kafka
第一章、初识Kafka
原先:
kafka,由LinkedIn公司采用Scala语言开发的一个多分区,多副本,基于Zookeeper协调的分布式消息系统,被捐献给Apache基金会。
现在
分布式流式处理平台。
-
高吞吐
-
可持久化
-
可水平扩展
-
支持流数据处理
广度:Cloudera,Storm,Spark,Flink等都支持与Kafka集成。
Kafka 三大角色
消息系统
系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。
额外,还提供了,大多数消息系统难以实现的 消息顺序性保障及回溯消费的功能。
存储系统
消息持久化到系统。得益于消息持久化功能和多副本机制。
可以把Kafka作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或者启用主题的日志压缩功能即可。
流式处理平台
Kafka不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
1.1、基本概念
典型的Kafka体系,
-
Producer 生产者
-
Broker 转发(服务代理节点)
-
Consumer 消费者
-
ZooKeeper 集群(负责集群元数据的管理、控制器的选举等操作)
Topic 主题
Partion 分区(主题分区)
脑裂。
同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset是消息在分区中的唯一标识,kafka通过它来保证消息在分区内的顺序性。不过offset并不跨越分区,也就是说,kafka保证的是分区有序而不是主题有序。
一个主题可以多个分区,多个broker.
重点
每一条消息被发送到broker之前,会根据分区规则选择存储到哪个具体的分区,如果分区规则设定得合理,所有的消息都可以均匀地分配到不同的分区中。可以实现水平扩展。
多副本
Kafka为分区引入了多副本(Replica)机制.通过增加副本数量,提升容灾能力。
同一分区的不同副本中,保存的是相同的消息(同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群的某个broker失效时,仍然能保证服务可用。
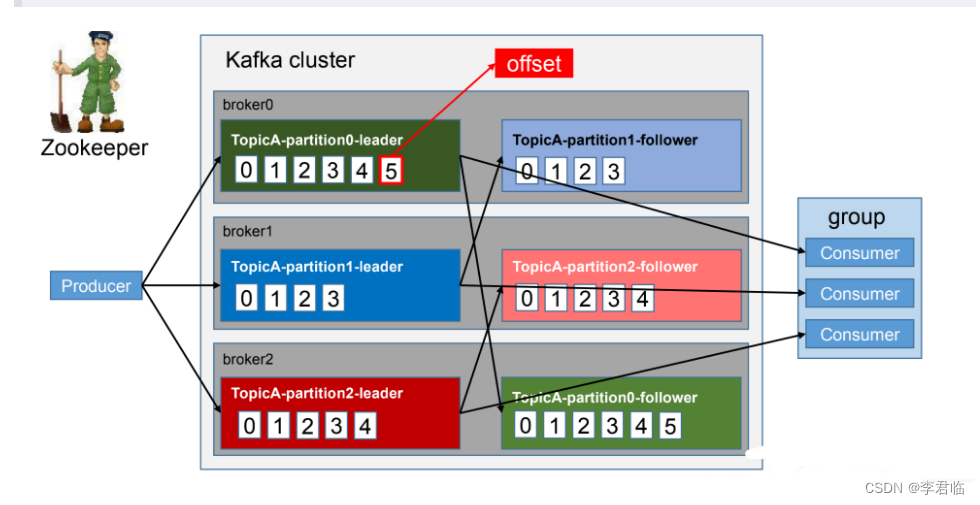
上面有3个broker,也就是3个服务器。
1个topic,有3个分区:partion0,partion1,partion2;
应该是3个副本因子。
副本
1、AR
AR
所有副本统称为AR(Assigned Replicas).
ISR
所有和leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Synv Replicas).
ISR集合是AR集合中的一个子集。
OSR
同步滞后过多的副本(不包括leader副本)组成OSR(out-of-Sync Replicas).
AR = ISR+OSR.
正常情况下,所有的follower副本都应该与leader副本保持一定程度的同步,即AR=ISR,OSR集合为空。
ISR就是老母鸡,后面跟着一群小母鸡。 看哪个小母鸡不行,就让他到第二梯队去OSR。
leader副本负责,维护和跟踪ISR集合中所有follower副本的滞后状态,当follower副本落后时太多或失效时,leader副本会把它从ISR集合中剔除。
如果OSR集合有follower副本“追上”了leader副本,那么leader副本(也会记录OSR吗)会把它从OSR集合转移至ISR集合。默认情况下,当leader副本发生故障,只有在ISR集合中的副本才有资格被选举为新的leader,而在OSR集合中的副本则没有任何机会(不过这个原则也可以通过修改相应的参数配置来改变)。
消息介绍
HW High Watermark 高水位
它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
LSO LogStartOffset
9条消息 LSO=0,最后一条消息的offset为8,那么leo为9
0-8消息,HW为6,那么消费者只能拉取到offset在0-5之间的消息,而offset为6的消息对消费者而言是不可见的。
LEO LogEndOffset
它标识当前日志文件中下一条待写入消息的offset。
LEO的大小,相当于当前日志分区中最后一条消息的offset值加1.
分区ISR集合中的每个副本都会维护自身的LEO,也就是最后一个需要加入的offset.
而ISR集合中,最小的LEO即为分区的HW,对消费者而言,只能消费HW之前的消息。 漏桶效应。
消息同步时,由HW控制所有同步的副本。
当HW=LEO,也就是同步完成,全部都可以消费了。
HW和LEO
Kafka的复制机制,不是完全的同步复制,也不是单纯的异步复制。
-
事实上,同步复制要求所有能工作的follwer副本都复制完,这条消息才会被确认为已成功提交,这种复制方式极大地影响了性能。(同步了一部分也能用!!)
-
异步复制,follower副本异步地从leader副本中复制数据,数据只要被leader副本写入就被认为已经成功提交。在这种情况下, 如果follower副本都还没有复制完而落后于leader副本,突然leader副本宕机,那么就会造成数据丢失。
kafka使用的这种ISR的方式则有效地权衡了数据可靠性和性能之间的关系。
安装和配置。
Zookeeper
Zookeeper
zookeeper是一个开源的 分布式协调服务,是Google Chubby的一个开源实现。
分布式应用程序,可以基于Zookeeper实现诸如
-
数据发布/订阅
-
负载均衡
-
命名服务
-
分布式协调/通知
-
集群管理
-
Master选举
-
配置维护等功能。
Zookeeper角色
-
leader
-
follower
-
observer(不参与投票)
windows安装kafka
Windows中安装和使用Kafka_windows安装kafka_时间不会赖着不走的博客-CSDN博客
一,打开Kafka官网进行下载Kafka
官网地址:Apache Kafka 我下载的是2.4.0版本
二、下载完毕之后进行解压
因为Kafka的运行依赖于 Zookeeper,所以还需要下并安装Zookeeper,ZooKeeper和Kafka版本之间有一定的对应关系,不同版本的ZooKeeper和Kafka可以相互兼容,但需要满足一定的条件。 Kafka 2.2.0 开始支持使用内置的ZooKeeper替代外部ZooKeeper。 所以2.4.0是不需要安装Zookeeper的,直接解压即可。
牛的。
三、启动Zookeeper
因为Kafka中的Broker注册,Topic注册,以及负载均衡都是在Zookeeper中管理,所以需要先启动内置的Zookeeper
打开之前下载的Kafka安装包,然后输入cmd
四、启动Kafka
新开一个命令行窗口,在之前的目录中输入启动命令
.\bin\windows\kafka-server-start.bat .\config\server.properties
五、测试kafka
在之前的目录中,新开一个命令行,进行创建名为“topic_test”的主题,其包含一个分区,只有一个副本
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic_test
kafka3
2023年 kafka3移除了zookeeper
Apache Kafka3.0不仅引入了各种新功能,API实现了突破性更改,同时还改进了KRaft——Apache Kafka的内置共识机制将取代 Apache ZooKeeper。
Apache Kafka
但是dev是实验特性,可以不用zk,但是prod还是推荐zk.
首先还是要先弄zk吧。
1、启动Zookeeper
因为Kafka中的Broker注册,Topic注册,以及负载均衡都是在Zookeeper中管理,所以需要先启动内置的Zookeeper
打开之前下载的Kafka安装包,然后输入cmd
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
先看zk的properties的配置
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # the directory where the snapshot is stored. dataDir=/tmp/zookeeper # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=0 # Disable the adminserver by default to avoid port conflicts. # Set the port to something non-conflicting if choosing to enable this admin.enableServer=false # admin.serverPort=8080
zk和zk的配置
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
kafka和kafka的配置
.\bin\windows\kafka-server-start.bat .\config\server.properties
默认 9092
启动kafka的配置
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic_test
报错。
在Kafka 2.3.0 版本之后的版本中,Kafka已经不再使用ZooKeeper作为默认的协调服务,而是使用内置的Kafka集群协调器(Kafka集群自身)。因此,您在使用kafka-topics.bat命令时,应该使用--bootstrap-server参数来指定Kafka集群的连接地址,而不是--zookeeper参数。以下是正确的命令示例: Copy D:\env\kafka\kafka_2.13-3.5.1>.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic_test 注意,我假设您的本地Kafka集群正在运行,并且监听在默认的9092端口上。如果您的Kafka集群配置有所不同,请相应地调整--bootstrap-server参数的值。 另外,您可能还需要确保已经正确设置了Kafka的环境变量,以便在任意位置执行kafka-topics.bat命令。如果仍然遇到问题,请检查您的Kafka安装和配置是否正确,并参考Kafka的官方文档进行故障排除。
修改为
.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:2181 --replication-factor 1 --partitions 1 --topic topic-test
创建一个生产者来产生数据
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic topic_test >aa
创建一个消费者来接收数据
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic topic_test --from-beginning