基于图搜索路径规划-JPS
关注晓理紫并回复jps获取代码
[晓理紫]
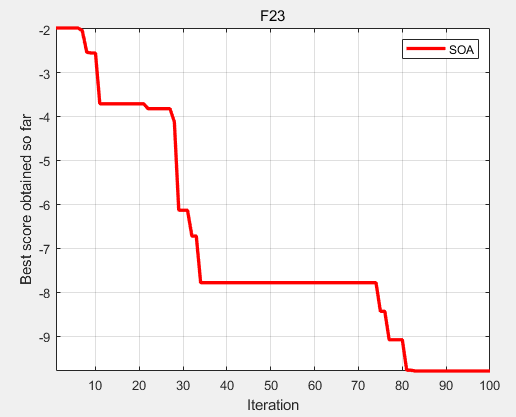
1、 Jump Point Search(跳点搜索)
核心:寻找到规划中的对称性 Path 并打破他们,从而避免扩展大量无用节点。
| A*搜索的节点 | JPS 搜索的节点 |
|---|---|
 | |
 | |
1.1 概念
-
强迫邻居
- 节点 x 的 8 个邻居中有障碍,且 x 的父节点 p 经过 x 到达 n 的距离代价比不经过 x 到达的 n 的任意路径的距离代价小,则称 n 是 x 的强迫邻居。(直观来说,实际就是因为前进方向(父节点到 x 节点的方向为前进方向)的某一边的靠后位置有障碍物,因此想要到该边靠前的空位有最短的路径,就必须得经过过 x 节点。)
| 直线强迫邻居(红圈) | 对角线强迫邻居(红圈) |
|---|---|
 | |
 | |
-
邻居修剪
- 如果其他节点可以通过 x 的父节点直接到达,并且路径的代价小于通过 x 到达的路径代价则没有必要通过 x 进行到达。对于 x 来说这些邻居是不需要的。:4->2 代价是根号 2,4->x->2 的代价是 2.

灰色节点:较差的邻居,当去它们时,没有 𝑥 的路径更便宜。 丢弃。
白色节点:自然邻居。当扩展搜索时,我们只需要考虑自然邻居。
-
跳点
- 如果点 y 是起点或目标点,则 y 是跳点
- 如果 y 有邻居且是强迫邻居则 y 是跳点, 从上文强迫邻居的定义来看 neighbor 是强迫邻居,current 是跳点,二者的关系是伴生的
- 如果 父节点到 y 是对角线移动,并且 y 经过水平或垂直方向移动可以到达跳点,则 y 是跳点。
下图举个例子,由于黄色节点的父节点是在斜方向,其对应分解成向上和向右两个方向,因为在右方向发现一个蓝色跳点,需要通过黄色节点到达跳跃点,因此黄色节点也应被判断为跳点:

1.2 实现原理
JPS 算法和 A* 算法非常相似,步骤大概如下:
1、openlist取一个权值最低的节点,然后开始搜索。(这些和A*是一样的)
2、搜索时,先进行 直线搜索(4个方向,跳跃搜索),然后再 斜向搜索(4个方向,只搜索一步)。如果期间某个方向搜索到跳点或者碰到障碍(或边界),则当前方向完成搜索,若有搜到跳点就添加进openlist。# 跳跃搜索是指沿直线方向一直搜下去(可能会搜到很多格),直到搜到跳点或者障碍(边界)。一开始从起点搜索,会有4个直线方向(上下左右),要是4个斜方向都前进了一步,此时直线方向会有8个。3、若斜方向没完成搜索,则斜方向前进一步,重复上述过程。# 因为直线方向是跳跃式搜索,所以总是能完成搜索。4、若所有方向已完成搜索,则认为当前节点搜索完毕,将当前节点移除于openlist,加入closelist。
5、重复取openlist权值最低节点搜索,直到openlist为空或者找到终点。
下面结合图片更好说明过程 2 和 3:首先我们从 openlist 取出绿色的节点,作为搜索的开始,先进行上方向,右方向的直线搜索,再斜向搜索,没有找到任何跳点。

斜方向前进一步后,在此点重复直线搜索和斜向搜索过程,仍没发现跳点。

斜方向前进两步后,重复直线搜索和斜向搜索过程,仍没发现跳点。

斜方向前进了三步后(假设当前位置为 x),在水平直线搜索上发现了一个跳点(紫色节点为强迫邻居)。

于是 x 也被判断为跳点,添加进 openlist。斜方向结束,绿色节点的搜索过程也就此结束,被移除于 openlist,放入 closelist。

1.3 代码框架
JPS 与 A*的代码框架是一样的,只是在搜索邻居时有所不同。
1、维护一个优先级队列,存放所有需要扩容的节点(OpenList)
2、所有节点的启发式函数 h(n) 都是预先定义的(可采用曼哈顿距离, 欧氏距离等)
3、优先级队列初始化为起始状态 $X_s$(OpenList.push($X_s$))
4、为图中的所有其他节点分配 g($X_s$)=0 和 g(n)=无穷大
5、循环(直到队列为空或者找到目标节点))如果队列为空,则返回FALSE; 返回;从优先级队列中删除 f(n)=g(n)+h(n) #最低的节点“n”(h(0)==0时是Dijkstra算法,g(n)==0时是贪心算法)将节点“n”标记为已展开 #将n加入ClosedList中对于节点“n”的所有未扩展邻居“m”如果 g(m) = 无穷大 #说明未扩展g(m)= g(n) + Cnm #(从起点到n节点的代价g(n)+从n节点到m节点的代价)将节点“m”推入队列 #OpenList.push(m)如果 g(m) > g(n) + Cnmg(m)= g(n) + Cnm #说明已经访问过,只修改g值不加入openList中6、结束循环
1.4、示例过程
1、假设起点为绿色节点,终点为红色节点。

2、重复直线搜索和斜向搜索过程,斜方向前进了 3 步。在第 3 步判断出黄色节点为跳点(依据是水平方向有其它跳点),将黄色跳点放入 openlist,然后斜方向搜索完成,绿色节点移除于 openlist,放入 closelist。

3、对 openlist 下一个权值最低的节点(即黄色节点)开启搜索,在直线方向上发现了蓝色节点为跳点(依据是紫色节点为强迫邻居),类似地,放入 openlist。

4、由于斜方向还没结束,继续前进一步。最后一次直线搜索和斜向搜索都碰到了边界,因此黄色节点搜索完成,移除于 openlist,放入 closelist

5、对 openlist 下一个权值最低的节点(原为蓝色节点,下图变为黄色节点)开启搜索,直线搜索碰到边界,斜向搜索无果。斜方继续前进一步,仍然直线搜索碰到边界,斜向搜索无果

6、由于斜方向还没结束,继续前进一步

7、最终在直线方向上发现了红色节点为跳点,因此蓝色节点先被判断为跳点,只添加蓝色节点进 openlist。斜方向完成,黄色节点搜索完成。

8、最后 openlist 取出的蓝色节点开启搜索,在水平方向上发现红色节点,判断为终点,算法完成。
注意点:JPS 在复杂环境下要比 A*快很多,但是但机器人视角较小的情况下性能会下降不一定会比 A*要快,而且只针对网格地图的寻路,非常适合作为于 2D 网格地图型寻路手段。
2、JPS+(Jump Point Search Plus)
JPS+ 是在 JPS 寻路基础之上加上了预处理来改进,从而使寻路更加快速。
2.1、预处理
先对地图每个节点进行跳点判断,找出所有主要跳点:

然后对每个节点进行跳点的直线可达性判断,并记录好跳点直线可达性

若可达还需记录号跳点直线距离

类似地,对每个节点进行跳点斜向距离的记录

剩余各个方向如果不可到达跳点的数据记为 0 或负数距离。如果在对应的方向上移动 1 步后碰到障碍(或边界)则记为 0,如果移动 n+1 步后会碰到障碍(或边界)的数据记为负数距离-n
最后每个节点的 8 个方向都记录完毕,便完成了 JPS+的预处理过程

2.2、示例过程
做好了地图的预处理之后,就可以使用 JPS+算法了。大致思路与 JPS 算法相同,不过这次有了预处理的数据,可以更快的进行直线搜索和斜向搜索。
在某个搜索方向上有:
-
对于正数距离 n(意味着距离跳点 n 格),我们可以直接将 n 步远的节点作为跳点添加进 openlist
-
对于 0 距离(意味着一步都不可移动),我们无需在该方向搜索;
-
对于负数距离 -n(意味着距离边界或障碍 n 格),我们直接将 n 步远的节点进行一次跳点判断(有可能满足跳点的第三条件,不过得益于预处理的数据,这步也可以很快完成)。
如下图示,起始节点通过已记录的向上距离,直接将 3 步远的跳点添加进 openlist,而不再像以前需要迭代三步(还每步都要判断是否跳点)

其它过程也是类似的:


2.3, 总结
可以看到 JPS/JPS+ 算法里只有跳点才会被加入 openlist 里,排除了大量不必要的点,最后找出来的最短路径也是由跳点组成。这也是 JPS/JPS+ 高效的主要原因。
-
JPS :
-
绝大部分地图,使用 JPS 算法都会比 A* 算法更快,内存占用也更小(openlist 里节点少了很多)。
-
JPS 在跳点判断上,要尽可能避免递归的深度过大(或者期待一下以后出现避免递归的算法),否则在超大型的地图里递归判断跳点可能会造成灾难。
-
JPS 也可以用于动态变化的地图,只是每次地图改变都需要再进行一次 JPS 搜索。
-
JPS 天生拥有合并节点(亦或者说是在一条直线里移除中间不必要节点)的功能,但是仍存在一些可以继续合并的地方。
-
JPS 只适用于 网格(grid)节点类型,不支持 Navmesh 或者路径点(Way Point)。
-
-
JPS+ :
-
JPS+ 相比 JPS 算法又是更快上一个档次(特别是避免了过多层递归判断跳点),内存占用则是每个格子需要额外记录 8 个方向的距离数据。
-
JPS+ 算法由于包含预处理过程,这让它面对动态变化的地图有天生的劣势(几乎是不可以接受动态地图的),因此更适合用于静态地图。
-
JPS+ 预处理的复杂度为 O(n),n 代表地图格子数。
-
对比:
| Dijkstra | A* | JPS |
|---|---|---|
 | ||
 | ||
 | ||
3 代码获取方式
关注晓理紫并回复有jps获取代码
{晓理紫|小李子}喜分享,也很需要你的支持,喜欢留下痕迹哦!