Hadoop的第二个核心组件:MapReduce框架第一节
- 一、基本概念
- 二、MapReduce的分布式计算核心思想
- 三、MapReduce程序在运行过程中三个核心进程
- 四、如何编写MapReduce计算程序:(编程步骤)
- 1、编写MapTask的计算逻辑
- 2、编写ReduceTask的计算逻辑
- 3、编写Driver驱动程序
- 五、MapReduce的案例实现 —— 大数据分布式计算的经典案例WordCount(单词计数)
- 1、案例需求
- 2、案例分析(基于MapReduce)
- 3、代码开发
一、基本概念
Hadoop解决了大数据面临的两个核心问题:海量数据的存储问题、海量数据的计算问题
其中MapReduce就是专门设计用来解决海量数据计算问题的,同时MapReduce和HDFS不一样的地方在于,虽然两者均为分布式组件,但是HDFS是一个完善的软件,我们只需要使用即可,不需要去进行任何的逻辑的编辑。而MapReduce进行数据计算,计算什么样的数据,使用什么样的逻辑,MR程序都不清楚,因此MR只是一个分布式的计算【框架】,所谓的框架就是MR程序把分布式计算的思想和逻辑全部封装好了,我们只需要按照框架的思维编写计算代码(就是我们自己处理数据的逻辑代码),编写完成之后,我们的程序必然是分布式的程序。
使用分布式计算框架的好处就在于我们开发人员只需要把关注点和重点放在业务的逻辑开发,而非分布式计算程序逻辑的逻辑。
二、MapReduce的分布式计算核心思想
MR框架实现分布式计算的逻辑是将MR程序分成了两部分:Map阶段、Reduce阶段
其中运行一个计算程序先执行Map阶段,map阶段又可以同时运行多个计算程序(MapTask)去计算map阶段的逻辑,Map阶段主要负责分数据,而且map阶段的多个MapTask并行运行互不干扰。
第二阶段Reduce阶段,Reduce阶段也可以同时运行多个计算程序(ReduceTask),Reduce阶段的任务主要负责合数据,同时多个ReduceTask同时运行互不干扰的。
任何一个MR程序,只能有一个Map阶段,一个Reduce阶段。
三、MapReduce程序在运行过程中三个核心进程
MRAppMaster(一个):负责整个分布式程序的监控
MapTask(多个):Map阶段的核心进程,每一个MapTask处理数据源的一部分数据
ReduceTask(多个):Reduce阶段的核心进程,每一个ReduceTask负责处理Map阶段输出的一部分数据
四、如何编写MapReduce计算程序:(编程步骤)
1、编写MapTask的计算逻辑
1、编写一个Java类继承Mapper类,继承Mapper类之后必须指定四个泛型,四个泛型分别代表了MapTask阶段的输入的数据和输出的数据类型。
MR程序要求输入的数据和输出的数据类型必须都得是key-value键值对类型的数据。
2、重写继承的Mapper类当中的map方法,map方法处理数据的时候是文件中的一行数据调用一次map方法,map方法的计算逻辑就是MapTask的核心计算逻辑。
3、同时map方法中数据计算完成,需要把数据以指定的key-value格式类型输出。
2、编写ReduceTask的计算逻辑
1、编写一个Java类继承Reducer类,继承Reducer类之后必须指定四个泛型,四个泛型分别代表了Reduce阶段的输入和输出的KV数据类型。
Reduce的输入的KV类型就是Map阶段的输出的KV类型。
Reduce的输出类型自定义的。
2、重写Reducer类当中提供的reduce方法,reduce方法处理数据的时候一组相同的key调用一次reduce方法,reduce方法的计算逻辑就是ReduceTask的核心计算逻辑。
3、调用reduce方法,reduce逻辑处理完成,需要把数据以指定的key-value格式类型输出。
3、编写Driver驱动程序
Driver驱动程序是用来组装MR程序,组装MR程序的处理的文件路径、MR程序的Map阶段的计算逻辑、MR程序的Reduce阶段的计算逻辑、MR程序运行完成之后的结果的输出路径。
Driver驱动程序本质上就是一个main函数
MapReduce底层是由Java开发的,因此MR程序我们要编写的话支持使用Java代码来进行编写
五、MapReduce的案例实现 —— 大数据分布式计算的经典案例WordCount(单词计数)
1、案例需求
现在有一个文件,文件很大,文件中存储的每一行数据都是由空格分割的多个单词组成的,现在需要通过大数据分布式计算技术去统计文件中每一个单词出现的总次数
2、案例分析(基于MapReduce)

3、代码开发
1、创建一个maven管理的Java项目
2、引入MR的编程依赖
- hadoop-client
- hadoop-hdfs
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.kang</groupId><artifactId>mr-study</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><name>mr-study</name><url>http://maven.apache.org</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><hadoop.version>3.1.4</hadoop.version></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency></dependencies>
</project>
3、编写Mapper阶段的计算逻辑
package com.kang.wc;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** 单词计数的MapTask的计算逻辑* 1、继承Mapper类。同时需要指定四个泛型 两两一组 分别 代表输入的key value 和输出的key value的数据类型* 默认情况下,map阶段读取文件数据是以每一行的偏移量为key 整数类型 每一行的数据为value读取的 字符串类型* map阶段输出以单词为key 字符串 以1为value输出 整数* 数据类型不能使用Java中的数据类型,数据类型必须是Hadoop的一种序列化类型* Int —— hadoop.io.IntWritable* Long —— hadoop.io.LongWritable* String —— hadoop.io.Text* 2、重写map方法*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> {/*** map方法就是MapTask的核心计算逻辑方法* map方法是切片中的一行数据调用一次* @param key 这一行数据的偏移量* @param value 这一行数据* @param context 上下文对象 用于输出map阶段处理完成的key value数据* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {//拿到一行数据,并且将一行数据转成字符串类型String line = value.toString();//字符串以空格切割得到一个数组,数组中存放的就是一行的多个单词String[] words = line.split(" ");//遍历数组 得到每一个单词 以单词为key 以1为value输出数据即可for (String word : words) {context.write(new Text(word),new LongWritable(1L));}}
}
4、编写Reducer阶段的计算逻辑
package com.kang.wc;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** Reduce的编程逻辑:* 1、继承Reducer类,指定输入和输出的kv类型* 输入KV就是Map阶段的输出KV Text LongWritable* 输出kv Text LongWritable* 2、重写reduce方法*/
public class WCReducer extends Reducer<Text, LongWritable,Text,LongWritable> {/*** Reduce方法是Reduce阶段的核心计算逻辑* reduce方法是一组相同的key执行一次* @param key 一组相同的key 某一个单词* @param values 是一个集合,集合存放的就是这一个单词的所有的value值* @param context 上下文对象 用于reduce阶段输出数据* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {//只需要将某个单词聚合起来的value数据累加起来 得到总次数long sum = 0L;for (LongWritable value : values) {sum += value.get();}//只需要以单词为key 以sum为value输出即可context.write(key,new LongWritable(sum));}
}
5、编写Driver驱动程序
package com.kang.wc;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** Driver驱动程序说白了就是封装MR程序的* Driver驱动程序其实就是一个main函数*/
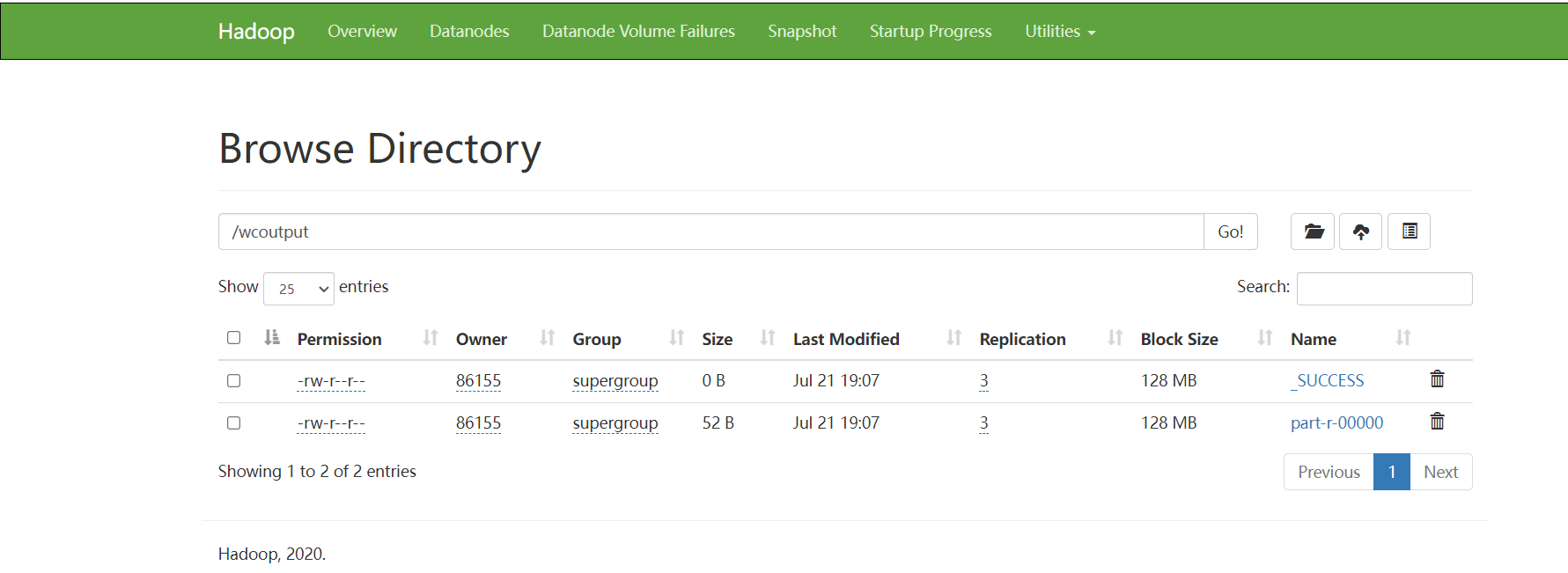
public class WCDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {//1、准备一个配置文件对象ConfigurationConfiguration conf = new Configuration();//指定HDFS的地址conf.set("fs.defaultFS","hdfs://192.168.31.104:9000");//2、创建封装MR程序使用一个Job对象Job job = Job.getInstance(conf);//3、封装处理的文件路径hdfs://single:9000/wc.txtFileInputFormat.setInputPaths(job,new Path("/wc.txt"));//4、封装MR程序的Mapper阶段,还要封装Mapper阶段输出的key-value类型job.setMapperClass(WCMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);//5、封装MR程序的Reducer阶段,还要封装reduce的输出kv类型job.setReducerClass(WCReducer.class);job.setOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);job.setNumReduceTasks(1);//指定reduce阶段只有一个ReduceTask//6、封装MR程序的输出路径 —— 输出路径一定不能存在 如果存在会报错FileOutputFormat.setOutputPath(job,new Path("/wcoutput"));//7、提交运行MR程序boolean flag = job.waitForCompletion(true);System.exit(flag?0:1);}
}









![[NLP] LLM---扩充词表LLama2-构建中文tokenization](https://img-blog.csdnimg.cn/1c4ccf9d0a864e3092f16c7757ee24c9.png)