前言
三年耕耘大厂数据分析师,有些工具是必须要掌握的,尤其是Python中的数据分析三剑客:Pandas,Numpy和Matplotlib。就以个人经验而已,Pandas是必须要掌握的,它提供了易于使用的数据结构和数据操作工具,使得在Python中处理结构化数据变得更加简单和高效。无论是处理常用的时序数据还是处理金融数据,与各类数据库联动或者是使用各类算法进行计算分析,都离不开Pandas的数据处理支持。作为一名数据分析师几乎每天都得和Pandas打交道,所以学习Pandas避不可避,但是如何高效学习Pandas确是需要深度思考的问题。所以本篇文章就以我个人使用Pandas的多年经验,给想要入门Pandas数据分析的同学分享学习经验和路线。
如果觉得分享不放心或者觉得是虚假宣传的可以去看看博主专门写的数据分析专栏:
一文速学系列-数据分析![]() https://blog.csdn.net/master_hunter/category_11740969.html,专栏写了有三年时间,“夯实基础,熟练掌握各类Pandas基础函数使用方法。以实战项目为线索,深入了解数据分析原理以及掌握Pandas处理数据基础方法,最终能够完全掌握使用Pandas处理常见业务需求以及数据建模数据处理。”这是我创立该专栏的初心,所以希望大家可以放心阅读而不是担心虚假宣传。
https://blog.csdn.net/master_hunter/category_11740969.html,专栏写了有三年时间,“夯实基础,熟练掌握各类Pandas基础函数使用方法。以实战项目为线索,深入了解数据分析原理以及掌握Pandas处理数据基础方法,最终能够完全掌握使用Pandas处理常见业务需求以及数据建模数据处理。”这是我创立该专栏的初心,所以希望大家可以放心阅读而不是担心虚假宣传。
送书活动规则
- 关注我的博客:成为我博客的关注者,你将第一时间收到所有新的博客文章和活动信息。
- 留言参与:在每一期文章下方留言,留言内容见每期的参与方式。
- 公布结果:在评论中抽取几名幸运读者免费赠送,获奖名单将在 2023/9/17 12:00:00 置顶评论区。
抽选粉丝算法完全透明。
每期活动将在获奖名单公布后结束。
参与方式
参与赠书活动非常简单,大家只需按照以下步骤操作即视为参与:
- 关注博主。
- 在本文下方评论 “一文速学-Pandas数据分析”。
本期赠书《Pandas数据分析》见文末
一、Pandas学习内容

方便大家记忆我做了一张四维导图,其实Pandas用来做数据分析用到模块没有那么复杂,很多复杂的功能一个函数就可以轻松搞定,但是如果想要做出更高效的效果需要利用这些功能函数构思还是挺难的一件事。比如实现一列切分为多列或者多文件批次聚合处理等此类的需求,都需要具备一定的Pandas熟练度才能实现。一般来说掌握了以上Pandas的功能使用能力,处理业务需求基本上是够用了,只要加深熟练度就行。但是Pandas很多情况下都不是单独使用,很多场景是结合numpy、matplotlib或者是sklearn等其他第三方库一起使用,因此还需要灵活多变掌握其他功能。
二、Pandas学习路线
想要学习Pandas数据分析的人来说,对一般的数据分析工具,比如Excel或者PowerBI都有所接触过,对数据分析基础知识应该是懂的。学习Pandas很多人是为了办公更加高效,也有很多人学Pandas是为了数据处理,总之我认为是具备了一定学习能力基础再来学习Pandas,我自己也是,因此我推荐的学习路线和我专栏写作顺序是一致的,大家可以参考:
1.先学Pandas数据结构
数据结构作为工具的基础零件,必须对其有十分清晰的了解,先掌握Series和DataFrame十分有必要。该两种数据结构并不难理解,语言都是共通的,只要了解C语言结构的数据结构或是Python、JAVA的都能理解。关键是如何运用函数处理这些数据结构。主要学习每个数据结构的三大操作,打下基础之后进行复杂的表操作即可,因为大部分还是需要输出表结构数据。
1.Series
2.DataFrame
- 创建
- pd.Series()
- pd.DataFrame()
- 转换操作
- 字典转换,数组转换
- 索引操作
- 重命名索引,重置索引
- 查询操作
- .at(),.iloc(),.loc()
- 切片操作
- 拼接操作
- pd.concat(),pd.merge()
2.常用I/O操作
使用pandas作为数据分析的好处在于它不像excel那么死板只能用xlsx或者csv的文件读写,甚至可以将一些json,sql语句作为读写载体,进而转为表结构。这样一来就不受数据格式现在,可以自由的进行数据输出,因此第二步必要学习的就是常用的I/O操作。不过这时候很多人要问了,Pandas的I/O操作不是简单的pd.read_csv或者是pd.read_excel()这么简单吗?
当然平常我们使用的readI/O函数,通常是读进来再自己内部写代码处理数据格式,但是很多情况我们直接修改read_csv等一些参数就可以直接提前完成 部分数据处理的工作,可以帮我们省去相当大的功能。这里举一个例子:
倘若某个csv文件,我希望讲其一列的类型修改转为文本类型:
df_csv=pd.read_csv("user_info.csv")
df_csv.user_id=df_csv.user_id.astype(str)一般我们都是采取以上做法,但如果要进行多个列转格式还是比较繁琐的,而通过read_csv()可以直接修改:
df_csv=pd.read_csv(r'\user_info.csv',dtype={'user_id':'str'})
当然read系列函数每个基本都有20以上多种参数可供修改, 以上的案例很多,大家使用的时候自然而然就会发现。
Pandas自带的I/O函数很多,但是使用频繁的掌握以下八个就足够看,涉及到另外的数据格式再用就好了,参数很多都是相似的:
- pd.read_csv()-pd.to_csv()
- pd.read_excel()-pd.to_excel()
- pd.read_sql()-pd.to_sql()
- pd.read_json()-pd.to_json()
3.表结构复杂操作
1.数据清洗
Pandas常作为机器学习的数据清洗工具,常常进行数学建模分析的朋友基本都有接触过。一般进行数据清洗对三类数据进行处理:存在空值的数据、异常值数据、重复值数据。缺失值处理有空值计数,筛选以及填充,都有对应的函数处理,重复值有duplicated() 和drop_duplicates() 等,其他处理不必多说,大家如果有数据处理的需求可以看看本人的专栏。
2.索引复杂操作
DataFrame的索引操作有很多,一般业务上使用的都相对较简单,但是部分需求对索引使用较高,比较难使用。常用的索引操作有索引重置:
例如原数据集为:

reset_index会将全部的index都转化为columns:

重设置索引:
index.set_index('ID') 
比较复杂的索引操作有索引重塑实现长宽表数据转换,要理解并使用该函数需要下一定功夫,长宽表转换很多应用于Hive等NoSQL数据库的表,或者是票据数据等存在多个索引的数据。
索引重塑就是将原来的索引进行重新构造,我们根据DataFrame的结构表可知,我们锁定一个数据是依靠他的列名和行名对应得到,可以理解为该数据的x和y坐标轴。例如我们想查找user2的2021年数据。而重塑索引更像是换了个坐标系,等于换了个基。
这种通过两个特征确定唯一值的方法,我们不仅可以用表格型结构表示,还可以用树形结构来表示:

树形结构其实就是在维持表格型行索引不变的情况下,把列索引该为二次行索引,相当于把表格型数据建立成层次化索引。
在pandas用到的方法是stack():
df1.stack()user1 sum 100
2020 30
2021 30
2022 40
user2 sum 120
2020 30
2021 50
2022 40
user3 sum 130
2020 40
2021 50
2022 40
user4 sum 150
2020 50
2021 20
2022 80
user5 sum 160
2020 40
2021 40
2022 80
dtype: int64
根据pandas提供的stack()方法很容易就能实现长宽表之间的转换,以下就为一个宽表:
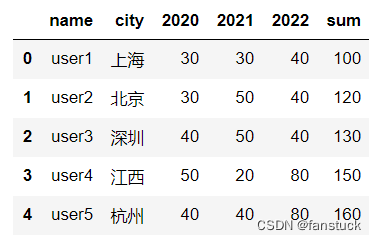
要将宽表转化为长表首先要保持name和city不变的前提下,将年份信息变为行索引,所以要现将name和city先设置为索引,然后再调用stack()方法,将列索引也转换为行索引,最后用reset_index()方法进行索引重置:
df1.set_index(['name','city'],inplace=True) 
若是一头雾水的同学可以去看看本人的博文:一文速学(九)-数据分析之Pandas索引重塑实现长宽表数据转换
还有长表转换为宽表我这里就不展示了。
3.数值操作
数值操作算基础操作了,大家看我的思维导图就好了,这里介绍几个必要的。数值排序:
df1.sort_values(by=['old','weight'],ascending=[True,False])上面这段代码的意思是先按old进行升序排序,若是遇到相同的数值,则按weight降序排序:

排名:
se1=df1['old'].rank()
df1.insert(0,'randk',se1)
df1.sort_values(by='old') 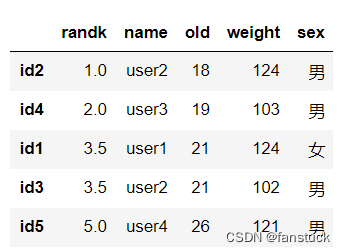
这些操作在SQL里面很常见,Pandas设计的时候也是参考了对数据库表的操作,一般来说SQL对表的操作Pandas都会有的,SQL经常使用的分组聚合功能,Pandas基本上全都复刻了一遍。
4.数据分组
数据工程师估计闭着眼睛都会打groupby,pandas完美复刻了在数据库处理表的聚合各类函数。分组的步骤有三步:

第一步为将指定的数据表,按照键的不同分为若干组。第二部为将这些分组进行计算操作,可以设定为自定义函数运算。第三步计算完成后,再进行合并操作,得到新的一张表格。这个操作很像大数据架构计算框架中的MapReduce,经过上述操作我们就能对一些排列杂乱无章的表操作,从而得到我们想要的数据。这里就不展开说明了,大家要明白Pandas是有对标SQL分组的功能的。
5.时间序列处理
一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档,需要把一些object或者是字符、整型等某列进行转换为pandas可识别的datetime时间类型数据,方便时间的运算等操作。都不需要我过多提示,到时候大家自然会学习此类方法,功能的话我这边给出常用的处理:
通过使用asfreq改变频率函数设定每次频率改变可以设定每个时间片都对应一个值:
rng = pd.date_range('1/1/2011', periods=2, freq='d')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
converted = ts.asfreq('360Min', method='pad') 
将系列重新采样为每日频率resample:
rng = pd.date_range('1/1/2011', periods=5, freq='H')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts.resample('D').mean() 
Series数据类型转换
df_csv['collect_date']=pd.to_datetime(df_csv['collect_date'],format="%Y-%m-%d")
df_csv.dtypes 
4.文本数据处理
Pandas用来代表文本数据类型有两种:
- object:一般为NumPy的数组
- string:最常规的文本数据
我们最常用的还是使用string来存储文本文件,但是使用dataframe和series进行数据处理转换的时候object数据类型又用的多。在Pandas1.0版本之前只有object类型,这会导致字符数据和非字符数据全部都以object方式存储,导致处理混乱。而后续版本优化加入了String更好的区分了处理文本数据的耦合问题。目前的object类型依旧是文本数据和数组类型的string数据,但是Pandas为了后续的兼容性依旧将object类型设为默认的文本数据存储类型。
String数据类型处理方法很多,序列和索引都配备了一组字符串处理方法,可以轻松地对数组的每个元素进行操作。最重要的是这些方法自动排除丢失的/NA值。这些方法通过str属性访问,通常名称与等效(标量)内置字符串方法匹配。
这里举几个常用的案例:
1.大小写转换
s=pd.Series(['A','b','C',np.nan,'ABC','abc','AbC'],dtype='string')小写转换lower()
s.str.lower() 
大写转换upper()
s.str.upper() 
2.字符串空格去除
经常配合正则使用,也就是常在爬虫中代码出现。这种方法有三种控制形式,这里我们创建一个覆盖测试用例全面的数据集:
s=pd.Index([' A','A ',' A ','A'],dtype='string')全部去除strip()
s.str.strip() ![]()
索引上的字符串方法对于处理或转换DataFrame列特别有用。例如,可能有带有前导或尾随空格的列
df = pd.DataFrame(np.random.randn(3, 2), columns=[" Column A ", " Column B "], index=range(3)
) 
我们将列索引提取之后使用str类方法就可以处理转换, 函数组合一起来用的话,还可以搭配其他函数实现复杂的转换效果::
df.columns = df.columns.str.strip().str.lower().str.replace(" ", "_") 
3.拆分和拼接
拆分字符串我们一般回用到split这个函数,使用起来非常方便:
s2 = pd.Series(["a_b_c", "c_d_e", np.nan, "f_g_h"], dtype="string")
s2.str.split("_") 
基于cat(),resp。Index.str.cat的方法可以将序列或索引与自身或其他序列或索引连接起来。
Series(或index)的值可以串联:
s = pd.Series(["a", "b", "c", "d"], dtype="string")
s.str.cat(sep=",") ![]()
cat()的第一个参数可以是一个类似列表的对象,只要它匹配调用序列(或索引)的长度。
s.str.cat(["A", "B", "C", "D"])任何一侧的缺失值也会导致结果中的缺失值,除非指定了na_rep:
s.str.cat(t, na_rep="-") 
再下来就不展开讲解了,有兴趣的同学可以去看本人的数据分析专栏。
5.快速图表可视化
一般我们做数据挖掘或者是数据分析,再或者是大数据开发提取数据库里面的数据时候,难免只能拿着表格数据左看右看,内心总是希望能够根据自己所想立马生成一张数据可视化的图表来更直观的呈现数据。而当我们想要进行数据可视化的时候,往往需要调用很多的库与函数,还需要数据转换以及大量的代码处理编写。这都是十分繁琐的工作,确实只为了数据可视化我们不需要实现数据可视化的工程编程,这都是数据分析师以及拥有专业的报表工具来做的事情,日常分析的话我们根据自己的需求直接进行快速出图即可,而Pandas正好就带有这个功能,当然还是依赖matplotlib库的,只不过将代码压缩更容易实现。

那么到这里本篇文章就结束了,Pandas数据分析系列专栏已经更新了很久了,基本覆盖到使用pandas处理日常业务以及常规的数据分析方方面面的问题。从基础的数据结构逐步入门到处理各类数据以及专业的pandas常用函数讲解都花费了大量时间和心思创作,如果大家有需要从事数据分析或者大数据开发的朋友推荐订阅专栏,将在第一时间学习到Pandas数据分析最实用常用的知识。
⭐️ 好书推荐

清华社【秋日阅读企划】领券立享优惠
IT好书 5折叠加10元 无门槛优惠券:https://u.jd.com/Yqsd9wj
活动时间:9月4日-9月17日,先到先得,快快来抢
《Pandas数据分析》

内容简介
《Pandas数据分析》详细阐述了与Pandas数据分析相关的基本解决方案,主要包括数据分析导论、使用PandasDataFrame、使用Pandas进行数据整理、聚合Pandas DataFrame、使用Pandas和Matplotlib可视化数据、使用Seabom和自定义技术绘图、金融分析、基于规则的异常检测、Python机器学习入门、做出更好的预测、机器学习异常检测等内容。此外,该书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
《Pandas数据分析》适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
编辑推荐
Pandas是强大且流行的库,是Python中数据科学的代名词。本书将向你介绍如何使用Pandas对真实世界的数据集进行数据分析,如股市数据、模拟黑客攻击的数据、天气趋势、地震数据、葡萄酒数据和天文数据等。Pandas使我们能够有效地处理表格数据,从而使数据整理和可视化变得更容易。