贡献
将深度神经网络应用于视频动作识别的难点,是如何同时利用好静止图像上的 appearance information以及物体之间的运动信息motion information。本文主要有三点贡献:
1.提出了一种融合时间流和空间流的双流网络;
2.证明了直接在光流上训练的网络,即使训练集很小,仍能获得很好的效果;
3.在两个动作识别数据集上使用多任务学习(multi-task learning),同时训练一个backbone,可以增加训练数据量,提高模型性能。
简介
所谓two-stream是指空间stream和时间stream,视频可以分成空间与时间两个部分,空间部分指独立帧的表面信息,关于物体、场景等;而时间部分信息指帧间的光流,携带着帧之间的运动信息。相应的,所提出的网络结构由两个深度网络组成,分别处理时间与空间的维度。
网络结构
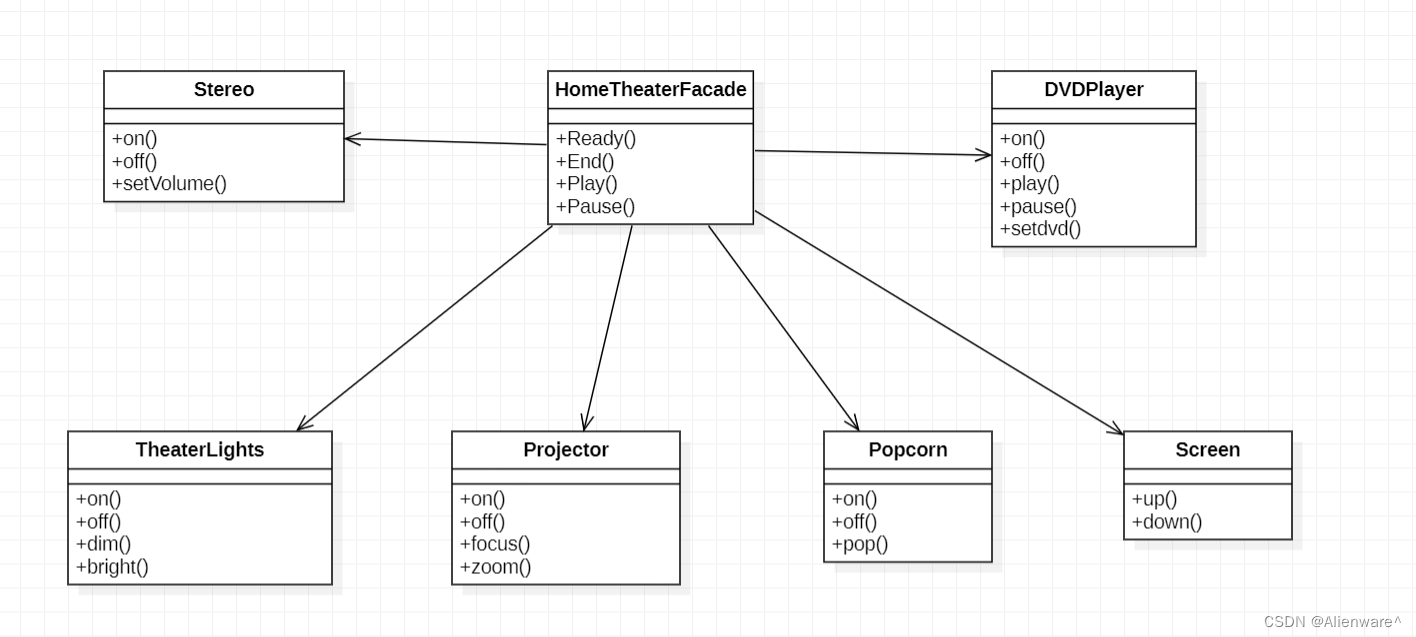
结构如下图所示:

- Spatio Stream Convet:空间流卷积网络,输入是单个帧画面(静态图片),主要学习场景信息。因为是处理静态图片,所以可以使用预训练的模型来做,更容易优化。最后根据网络输出的特征得出一个logist(假设模型是在UCF-101数据集上做测试,数据集共101个类,logist是softmax之后的类别概率,那么时间流网络的输出就是一个1×101维的向量)。
- temporal stream convet:时间流卷积网络(光流网络),输入是光流图像,通过多帧画面的光流位移来获取画面中物体的运动信息,最后也根据网络输出的特征得出一个logist。
- 光流输入显式地描述了视频帧之间的运动,而不需要CNN网络去隐式地估计运动信息,所以使得识别更加容易。加入时间流卷积网络之后,模型精度大大提升。
- 直接以光流做输入来预测动作,而不用CNN本身去学动作信息,大大简化了学习过程。
融合有两种方式:
- late fusion融合:两个logist加权平均得到最终分类结果(比如两个softmax向量取平均,再做一个argmax操作)。
- 将softmax分数作为特征再训练一个SVM分类器。







![[EROOR] SpringMVC之500 回调函数报错](https://img-blog.csdnimg.cn/980079d0436c43cbad6c395d83ea80d5.png)