文章目录
- 一、MoCo v3
- 二、AmoebaNet
- 三、Residual Multi-Layer Perceptrons
- 四、FractalNet
- 五、LV-ViT
- 六、RepVGG
- 七、Transformer in Transformer
- 八、SimpleNet
- 九、SpineNet
- 十、Bottleneck Transformer
- 十一、ZFNet
- 十二、DetNet
- 十三、Invertible Rescaling Network
- 十四、SNet
- 十五、Focal Transformers
一、MoCo v3


二、AmoebaNet
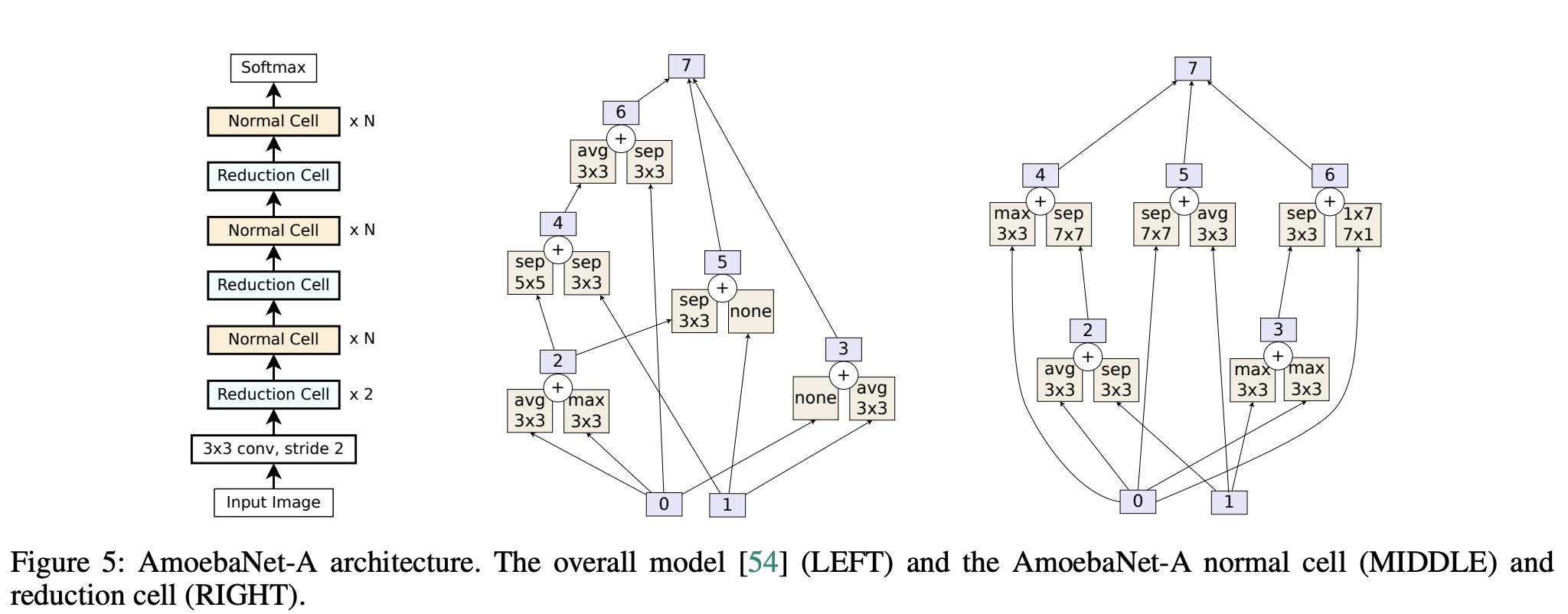
AmoebaNet 是通过正则化进化架构搜索发现的卷积神经网络。 搜索空间是 NASNet,它指定具有固定外部结构的图像分类器空间:称为单元的类似 Inception 的模块的前馈堆栈。 发现的架构如右图所示。
三、Residual Multi-Layer Perceptrons
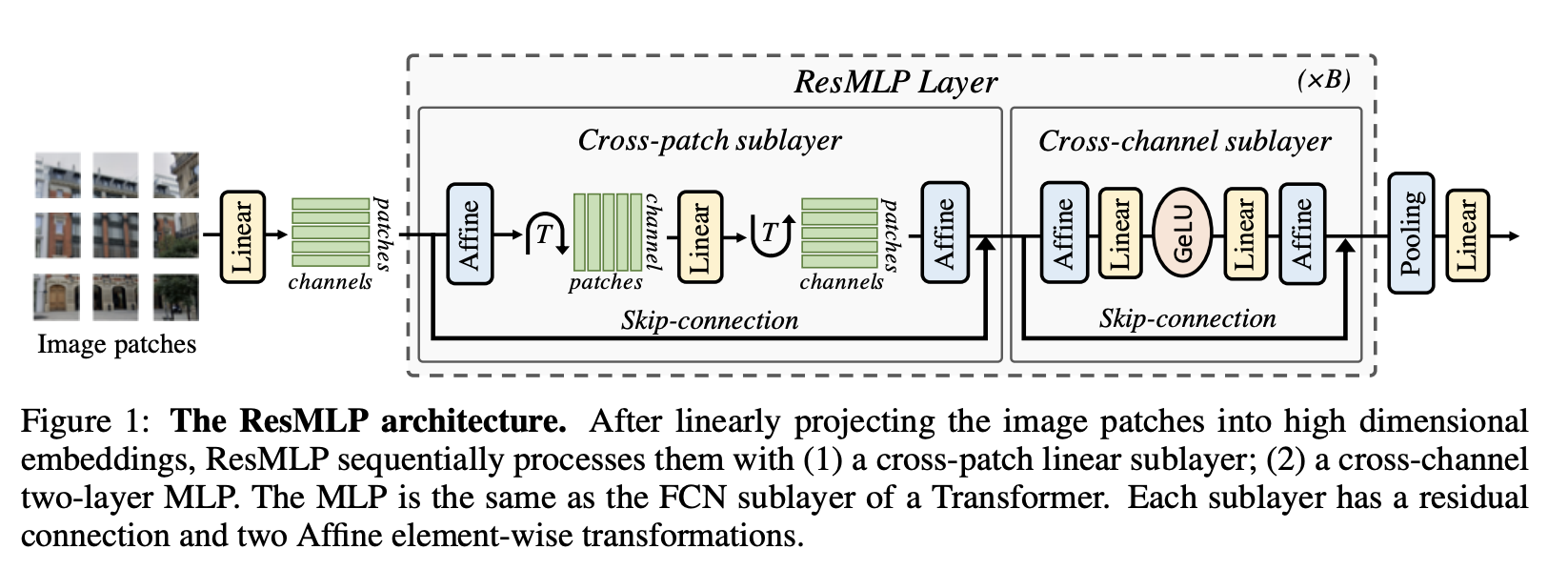
残差多层感知器(ResMLP)是一种完全基于多层感知器构建的图像分类架构。 它是一个简单的残差网络,交替出现 (i) 线性层,其中图像块在通道之间独立且相同地交互,以及 (ii) 两层前馈网络,其中通道每个块独立交互。 在网络的末端,补丁表示被平均池化,并馈送到线性分类器。
由于没有自注意力层,层归一化被更简单的仿射变换所取代,这使得训练更加稳定。 仿射算子应用于每个残差块的开始(“预归一化”)和结束(“后归一化”)。 作为预归一化,Aff 取代了 LayerNorm,而不使用通道统计。
四、FractalNet
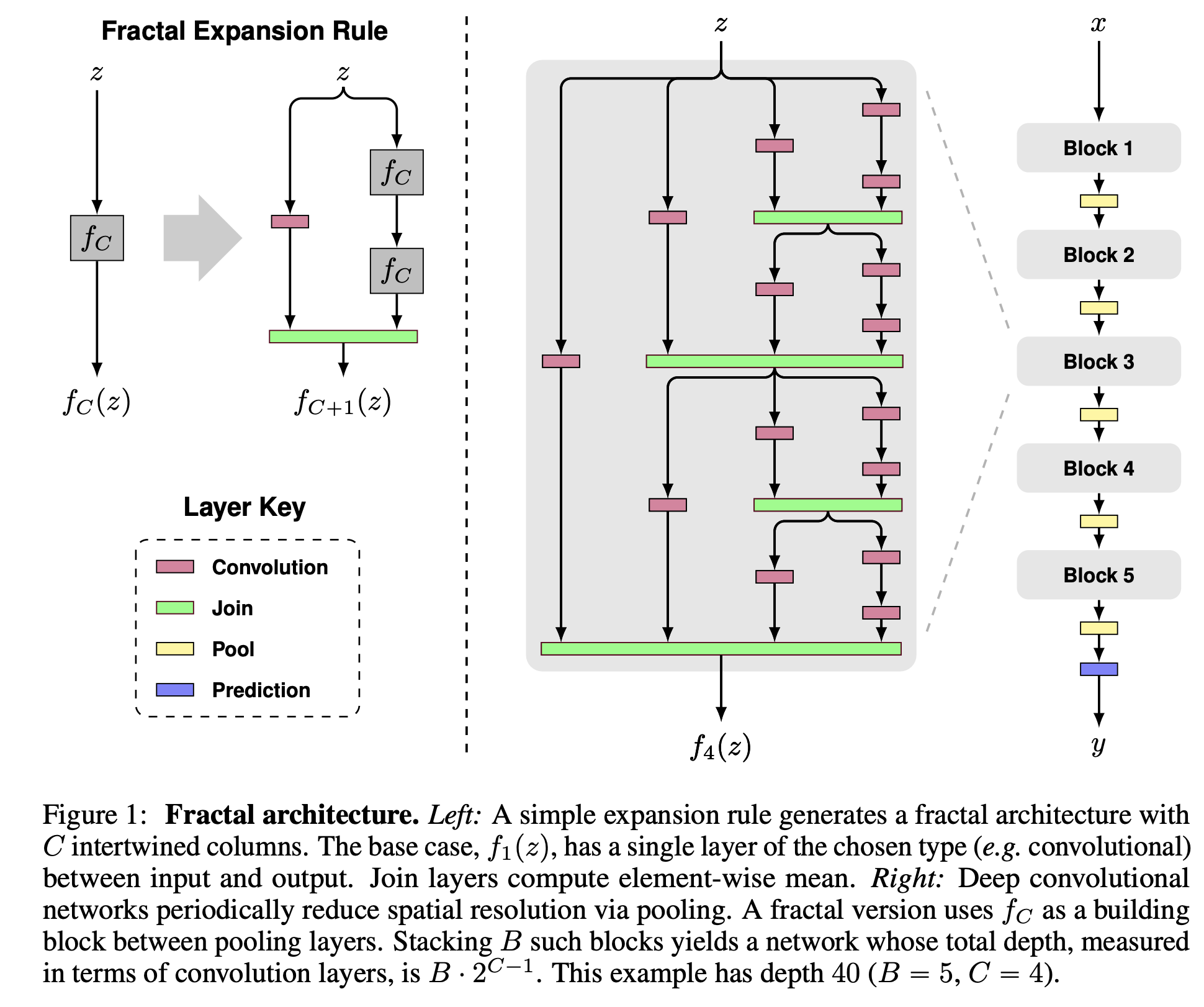
FractalNet 是一种卷积神经网络,它避开残差连接,转而采用“分形”设计。 它们涉及重复应用简单的扩展规则来生成其结构布局是精确截断的分形的深层网络。 这些网络包含不同长度的交互子路径,但不包括任何直通或残余连接; 每个内部信号在被后续层看到之前都经过滤波器和非线性变换。
五、LV-ViT
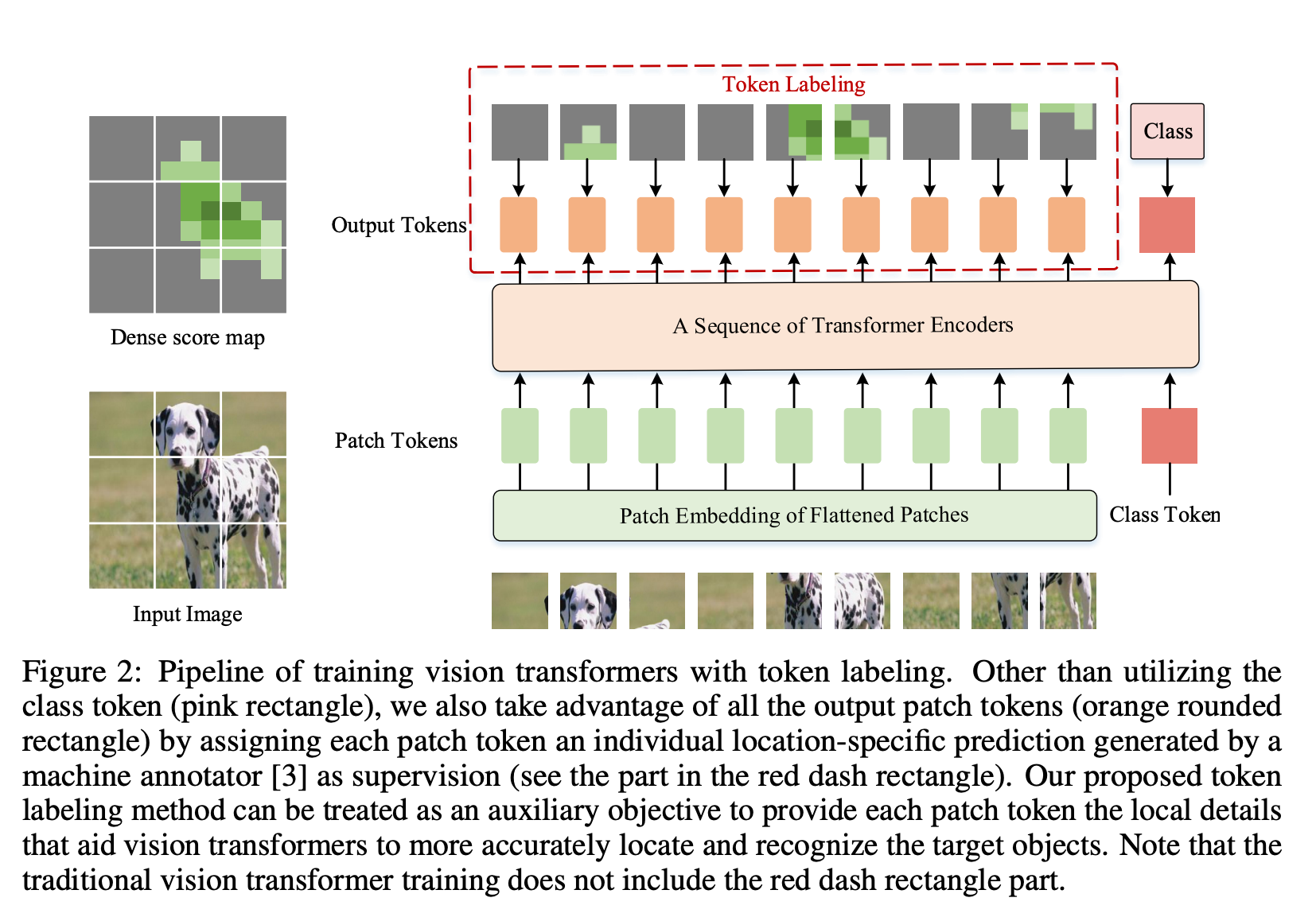
LV-ViT 是一种视觉转换器,使用标记标签作为训练目标。 与 ViT 的标准训练目标不同,ViT 的标准训练目标是在额外的可训练类标记上计算分类损失,标记标记利用所有图像块标记以密集的方式计算训练损失。 具体来说,标记标记将图像分类问题重新表述为多个标记级识别问题,并为每个补丁标记分配由机器注释器生成的单独位置特定的监督。
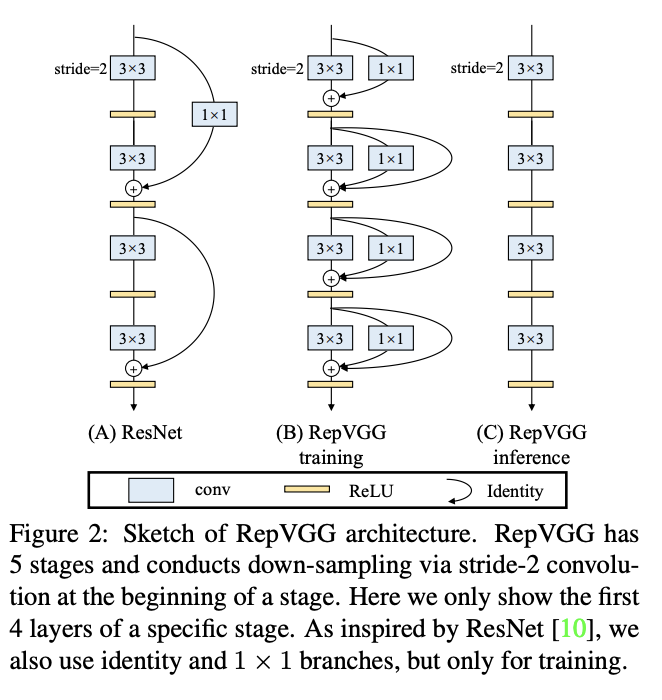
六、RepVGG
RepVGG 是一种 VGG 风格的卷积架构。 它具有以下优点:
该模型具有类似 VGG 的普通(又称前馈)拓扑 1,没有任何分支。 即,每一层都将其唯一的前一层的输出作为输入,并将输出馈送到其唯一的下一层。
该模型的主体仅使用 3 × 3 卷积和 ReLU。
具体架构(包括特定深度和层宽度)是在没有自动搜索、手动细化、复合缩放或其他繁重设计的情况下实例化的。
七、Transformer in Transformer
Transformer 是一种最初应用于 NLP 任务的基于自注意力的神经网络。 最近,提出了纯基于变压器的模型来解决计算机视觉问题。 这些视觉转换器通常将图像视为一系列补丁,而忽略每个补丁内部的内在结构信息。 在本文中,我们提出了一种新颖的 Transformer-iN-Transformer (TNT) 模型,用于对块级和像素级表示进行建模。 在每个 TNT 块中,外部变压器块用于处理补丁嵌入,内部变压器块从像素嵌入中提取局部特征。 像素级特征通过线性变换层投影到补丁嵌入的空间,然后添加到补丁中。 通过堆叠 TNT 块,我们构建了用于图像识别的 TNT 模型。

八、SimpleNet
SimpleNet 是一个 13 层的卷积神经网络。 该网络采用同构设计,利用 3 × 3 内核进行卷积层,使用 2 × 2 内核进行池化操作。 唯一不使用 3 × 3 内核的层是第 11 层和第 12 层,这些层使用 1 × 1 卷积核。 特征图下采样是使用非重叠 2 × 2 最大池进行的。 为了解决梯度消失和过拟合问题,SimpleNet 还在任何 ReLU 非线性之前使用了移动平均分数为 0.95 的批量归一化。
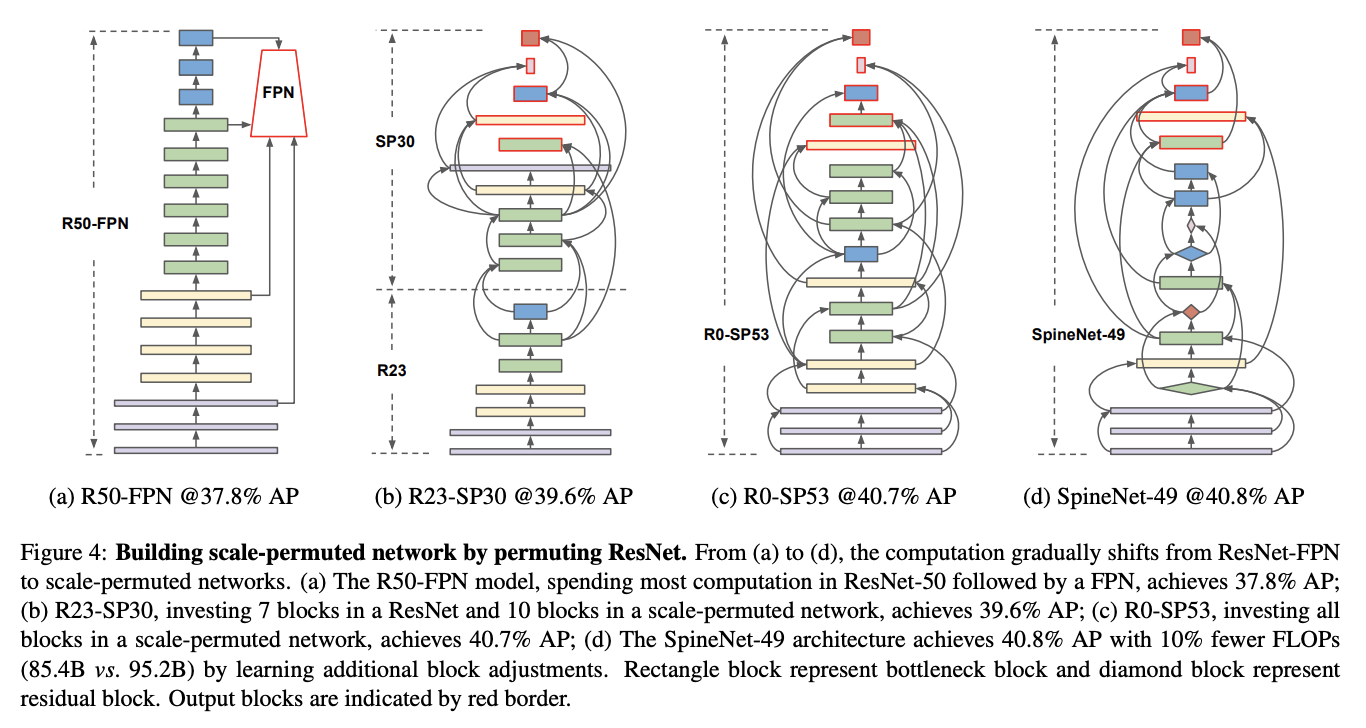
九、SpineNet
SpineNet 是一个卷积神经网络主干,具有尺度排列的中间特征和跨尺度连接,是通过神经架构搜索在对象检测任务中学习到的。
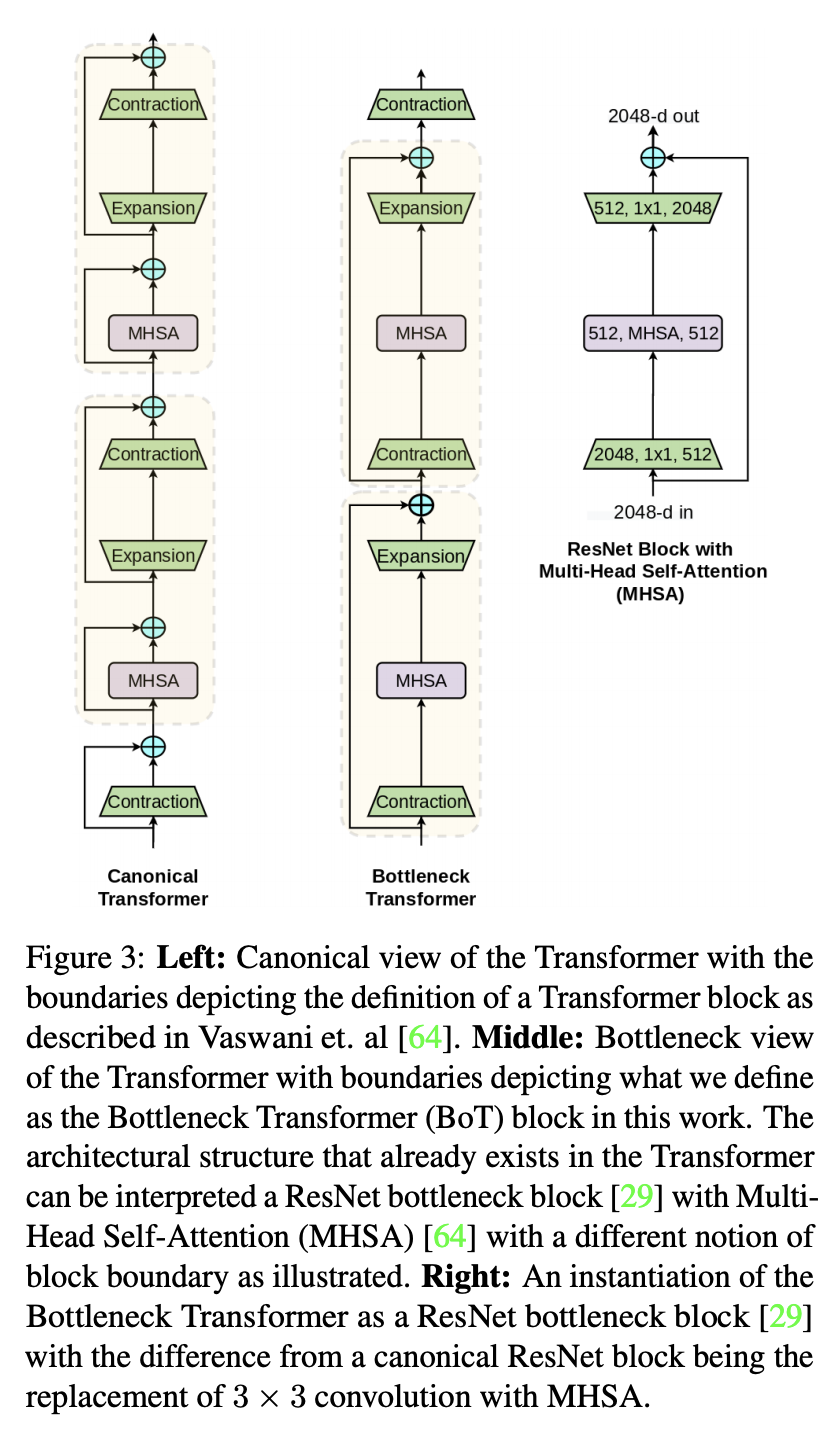
十、Bottleneck Transformer
Bottleneck Transformer (BoTNet) 是一种图像分类模型,它结合了多种计算机视觉任务的自注意力,包括图像分类、对象检测和实例分割。 通过仅在 ResNet 的最后三个瓶颈块中将空间卷积替换为全局自注意力,并且没有其他任何更改,该方法在实例分割和对象检测方面显着改进了基线,同时还减少了参数,并且延迟开销最小。
十一、ZFNet
ZFNet是一个经典的卷积神经网络。 该设计的动机是可视化中间特征层和分类器的操作。 与 AlexNet 相比,滤波器尺寸减小,卷积步长也减小。
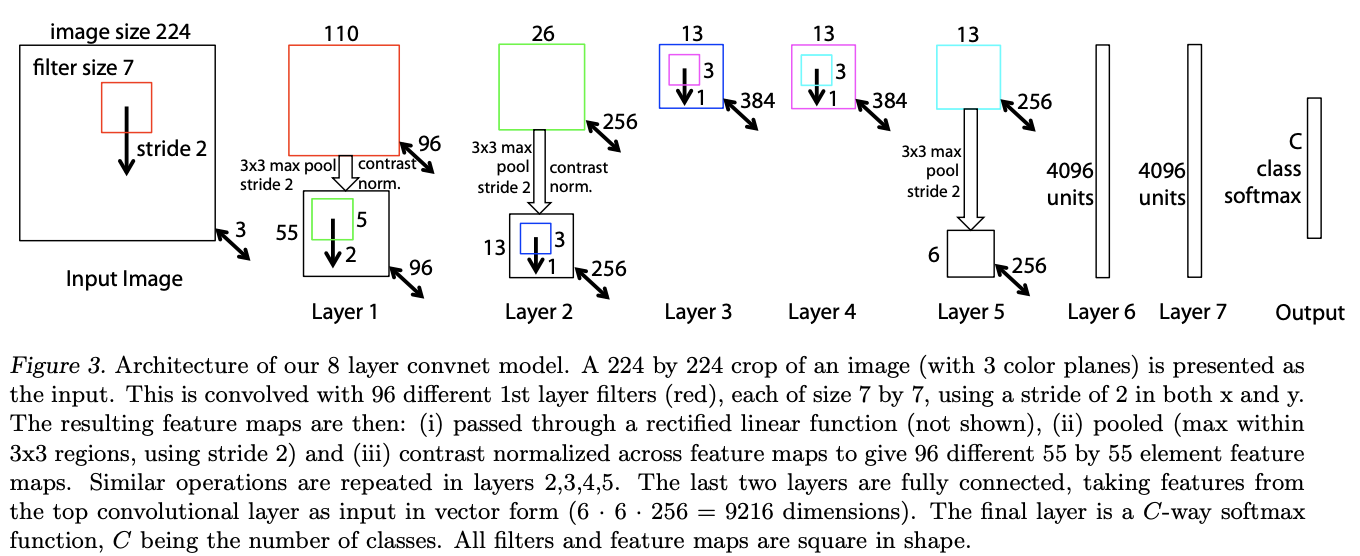
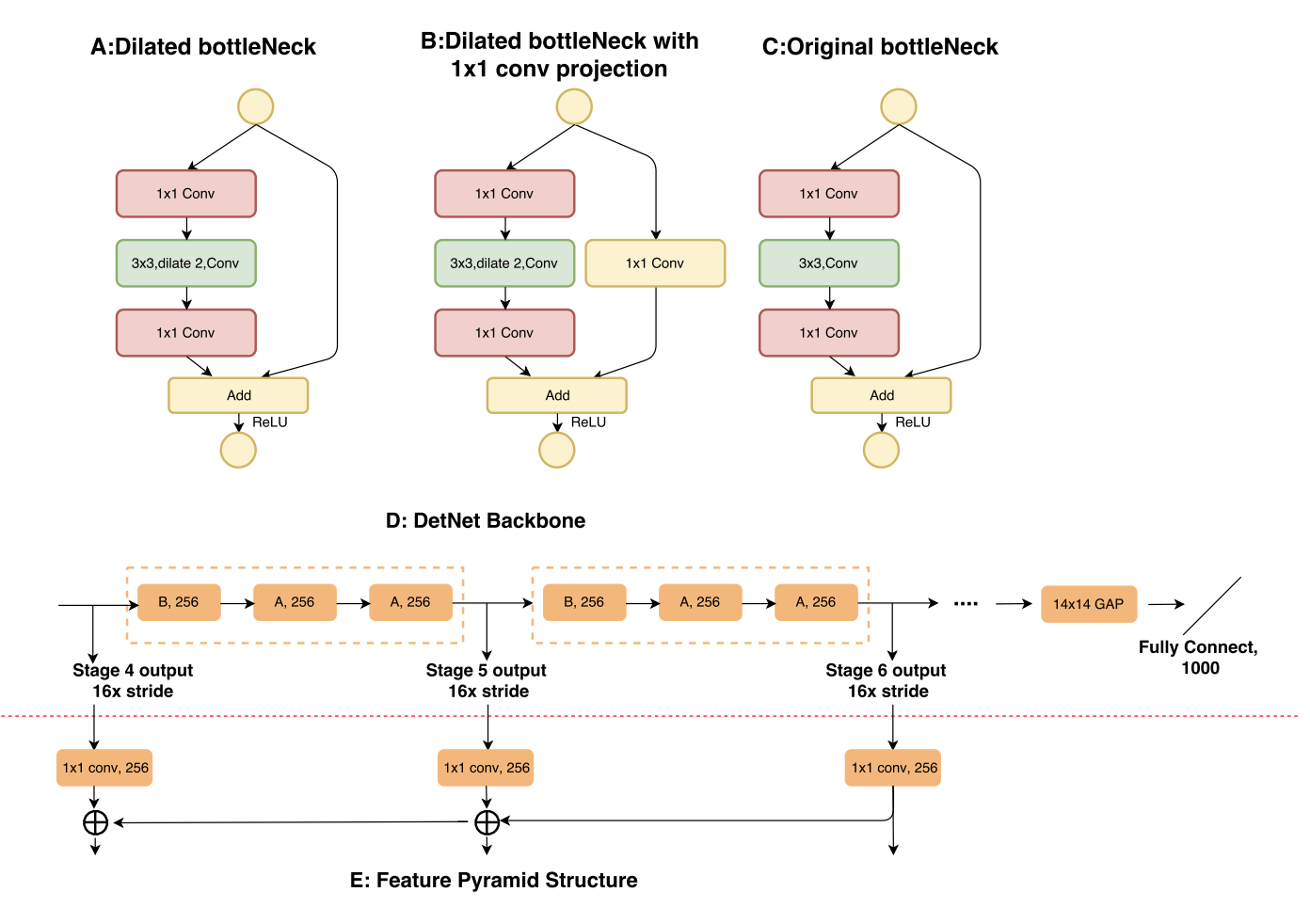
十二、DetNet
DetNet 是用于目标检测的主干卷积神经网络。 与传统的 ImageNet 分类预训练模型不同,DetNet 即使包含额外的阶段也能保持特征的空间分辨率。 DetNet 尝试通过采用低复杂度的扩张瓶颈结构来保持效率。
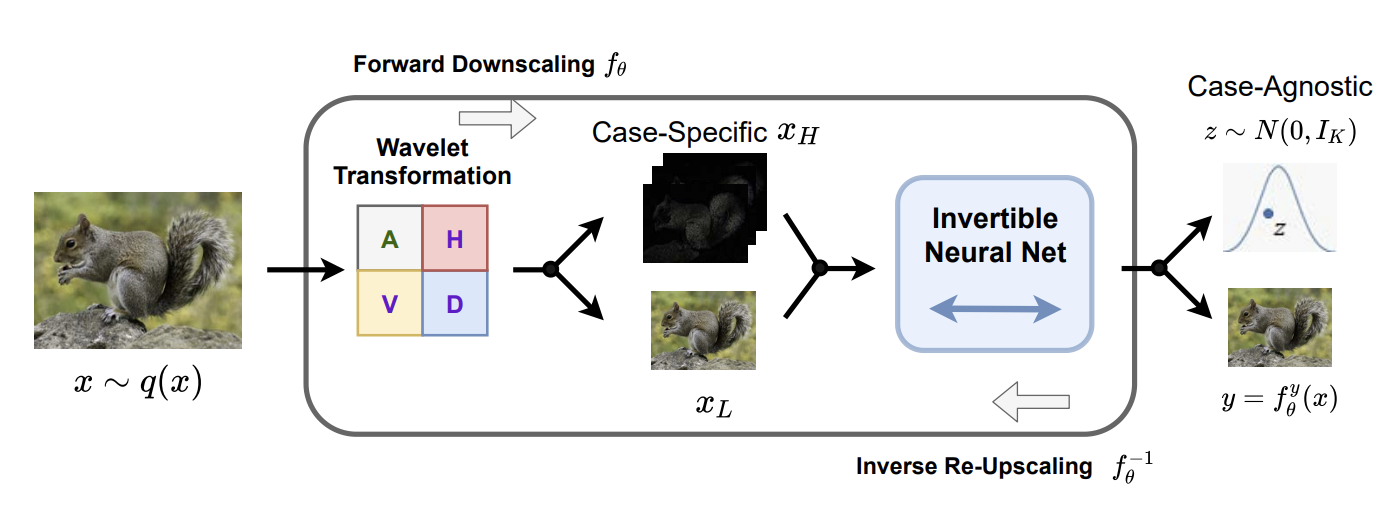
十三、Invertible Rescaling Network
可逆缩放网络(IRN)是用于图像缩放的网络。 根据奈奎斯特-香农采样定理,在降尺度过程中高频内容会丢失。 理想情况下,我们希望保留所有丢失的信息以完美地恢复原始HR图像,但存储或传输高频信息是不可接受的。 为了很好地应对这一挑战,可逆重缩放网络(IRN)以分布的形式捕获有关丢失信息的一些知识,并将其嵌入到模型的参数中以减轻不适定性。 给定 HR 图像,IRN 不仅将其缩小为 LR 图像 y,而且还将特定于案例的高频内容嵌入到辅助的与案例无关的潜在变量中,其边际分布服从固定的预先指定的分布(例如,各向同性高斯)。 基于这个模型,我们使用随机抽取的样本来自逆升级过程的预先指定的分布,它包含在升级过程中可以拥有的最多信息。
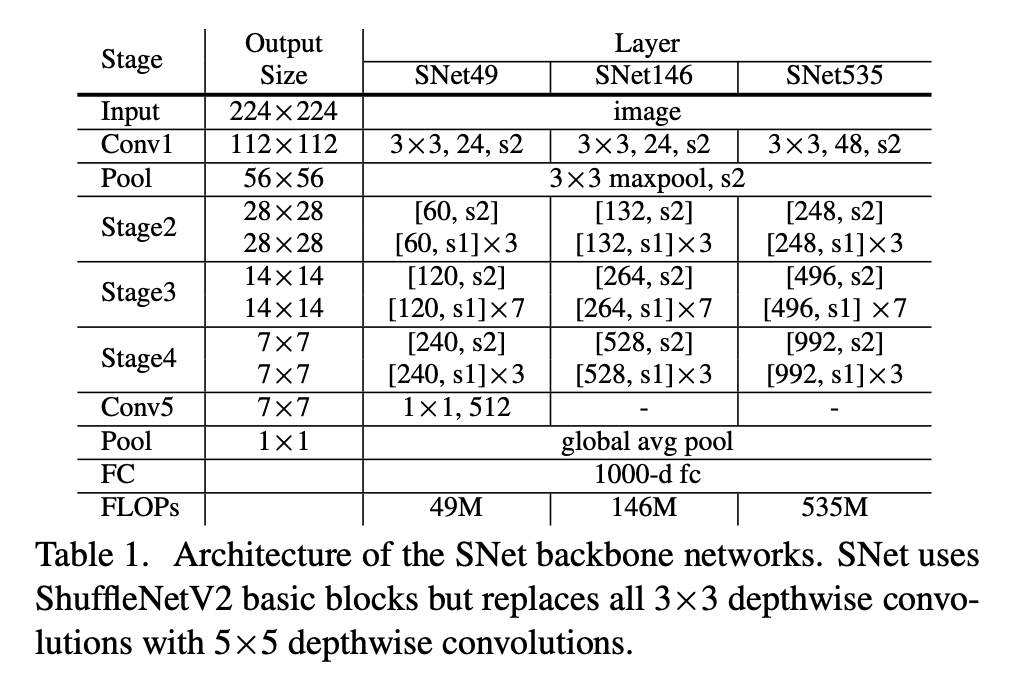
十四、SNet
SNet 是一种卷积神经网络架构和对象检测主干,用于 ThunderNet 两级对象检测器。 SNet 使用 ShuffleNetV2 基本块,但将所有 3×3 深度卷积替换为 5×5 深度卷积。
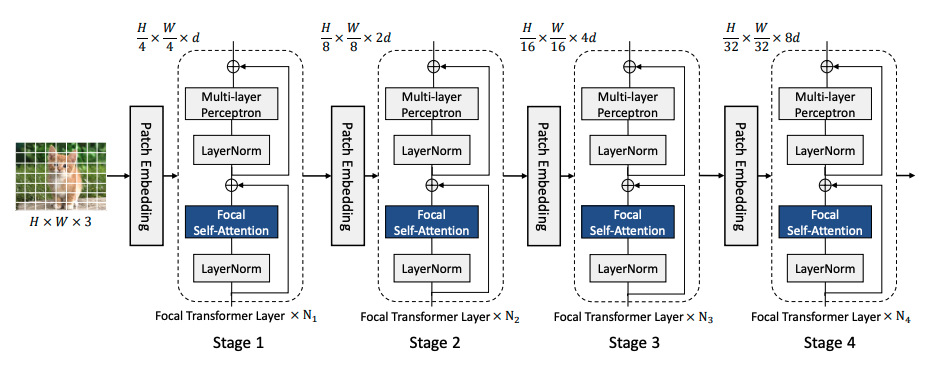
十五、Focal Transformers
焦点自注意力的构建是为了使 Transformer 层可扩展到高分辨率输入。 该方法不是以细粒度处理所有令牌,而是仅在本地处理细粒度令牌,而在全局处理汇总令牌。 因此,它可以覆盖与标准自注意力一样多的区域,但成本要低得多。 图像首先被分割成块,从而产生视觉标记。 然后是补丁嵌入层,由具有相同大小的滤波器和步幅的卷积层组成,将补丁投影到隐藏特征中。 然后,该空间特征图被传递到焦点 Transformer 块的四个阶段。