服务器数据恢复环境:
北京某单位有一台EMC某型号存储,有一组由10块STAT硬盘组建的RAID5阵列,另外2块磁盘作为热备盘使用。RAID5阵列上层只划分了一个LUN,分配给SUN小机使用,上层文件系统为ZFS。
服务器故障:
存储RAID5阵列中有2块硬盘损坏离线,只有一块热备盘激活,RAID5阵列瘫痪,上层LUN无法正常使用。
服务器数据恢复过程:
1、将故障存储中所有磁盘编号后取出,由硬件工程师对所有磁盘做硬件故障检测,经过检测没有发现有硬盘存在物理故障和坏道。
磁盘没有发现物理故障和坏道,初步推断是某些磁盘读写不稳定导致故障发生。EMC控制器的磁盘检测策略非常严格,一旦检测到某些磁盘性能不稳定,EMC控制器极有可能会判定这些磁盘为坏盘,将认定为坏盘的磁盘踢出RAID阵列。一旦RAID阵列中掉线的盘到达到该RAID级别允许掉盘的极限值,就会导致RAID阵列崩溃不可用,由于EMC存储的LUN都是基于RAID阵列的,RAID崩溃会导致基于该RAID阵列的LUN不可用。
2、将故障存储中所有磁盘以只读方式做全盘镜像备份,镜像完成后按照编号将所有磁盘还原到原存储中,后续的数据分析和数据恢复操作都基于镜像文件进行,避免对原始磁盘数据造成二次破坏。镜像完成后发现源磁盘的扇区大小为520字节,使用工具将镜像数据做520字节To512字节的转换。
3、基于镜像文件分析底层RAID5阵列的相关信息。经过分析发现发现其中有2块盘(8号盘和11号盘)完全没有数据,从管理后台上显示这2块盘是Hot Spare,8号盘替换了离线的5号盘。虽然8号盘作为热备盘成功激活,但该RAID级别为RAID5,因为有2块盘离线,所以该RAID5阵列还缺失一块硬盘,所以数据没有同步到8号盘中。继续分析其他10块硬盘,分析数据在硬盘中的分布规律、RAID条带的大小、盘序等相关信息。
4、根据上面步骤分析出来的RAID信息虚拟重构原RAID。由于整个RAID阵列中一共掉线两块盘,需要分析这两块盘掉线的顺序。经过分析发现有一块盘在同一个条带上的数据和其他盘明显不一样,因此初步判断此盘可能是先掉线的。使用北亚企安自主开发的RAID校验程序对这个条带做校验后确认先掉线的那块硬盘。
5、由于LUN是基于RAID阵列的,完成原RAID阵列的重组后分析LUN在RAID阵列中的分配信息和LUN分配的数据块MAP。根据LUN相关信息解释LUN的数据MAP并导出LUN的所有数据。
6、使用北亚企安自主开发的ZFS文件系统解释程序对生成的LUN做文件系统解释,在解释某些文件系统元文件的过程中程序报错。开发工程师对程序做debug调试并分析程序报错原因,经过数小时的分析与调试,发现无法解释文件系统的的原因是存储瘫痪导致ZFS文件系统中某些元文件损坏。人工修复这些损坏的元文件。
7、修复完成后解析ZFS文件系统,解析所有文件节点及目录结构。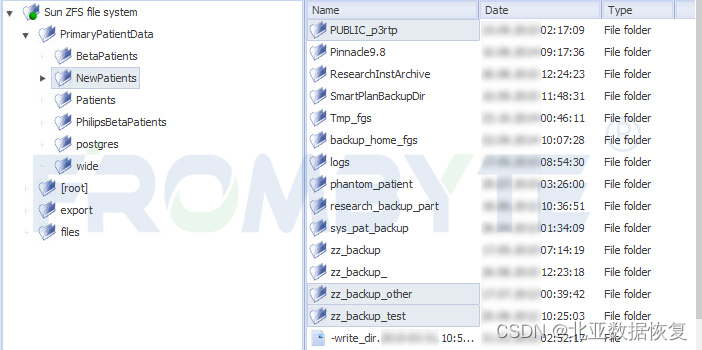
8、由用户方工程师对恢复出来的数据进行验证,验证过程中没有发现问题,确认恢复数据完整有效。本次数据恢复工作完成。