行建模的方式,将一个object用 一个 点 来表示。这个 点 是bouding box的中心点。
输入图像通过高斯半径生成热力图Heatmap, Heatmap head用于确定目标中心,Dimension Head用于估计目标大小(从目标中心向外半径多少),Offset head用于校正目标点的偏移。
CenterNet使用预训练的DLANet作为提取器网络(什么是DLANet?有什么独特的优良特性),这个DLANet网络有3个Head: Heatmap Head, Dimension Head, Offset Head。这三个Head的多任务损失在训练时被反向传播到特征提取器进行参数更新,梯度优化。
他比之前的工作更准确,推理时间更短。
EfficientDet
比之前的模型准确率更高,效率更高(体现在哪里?),是可扩展的目标检测器(可扩展体现在哪里?——可以把这个EfficientDet很好的推广到其他任务上)
引入了高效的多尺度特征、BiFPN和模型缩放(啥叫模型缩放?是不是指的,我串联堆叠3个BiFPN也行,五个也行,一个也行)。BiFPN是 具有可学习权重的 双向Bi-directional 特征金字塔Feature Pyramid Network,用于在不同尺度上将输入特征 交叉连接。
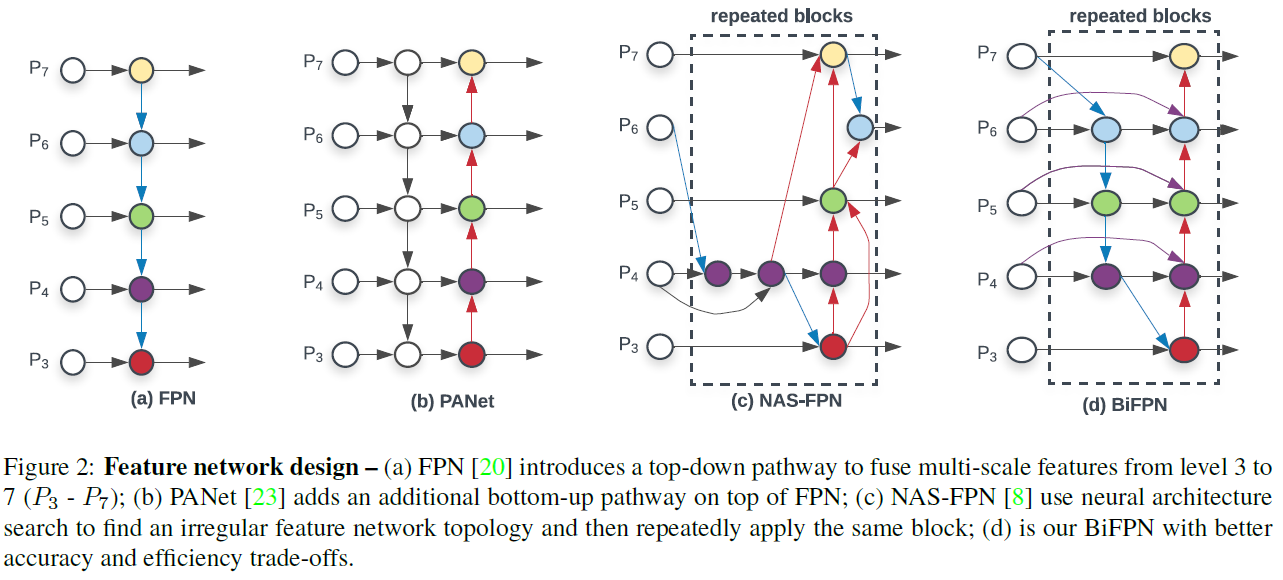
上图想展示的是作者如何一步步改机和演进,从而设计出BiFPN这个网络
第一步 (a) 是利用 top-down自上而下的方式去融合level 3到level 7的特征(P3-P7)
第二步 (b)在top-down的FPN的基础之上 ,串联 一条 通路 path, 可以bottom-up 自底向上
第三步(c)引入NAS(Neural Architecture Search)神经网络架构搜索技术,去找到一条不规则的特征提取网络Feature Network的拓扑结构topology,然后重复串行这个结构多次(我猜的,不知道对不对)。你看图(c)就会发现这个网络结构十分不规则和奇怪,但是这种奇怪的网络结构是最优的网络结构。(或者performance更好,或者保证前者的基础上参数量相对较少)
第四步(d)在权衡的accuracy和efficiency的基础上,平衡二者最优的架构是这个样子的结构的BiFPN。
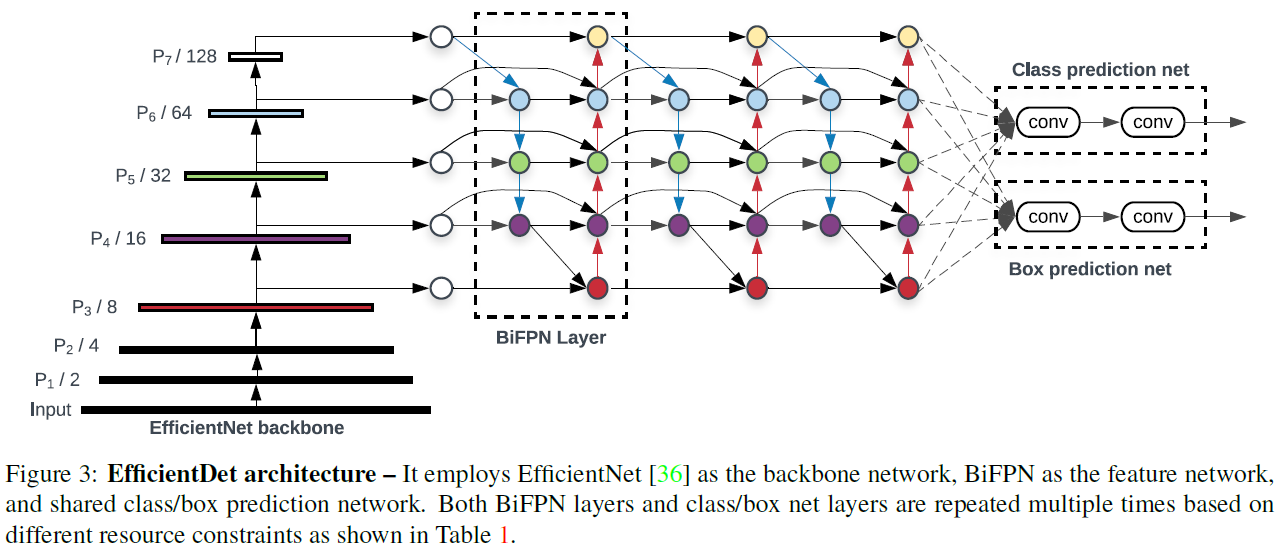
EfficientDet利用EfficientNet作为主干网络(下图左边那个),将多组BiFPN层串联堆叠作为特征提取网络(下面这个示意图,从左到右,堆叠了三个BiFPN)。最终BiFPN层的每个输出都被送到分类网络和框检测。
YOLOv4
YOLOv4相比YOLOv3在范式上没有太大的改进,只是一堆Trick(奇淫巧技)的集合,使得模型速度很快,易于训练。
为了改进性能引入了,数据增强、正则化方法、类标签平滑、CIoU-loss、CmBN(Cross mini-Batch Normalization)、自对抗训练、余弦退火算法来改进其最终的性能。
使用了Mish激活函数、跨阶段部分连接CSP(Cross Stage Partial)、SPP-block(Spatial Pyramid Pooling)、PAN路径聚合块(Path Aggregation Network)、多输入加权残差连接MiWRC(Multiple input Weighted Residual Connection)
检测头沿用YOLOv3的,backbone在YOLOv3的Darknet-53的基础上加入CSPNet,骨干网络是CSPNetDarknet-53.
趋势总结
整体趋势,逐渐走向End-to-End端到端
End-to-End的意思是,从输入数据的开始端到模型处理得到最终结果的结束段之间,不需要将问题拆分成多个独立的子问题。开始端到结束端整个过程一体化的进行优化。
(1)Craft Free, 不再需要手工设计特征,用神经网络来自动提取特征
(2)proposal free, 不需要候选区域推荐,从二阶段算法到单阶段算法
(3)anchor free
(4)NMS free, YOLOX尝试过,但是没提供代码










![[Qt]基础数据类型和信号槽](https://img-blog.csdnimg.cn/5e3bbac85e3f4c56801d12f932fc662d.png)
