ECA注意力机制简介
论文题目:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
论文地址:here
基本原理
🐸 ECANet的核心思想是提出了一种不降维的局部跨通道交互策略,有效避免了降维对于通道注意力学习效果的影响。适当的跨通道交互可以在保持性能的同时显著降低模型的复杂性,通过少数参数的调整,获得明显的效果增益。通过这种机制,ECANet能够在不增加过多参数和计算成本的情况下,有效地增强网络的表征能力。
具体添加步骤
tips:在前两篇文章当中,我们提到了注意力机制的添加方法。
分为
不带有通道数的注意力机制:参考这篇文章 添加方法
带通道数的注意力机制:参考这篇文章添加方法
他们之间的区别在于,观察注意力机制的源代码中是否含有channel参数。
🔔 (1)在models文件夹下,新建一个:注意力机制名字.py。如本篇文章中使用ECAAttention.py.
🔔 (2)添加ECA注意力机制的代码
# author:mawei,SZU
import torch
from torch import nn
from torch.nn import init
class ECAAttention(nn.Module):def __init__(self, kernel_size=3):super().__init__()self.gap = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2)self.sigmoid = nn.Sigmoid()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):y = self.gap(x) # bs,c,1,1y = y.squeeze(-1).permute(0, 2, 1) # bs,1,cy = self.conv(y) # bs,1,cy = self.sigmoid(y) # bs,1,cy = y.permute(0, 2, 1).unsqueeze(-1) # bs,c,1,1return x * y.expand_as(x)if __name__ == '__main__':input = torch.randn(50, 512, 7, 7)eca = ECAAttention(kernel_size=3)output = eca(input)print(output.shape)
🔔 (3)修改yolo.py,添加如下行
from 你的注意力机制.py import *
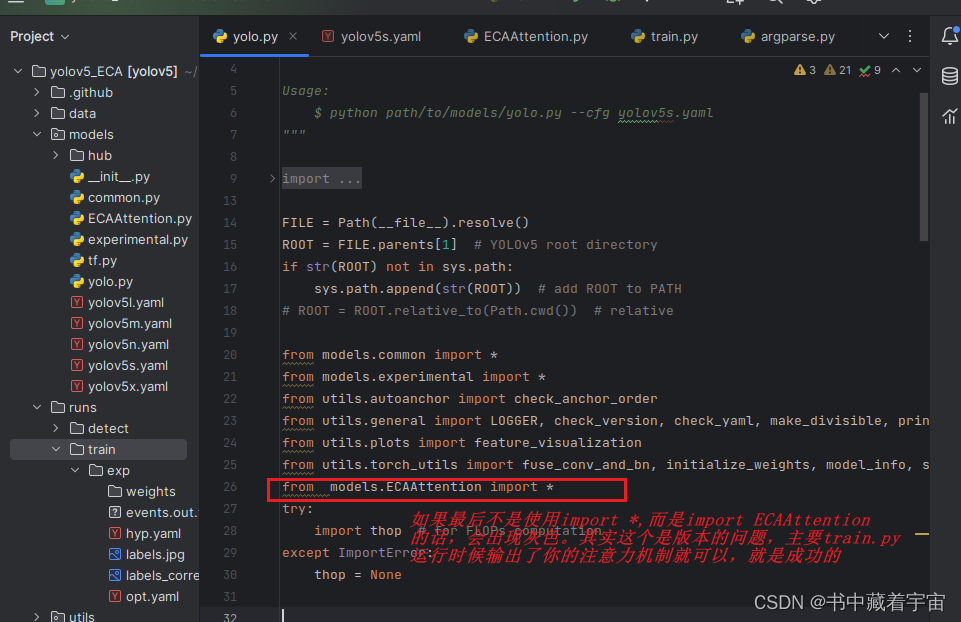
🔔 (4) 修改yolo5s.yaml,这个取决你自己使用的是那种模型文件,比如你修改yolov5m.yaml代表你使用的时候yolov5m的模型。每种模型深度和模型规模不一样。
说明:具体你添加到那一层看个人习惯,任何一层都可以。

🔔 (5)最后在train.py当中,cfg参数中添加你自己修改的yaml文件,我这里是yolov5s.yaml.
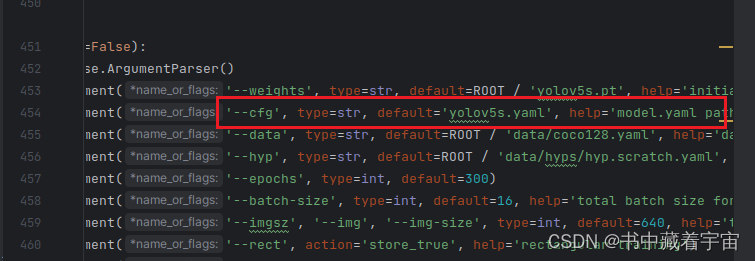
完成上诉步骤之后,就可以点击运行了。
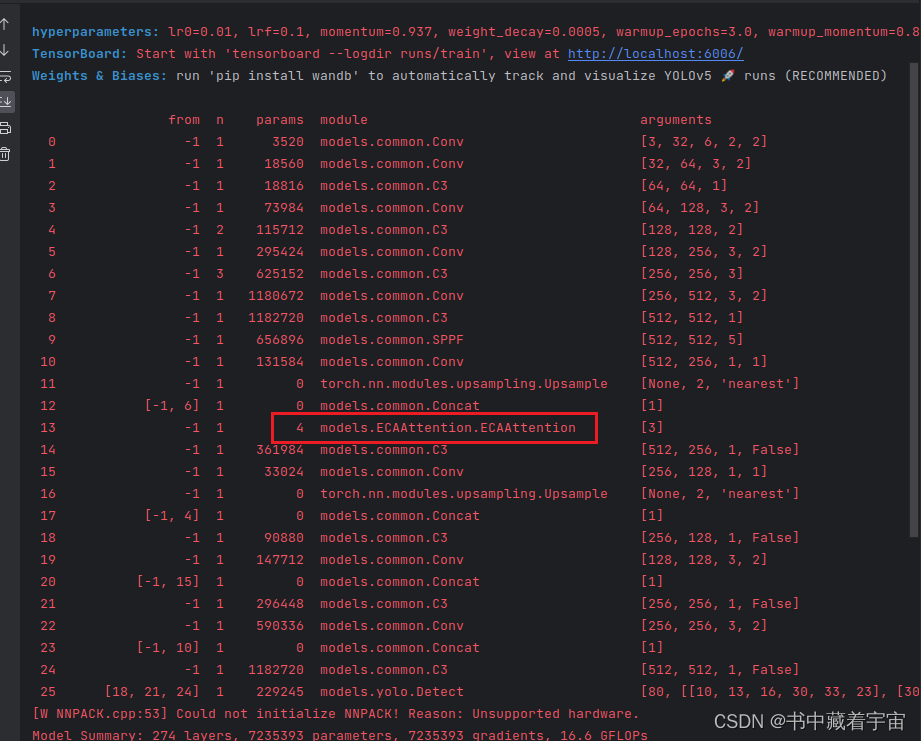
❤️yolov5,yolov7改进之SimAM 注意力机制
❤️yolov5,yolov7改进之Shuffle注意力机制