作者:LUCA WINTERGERST
在本博客中,我们将测试一个使用 OpenAI 的 Python 应用程序并分析其性能以及运行该应用程序的成本。 使用从应用程序收集的数据,我们还将展示如何将 LLMs 成到你的应用程序中。

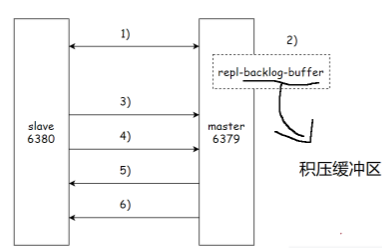
在之前的博客文章中,我们构建了一个小型 Python 应用程序,该应用程序使用向量搜索和 BM25 的组合来查询 Elasticsearch,以帮助在专有数据集中找到最相关的结果。 然后,最热门的结果会传递给 OpenAI,它会为我们解答问题。
在本博客中,我们将测试使用 OpenAI 的 Python 应用程序并分析其性能以及运行该应用程序的成本。 使用从应用程序收集的数据,我们还将展示如何将大型语言模型 (LLM) 集成到你的应用程序中。 作为额外的奖励,我们将尝试回答这个问题:为什么 ChatGPT 逐字打印其输出?
使用 Elastic APM 检测应用程序
如果你有机会尝试我们的示例应用程序,你可能会注意到,从搜索界面加载结果的速度没有你期望的那么快。
现在的问题是,这是否来自我们首先在 Elasticsearch 中运行查询的两阶段方法,或者缓慢的行为是否来自 OpenAI,或者是否是两者的组合。
使用 Elastic APM,我们可以轻松地检测该应用程序以获得更好的外观。 我们需要为检测做的所有事情如下(我们将在博客文章末尾以及 GitHub 存储库中展示完整的示例):
import elasticapm
# the APM Agent is initialized
apmClient = elasticapm.Client(service_name="elasticdocs-gpt-v2-streaming")# the default instrumentation is applied
# this will instrument the most common libraries, as well as outgoing http requests
elasticapm.instrument()由于我们的示例应用程序使用 Streamlit,因此我们还需要启动至少一项 transaction 并最终再次结束它。 此外,我们还可以向 APM 提供有关 transaction 结果的信息,以便我们可以正确跟踪故障。
# start the APM transaction
apmClient.begin_transaction("user-query")(...)elasticapm.set_transaction_outcome("success")# or "failure" for unsuccessful transactions
# elasticapm.set_transaction_outcome("success")# end the APM transaction
apmClient.end_transaction("user-query")就是这样 ---- 这足以为我们的应用程序提供完整的 APM 工具。 话虽这么说,我们将在这里做一些额外的工作,以获得一些更有趣的数据。
第一步,我们将用户的查询添加到 APM 元数据中。 通过这种方式,我们可以检查用户尝试搜索的内容,并可以分析一些流行的查询或重现错误。
elasticapm.label(query=query)在我们与 OpenAI 对话的异步方法中,我们还将添加一些更多的检测,以便我们可以更好地可视化我们收到的 tokens,并收集额外的统计数据。
async with elasticapm.async_capture_span('openaiChatCompletion', span_type='openai'):async for chunk in await openai.ChatCompletion.acreate(engine=engine, messages=[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": truncated_prompt}],stream=True,):content = chunk["choices"][0].get("delta", {}).get("content")# since we have the stream=True option, we can get the output as it comes in# one iteration is one token# we start a new span here for each token. These spans will be aggregated# into a compressed span automaticallywith elasticapm.capture_span("token", leaf=True, span_type="http"):if content is not None:# concatenate the output to the previous one, so have the full response at the endoutput += content# with every token we get, we update the elementelement.markdown(output)最后,在应用程序的最后阶段,我们还将向 APM 交易添加 token 数量和大致成本。 这将使我们能够稍后可视化这些指标并将它们与应用程序性能相关联。
如果你不使用流式传输,则 OpenAI 响应将包含一个 total_tokens 字段,它是你发送的上下文和返回的响应的总和。 如果你使用 stream=True 选项,那么你有责任计算 token 数量或近似数量。 一个常见的建议是对英文文本使用 “(len(prompt) + len(response)) / 4”,但特别是代码片段可能会偏离这种近似值。 如果你需要更准确的数字,你可以使用 tiktoken 等库来计算 token 数量。
# add the number of tokens as a metadata label
elasticapm.label(openai_tokens = st.session_state['openai_current_tokens'])
# add the approximate cost as a metadata label
# currently the cost is $0.002 / 1000 tokens
elasticapm.label(openai_cost = st.session_state['openai_current_tokens'] / 1000 * 0.002)检查 APM 数据 — Elasticsearch 或 OpenAI 哪个更慢?
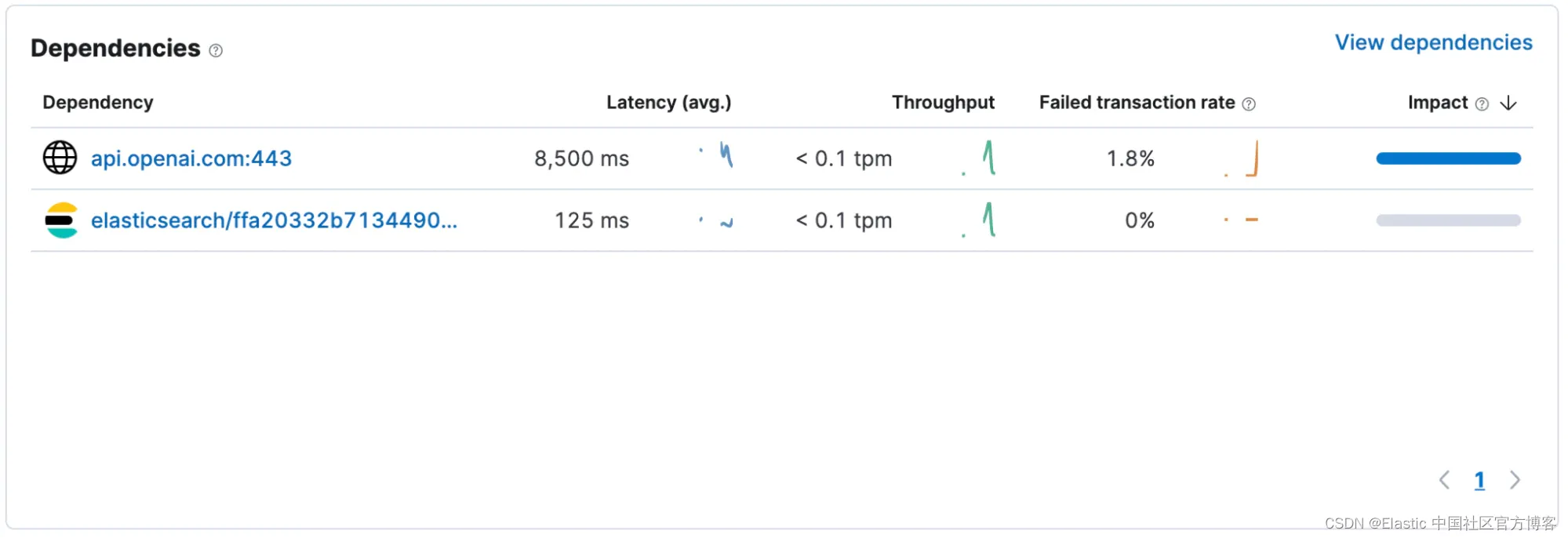
对应用程序进行检测后,快速查看 “Dependencies” 可以让我们更好地了解正在发生的情况。 看起来我们对 Elasticsearch 的请求平均在 125 毫秒内返回,而 OpenAI 需要 8,500 毫秒才能完成请求。 (此屏幕截图是在不使用流式传输的应用程序版本上拍摄的。如果你使用流式传输,则默认检测仅考虑依赖项响应时间中的初始 POST 请求,而不考虑流式传输完整响应所需的时间。)
如果你自己已经使用过 ChatGPT,你可能想知道为什么 UI 单独打印每个单词,而不是立即返回完整的响应。
事实证明,如果你使用免费版本,这实际上并不是为了诱使你付费! 这更多的是推理模型的限制。 简而言之,为了计算下一个 token,模型还需要考虑最后一个 token。 所以并行化的空间不大。 由于每个 token 都是单独处理的,因此在运行下一个 token 的计算时,该 token 也可以发送到客户端。
为了改善用户体验,在使用 ChatCompletion 功能时使用流式方法会很有帮助。 这样,用户可以在生成完整响应的同时开始使用第一个结果。 你可以在下面的 GIF 中看到这种行为。 即使所有三个响应仍在加载,用户也可以向下滚动并检查已有的内容。
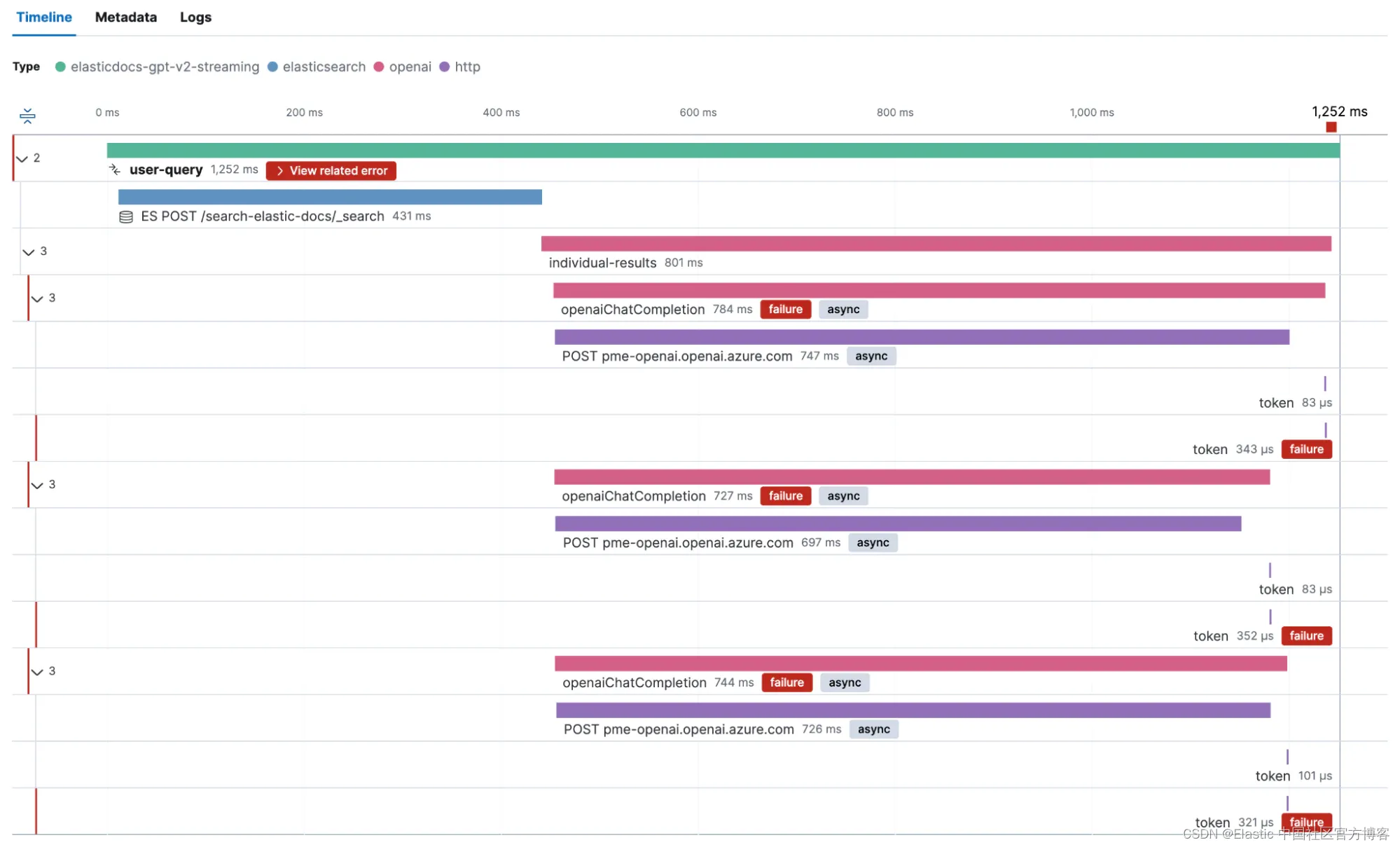
如前所述,我们添加了比最低限度更多的自定义检测。 这使我们能够获得有关我们的时间花在哪里的详细信息。 让我们看一下完整的跟踪,看看这个流的实际情况。
我们的应用程序配置为从 Elasticsearch 获取前三名点击,然后针对 OpenAI 并行运行一个 ChatCompletion 请求。
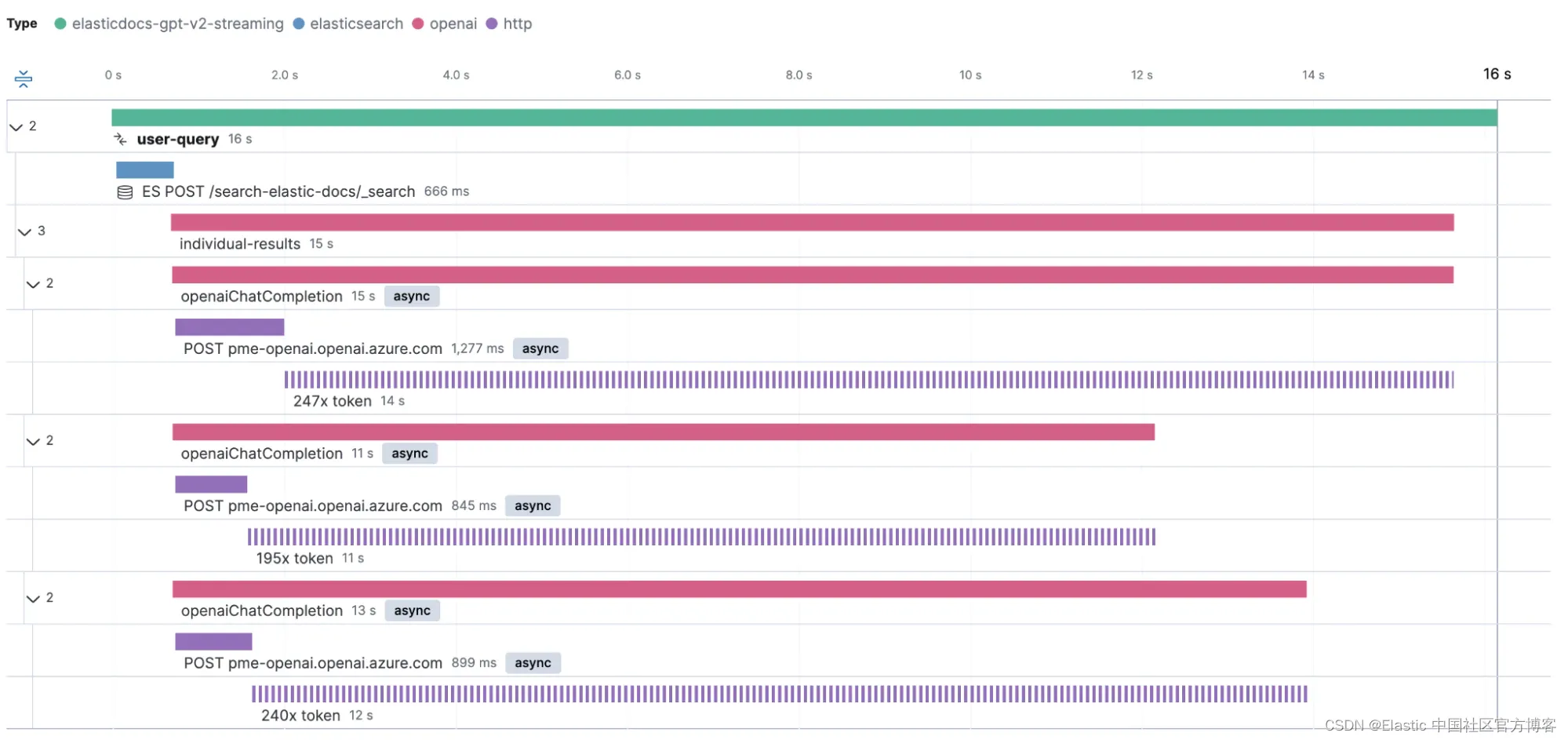
正如我们在屏幕截图中看到的,加载单个结果大约需要 15 秒。 我们还可以看到,返回较大响应的 OpenAI 请求需要更长的时间才能返回。 但这只是一个请求。 所有请求都会发生这种行为吗? 响应时间和支持我们之前主张的 token 数量之间是否存在明显的相关性?
分析成本和响应时间
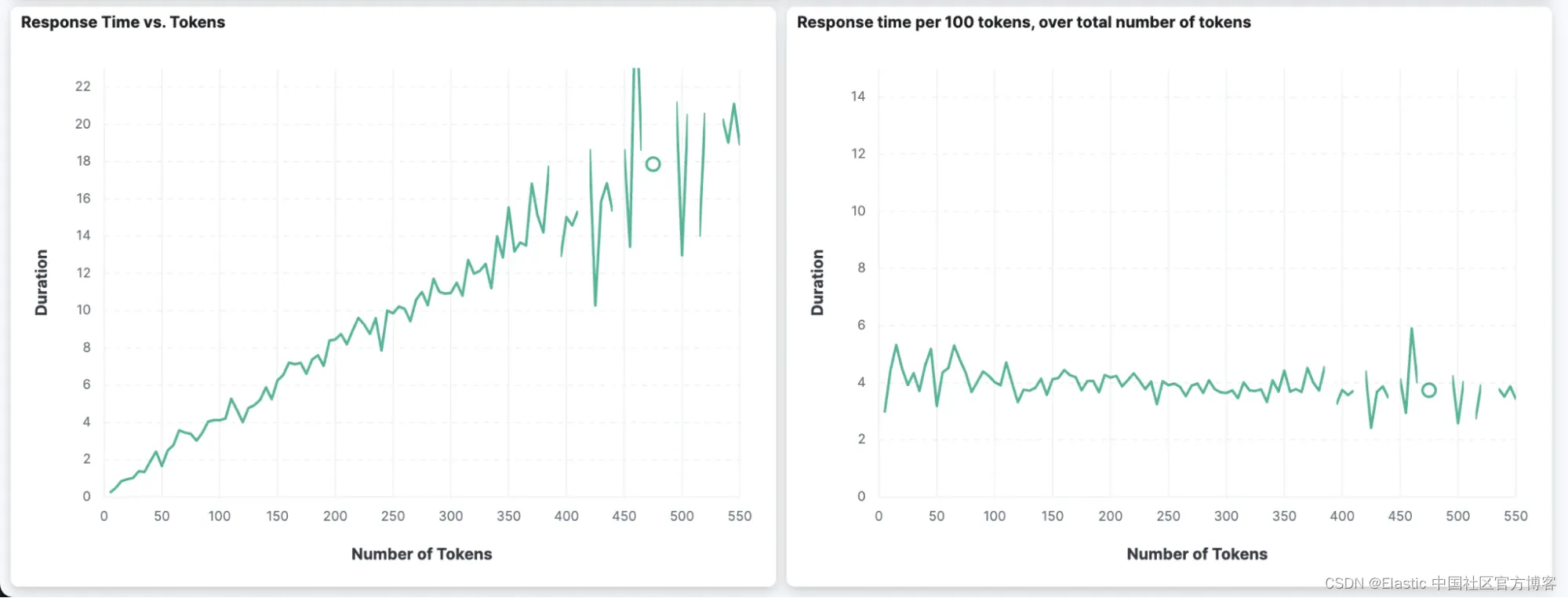
我们还可以使用自定义仪表板并根据 APM 数据创建可视化效果,而不是使用 Elastic APM 来可视化数据。 我们可以构建两个有趣的图表,显示响应中的 token 数量与请求持续时间之间的关系。
我们可以看到返回的 token 越多(第一个图表中的 x 轴),持续时间就越长(第一个图表中的 y 轴)。 在右图中,我们还可以看到,无论返回的 token 总数(x 轴)有多少,每返回 100 个 token 的持续时间几乎保持在 4 秒左右。
如果你想提高使用 OpenAI 模型的应用程序的响应能力,最好告诉模型保持简短的响应。
除此之外,我们还可以跟踪我们的总支出和每个页面加载的平均成本,以及其他统计数据。
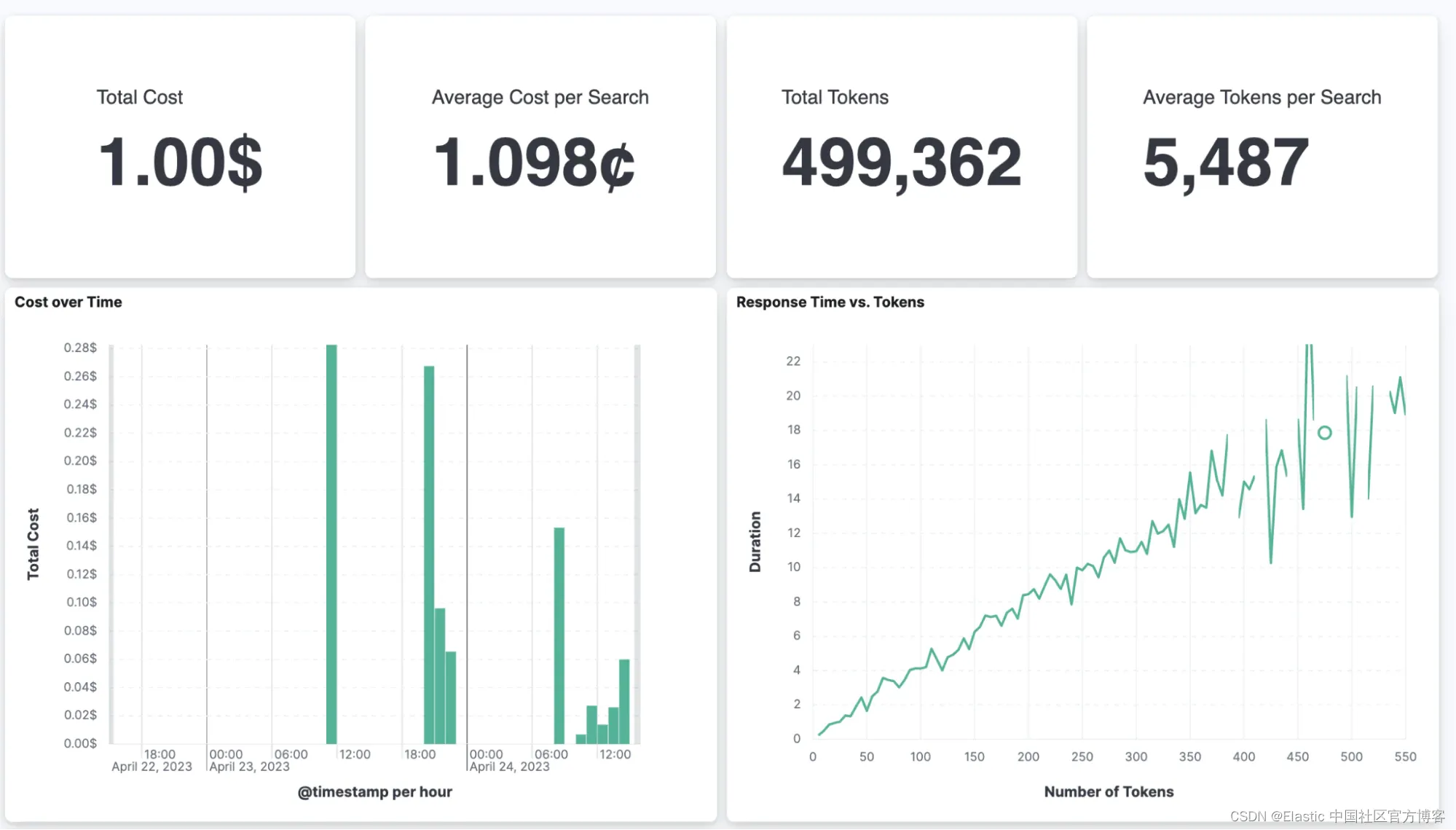
对于我们的示例应用程序,单次搜索的成本约为 1.1 美分。 这个数字听起来并不高,但它可能不会很快出现在你的公共网站上作为搜索选项。 对于公司内部数据和偶尔使用的搜索界面来说,这个成本可以忽略不计。
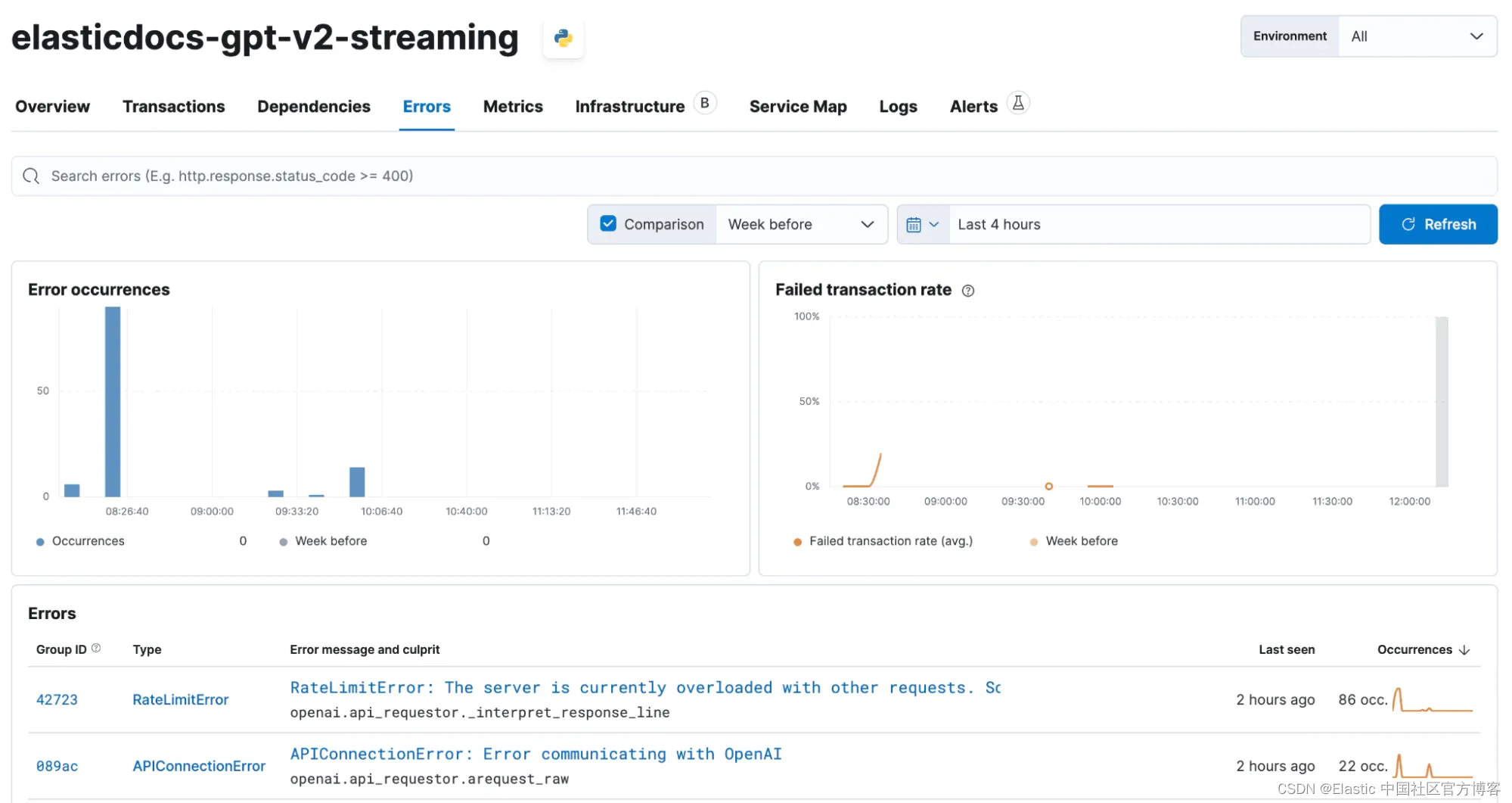
在我们的测试中,我们在 Azure 中使用 OpenAI API 时也经常遇到错误,这最终导致我们向示例应用程序添加了一个具有指数退避的重试循环。 我们还可以使用 Elastic APM 捕获这些错误。
while tries < 5:try:print("request to openai for task number: " + str(index) + " attempt: " + str(tries))async with elasticapm.async_capture_span('openaiChatCompletion', span_type='openai'):async for chunk in await openai.ChatCompletion.acreate(engine=engine, messages=[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": truncated_prompt}],stream=True,):content = chunk["choices"][0].get("delta", {}).get("content")counter += 1with elasticapm.capture_span("token", leaf=True, span_type="http"):if content is not None:output += contentelement.markdown(output)breakexcept Exception as e:client = elasticapm.get_client()# capture the exception using Elastic APM and send it to the apm serverclient.capture_exception()tries += 1time.sleep(tries * tries / 2)if tries == 5:element.error("Error: " + str(e))else:print("retrying...")然后,任何捕获的错误都会在瀑布图中可见,作为发生故障的跨度的一部分。
此外,Elastic APM 还提供所有错误的概述。 在下面的屏幕截图中,你可以看到我们偶尔遇到的 RateLimitError 和 APIConnectionError。 使用我们粗略的指数重试机制,我们可以缓解大多数此类问题。
延迟和失败的 transaction 关联
借助 Elastic APM 代理捕获的所有内置元数据以及我们添加的自定义标签,我们可以轻松分析性能与任何元数据(如服务版本、用户查询等)之间是否存在任何相关性。
如下所示,查询 “How can I mount and index on a frozen node?” 之间存在很小的相关性。 和较慢的响应时间。
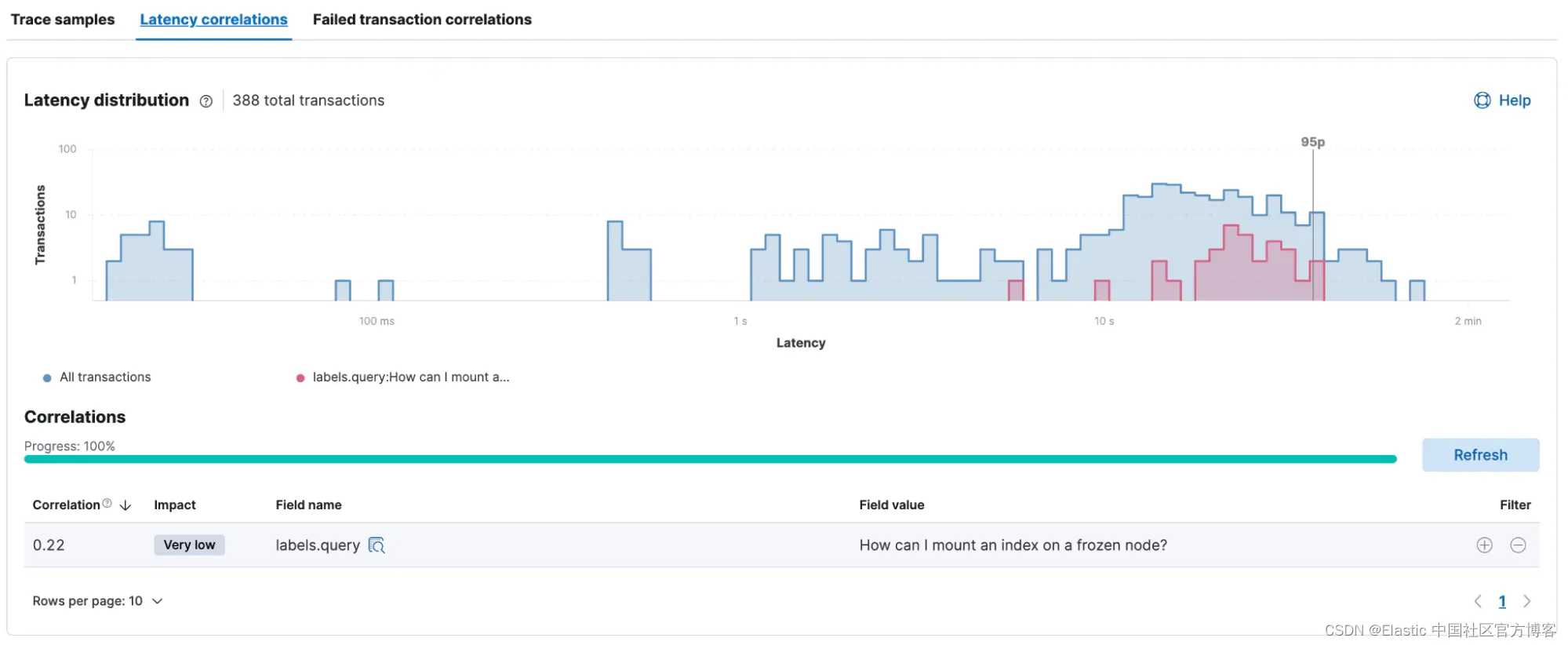
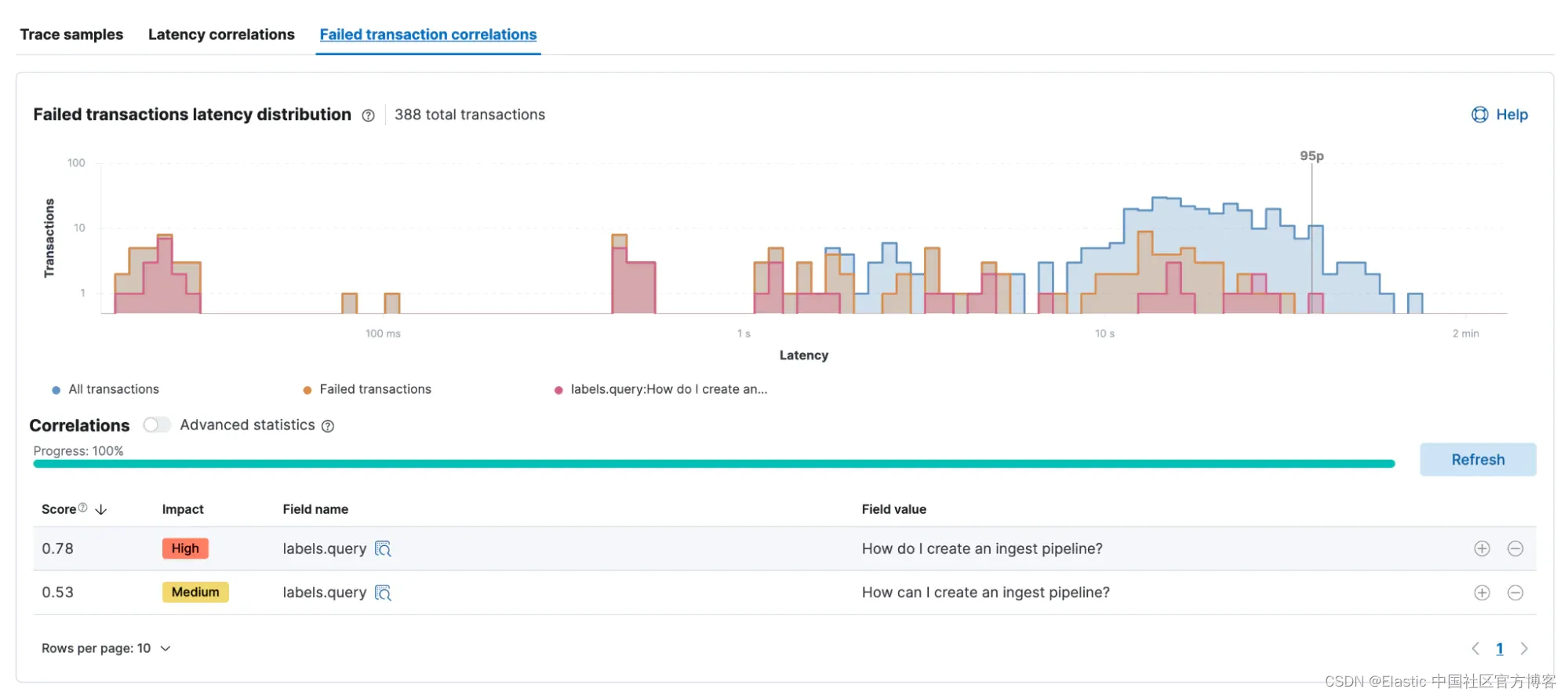
可以对任何导致错误的事务进行类似的分析。 在此示例中,“How do I create an ingest pipeline” 这两个查询比其他查询更频繁地失败,导致它们在此相关性分析中脱颖而出。
import elasticapm
# the APM Agent is initialized
apmClient = elasticapm.Client(service_name="elasticdocs-gpt-v2-streaming")# the default instrumentation is applied
# this will instrument the most common libraries, as well as outgoing http requests
elasticapm.instrument()# if a user clicks the "Search" button in the UI
if submit_button:# start the APM transaction
apmClient.begin_transaction("user-query")
# add custom labels to the transaction, so we can see the users question in the API UI
elasticapm.label(query=query)async with elasticapm.async_capture_span('openaiChatCompletion', span_type='openai'):async for chunk in await openai.ChatCompletion.acreate(engine=engine, messages=[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": truncated_prompt}],stream=True,):content = chunk["choices"][0].get("delta", {}).get("content")# since we have the stream=True option, we can get the output as it comes in# one iteration is one tokenwith elasticapm.capture_span("token", leaf=True, span_type="http"):if content is not None:# concatenate the output to the previous one, so have the full response at the endoutput += content# with every token we get, we update the elementelement.markdown(output)
async def achat_gpt(prompt, result, index, element, model="gpt-3.5-turbo", max_tokens=1024, max_context_tokens=4000, safety_margin=1000):output = ""# we create on overall Span here to track the total process of doing the completionasync with elasticapm.async_capture_span('openaiChatCompletion', span_type='openai'):async for chunk in await openai.ChatCompletion.acreate(engine=engine, messages=[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": truncated_prompt}],stream=True,):content = chunk["choices"][0].get("delta", {}).get("content")# since we have the stream=True option, we can get the output as it comes in# one iteration is one token, so we create one small span for eachwith elasticapm.capture_span("token", leaf=True, span_type="http"):if content is not None:# concatenate the output to the previous one, so have the full response at the endoutput += content# with every token we get, we update the elementelement.markdown(output)在本博客中,我们测试了一个用 Python 编写的应用程序,以使用 OpenAI 并分析其性能。 我们研究了响应延迟和失败的事务,并评估了运行应用程序的成本。 我们希望本指南对你有用!
详细了解 Elasticsearch 和 AI 的可能性。
在这篇博文中,我们可能使用了第三方生成式人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对您使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。 你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
本文提到的成本基于当前 OpenAI API 定价以及我们在加载示例应用程序时调用它的频率。
Elastic、Elasticsearch 和相关标志是 Elasticsearch N.V. 的商标、徽标或注册商标。 在美国和其他国家。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:ChatGPT and Elasticsearch: APM instrumentation, performance, and cost analysis — Elastic Search Labs