A Mathematical Framework for Transformer Circuits
- Two-Layer Attention-Only Transformers
- Three Kinds of Composition
- Path Expansion of Logits
- Path Expansion of Attention Scores QK Circuit
- Analyzing a Two-Layer Model
- Induction Heads
- Induction heads的功能
- Induction heads是如何工作的
- CHECKING THE MECHANISTIC THEORY
- 方程中各个项的重要性分析
- Virtual Attention Heads
- 至此本文取得了哪些进展?
这篇主要介绍Two-Layer Attention-Only Transformers部分的内容
Two-Layer Attention-Only Transformers
深度学习研究的模型都很”深“,也就是说它们都由很多层组成。从经验上来看,这类模型非常强大。但是,这种强大是从何而来呢?直觉上来讲,模型的深度允许执行组合操作,进而产生了强大的表现力。
Attention heads的组合是one-layer attention-only transformers和two-layer attention-only transformers之间主要的区别。如果没有对attention heads进行组合,那么two-layer模型将会使用更多的attention heads来实现skip-trigrams。但是,在实际中,two-layer模型发现了利用attention heads组合的方法来表达一种更强大的机制来 完成上下文学习。在模型进行这样的操作时,attention heads变得更像是一个运行算法的计算机程序,而不是一个之前在one-layer模型中看到的skip-trigrams的查找表。
Three Kinds of Composition
在这个系列的第一篇中提到了residual stream可以作为一种通信通道。在residual stream中,每个attention head读取由 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 决定的residual stream的子空间,然后写入某个由 W O W_O WO 决定的子空间。因此,attention head vectors的尺寸要小于residual stream的尺寸(( d h e a d / d m o d e l d_{head}/d_{model} dhead/dmodel)的值域为 [ 1 / 10 , 1 / 100 ] [1/10, 1/100] [1/10,1/100]),attention heads在较小的子空间上运行,可以很容易地避免大量交互。
attention heads有以下三种组合方式:
- Q-Composition:
W Q W_Q WQ 读入一个由前一个head影响的子空间。 - K-Composition:
W K W_K WK 读入一个由前一个head影响的子空间。 - V-Composition:
W V W_V WV 读入一个由前一个head影响的子空间。
Q-Composition和K-Composition与V-Composition有很大的不同。Q-Composition和K-Composition都会影响注意力模式,允许attention heads表示更为复杂的模式。另一方面,当一个attention head关注一个给定的位置时,V-Composition会影响该attention head从所关注位置移动的信息;这就使V-composed heads实际上表现的更像一个单独的单元,并且可以认为是创建了一个额外的”virtual attention heads “。将信息的移动与信息的移动组合起来会产生信息的移动,但是attention heads对注意力模式的影响不会因这种组合方式而减少。
为了真正地了解这三种组合方式,作者将再一次研究OV数据流程和QK数据流程。
Path Expansion of Logits
关于transformer的一个最基本的问题是“logits是如何计算的?”。
按照作者针对one-layer模型的研究方法,列出了一个乘法表达式,表达式中每一项都是模型中的一个层。然后将表达式进行扩展为加法表达式,其中每一项都是一条贯穿模型的端到端路径。如图1. 所示,第一行的公式为乘法表达式,每一项是模型中的一层;第二行的公式为扩展后的加法表达式,每一项都是贯穿模型的一条端到端路径。
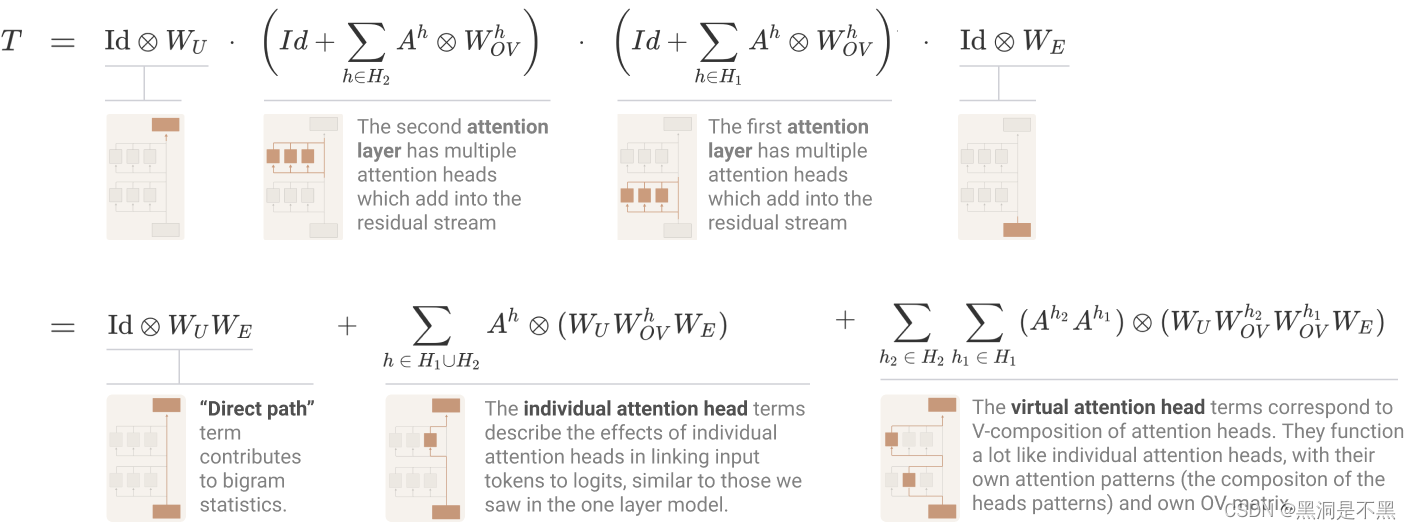
Two of these terms, the direct path term and individual head terms, are identical to the one-layer model. The final “virtual attention head” term corresponds to V-Composition. Virtual attention heads are conceptually very interesting, and we’ll discuss them more later. However, in practice, we’ll find that they tend to not play a significant role in small two-layer models.
在组成图 1表达式的各项中,direct path项和individual attention head项与one-layer模型的一致。最后的”virtual attention head “与V-Composition对应。virtual attention heads会在后续内容进行介绍,并且作者发现,在实际应用中,virtual attention heads不会在较小的two-layer模型中发挥重要作用。
Path Expansion of Attention Scores QK Circuit
如果仅关注logit路径扩展就会忽略了可能是two-layer attention-only transformer中最具差异性的根本属性:Q-composition和K-composition。这一属性使two-layer attention-only transformer拥有更具表现力的第二层注意力模式。
为了了解这一属性,需要查看计算注意力模式的QK数据流程。对于一个attention head h h h,其注意力模式为 A h = s o f t m a x ( t T C Q K h t ) A^h=softmax(t^TC_{QK}^ht) Ah=softmax(tTCQKht),其中 C Q K h C_{QK}^h CQKh 是将tokens映射为注意力分值的QK数据流程。对于第一层attention heads,QK数据流程与one-layer model中所用的矩阵一致: C Q K h ∈ H 1 = W E T W Q K h W E C_{QK}^{h\in H_1}=W_E^TW_{QK}^hW_E CQKh∈H1=WETWQKhWE 。
但是对于第二层的QK-circuit:Q-composition和K-composition都在增加表现力这一点上发挥作用,同时,前一层attention heads也可能会影响keys和queries的构造;最后, W Q K W_{QK} WQK作用于residual stream。
- 在第一层的情况下, W Q K W_{QK} WQK简化为仅作用于token嵌入: C Q K h ∈ H 1 = x 0 T W Q K h x 0 = W E T W Q K h W E C_{QK}^{h\in H_1}=x_0^TW_{QK}^hx_0=W_E^TW_{QK}^hW_E CQKh∈H1=x0TWQKhx0=WETWQKhWE,
- 但是对于第二层,
C Q K h ∈ H 2 = x 1 T W Q K h x 1 C_{QK}^{h\in H_2}=x_1^TW_{QK}^hx_1 CQKh∈H2=x1TWQKhx1 作用于 x 1 x_1 x1,即第一层attention heads后面的residual stream。
可以将这一行为采用乘积表示,即第一层同时在key和query的那一侧。那么,就可以对乘积表达式使用路径扩展方法了。
上述的一个复杂因素是需要将乘积表达式表示为一个6维的tensor,在矩阵上使用两个张量积。这么做是因为需要表达一个形如
[ n c o n t e x t , d m o d e l ] × [ n c o n t e x t , d m o d e l ] → [ n c o n t e x t , n c o n t e x t ] [n_{context},d_{model}]×[n_{context},d_{model}]→[n_{context},n_{context}] [ncontext,dmodel]×[ncontext,dmodel]→[ncontext,ncontext] 的多线性函数。在one-layer的情况下,可以通过隐式地做一个外积来避开这一操作,但是在two-layer的情况下不再有效。很自然地可以想到使用一个 (4,2)-tensor 表示该6维tensor(4个输入维度,2个输出维度)。表达式中的每一项的形式都为 A q ⊗ A k ⊗ W A_q⊗A_k⊗W Aq⊗Ak⊗W,其中 x ( A q ⊗ A k ⊗ W ) y = A q T x W y A k x(A_q⊗A_k⊗W)y=A_q^TxWyA_k x(Aq⊗Ak⊗W)y=AqTxWyAk,意味着 A q A_q Aq 描述了tokens之间query侧的信息移动, A k A_k Ak描述了tokens之间key侧的信息移动,W 描述了 A q A_q Aq 和 A k A_k Ak 是如何通过相乘来生成注意力分值的。

图中第一行,从左至右:
第一项为query side residual stream,由layer 1的直接路径和layer 1的attention heads组成,其输出是layer 2的输入。
第三项为key side residual stream,由layer 1的直接路径和layer 1的attention heads组成,其输出是layer 2的输入。
第二项是layer 2 head的 W Q K W_{QK} WQK ,将第一项和第三项的sides合并至注意力分值。
图 2中第二行,从左至右:
第一项:不具有合并功能的项。表示layer 1沿着query side和key side的直接路径。
第二项:对应纯粹的Q-composition。query side由前一个attention head生成,key side由layer 1的直接路径生成。
图 2中第三行,从左至右:
第一项:对应纯粹的K-composition。key的一部分由前一个attention head生成,query side由layer 1的直接路径生成。
第二项:Q-composition和K-composition之间的相互作用。query side和key side由前一个attention head生成
上图所示公式中的每一项都对应了模型中的一条路径,模型基于该路径可以实现更为复杂的注意力模式。抽象地说,很难对图中的公式进行推理。但是,当讨论induction heads时,将会使用一个具体的例子来再次进行研究。
Analyzing a Two-Layer Model
至此,作者已经构建了一个用于理解two-layer attention-only models的理论模型。得到了一个描述logits(OV数据流程)的整体方程,一个描述每个attention head的注意力模式(QK数据流程)是如何计算的方程。为了在实际中理解上述方程,作者对一个two-layer 模型进行了逆向工程。
two-layer模型和ong-layer模型之间的主要区别就是Q-composition,K-composition,V-composition。如果没有composition,那么two-layer模型仅是一个具有额外attention heads的one-layer模型。
小的two-layer模型通常(尽管并非总是)具有一个非常简单的composition结构,其唯一的composition类型是一个单独first layer head和部分second layer heads之间的K-composition。接下来的图表中显示了模型中,位于first layer和second layer之间需要被分析的Q-composition,K-composition和V-composition。作者根据其对每个head的行为的理解,对各个head进行了着色。first layer head具有非常简单的注意力模式:主要是关注前一个token,然后以较小的程度关注当前token和后面的两个tokens。second layer heads是作者所说的induction heads(就叫感应头吧,不知道咋翻译)。

图3显示了first layer attention heads和second layer attention heads之间的Q-composition,K-composition,V-composition。那么,如何计算一个second layer head的query、key、value向量从一个给定的first layer head中读取了多少信息。作者通过检测相关矩阵的乘积的Frobenius norm除以各个相关矩阵的norm的结果来计算读取的信息量。
对于Q-composition, ∣ ∣ W Q K h 2 T W O V h 1 ∣ ∣ F / ( ∣ ∣ W Q K h 2 T ∣ ∣ F ∣ ∣ W O V h 1 ∣ ∣ F ) ||{W_{QK}^{h_2}}^TW_{OV}^{h_1}||_F/(||{{W_{QK}^{h_2}}}^T||_F||{{W_{OV}^{h_1}}}||_F) ∣∣WQKh2TWOVh1∣∣F/(∣∣WQKh2T∣∣F∣∣WOVh1∣∣F),
对于K-composition, ∣ ∣ W Q K h 2 W O V h 1 ∣ ∣ F / ( ∣ ∣ W Q K h 2 ∣ ∣ F ∣ ∣ W O V h 1 ∣ ∣ F ) ||{W_{QK}^{h_2}}W_{OV}^{h_1}||_F/(||{{W_{QK}^{h_2}}}||_F||{{W_{OV}^{h_1}}}||_F) ∣∣WQKh2WOVh1∣∣F/(∣∣WQKh2∣∣F∣∣WOVh1∣∣F),
对于V-composition, ∣ ∣ W O V h 2 W O V h 1 ∣ ∣ F / ( ∣ ∣ W O V h 2 ∣ ∣ F ∣ ∣ W O V h 1 ∣ ∣ F ) ||{W_{OV}^{h_2}}W_{OV}^{h_1}||_F/(||{{W_{OV}^{h_2}}}||_F||{{W_{OV}^{h_1}}}||_F) ∣∣WOVh2WOVh1∣∣F/(∣∣WOVh2∣∣F∣∣WOVh1∣∣F)。
默认情况下,针对具有相同形状的随机矩阵(大多数attention heads的composition比随机矩阵要小),作者降低了其经验预期量。在实际中,对于这个模型,只有显著的K-composition,并且该模型只有一层,0个head。
从上图可以看出,大多数attention heads都没有参与实质性的composition。我们可以粗略地认为它们是一个更大的skip-trigram。该two-layer模型有一个谜题需要弄清楚,但是该谜题涉及的范围相当狭窄。(作者推测,在某种意义上a couple induction heads会“胜过”一些潜在的skip-trigram heads,但是其他类型的composition无法做到这一点。也就是说,在小模型中,拥有更多的skip-trigram heads是second layer attention heads的一种竞争性使用。)
在后续几个部分,作者将构建一个关于“当前正在发生的情况”的理论,但是在作者开展构建之前,作者使用下面的交互图表来探索attention heads,所使用的图表显示了《哈利波特与魔法石》第一段的value-weighted 注意力模式。作者使用了与前文相同的机制对参与了K-composition的attention heads进行着色。(这种方法增加了研究其他heads的难度,如果读者感兴趣,可以访问该链接,该链接是一个用于一般性探索的接口。Paper1_AttentionMulti)
可以点进去看看,动态效果

上图显示了各种注意头的值加权注意模式;即注意按源位置的值向量的范数缩放的注意力模式 ∣ ∣ v s r c h ∣ ∣ ||v_{src}^h|| ∣∣vsrch∣∣。[即,注意力模式中的注意力权重被位于源位置的value vector的norm ∣ ∣ v s r c h ∣ ∣ ||v_{src}^h|| ∣∣vsrch∣∣ 缩放]
您可以将值加权注意力模式视为显示“矢量从每个位置移动的有多大”。(Kobayashi等人最近也引入了这种方法。[16] )这特别有用,因为当没有tokens与attention heads当前正在寻找的目标匹配时,attention heads有时会使用某些特定tokens作为一种默认或静止位置;这些默认位置的value vector会很小,因此value-weighted模式更能够增加信息量。
该界面允许attention heads进行隔离,显示整体注意力模式,并且允许探索单个tokens的注意力。K-composition涉及的attention heads使用了与上述相同的方法进行着色。作者建议尝试隔离这些heads。
作者建议单独地对每个head进行隔离,并且将鼠标悬停在tokens上的同时,观察注意力模式。对于induction heads,特别要注意注意力模式中的非对角线部分,以及组成Dursley和Potters的tokens的行为。
如果仔细观察,可以注意到浅绿色的induction heads通常会返回到下一个token的前一个实例。作者将在下一节对此进行研究。
Induction Heads
在小型two-layer attention-only transformers中,composition似乎主要用于一个目的:创建induction heads。在之前的研究中,one-layer模型将其大部分容量分配给了执行复制操作的heads,作为一个实现上下文学习的粗略方式。Induction heads是实现上下文学习的更强大的机制。【作者在该篇论文中详细地介绍了induction heads在上下文学习中的重要性,In-context Learning and Induction Heads】。
Induction heads的功能
Induction heads在上下文中搜索当前tokens的前一个示例。如果它们没有找到,它们会关注第一个token(在作者的例子中,一个位于开始位置的特殊token),并且什么操作也不做。但如果它们找到了该示例,它们就会查看下一个token并复制该token。这允许它们能够精确地和近似地重复先前的tokens序列。
Induction heads与one-layer模型中观测到的上下文学习类型:
- One-layer模型的复制head: [b]…[a]→[b]
- 当token化的罕见行为被允许时: [ab]…[a]→[b]
- Two-layer模型的induction head: [a][b]…[a]→[b]
Two-layer算法的性能更加强大。该算法能够知道token在之前是如何被使用的,并且能够查找相似的情况,而不是简单地寻找可能重复一个token的位置。这能够使算法在这些情况下做出更有信心的预测。该算法也不太容易收到分布转移的影响,因为它不依赖于学习到的关于一个token是否可以合理地跟随另一个token的统计数据。(稍后我们将看到induction heads可以操作完全随机的tokens的重复序列)。
图中的例子突出了哈利波特第一段中induction heads有助于预测tokens的几个案例。

假设induction heads正在关注token的前一个副本并向前移动,heads应该能够在完全随机的重复模式上做到这一点。这可能是heads能够遇到的最难的测试,因为heads不能依赖于哪些tokens通常出现在其他tokens之后的常规统计数据。由于tokens是从作者的词汇表中均匀随机采样的,因此作者将词汇表中第n个token表示为<n>,特殊标记<START>除外。(这完全不在分布内。只要保证重复序列更容易再次出现这一更为抽象的属性成立,那么Induction heads就能够在完全不同的分布上运行。)

图6似乎是很有力的证据,能够证明induction heads的假设是正确的。现在已经知道了K-composition在two-layer模型中的作用。接下来的问题是K-composition如何做到的。
Induction heads是如何工作的
Induction heads的核心技巧是key是从向后移动一个token的tokens中计算得到的。query搜索“相似的”key vector,但是由于keys被移动了,所以寻找下一个token。
在residual stream(不同于旋转注意力)中可以使用位置嵌入的模型,有另一种实现induction heads的算法;可以参阅作者对transformer中位置嵌入和指针技术的直观理解。
图7中的例子来源于具有更为复杂的induction heads的更大的模型:

QK数据流程可以通过tokens来扩展,而不是attention heads。图中,key和query的强度表示每个token增加注意力分值的量。Logit结果是OV数据流程。
创建一个induction head的最基础方法是使用K-composition和前一个token head,将key vector向前移动一个token。这就在QK数据流程中生成了一个形式为 I d ⊗ A h − 1 ⊗ W Id⊗A^{h−1}⊗W Id⊗Ah−1⊗W 的项。( A h − 1 A^{h−1} Ah−1定义了一个关注前一个token的注意力模式。)如果 W 匹配tokens相同的情况,那么 W就是QK版本的“执行复制操作矩阵”,那么当源位置之前的上一个token于目标token相同时,该项将增加注意力分值。(Induction heads可以比这更加复杂;例如,其它two-layer模型构建了一个attention head,该head关注比前一个token还要稍远一些的token,很可能生成一个形如 A h − 1 ⊗ A h − 2 ⊗ W A^{h−1}⊗A^{h−2}⊗W Ah−1⊗Ah−2⊗W的项,进而使heads能够匹配更远的内容。)
CHECKING THE MECHANISTIC THEORY
作者在之前提出的针对transformer的机械式解释理论表明induction heads必备两个功能:
- 拥有一个“copying”OV数据流程矩阵。
- 拥有一个与 I d ⊗ A h − 1 ⊗ W Id⊗A^{h−1}⊗W Id⊗Ah−1⊗W 项相关的“same matching”QK数据流程。
尽管作者不确定来自Detecting Copying部分的特征值汇总统计信息是否是用于检测“copying”或“matching”矩阵的最可能的汇总统计信息,但是作者还是选择将其作为一种工作形式。如果将attention heads看作是QK特征值和OV特征值为正数的2D空间中的点,那么所有的induction heads都在最右边的角落。

也许有人会思考这些观察结果是不是循环的。作者最开始研究这写attention heads是因为它们具有大于随机概率的K-composition。但是在此情况下,作者发现K-composition创建了一个矩阵,该矩阵非常倾向于正的特征值。但是,没有任何理由表明一个大的K-composition会是一个正的K-composition。也没有任何理由支持OV数据流程应该是正的。但是,如果实现的算法是按照前文所述的用于实现induction的算法来实现的,这种结果却是作者所希望的。
方程中各个项的重要性分析
在本文较前部分,作者忽略了所有“virtual attention head”在方程中对应的项,因为作者没有观察到任何显著的V-composition。 虽然这看起来可能是对的,但是可能会犯错。 特别是,虽然每个单独的virtual attention head都不重要,但从总体上来看它们很重要。 本节将描述一种使用消融技术进行双重检查的方法。
通常,当我们在神经网络中消融某些东西时,会消融在激活操作中明确表示的东西。可以通过乘以零来实现消融。但是在这种情况下,会试图去消融一个只有在方程展开时才会存在的隐式项。可以通过尝试运行方程所描述的transformer来做到这一点,但是这会非常慢,并且当研究更深的模型时会变得更糟。
但是事实证明,有一种算法可以确定消融n阶项(即,对应于通过具有n个attention heads的V-composition的路径的项)的边际效应。该算法的关键技巧是多次运行模型,将当前的激活操作替换为之前运行模型时的激活操作。这允许限制路径的深度,消融所有阶数大于该深度的项。然后通过对比每次消融时观测到的损失之间的差异,可以得到n阶项的边际效应。
测量n阶项边际损失率的算法
第一步:运行模型,保存所有注意力模式。
第二步:运行模型,强制所有注意力模式都是所记录的版本,而不是将attention head的输出添加到residual stream中;保存输出,并用形状相同的0tensor替换输出。记录产生的损失。
第n步:运行模型,强制所有注意力模式为所记录的版本,而不是将attention head的输出添加到residual stream中;保存输出,并用该head最后一次所保存的值来替换输出。记录产生的损失。
值得注意是,将注意力模式冻结为真值可以使这种消融仅针对V-composition。尽管在某种程度上这是最简单的,专注于OV数据流程的算法,但是该算法的变体也可以用于隔离Q-composition或K-composition。
正如V-composition结果表明的那样,二阶“virtual attention head”项在模型中的边际效应非常小。(尽管它们很可能在其它模型,尤其是更大的模型中更为重要)。

作者得出的结论:为了理解two-layer attention only models,不应该优先理解二阶“virtual attention head”,而是关注直接路径(只有助于双元统计)和单独的attention head项。(这与Q-composition和K-composition无关;OV数据流程中更高阶的项是无关紧要的,仅仅排除了V-composition的重要性。Q-composition和K-composition对应了每个head中的QK数据流程中的项。)
我们可以将这些单独的attention head项进一步细分为第1层和第2层中的那些:

上述内容表明了需要关注second layer head项。
Virtual Attention Heads
尽管virtual attention heads被证明对于理解two-layer model的性能并不重要,但是作者推测它们在更大、更复杂的transformers中可能会更为重要。而且, 它们在理论上看起来非常优雅。
virtual attention heads在logit方程的扩展路径中是形式为 ( A h 2 A h 1 ) ⊗ ( . . . W O V h 2 W O V h 1 . . . ) (A_{h2}A_{h1})⊗(...W_{OV}^{h_2}W_{OV}^{h_1}...) (Ah2Ah1)⊗(...WOVh2WOVh1...) 的项,对用两个heads的V-composition。
关于virtual attention heads,有两件事值得注意。
首先,这种composition看起来性能非常好。作者在实验中经常可以观测到heads的注意力模式关注到前一个token,但是并没有heads的注意力模式向后关注两个tokens,这也许是因为从后两个tokens得到的任何有用的预测能力都是通过virtual heads获取的。注意力模式也能够实现更抽象的事情,例如关注当前子句的开头或句子的主语 - composition实现了诸如‘关注前一个子句的主题’之类的功能。
Q-composition和K-composition影响注意力模式,V-composition创建了上述方程中的项,这些项实际上作为一种独立单元运行,逐个第执行每个head的运算。最终得到的结果对象最好认为是heads的组成部分: h 2 ∘ h 1 h_2∘h_1 h2∘h1。得到的结果对象有自己的注意力模式: A h 2 ∘ h 1 = A h 2 A h 1 A^{h_2∘h_1}=A^{h_2}A^{h_1} Ah2∘h1=Ah2Ah1 ,其属于自己的OV矩阵为 W O V h 2 ∘ h 1 = W O V h 2 W O V h 1 W_{OV}^{h_2∘h_1}=W_{OV}^{h_2}W_{OV}^{h_1} WOVh2∘h1=WOVh2WOVh1。在更深的模型中,原则上可以有更高阶的virtual attention heads,(例如 h 3 ∘ h 2 ∘ h 1 h_3∘ h_2∘h_1 h3∘h2∘h1)。
其次,有大量的virtual attention heads。正常heads的数目按照层的数目线性增长,而基于two-heads composition的virtual heads的数目是呈二次增长的,three-heads呈立方增长,以此类推。这就意味着,在理论上模型可能有更多的空间通过virtual attention heads来获取有用的预测能力。这一点特别重要,因为在某种意义上,正常的注意力头是“很大的”。head有一个单独的注意力模式,决定它关注哪个源tokens,以及从源token复制到目标token的 d h e a d d_{head} dhead 维度。这使得它在不需要传递太多信息的直观“小”任务中使用起来很笨拙,例如,关注前面的代词来确定文本是第几人称,或者关注时态标记来检测文本是过去、现在,还是将来时。
至此本文取得了哪些进展?
在前面的几节中,我们在理解one-layer attention-only transformers和two-layer attention-only transformers方面取得了进展。但我们的最终目标是了解一般的transformers。这项工作真的让我们更接近目标了吗?这些特殊的、有限的案例真的能解释普遍的问题吗?作者将在后续工作中探讨这个问题,但作者的总体感觉是认为上述问题的答案是肯定的,这些方法可以用于理解通用transformers的部分内容,包括大型语言模型。
一个原因是,普通的transformers包含一些似乎是primarily attentional的数据流程。甚至在MLP层存在的情况下,attention heads仍然在residual stream上工作,并且仍然可以与各个attention heads和嵌入直接交互。而且在实际中,作者发现了仅涉及attention heads和嵌入的可解释数据流程的实例。尽管作者现在可能无法理解整个模型,但可以很好地对这些部分进行逆向工程。
实际上,作者在一些大模型中发现了一些与其在toy models中所研究的类似的attention heads和数据流程。特别的,作者发现了大模型形成了许多induction heads,并且这些构建这些heads的基础构建模块是具有一个前向token head的K-composition,正如作者在本文中所述的那样。这似乎是各种规模的语言模型中上下文学习的核心驱动力,也是作者下一篇文章的主题。