这不是你期望的介绍深度学习大模型的文章。而是使用人人都能理解、编程、运行的简单技术(包括机器学习和非机器学习技术),通过一系列工程进行整合、组装,从而实现一个 AI 虚拟主播的故事。
muvtuber
让 AI 成为虚拟主播:看懂弹幕,妙语连珠,悲欢形于色,以一种简单的实现
元宇宙终于不再铺天盖地,ChatGPT 又来遮天蔽日。看不下去了,那当然是选择——加入这虚浮的演出,诶嘿~(误)
想法
蹭热度的想法是这样:元宇宙 => 皮套人,ChatGPT => 中之人,放到一起:AI 主播!
咳,实际上没那么假大空啦。真实的故事是这样:
既然我可以让 AI 看懂你的心情,并推荐应景的音乐,以一种简单的实现,那么,我还想再进一步!让 AI 站到唱机背后,聆听你的故事,为你播出此时此刻萦绕心中、却难以言表的那段旋律。曲终意犹未尽当时 ,一段 AI 细语入耳更入心 —— 机器不是冰冷的玩具,她比你更懂你,至少她更懂那个真实的你:她不会说谎,而你每天都在骗自己。
这个想法指向的产品是一个 AI 电台,我把它叫做 muradio。在细化设计的过程中,我不得不考虑电台的传播问题。我当然可以在本地完成一切,让 AI 电台只为你一人播,这样实现起来还简单;但是,电台果然还是要大家一起分享吧。所以,我考虑用一种现代的方式——视频直播。
那么,在实现 muradio 之前,先让 AI 学会直播吧!
设计
我把这个 AI 主播叫做 muvtuber 1。
人是如何做的
要设计一个直播的机器,其实很简单。首先考察人是如何完成直播的:
- 首先需要一个人作为主播:这个人是会动会说话的,心情是会写在脸上的;(只是以普遍理性而论,非必要条件,更非歧视残障人士。)
- 在开始前有一个预订的主题,也可能没有;
- 主线:推进主题:打游戏、一起看、点歌 …;
- 支线:主线被弹幕打断,转而与观众互动:聊天;
- 最后,需要一个直播推流工具,比如 OBS。
互动是直播的灵魂。直播没有主题仍是直播,而没有了互动就成了电视。简单起见,我们先忽略主题问题,只考虑注入灵魂的互动实现。互动的过程如下:
- 观察:看到弹幕
- 过滤:选择性忽略一些没有意义或太有意义的话
- 思考:对过滤后留下来的话进行思考 => 回应的话
- 过滤:想到的部分话可能是不适合说出的,也要过滤掉
- 发声:把回应说出来
- 动作与表情:伴随观察、思考、表达这个流程的动作控制、表情管理。
用机器模拟人
清楚了直播的处理过程,就容易用机器模拟:
- 主播:我们可以用 Live2D 模型来作为主播本人。
- 看弹幕:使用弹幕姬类程序,暴露接口即可:
func danmaku(room) chan text - 思考:机器文本生成:
func chat(question) answer - 发声:机器语音合成:
func tts(text) audio - 过滤:
func filter(text) bool - 动作表情:Live2D 模型可以具有动作、表情,可以通过某种方式驱动。
Live2D 和弹幕姬是现成的解决方案,而从看弹幕、到思考、到发声的整个流程也是非常模块化、函数式的,直观清晰。难点是如何让 Live2D 模型动起来?
模型何时该摆什么样的表情,何时该做什么样的动作?真人主播解决这个问题靠得是本能,虚拟主播解决这个问题靠得是动捕——归根到底还是人。看来现实不能直接借鉴,那么只好做个抽象了。
我认为,表情是心情的反映,动作是表达的延伸。淦我写不清关于心情 => 表达 => 动作,所以 动作 = f(心情) 的观点😭

(怎么会有人问 ChatGPT “我要如何解释我的观点?”😭)
所以说,我们可以用“心情”来驱动 Live2D,赋予 AI 主播表情与动作。
那么,我们又如何让机器拥有“心情”呢?事实上,在前文提到的 让 AI 看懂你的心情,并推荐应景的音乐,以一种简单的实现 一文的“中文文本情感分析”小节中,我们用一种及其简单的方式,实现了一种 文本 -> 心情 的模型。这里我们就沿用当时的成果,不作额外介绍了,新读者可以先去阅读那篇文章的对应部分。
总之,我们可以用“思考”的输出,即主播要说的话,通过文本情感分析技术,反推出主播的心情,然后根据心情,就可以控制 Live2D 模型做出合适的表情、动作。
整体设计
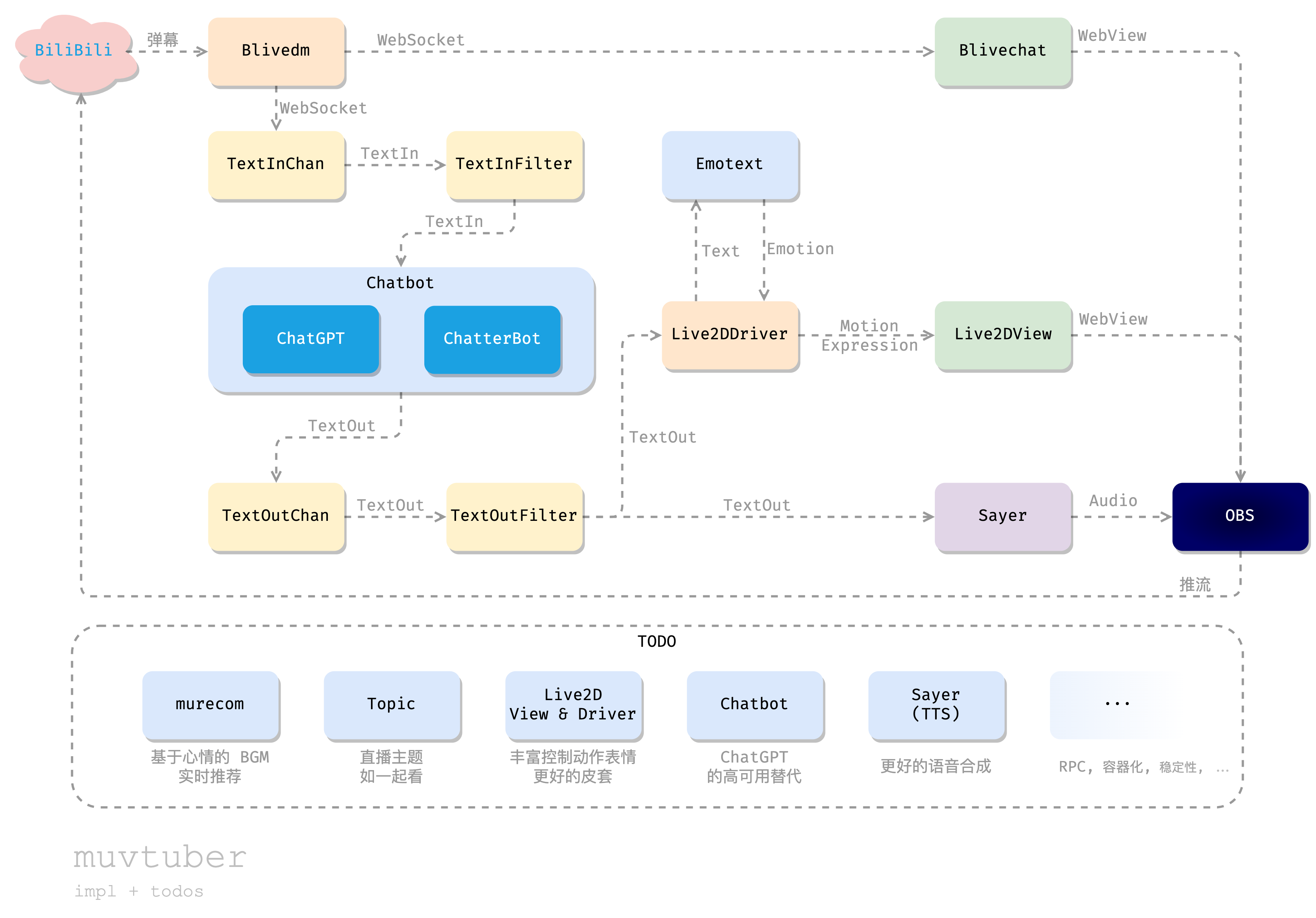
小结一下上述设计,我们用机器来模拟人类主播,完成与观众的闲聊交互,整个过程如下图所示:
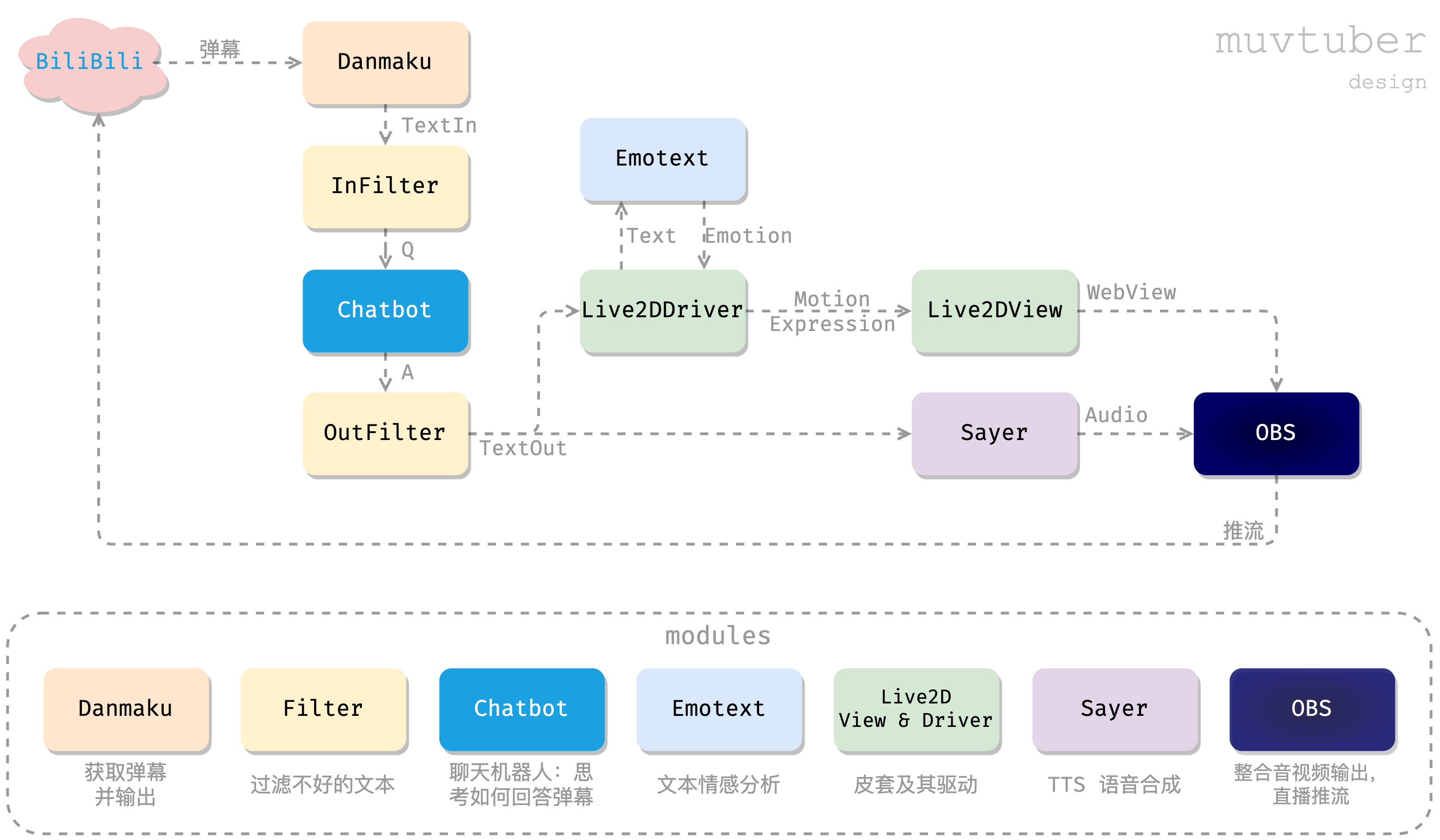
我们把 muvtuber 分成了一个个独立的模块。每个模块使用独立的技术栈,实现自己的工作,并通过某种方式暴露 API,供他人调用。最后,我们会通过一个“驱动程序”muvtuberdriver 来调用各个模块,通过一个顺序流程,实现上图所示的数据流动。
组件实现
本节介绍对上述 muvtuber 设计方案的实现。我会先写各个独立组件,再写如何把他们组装到一起完成工作。喜欢“自顶向下”的读者请自行安排阅读顺序。
这是一个拥有众多组件的项目,装起 numpy 从头撸似乎不够明智。我们会心怀感激地借助一些开源项目。我希望提供一种最简单的实现——面向麻(my)瓜(self)编程——只写必要的、能理解的代码。
先修课程:这是个 Web 前端 + 后端 + 机器学习的综合项目,需要使用到 Vue(TypeScript)、Go、Python 等相关语言和技术。
文短码长,下文只给出必要的设计、核心的代码,忽略错误处理、并发安全等等工程中实际的问题。真实的代码实现,请读者参考源码:
| 服务 | 说明 |
|---|---|
| xfgryujk/blivechat | 获取直播间弹幕消息 |
| Live2dView | 前端:显示 Live2D 模型 |
| Live2dDriver | 驱动前端 Live2D 模型动作表情 |
| ChatGPTChatbot | 基于 ChatGPT 的优质聊天机器人 |
| MusharingChatbot | 基于 ChatterBot 的简单聊天机 |
| Emotext | 中文文本情感分析 |
| muvtuberdriver | 组装各模块,驱动整个流程 |
弹幕姬
技术栈:Node,Python。
为了和其他模块对接,我们需要那种能通过比较底层的方式输出弹幕的工具。我们要给机器看的,而不是一个给人看的黑箱的图形界面。
好在也不必自己从头写。xfgryujk/blivedm 就是这样的一个工具。作者大大还顺别提供了显示给人看的界面 blivechat。
这里我们直接使用封装好的 blivechat。这个东西后端通过 WebSocket 把弹幕、礼物等消息发送给前端的界面。拉取、编译、运行 blivechat(blivechat 的 README 里有详细的安装、使用方法,此处从简。):
# clone repo
git clone --recursive https://github.com/xfgryujk/blivechat.git
cd blivechat# 编译前端
cd frontend
npm install
npm run build
cd ..# 运行服务
pip3 install -r requirements.txt
python3 main.py
虽然没有文档,但稍微抓包,就可以模仿出一个前端,通过 WebSocket 接口获取到弹幕:
// 建立链接
let ws = new WebSocket('ws://localhost:12450/api/chat');// 订阅直播间
ws.send(JSON.stringify({"cmd": 1,"data": { "roomId": 000 }
}));// 接收弹幕消息
ws.onmessage = (e) => {console.log(JSON.parse(e.data))
};// KeepAlive:每 10 秒发一次 heartbeat
setInterval(() => {ws.send(`{"cmd":0,"data":{}}`)
}, 1000 * 10);
除此之外,我们还可以使用它自带的图形界面(有没有一种可能,这才是这个项目的正确用法),这个弹幕框可以由 OBS 采集输出到直播间里:
优质聊天机器人:ChatGPT
技术栈:Python
这应该是最有意思的部分,却也是最难的。幸好,有 ChatGPT。
acheong08/ChatGPT 项目提供了一个很好的 ChatGPT 接口。
安装:
pip3 install revChatGPT
使用:
from revChatGPT.V1 import Chatbotchatbot = Chatbot(config={"access_token": "浏览器访问https://chat.openai.com/api/auth/session获取"
})prompt = "你好"
response = ""for data in chatbot.ask(prompt):response = data["message"]print(response)
我们只要编写一条合适的 prompt,即可让 ChatGPT 化身“虚拟主播”,例如:
请使用女性化的、口语化的、抒情的、感性的、可爱的、调皮的、幽默的、害羞的、态度傲娇的语言风格,扮演一个正在直播的 vtuber,之后我的输入均为用户评论,请用简短的一句话回答它们吧。
大概是这种效果:

我并不擅长写 prompt,上面这段也改编自网络(原版大概是让做猫娘的),如果你有更好的 prompt,欢迎与我分享。
注:prompt 笑话一则:
嘿,知道吗?以后不需要程序员啦!只要描述出需求,ChatGPT 就能写出代码!
——太棒了,那么如何写出简洁清晰无歧义的需求描述呢?
呃,未来或许会有那么一种语言…
——你说的可能是:计算机程序设计语言 😃
我们把这个东西简单封装出一个 HTTP API,方便其他组件调用:
$ curl -X POST localhost:9006/renew -d '{"access_token": "eyJhb***99A"}' -i
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Content-Length: 2ok
$ curl -X POST localhost:9006/ask -d '{"prompt": "你好"}'
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Content-Length: 45你好!有什么我可以帮助你的吗?
基本聊天机器人:ChatterBot
技术栈:Python
ChatGPT 很好用,输出质量非常高,但是:
- 这不是一个开源的组件,或者廉价的公共服务。不能保证始终可用,也不能确定用它直播是否符合规则。
- OpenAI 有访问限制:请求太频繁会拒绝服务。在实践中 30 秒/次会触发,60 秒/次 才比较安全。
总之,ChatGPT 硬用下去也不是个办法。我们可以实现一个丐版聊天机器人作为补充。在 ChatGPT 由于网络、限制等原因无法访问时,也提供一点点对话能力。
在很多年前,我曾用过一个开箱即用的傻瓜式聊天机器人库:ChatterBot。训练、推理都非常简单,调用者无需任何机器学习知识:
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainerchatbot = ChatBot('Charlie')# 训练
trainer = ListTrainer(chatbot)
trainer.train(["Hi, can I help you?","Sure, I'd like to book a flight to Iceland.","Your flight has been booked."
])# 推理:对话
response = chatbot.get_response('I would like to book a flight.')
print(response)
可以用列表传入对话进行训练。训练完后,调用 get_response 方法即可进行对话。同样简单封装成 HTTP API:
curl 'http://localhost:9007/chatbot/get_response?chat=文本内容'
它的对话效果非常差。但有趣的是,这个库可以在线学习。在你和他对话的过程中,它会持续学习。在测试时,我给它接上 blivechat,随便进一个直播间,让它旁听,和弹幕虚空交流。经过一上午它已经学会了包括但不限于“妙啊”“有点东西”“对对对”等直播弹幕常(抽)用(象)表达,可以在恰当语境下输出作为回应。(这样让它黑听学习也有弊端,它会顺别学到许多“别的女人”,然后满嘴 Lulu、白菜、社长什么什么的😂)
不能指望这个库做出 ChatGPT 那样的优质、有逻辑的回答。只把它作为兜底,让它快速跟着弹幕瞎附合嚷嚷还是不错的,别冷场就好。
我在直播实测中的对比:
- ChatGPTChatbot:由 ChatGPT 生成的回答
- MusharingChatbot:本节介绍的 Chatterbot 库(我最初在一个叫做 musharing 的项目中使用了这个库,故此命名)

注意:ChatterBot 库早已年久失修。但可以找到一些可以用的 fork,例如 RaSan147/ChatterBot_update(from issues #2287):
pip install https://github.com/RaSan147/ChatterBot_update/archive/refs/heads/master.zip # 直接从 GitHub 而非 PyPI 仓库安装
python -m spacy download en_core_web_sm # 一个执行不到的依赖,但是不装跑不起来。
语音合成
技术栈:macOS,Go
用 Chatbot 生成了回应观众的文本,(暂时忽略过滤),接下来就要送到 TTS 语音合成模块,让机器把话说出来。
这个要效果好似乎必须上深度学习,PaddleSpeech 似乎是一个不错的选择,不过 i5-8700U + 核显大概跑不动就是了。
可以考虑用一点云服务:
- Microsoft Speech Studio:要注意网络问题
- 百度 AI 开方平台 - 短文本在线合成:要注意钱包问题
选择心仪的服务照着文档写就好了,非常容易。但这还是有点麻烦了,如果你使用 macOS,事情还可以更简单:
SAY(1) 命令使用 macOS 的 Speech Synthesis Manager 将输入文本转换为可听语音,并通过在“系统偏好设置”中选择的声音输出设备播放它,或将其存储到 AIFF 文件中。
你可以通过man say查看这个命令的详细用法。
打开扬声器或者耳机,调节音量;打开终端,键入命令:
say '你好,这是系统自带的 TTS 语音合成。'
不出意外,你会听到 Siri 或者婷婷声情并茂地大声朗读。
如果你对听到的声音不胜满意,(例如系统默认配置的似乎是低配婷婷,只能听个响),可以到「系统设置 > 辅助功能 > 朗读内容 > 系统声音」按照个人喜好修改(个人觉得简体中文系女声,讲的最好的就是「Siri 2」)。

容易在任何主流语言中调用这个工具,例如我们之后会在 Go 语言中调用它:
package mainimport "os/exec"type Sayer interface {Say(text string) error
}// sayer is a caller to the SAY(1) command on macOS.
type sayer struct {voice string // voice to be usedrate string // words per minuteaudioDevice string // audio device to be used to play the audio
}func (s *sayer) Say(text string) error {// say -v voice -r rate -a audioDevice textreturn exec.Command("say","-v", s.voice, "-r", s.rate, "-a", s.audioDevice,text,).Run()
}
文本情感分析
技术栈:Python
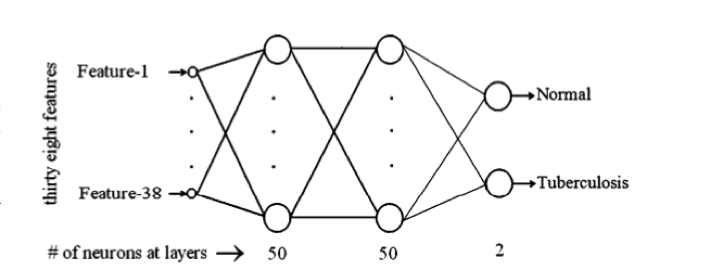
在 murecom 项目中,我们实现了一个名为 Emotext 的中文文本情感分析模块。它的作用就是输入文本,输出其中蕴含的情感(Emotext = func (text) -> emotions):
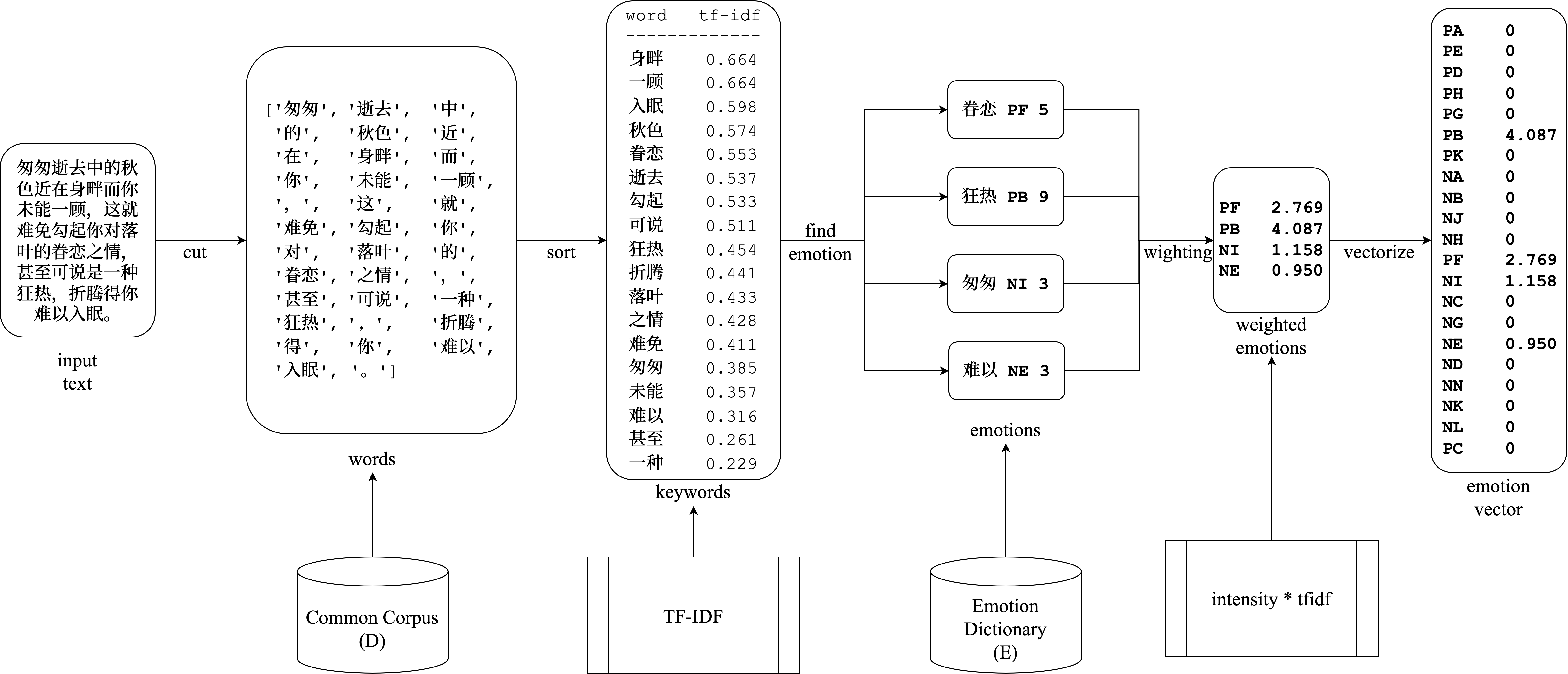
关于这个东西的原理即实现详见让 AI 看懂你的心情,并推荐应景的音乐,以一种简单的实现 一文(说人话的介绍)。下面仅给出核心算法(不说人话的介绍)(某蒟蒻的毕业论文,我先喷:学术辣鸡):

其中词典 E E E 使用大连理工情感本体库 2。大连理工情感本体库是较为成熟的一套中文情感词典方案,提供了对数万中文词汇的情感分类及强度分析,在中文文本情感分析领域被广泛使用。该库的情感划分方案 与 表 3-1 保持一致。该库的情感强度表示为 1 ∼ 9 的数值,数值越大,认为对应情感越强烈。
定义整段输入文本的总情感为所有关键词情感强度的 tfidf 加权总和:
e ( d ) = ∑ t ∈ k e y w o r d s t f i d f ( t , d , D ) ⋅ I t e(d) = \sum_{t \in keywords} tfidf(t,d,D)\cdot I_t e(d)=t∈keywords∑tfidf(t,d,D)⋅It
在有必要的情况下,还可以对 e ( d ) e(d) e(d) 进行 softmax 计算,得到文本在各情感类别上的概率分布。
总之,这东西就是一个很简单的算法,抛开效果不谈(该算法仅作为非深度学习的 baseline),人人都能写、人人都能理解。
此处复用当时的代码,只做简单的 API 重新封装,开放如下 HTTP 接口:
$ curl -X POST localhost:9008/ --data '高兴'
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 149{"emotions": ..., "polarity": ...}
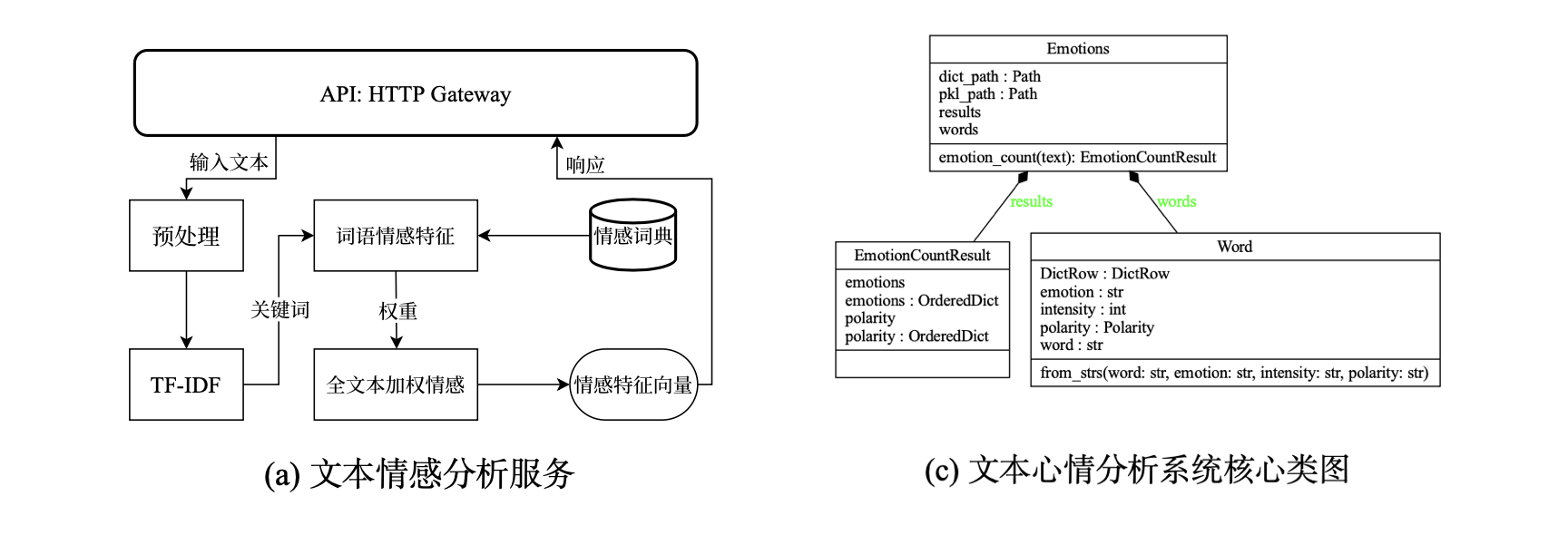
实现的工作示意图和核心类图如下:
Live2D View
技术栈:TypeScriptVue.js,Quasar,Pinia,WebSocket
我从未设想过,所有组件中最麻烦的居然是 Live2D 这个看似除编外人员 OBS 之外最成熟的东西。
因为我们的需求有一点刁钻。正常的 Live2D 使用方式是:
- 把模型作为皮套,通过面/动捕进行驱动。但我们是机器作为中之人,机器没头没脸、没法自己动。所以一些封装的很好的、大家都在用的直播皮套 app 不能用。
- 网站上的看板娘,把 Live2D 模型加载到网页上,并全自动地吸引你的目光(而她的目光却被你的鼠标吸引😖),同时响应你对她的点(抚)击(摸)等动作。这个东西为了对使用者友好,一般封装地非常严实,基本不暴露什么接口,所有我们也不能直接拿来用。
我们要找那种暴露了底层一点的接口,能通过程序调用控制的方案。事实上,我发现常用的 Live2DViewerEX 就提供了非常好的 ExAPI 功能。但考虑到它的接口还是不够丰富,并且该 app 也不是开源实现,所以,我决定自己写。(绝对不是心疼那 $4.99,只是恰好缺那 $4.99罢了)
Live2D 官方 提供有各种 SDK。例如 Web、Unity 等等。出于能耗考虑,决定使用 Web 平台。但是打开文档,不太能看懂,搞了好久 Demo 都没跑起来。好在我找到了一个对官方 SDK 的封装:
- guansss/pixi-live2d-display: A PixiJS plugin to display Live2D models of any kind.
这个库提供了简单清晰的接口,可以导入、显示模型,并控制表情、动作。
import * as PIXI from 'pixi.js';
import { Live2DModel } from 'pixi-live2d-display';
window.PIXI = PIXI;// 模型文件
const cubism2Model ="https://cdn.jsdelivr.net/gh/guansss/pixi-live2d-display/test/assets/shizuku/shizuku.model.json";// 初始化 view
const app = new PIXI.Application({view: document.getElementById('canvas'),
});// 读取模型
const model = await Live2DModel.from(cubism2Model);// 显示模型
app.stage.addChild(model);// 设置动作、表情
model.motion('tap_body');
model.expression('smile');
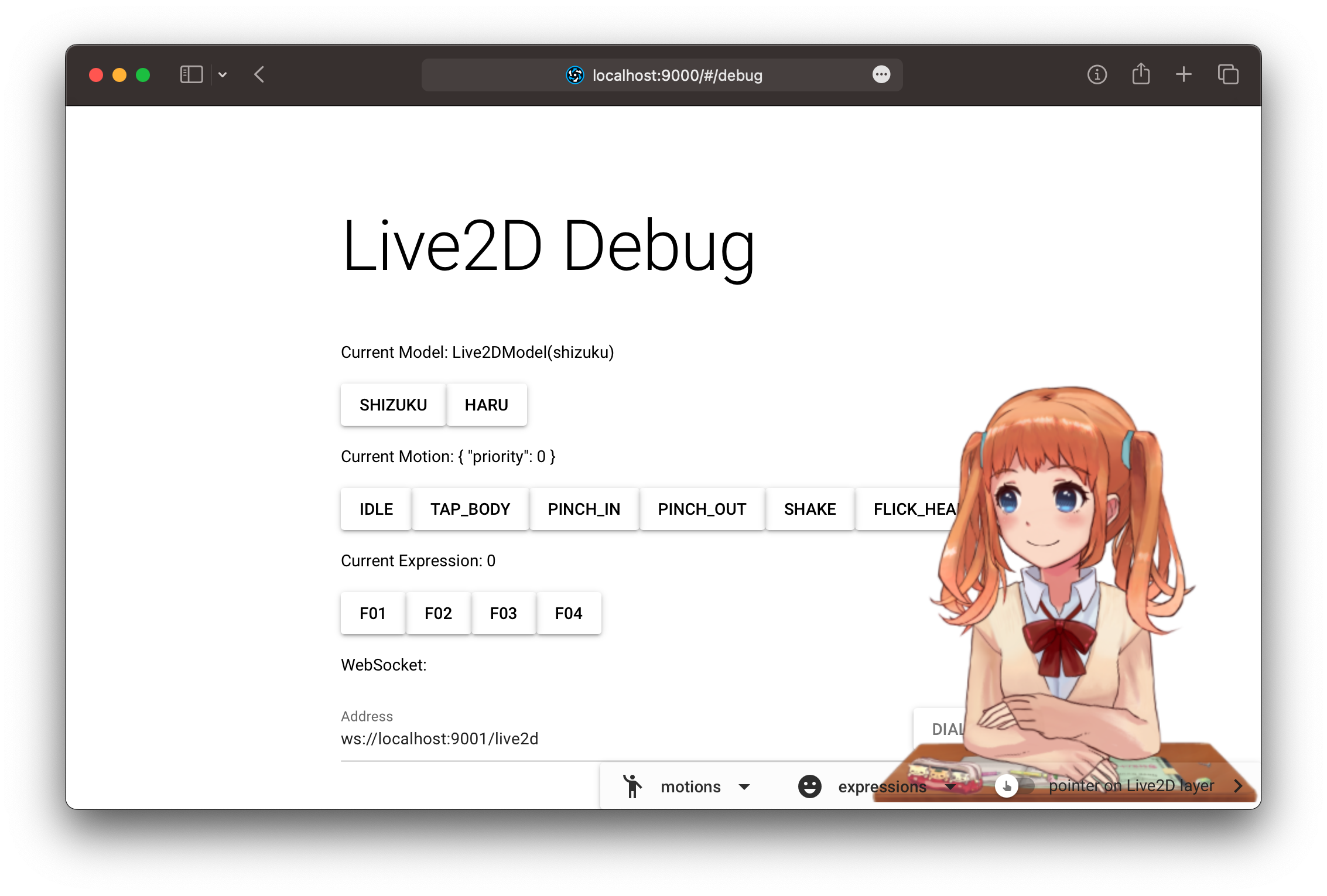
用 Vue 把上面的 Demo 封装成为 component,名曰 Live2DView。辅以一个 Live2DStore,用于控制 View 中 Live2D 的动作和表情。一个通用的、可复用的 Live2D 组件就完成了:
<template><Live2DView />
</template><script setup lang="ts">
import Live2DView from './Live2DView.vue';import { useLive2DStore } from 'stores/live2D-store';
const live2DStore = useLive2DStore();// 通过 store 控制 view 中的 Live2D 皮套
live2DStore.setMotion({ group: 'tap_body' })
live2DStore.setExpression('smile')
</script>
运行一下(背后的调试功能只是简单地暴露 store 的 actions,文中不作介绍):
再写一个 WsStore,用来接收来自 WebSocket 的命令,进而调用 Live2DStore,完成响应的动作、表情控制:
import { defineStore } from 'pinia';
import { computed, ref } from 'vue';
import { useLive2DStore } from './live2D-store';export const DEFAULT_WS_ADDR = 'ws://localhost:9001/live2d';const live2DStore = useLive2DStore();export const useWsStore = defineStore('ws', () => {const ws = ref<WebSocket>();function dialWebSocket(address: string = DEFAULT_WS_ADDR) {ws.value = new WebSocket(address);ws.value.onmessage = (event: MessageEvent) => {let data = JSON.parse(event.data);if (data.model) { // 更换模型live2DStore.setModel(data.model);}if (data.motion) { // 设置动作live2DStore.setMotion(data.motion);}if (data.expression) { // 设置表情live2DStore.setExpression(data.expression);}};}return { dialWebSocket, };
});
这样,我们就可以通过 WebSocket,发送 JSON 命令,从其他程序来控制她了:
{"model": "https://path/to/model.json","motion": "tap_body","expression": "smile"
}
这个用来控制她的程序是 live2ddriver——
Live2D Driver
技术栈:Go,HTTP,WebSocket
live2ddriver 要做的是:接收来自 Chatbot 输出的文本;调用 Emotext 进行情感分析;并根据得到的“心情”,驱动 Live2D View,使做出对应的表情、动作。
- 输入:文本,Vtuber 要说的话。
- 接收自 HTTP 请求。
- 输出:JOSN,符合输入文本情感的表情、动作。
- 发送到 WebSocket。
这个程序非常简单,不过多介绍,只给出关键代码(已去掉烦人的日志打印、错误处理和并发安全)。
访问 Emotext:进行文本情感分析:
var EmotextServer = "http://localhost:9008/"
var client = &http.Client{}func Query(text string) (EmotionResult, error) {body := strings.NewReader(text)resp, _ := client.Post(EmotextServer, "text/plain", body)defer resp.Body.Close()var result EmotionResultjson.NewDecoder(resp.Body).Decode(&result)return result, nil
}
驱动 Live2D 模型:文本 -> 驱动指令:
type Live2DDriver interface {Drive(textIn string) Live2DRequest
}// DriveLive2DHTTP get text from request body.
// A Live2DRequest will be generated by the driver and sent to chOut
func DriveLive2DHTTP(driver Live2DDriver, addr string) (chOut chan []byte) {chOut = make(chan []byte, BufferSize)go func() {router := gin.Default()router.POST("/driver", func(c *gin.Context) {body := c.Request.Bodydefer body.Close()text, _ := ioutil.ReadAll(body)// 调用 driver 计算该做何中动作res := driver.Drive(string(text))j, _ := json.Marshal(res)chOut <- j})router.Run(addr)}()return chOut
}
我们需要针对每个模型写对应的 Driver 具体实现(情感的转移实际上使用了一个一阶马尔可夫过程,这里简化了):
type shizukuDriver struct {currentExpression shizukuExpressioncurrentMotion shizukuMotionemotions emotext.Emotions // emotion => motionpolarity emotext.Polarity // polarity => expression
}func (d *shizukuDriver) Drive(textIn string) Live2DRequest {// 请求 EmotextemoResult, err := emotext.Query(text)d.emotions, d.polarity = emoResult.Emotions, emoResult.Polarity// 找得分最大的情感maxEmotion, maxPolarity := keyOfMaxValue(d.emotion), keyOfMaxValue(d.polarity)// 构造驱动命令var req Live2DRequestif d.currentExpression != maxPolarity {d.currentExpression = maxPolarityreq.Expression = d.currentExpression}if d.currentMotion != maxEmotion {d.currentMotion = maxEmotionreq.Motion = d.currentMotion}return req
}
WebSocket 消息转发器:把消息通过 WebSocket 发给前端,就是简单的开几个 goruntine 用 chan 来传数据:
// messageForwarder forwards messages to connected clients, that are, Live2DViews.
type messageForwarder struct {msgChans []chan []byte
}func (f *messageForwarder) ForwardMessageTo(ws *websocket.Conn) {ch := make(chan []byte, BufferSize)// addf.msgChans = append(f.msgChans, ch)// forwardfor msg := range ch {ws.Write(msg)}
}func (f *messageForwarder) ForwardMessageFrom(msgCh <-chan []byte) {for msg := range msgCh {// sendfor _, ch := range f.msgChans {ch <- msg}}
}
main:
// WebSocket 转发器:把东西发到 WebSocket 中
forwarder := wsforwarder.NewMessageForwarder()// 监听 :9004,获取来自 Chatbot 的 text
// 分析情感,生成驱动指令,发给 WebSocket 转发器。
go func() {driver := live2ddriver.NewShizukuDriver()dh := live2ddriver.DriveLive2DHTTP(driver, ":9004")forwarder.ForwardMessageFrom(dh)
}()// WebSocket 服务:转发 Live2D 驱动指令到前端
http.Handle("/live2d", websocket.Handler(func(c *websocket.Conn) {forwarder.ForwardMessageTo(c)
}))
http.ListenAndServe(":9001", nil)
组件小结
| 端口 | 服务 | 说明 |
|---|---|---|
| 12450 | Blivechat | 获取直播间弹幕消息 |
| 9000 | Live2dView | 前端:显示 Live2D 模型 |
| 9001 | Live2dDriver::ws | 发动作表情给前端的 WebSocket 服务 |
| 9004 | Live2dDriver::driver | 发文本给 live2ddriver 以驱动模型动作表情 |
| 9006 | ChatGPTChatbot | 优质聊天机器人 |
| 9007 | MusharingChatbot | 基于 ChatterBot 的简单聊天机 |
| 9008 | Emotext | 中文文本情感分析 |
| - | Say | 文本语音合成:系统自带命令 |
总装,开播!
技术栈:Go
好了,把前面实现的具体组件放到最开始的设计图中:
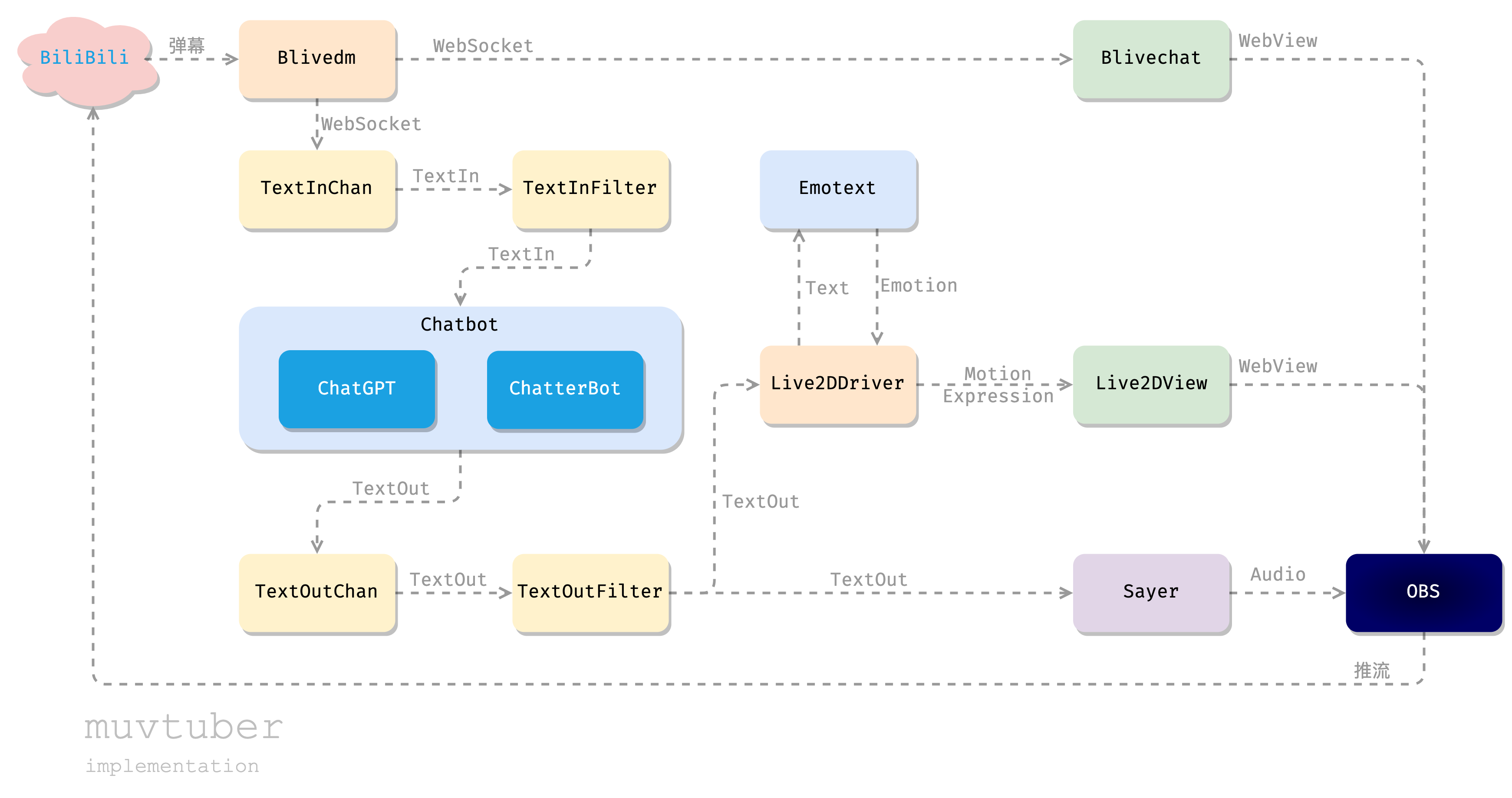
我们通过 blivechat,从 B 站的直播间获取弹幕消息;传递给 ChatGPT 或者备用的 ChatterBot 获取对话的回应;然后一方面把回应文本朗读出来,另一方面把回应文本传给 Live2DDriver,用 Emotext 进行情感分析,然后视话中情感,向 Live2DView 发出 WebSocket 命令;前端的 Live2DView 接收到命令后,更新页面显示的模型动作表情。最后把弹幕框、Live2D以及 Sayer 朗读出的音频通过 OBS 采集,放到一个画面里,向 B 站直播间推流。这样一个简单的 AI 直播流程就实现了!同时为了保证直播质量,我们可能还需要过滤掉一些意义不明的弹幕,以及过于大胆的发言,这可以通过额外的 Filter 组件实现(本文不作介绍)。
最后的任务:把上面这段话,或者或上面那张图翻译成实际的代码。我们借助 Go 语言完成这个工作。
第一步,就是对上一节介绍的各个服务分别编写出客户端,这个非常容易,就是一些参数编码、http 请求、解析响应、错误处理这样繁琐但简单的调 API 的标准工作,大(GitHub)家(Copilot)都可以轻松完成。
第二步,也是最后一步,一个 main 函数,串起其所有组件,也就是完成设计图中的那些连线:
func main() { textInChan := make(chan *TextIn, BufSize)textOutChan := make(chan *TextOut, BufSize)// (blivedm) -> ingo TextInFromDm(*roomid, textInChan)// in -> filter (目前没有) -> intextInFiltered := textInChan// in -> chatbot -> outchatbot := NewPrioritizedChatbot(map[Priority]Chatbot{PriorityLow: NewMusharingChatbot(),PriorityHigh: NewChatGPTChatbot(),})go TextOutFromChatbot(chatbot, textInFiltered, textOutChan)// out -> filter (目前没有) -> outtextOutFiltered := textOutChan// out -> (live2d) & (say) & (stdout)live2d := NewLive2DDriver()sayer := NewSayer()for textOut := range textOutFiltered {live2d.TextOutToLive2DDriver(textOut)sayer.Say(textOut.Content)fmt.Println(textOut)}
}
归功于 Go 语言的 goruntine 和 chan,一切都非常直观。
最后一步,启动程序,打开 OBS,把输出的音视频采集进去:
- 弹幕框:
localhost:12450/... - Live2DView:
localhost:9000 - 音频(say)的输出:你使用的音频设备
在 B 站开始直播,OBS 推流,完成!
(详细的 OBS 使用方法以及如何在 B 站开启直播,大家可以在 B 站搜索相关视频学习,此处不作介绍。)
想看看她直播的效果?这个项目不是什么复杂的深度学习大模型,不需要任何特殊的硬/软件,一般配置的 Mac + Git + Python + Poetry + Node + Pnpm + Go + OBS 即可搭起全套环境,轻松复现。(我也会尽快实现容器化,届时便可直接一键运行。)
总结
大家可能很失望,本文没有去训练某种奇幻的深度学习模型,从而实现一切。这只是因为我不会。
我始终认为,计算机程序就应该是这样的。“Keep it simple, stupid!”。麻瓜模块的快速组合,而不是端到端的数学大魔法。强类型数据流、活动和状态,而不是高维浮点张量乘。。。又扯远了。
是这样的,我希望分享的是一个“从想法到 app”的过程。我如何想到一个点子,又如何把它变成可以程序化的需求,或者说把它变成可行的计算:我要的 = f(现有的),明确输入(弹幕)、输出(直播)和限制(我的机器跑的动)。然后,我又如何设计这个 f,把它拆分成一个个相对独立的小模块,每个模块完成一件事情,用最简单的代码去实现他们。最后我又如何把这些模块拼在一起,让他们协同工作,实现一个有趣的大程序(AI 虚拟主播)。
总之,这个项目实现了一个灵活的框架,你可以任意替换其中的组件,从而不断提升这个 AI 主播的业务能力。请容我再次放出整体的设计图,并在下面添加一些我觉得有意思的 TODO:
满打满算我只用了一周时间设(摸)计(鱼)、一周时间编码来实现了这个项目。所以她是非常粗糙的。换句话说,她有非常大的改进空间。例如我现在已经开始将其中的部分手写的 HTTP 通信迁移到 gRPC,用更少的代码,带来更强的性能、更完善的错误处理。
我把这个项目当作自己的“学期(课外)学习计划”来不断优化:希望在功能上实现上图的各种 todo 的同时,也在实现上不断重构,从现在的幼稚模式,逐步用上 RPC、容器编排、函数计算、devOps 等等现代云原生的方式。
最终这个项目或许会变得非常棒。如果有所进展,我会在下一篇文章“muvtuber:进化!从散装微服务到云原生”中介绍,请大家监督。
我不是一个老练的程序员,我写不出好的设计模式、刷不懂 Leetcode,我只有不断冒出的想法,和越来越长的 todo list。我的备忘录里躺满了 app 等待实现,但说到的总是做不到,美妙的想法都等到了发霉。可也只能一行一行慢慢写,just for fun。我用十年写了满屏烂代码,就算越来越迷茫,也就只好这样继续吧……
最后再次给出全部源码链接,望读者垂阅斧正:
| 服务 | 说明 | 基于 |
|---|---|---|
| xfgryujk/blivechat | 获取直播间弹幕消息 | - |
| Live2dView | 前端:显示 Live2D 模型 | guansss/pixi-live2d-display |
| Live2dDriver | 驱动前端 Live2D 模型动作表情 | - |
| ChatGPTChatbot | 基于 ChatGPT 的优质聊天机器人 | acheong08/ChatGPT |
| MusharingChatbot | 基于 ChatterBot 的简单聊天机 | RaSan147/ChatterBot_update musharing-team/chatbot_api |
| Emotext | 中文文本情感分析 | cdfmlr/murecom-verse-1 |
| muvtuberdriver | 组装各模块,驱动整个流程 | - |
参考资料:
- Cubism: Live2D Cubism SDK チュートリアル. https://docs.live2d.com/cubism-sdk-tutorials/
- Gunther Cox: ChatterBot Docs. https://chatterbot.readthedocs.io/en/stable/
- Pavo Studio: Live2DViewerEX 文档. http://live2d.pavostudio.com/doc/zh-cn/about/
- CDFMLR: 让 AI 看懂你的心情,并推荐应景的音乐,以一种简单的实现. https://juejin.cn/post/7070819253309407268
- guansss: pixi-live2d-display docs. https://guansss.github.io/pixi-live2d-display/
- MDN: The WebSocket API (WebSockets). https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API
- OBS: Open Broadcaster Software. https://obsproject.com
- 大连理工大学 - 信息检索研究室: 情感词汇本体-词典. https://ir.dlut.edu.cn/info/1013/1142.htm
- Bilibili 帮助中心: 成为主播. https://link.bilibili.com/p/help/index#/open-live
本项目、文章能够完成,还要特别感谢 GitHub Copilot 和 ChatGPT 的帮助。
何谓“mu”:一说是 machine/you 的缩写:这个系列用于探索机器与人、人工智能与艺术。另有一说 mu… 是 make your … 的意思:保持简单,开源共享,人人都能做。(事实上 mu 最初的来源是 music,所以这些探索的切入点是:音乐、分享、感动。) ↩︎
徐琳宏 , 林鸿飞 , 潘宇 , et al. 情感词汇本体的构造 [J]. 情报学报, 2008, 27(2) : 6. ↩︎