Transformer(二)—— ResNet(残差网络)
- 一、背景
- 1.1 梯度消失/爆炸
- 1.2 网络退化(Degradation)
- 二、思路
- 2.1 为什么需要更深的网络
- 2.2 理想中的深网络表现
- 三、实践和实验效果
- 3.1 构造恒等映射:残差学习(residule learning)
- 3.2 残差网络
- 四、Transformer中的残差连接
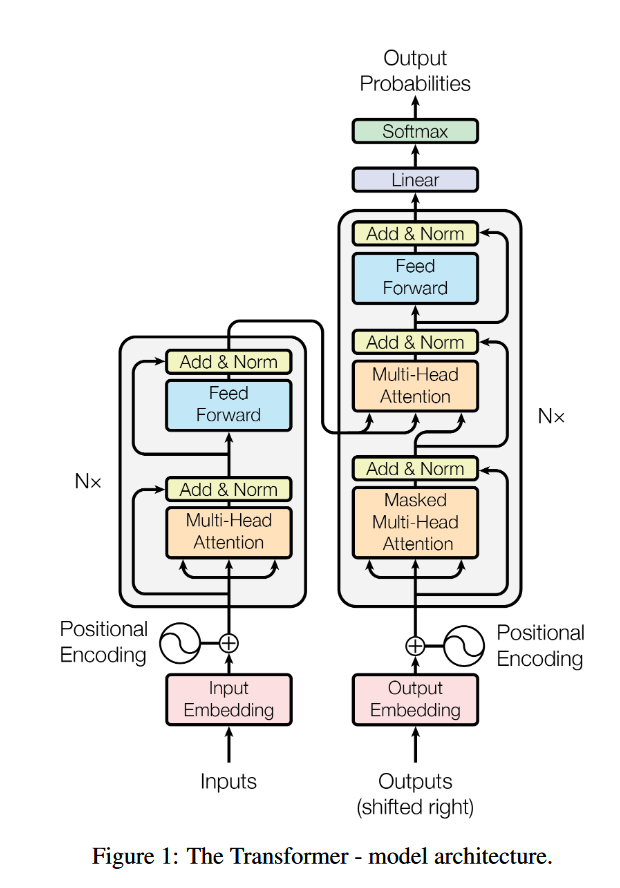
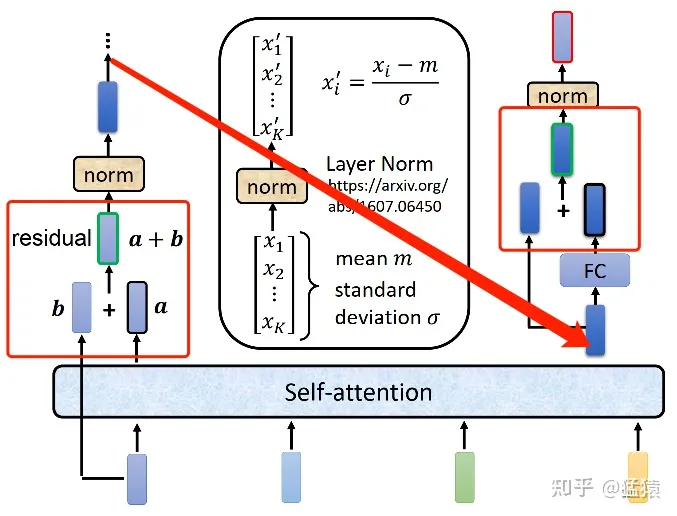
在Transformer中,数据过Attention层和FFN层后,都会经过一个Add & Norm处理。其中,Add为residule block(残差模块),数据在这里进行residule connection(残差连接)。残差连接的思想最经典的代表就是2015年被提出的ResNet,这个用于解决深层网络训练问题的模型最早被用于图像任务处理上,现在已经成为一种普适性的深度学习方法。
一、背景
1.1 梯度消失/爆炸
在深度学习网络中,为了让模型学到更多非线性的特征,在激活层往往使用例如sigmoid这样的激活函数。对sigmoid来说,其导数的取值范围在 (0, 1/4],在层数堆叠的情况下,更容易出现梯度消失的问题。
面对梯度消失/爆炸的情况,可以通过Normalization等方式解决,使得模型最终能够收敛。
1.2 网络退化(Degradation)
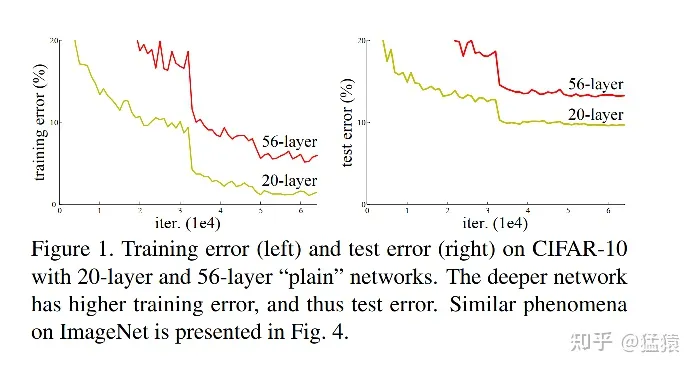
因为梯度消失/爆炸所导致的深层网络模型不收敛的问题,已经得到了解决。那么现在新的问题出现了:在模型能够收敛的情况下,网络越深,模型的准确率越低,同时,模型的准确率先达到饱和,此后迅速下降。这个情况我们称之为网络退化(Degradation)。如下图,56层网络在测试集(右)上的错误率比20层网络要更高,这个现象也不是因为overfitting所引起的,因为在训练集上,深层网络的表现依然更差。
二、思路
2.1 为什么需要更深的网络
神经网络帮我们避免了繁重的特征工程过程。借助神经网络中的非线形操作,可以帮助我们更好地拟合模型的特征。为了增加模型的表达能力,一种直觉的想法是,增加网络的深度,一来使得网络的每一层都尽量学到不同的模式,二来更好地利用网络的非线性拟合能力。
2.2 理想中的深网络表现
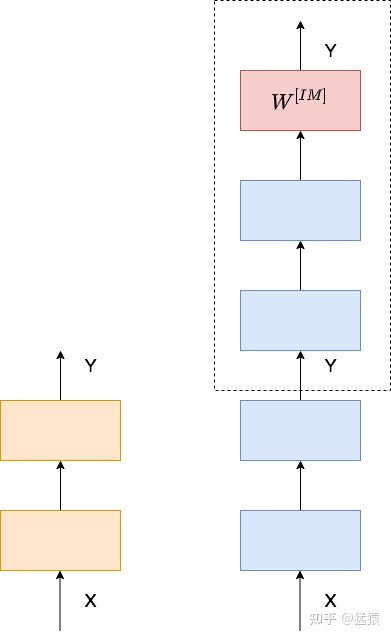
理想中的深网络,其表现不应该差于浅网络。举一个简单的例子,下图左边是2层的浅网络,右边是4层的深网络,我们只要令深网络的最后两层的输入输出相等,那么两个网络就是等效的,这种操作被称为恒等映射(Identity Mapping)。
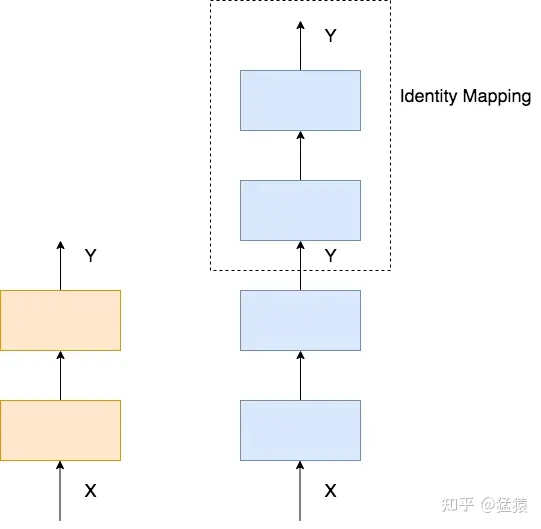
当然,这样完全相等的映射是一种极端情况,更为理想的情况是,在网络的深层,让网络尽量逼近这样的极端情况,使得网络在学到新东西的同时,其输出又能逼近输入,这样就能保证深网络的效果不会比浅网络更差。
总结:在网络的深层,需要学习一种恒等映射(Identity Mapping)。
三、实践和实验效果
3.1 构造恒等映射:残差学习(residule learning)
最暴力的构造恒等映射的方法,就是在相应网络部分的尾端增加一层学习层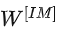 ,来满足输出和输入逼近。但是本来深网络要学的参数就很庞大了,再构造新的参数层,又增加了模型的复杂度。
,来满足输出和输入逼近。但是本来深网络要学的参数就很庞大了,再构造新的参数层,又增加了模型的复杂度。
能不能在不添加参数层的情况下,实现恒等映射的功能?考虑下图:

因此,ResNet就作为一种解决网络退化问题的有效办法出现了,借助ResNet,我们能够有效训练出更深的网络模型(可以超过1000层),使得深网络的表现不差于浅网络。
在深度神经网络中,当网络很深时,除了增加计算资源消耗以及模型过拟合问题外,还会出现梯度消失/爆炸问题,导致浅层网络参数无法更新。
而且深层的网络还有一个问题,假设我们的初始设定网络是M层,而其实最优化模型对应的层数可能是K层,那么多出来的(M-K)层网络结构,不仅不会提升模型的表达能力,反而使得模型的效果变差(表现为Loss先下降并趋于稳定值,然后再次上升。),这就产生了网络退化问题。
基于以上问题,CV领域里ResNet模型中的残差网络闪亮登场了。
3.2 残差网络
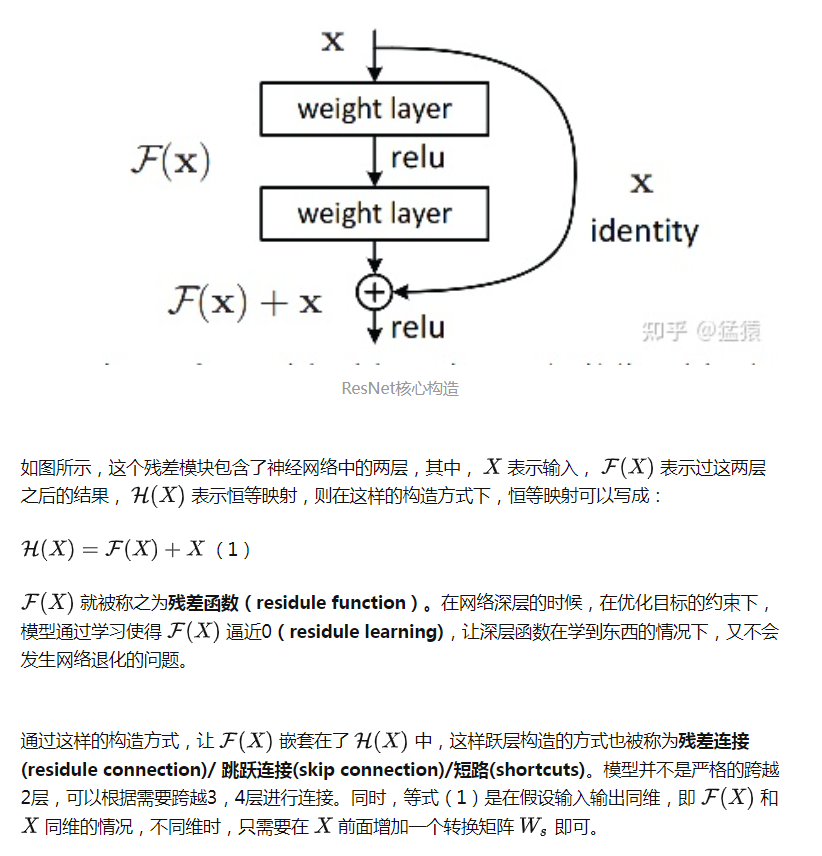
定义问题:统计学中的残差和误差是非常易混淆的两个概念。误差是衡量观测值和真实值之间的差距,残差是指预测值和观测值之间的差距。为什么叫残差网络呢?作者的解释是,网络的一层通常可以看做y=H(x),而残差网络的一个残差块为:H(x)=F(x)+x,则F(x) = H(x)-x,而y=x是观测值,H(x)是预测值,所以H(x)-x即为残差,也即F(x)是残差,故称残差网络。
深层网络在前向传播时,随着网络加深,网络获得的信息会逐层递减,而ResNet针对该问题的处理方式是“直接映射”,即下一层不仅包括该层的信息x,还包括该层经非线性变换后的新信息F(x)。这样的处理使得信息反而呈现逐层递增趋势。这可太好用了,可以不用担心信息的丢失问题了。
残差连接解决的问题
解决梯度消失和网络退化的问题。
四、Transformer中的残差连接
在transformer的encoder和decoder中,各用到了6层的attention模块,每一个attention模块又和一个FeedForward层(简称FFN)相接。对每一层的attention和FFN,都采用了一次残差连接,即把每一个位置的输入数据和输出数据相加,使得Transformer能够有效训练更深的网络。在残差连接过后,再采取Layer Nomalization的方式。具体的操作过程见下图,箭头表示画不下了,从左边转到右边去画:
【必知必会】残差连接
Transformer学习笔记四:ResNet(残差网络)