目录
一、第一个 Spring 项目
1、配置环境
2、Spring 的 jar 包
Maven 项目导入 jar 包和设置国内源的方法:
3、Spring 的配置文件
4、Spring 的核心 API
ApplicationContext
4、程序开发
5、细节分析
(1)名词解释
(2)Spring 工厂的相关方法
(3)配置文件中的细节
1、只配置 class 属性
2、name 属性
6、Spring 工厂的底层实现原理(简易版)
7、思考
二、Spring 与 日志框架的整合
1、Spring 如何整合日志框架?
一、第一个 Spring 项目
1、配置环境
2、Spring 的 jar 包
在项目的 porm.xml 中添加 Spring 框架的支持,xml 配置如下:
<!-- https://mvnrepository.com/artifact/org.springframework/spring-context -->
<dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.1.4.RELEASE</version>
</dependency>复制的时候注意观察当前的 pom.xml 中是否已经有 dependices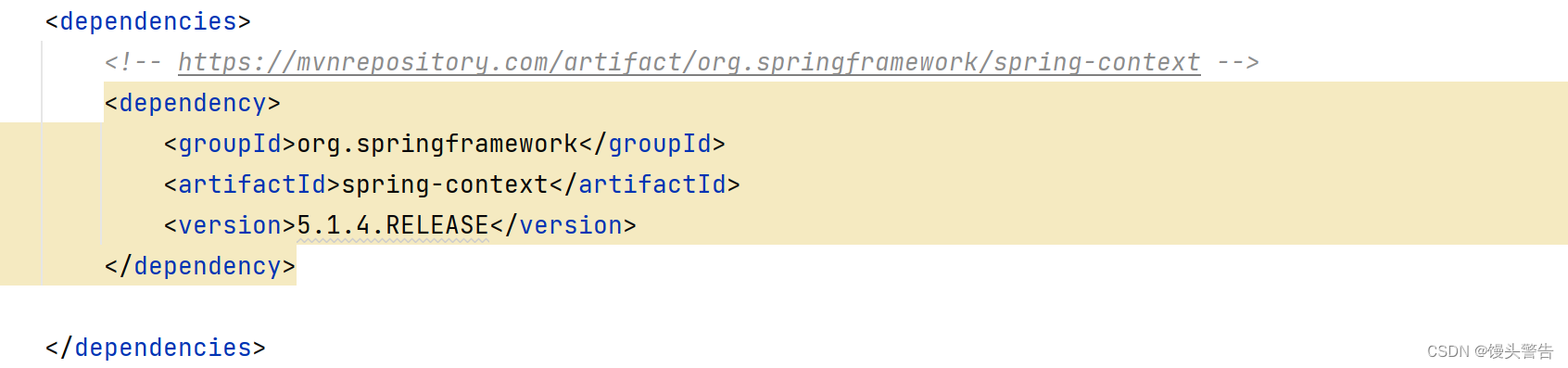
如果 jar 包下载过慢或者下载失败,我们可以设置国内源来解决
Maven 项目导入 jar 包和设置国内源的方法:
1、打开自己的 idea 检测 maven 的配置是否正确
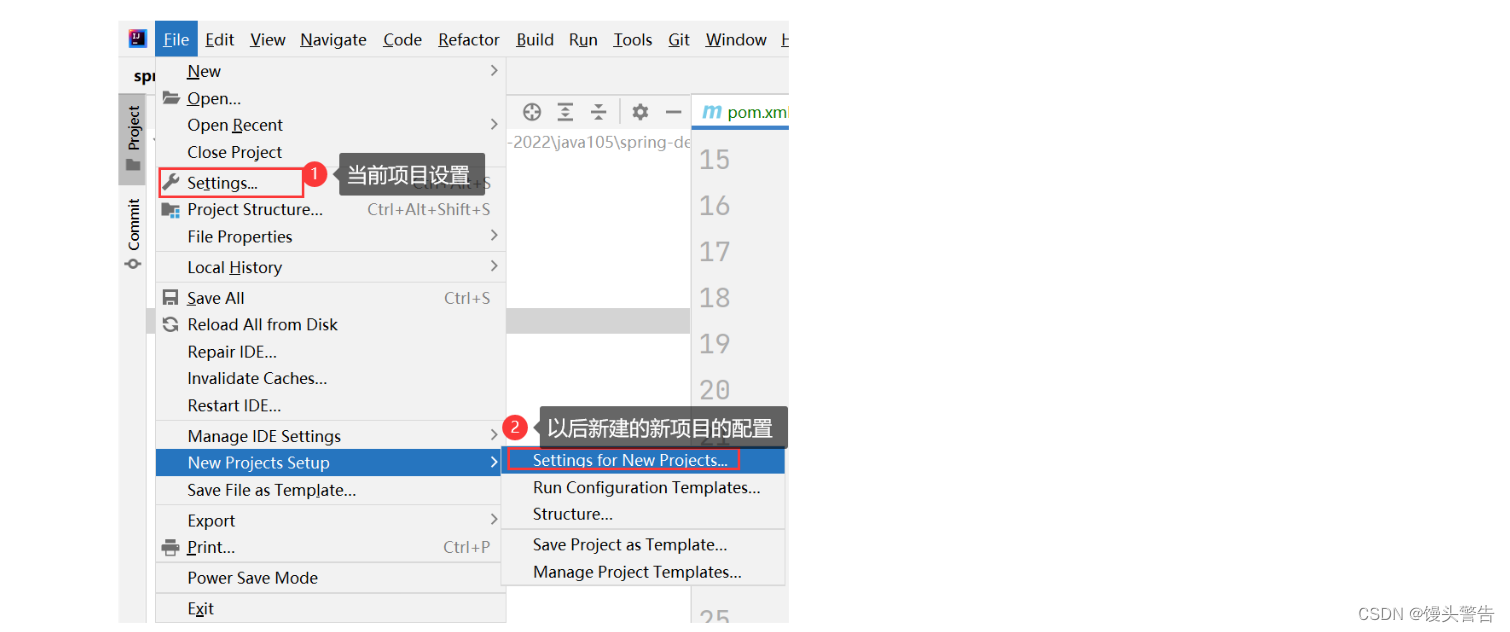
这两个地方都要进行配置!!!
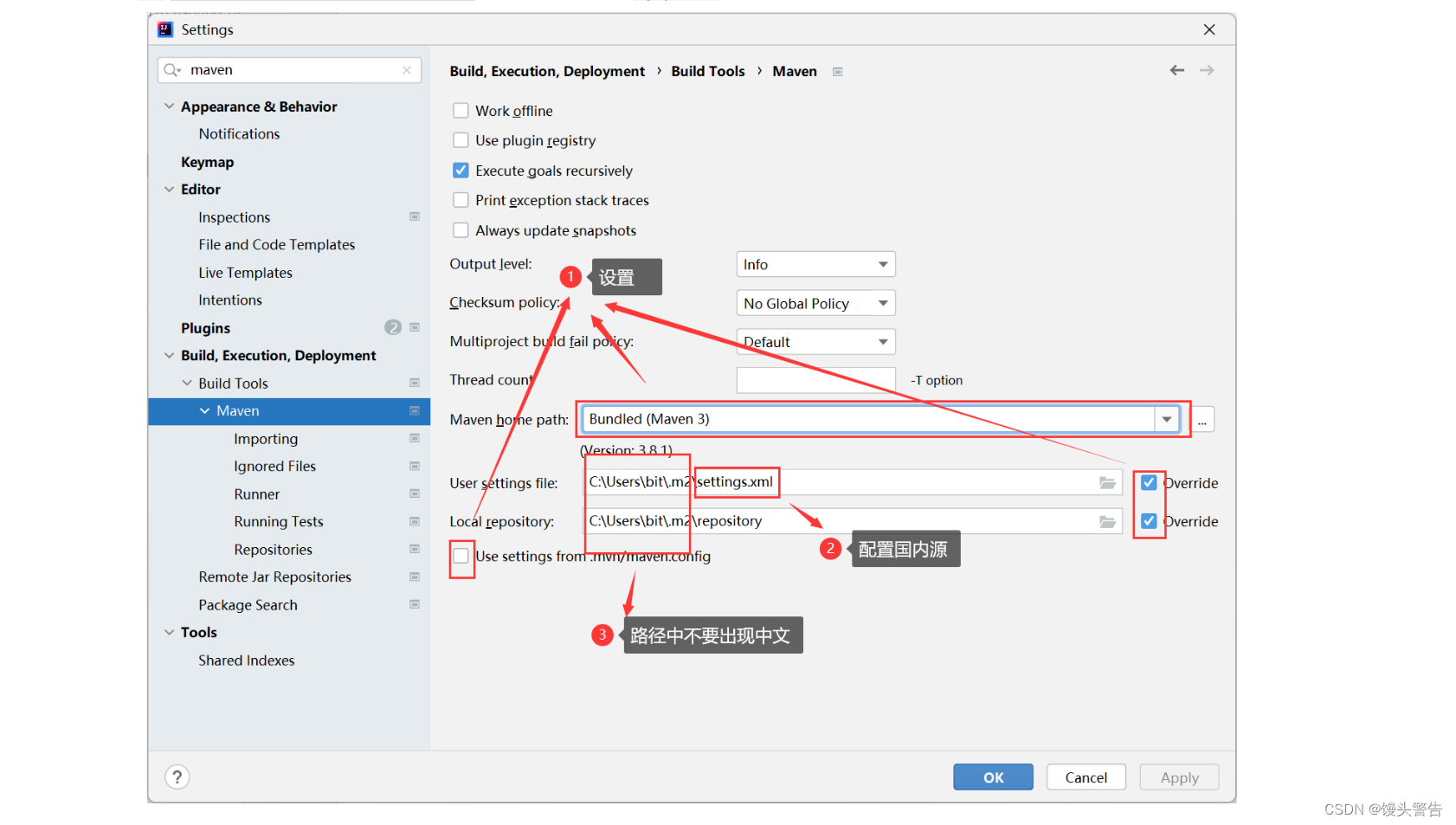
然后设置 settings 文件:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0https://maven.apache.org/xsd/settings-1.0.0.xsd"><mirrors><mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors>
</settings>如果电脑中没有 settings 文件,就自己创建一个,如果有,就直接在原来的 settings 文件上更改就行
2、如果继续出错,就删除本地 maven 仓库的 jar 包重新下载
3、当前网络运营商有问题,就尝试更换链接的数据源,使用更好的网络,如果还是不行,就间隔一段时间之后再去尝试
3、Spring 的配置文件
1、配置文件的放置位置:任意位置,没有硬性要求
2、配置文件的命名:没有硬性要求,建议叫 applicationContext.xml
接下来,我们思考一个问题:
Spring 框架如何知道开发人员未来会把配置文件放在哪里,叫什么名字呢?
所以,日后应用 Spring 框架时,需要进行配置文件路径的设置
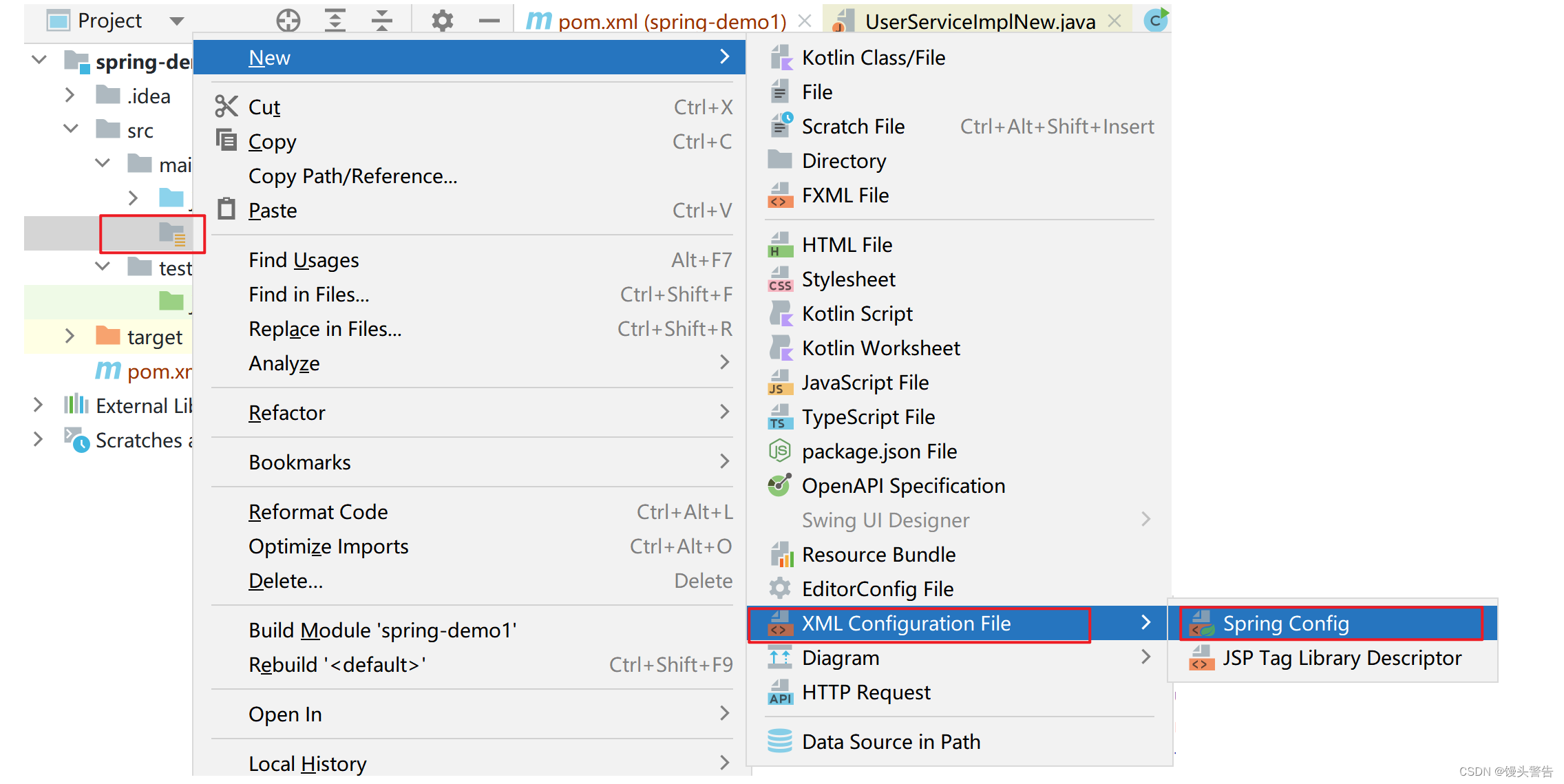
按照图中步骤,在 resourses 下创建好一个文件,并按照建议给它命名为 applicationContext.xml
此时我们就会发现,整个 Spring 的配置文件就帮我们建好了,
4、Spring 的核心 API
ApplicationContext
作用:Spring 提供的 ApplicationContext 这个工厂,主要的作用就是用于对象的创建
好处:解耦合
ApplicationContext 是一个接口类型
接口的主要目的:屏蔽实现的差异(工厂可能会应用到不同的开发场景下,不同的开发场景有不同的特点)
Spring 主要提供两种类型的工厂:
1、非 web 环境:ClassPathXmlApplicationContext(main,junit)
2、web 环境:XmlWebApplicationContext
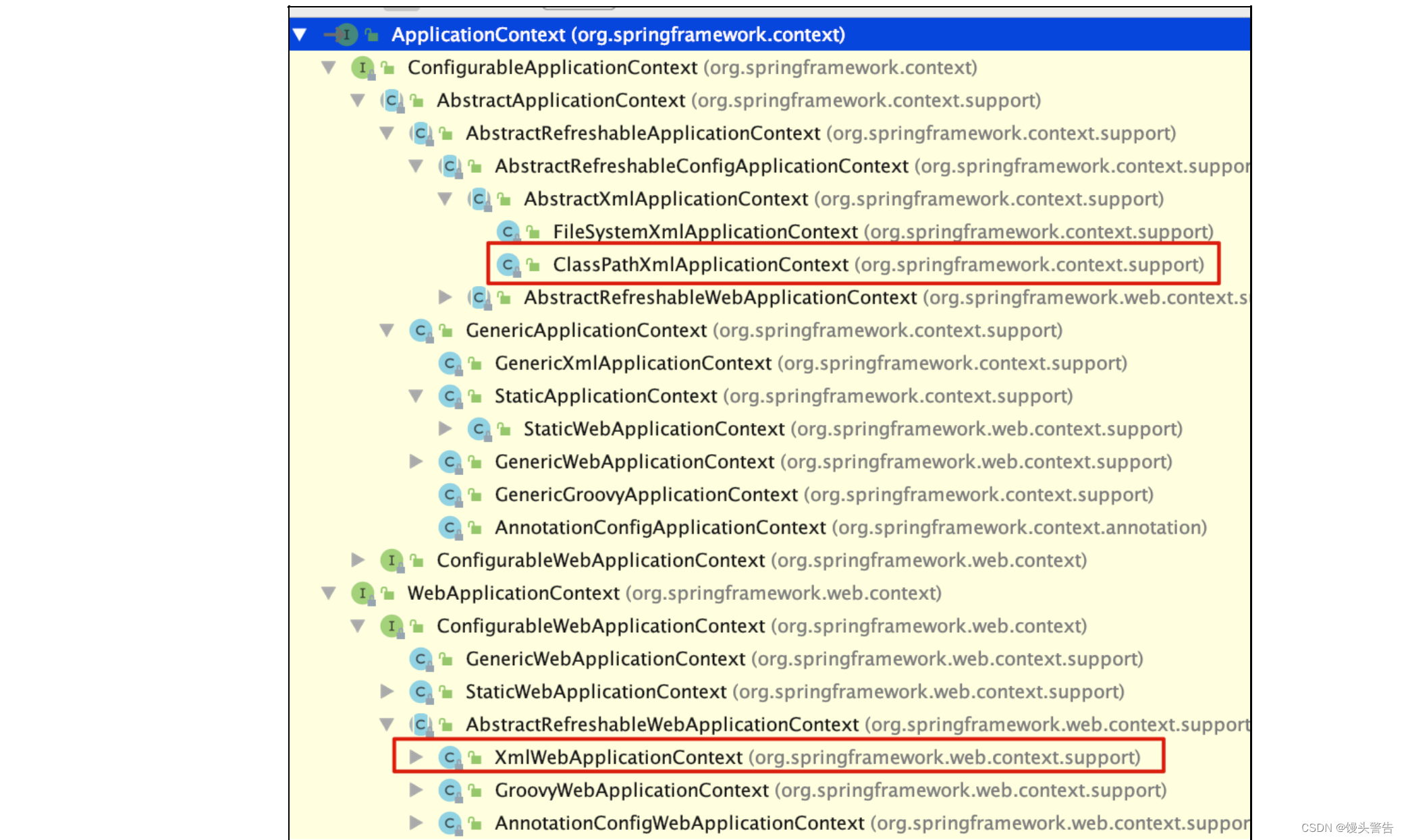
我们称 ApplicationContext 是一个重量级资源
那么什么是一个重量级资源?
如果一个对象对内存占用的比较多,那么我们就称之为重量级资源
这也就意味着,ApplicationContext 这个工厂的对象,会占用大量的内存
正因为它的内存占用比较多,所以我们不会频繁的创建对象:一个应用只会创建一个工厂对象
也正是因为它有这样的特点,所以这个对象就有可能会出现并发访问(多线程访问)的情况
所以,ApplicationContext 工厂,一定是线程安全的(多线程并发访问)
4、程序开发
Spring 提供的工厂和我们自己写的工厂,本质上是没有差异的,都是解耦合的
那么,对于 Spring 来讲,它的工厂使用,和我们前面所总结的通用工厂的使用方式,本质上是没有区别的
1、创建类型
2、配置文件的配置 applicationContext.xml
3、通过工厂类,获得对象 ApplicationContext
1、创建类型
2、配置文件的配置
我们要在 beans 下面创建一个子标签,里面有两个属性:id 和 class
id 属性:就是起个名字,命名(唯一的)
class 属性:配置所需要创建的文件的全限定名

虽然组织形式不同,但是所需要的要素是完全一样的

通过这步,我们也告诉了 Spring ,需要生产 Person 对象
3、通过工厂类,获得对应的对象
//用于测试 Spring 的第一个程序public static void test() {//1、获得 Spring 工厂ApplicationContext ctx = new ClassPathXmlApplicationContext("/applicationContext.xml");//2、通过工厂类来获得对象Person person = (Person) ctx.getBean("person");System.out.println("person = " + person);}此时,我们会发现,这个对象的引用打印出来了

说明这个对象由 Spring 的工厂创建完成了
5、细节分析
(1)名词解释
Spring 工厂创建的对象,叫做 bean 或者 组件(componet)
(2)Spring 工厂的相关方法
//通过这种⽅式获得对象,就不需要强制类型转换
Person person = ctx.getBean("person", Person.class);
System.out.println("person = " + person);//当前Spring的配置⽂件中 只能有⼀个<bean class是Person类型
Person person = ctx.getBean(Person.class);
System.out.println("person = " + person);//获取的是 Spring⼯⼚配置⽂件中所有bean标签的id值
String[] beanDefinitionNames = ctx.getBeanDefinitionNames();
for (String beanDefinitionName : beanDefinitionNames) {System.out.println("beanDefinitionName = " +
beanDefinitionName);
}//根据类型获得Spring配置⽂件中对应的id值
String[] beanNamesForType = ctx.getBeanNamesForType(Person.class);
for (String id : beanNamesForType) {System.out.println("id = " + id);
}//⽤于判断是否存在指定id值得bean
if (ctx.containsBeanDefinition("a")) {System.out.println("true = " + true);
}else{System.out.println("false = " + false);
}//⽤于判断是否存在指定id值得bean
if (ctx.containsBean("person")) {System.out.println("true = " + true);
}else{System.out.println("false = " + false);
}(3)配置文件中的细节
1、只配置 class 属性
<bean class="Person"/>上述这种配置,有没有 id 值呢?
我们可以借助上面的 ctx.getBeanDefinitionNames(); 来进行观察
我们发现,spring 会自动生成一个 id 的默认值,所以我们没有给它设定 id ,但是实际上还是存在一个 id 与之对应的
应用场景:如果这个 bean 只需要使用一次,那么就可以省略 id 值,反之,如果这个 bean 会使用多次或者被其它 bean 引用,则需要设置 id 值
2、name 属性
用于在 Spring 的配置文件中,为 bean 对象定义别名(小名)
<bean id="person1" name="p" class="Person" ></bean>id 与 name 相同点:
1、ctx.getBean(" id | name ") ; 都可以获取到对象
2、 < bean id = " " class = " " > 和 < bean name = " " class = " " >二者是等效的
id 和 name 的区别:
1、别名可以定义多个,但是 id 只能是一个

2、XML 的 id 属性的值,命名的时候要求:必须要以字母开头,字母,数字,下划线,连字符,不能以特殊字符开头,比如 / ,而 name 属性的值,在命名的时候,是没有要求的,所以 name 属性会应用在特殊命名的场景下,但是 xml 发展到了今天,id 的属性的限制,已经不存在了
3、代码的区别
//⽤于判断是否存在指定id值得bean,不能判断name值if (ctx.containsBeanDefinition("person")) {System.out.println("true = " + true);}else{System.out.println("false = " + false);}//⽤于判断是否存在指定id值得bean,也可以判断name值if (ctx.containsBean("p")) {System.out.println("true = " + true);}else{System.out.println("false = " + false);}6、Spring 工厂的底层实现原理(简易版)
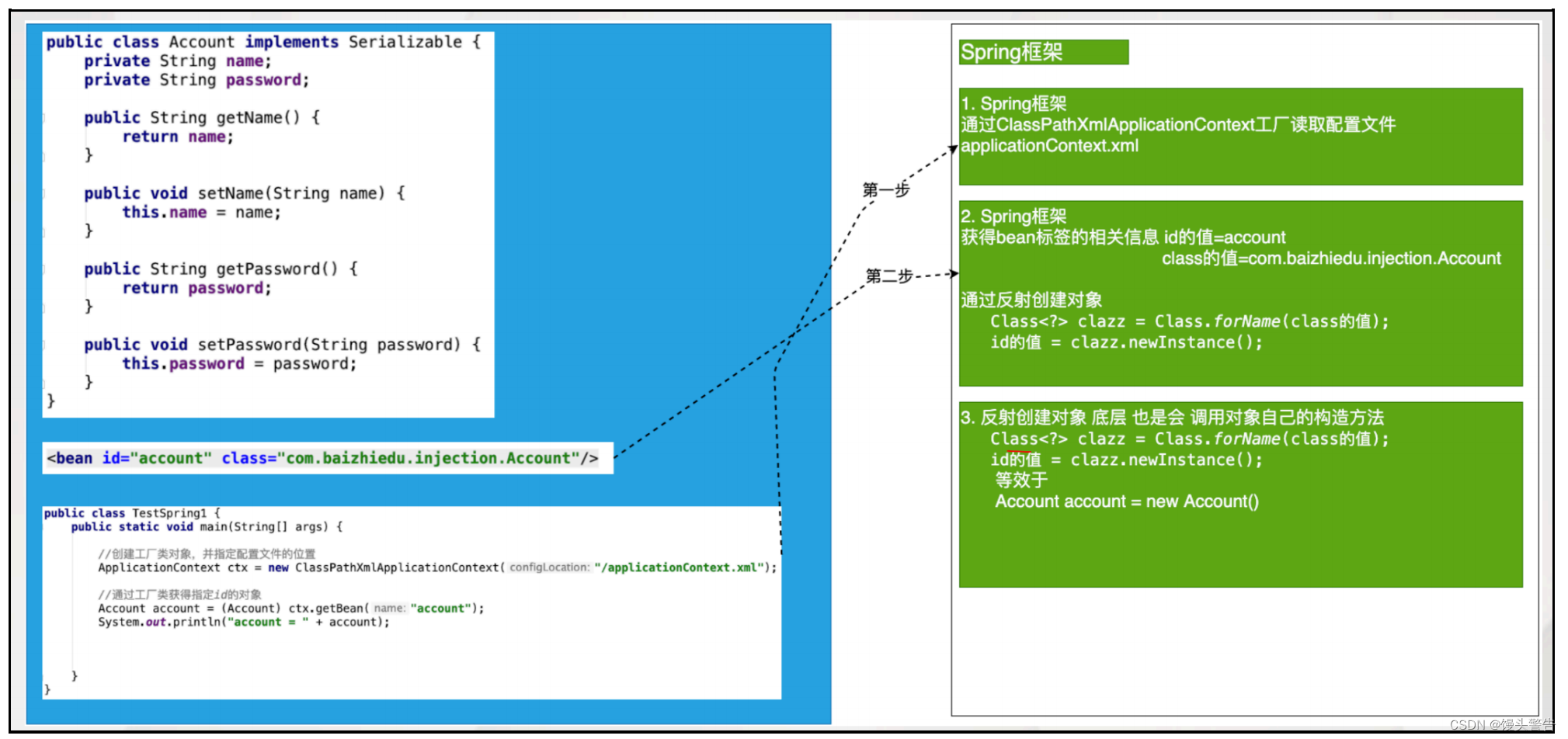
反射的底层是否会调用构造方法呢?
虽然反射创建了对象,但是底层也一定会调用这个对象的构造方法(无参),所以我们也可以认为反射创建对象就等效于我们的 new 创建对象
如果这个构造方法是私有的怎么办呢?
private 修饰的只能在本类调用,而显然 String 是外类
通过代码实验,我们能发现,即使构造方法被设为了私有的,private 的构造方法依旧会被调用
底层还是通过反射来实现的,因为反射能够调用一个类的私有的属性和构造方法,所以 Spring 工厂是可以调用对象私有的构造方法来创建对象的
7、思考
未来在开发过程中,是不是所有的对象都会被交给 Spring 工厂来创建呢?
理论上来说,是的,但是有特例:实体对象(entity)
实体对象是不会交给 Spring 创建的,是由持久层框架来进行创建的。
二、Spring 与 日志框架的整合
Spring 与日志框架整合,日志框架就可以在控制台中输出 Spring 框架运行过程中的一些重要的信息
好处:便于我们了解 Spring 框架的运行过程,利于程序的调试
1、Spring 如何整合日志框架?
Spring 的不同版本,针对于日志框架的整合,以及整合的内容和方式,是有一些区别的
比如:Spring 1.2.3早期的日志框架,都是与 common-logging.jar 这个日志进行整合的
Spring 5.x 默认整合的日志框架是 logback 或者 log4j2
根据我们的开发需要,我们想让 Spring 5.x 整合 log4j,那么整合 log4j 怎么整合呢?
1、引入 log4j 的 jar 包
2、引入 log4j.properties 配置文件
以 jar 包的方式,我们肯定要通过 maven 来完成,所以我们要设置我们的 pom 文件,那么在 pom 文件中我们要添加对应的依赖
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version>
</dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version>
</dependency>第二个配置就是引入 log4j.properties 的配置文件
# resources # resources⽂件夹根⽬录下
### ### 配置根
log4j.rootLogger = debug,console### ### ⽇志输出到控制台显示
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n整合完毕之后再次运行代码,就能发现区别了:
我们会发现,当我们整合日志之后,我们从控制台中看到的内容就不仅仅基于我们打印的,还基于我们 spring 内部运行的
这样的话,在日后解决复杂性问题的时候,我们就可以通过日志,大概可以猜测到 Spring 帮我们做了什么,就更加利于我们后续程序的调试