SAConv卷积
SAConv卷积模块是一种精度更高、速度更快的“即插即用”卷积,目前很多方法被提出用于降低模型冗余、加速模型推理速度,然而这些方法往往关注于消除不重要的滤波器或构建高效计算单元,反而忽略了特征内部的模式冗余。
原文地址:Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution
由于同一层内的许多特征具有相似却不平等的表现模式。然而,这类具有相似模式的特征却难以判断是否存在冗余或包含重要的细节信息。因此,不同于直接移除不确定的冗余特征方案,提出了一种基于Split的卷积计算单元(称之为SPConv),它运训存在相似模型冗余且仅需非常少的计算量。
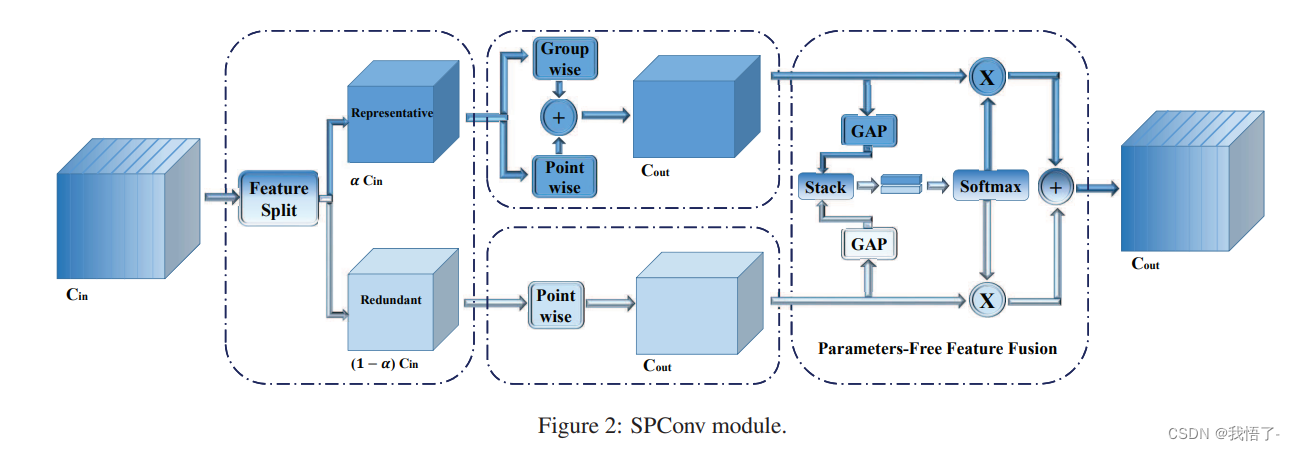
首先,将输入特征拆分为representative部分与uncertain部分;然后,对于representative部分特征采用相对多的计算复杂度操作提取重要信息,对于uncertain部分采用轻量型操作提取隐含信息;最后,为重新校准与融合两组特征,作者采用了无参特征融合模块。该文所提SPConv是一种“即插即用”型模块,可用于替换现有网络中的常规卷积。
无需任何技巧,在GPU端的精度与推理速度方面,基于SPConv的网络均可取得SOTA性能。该文主要贡献包含下面几个方面:
(1)重新对常规卷积中的特征冗余问题进行了再思考,提出了将输入分成两部分:representative与uncertain,分别针对两部分进行不同的信息提取;
(2)设计了一种“即插即用”型SPConv模块,它可以无缝替换现有网络中的常规卷积,且在精度与GPU推理速度上均可能优于SOTA性能,同时具有更少的FLOPs和参数量。
代码实现
class ConvAWS2d(nn.Conv2d):def __init__(self,in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True):super().__init__(in_channels,out_channels,kernel_size,stride=stride,padding=padding,dilation=dilation,groups=groups,bias=bias)self.register_buffer('weight_gamma', torch.ones(self.out_channels, 1, 1, 1))self.register_buffer('weight_beta', torch.zeros(self.out_channels, 1, 1, 1))def _get_weight(self, weight):weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,keepdim=True).mean(dim=3, keepdim=True)weight = weight - weight_meanstd = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)weight = weight / stdweight = self.weight_gamma * weight + self.weight_betareturn weightdef forward(self, x):weight = self._get_weight(self.weight)return super()._conv_forward(x, weight, None)def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,missing_keys, unexpected_keys, error_msgs):self.weight_gamma.data.fill_(-1)super()._load_from_state_dict(state_dict, prefix, local_metadata, strict,missing_keys, unexpected_keys, error_msgs)if self.weight_gamma.data.mean() > 0:returnweight = self.weight.dataweight_mean = weight.data.mean(dim=1, keepdim=True).mean(dim=2,keepdim=True).mean(dim=3, keepdim=True)self.weight_beta.data.copy_(weight_mean)std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)self.weight_gamma.data.copy_(std)class SAConv2d(ConvAWS2d):def __init__(self,in_channels,out_channels,kernel_size,s=1,p=None,g=1,d=1,act=True,bias=True):super().__init__(in_channels,out_channels,kernel_size,stride=s,padding=autopad(kernel_size, p),dilation=d,groups=g,bias=bias)self.switch = torch.nn.Conv2d(self.in_channels,1,kernel_size=1,stride=s,bias=True)self.switch.weight.data.fill_(0)self.switch.bias.data.fill_(1)self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))self.weight_diff.data.zero_()self.pre_context = torch.nn.Conv2d(self.in_channels,self.in_channels,kernel_size=1,bias=True)self.pre_context.weight.data.fill_(0)self.pre_context.bias.data.fill_(0)self.post_context = torch.nn.Conv2d(self.out_channels,self.out_channels,kernel_size=1,bias=True)self.post_context.weight.data.fill_(0)self.post_context.bias.data.fill_(0)self.bn = nn.BatchNorm2d(out_channels)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):# pre-contextavg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)avg_x = self.pre_context(avg_x)avg_x = avg_x.expand_as(x)x = x + avg_x# switchavg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)switch = self.switch(avg_x)# sacweight = self._get_weight(self.weight)out_s = super()._conv_forward(x, weight, None)ori_p = self.paddingori_d = self.dilationself.padding = tuple(3 * p for p in self.padding)self.dilation = tuple(3 * d for d in self.dilation)weight = weight + self.weight_diffout_l = super()._conv_forward(x, weight, None)out = switch * out_s + (1 - switch) * out_lself.padding = ori_pself.dilation = ori_d# post-contextavg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)avg_x = self.post_context(avg_x)avg_x = avg_x.expand_as(out)out = out + avg_xreturn self.act(self.bn(out))