划水一整天,模型看了仨!不错,虽然现在在打哈欠,还是很想把XGBoost梳理梳理
先从名字开始
XGBoost,eXtreme Gradient Boosting: em。。。。不理解
书上说,XGBoost有很好的性能,在各大比赛中大放异彩,行吧,冲这句,好好看看!
看了几篇,总感觉这个XGBoost不仅仅是对GBDT的改进版,还包含了对CART决策树的改进
1. 首先,GBDT是经过泰勒一阶导出来的,XGBoost则是经过泰勒二阶导,越高阶导越接近原函数值
初始的平方损失函数为 L o r i g i n a l = ( y i − y p r e ) 2 L_{original} = (y_i-y_{pre})^2 Loriginal=(yi−ypre)2,由于 y p r e y_{pre} ypre是由 y p r e = f ( x ) = ∑ i = 1 m f i ( x ) y_{pre}=f(x)=∑_{i=1}^mf_i(x) ypre=f(x)=∑i=1mfi(x)
因此, L o r i g i n a l = L ( y , f ( x ) ) ,表示由 y 和 f ( x ) 影响 L 值 L_{original}=L(y,f(x)),表示由y和f(x)影响L值 Loriginal=L(y,f(x)),表示由y和f(x)影响L值
L ( y , f ( x ) ) = L m − 1 ( y , f m − 1 ( x ) ) + ə L ( y , f m − 1 ( x ) ) ə f m − 1 ( x ) ∗ [ f ( x ) − f m − 1 ( x ) ] + 1 2 ∗ ə L ( y , f m − 1 ( x ) ) 2 ə f m − 1 ( x ) 2 ∗ ( f ( x ) − f m − 1 ( x ) ) 2 L(y,f(x)) = L_{m-1}(y,f_{m-1}(x))+\frac{ə_{L(y,f_{m-1}(x))}}{ə_{f_{m-1}(x)}}*[f(x)-f_{m-1}(x)]+\frac{1}{2}*\frac{ə^2_{L(y,f_{m-1}(x))}}{ə^2_{f_{m-1}(x)}}*(f(x)-f_{m-1}(x))^2 L(y,f(x))=Lm−1(y,fm−1(x))+əfm−1(x)əL(y,fm−1(x))∗[f(x)−fm−1(x)]+21∗əfm−1(x)2əL(y,fm−1(x))2∗(f(x)−fm−1(x))2
令 g i = ə L ( y i , f m − 1 ( x i ) ) ə f m − 1 ( x i ) g_i = \frac{ə_{L(y_i,f_{m-1}(x_i))}}{ə_{f_{m-1}(x_i)}} gi=əfm−1(xi)əL(yi,fm−1(xi)), h i = ə L ( y , f m − 1 ( x i ) ) 2 ə f m − 1 ( x i ) 2 h_i = \frac{ə^2_{L(y,f_{m-1}(x_i))}}{ə^2_{f_{m-1}(x_i)}} hi=əfm−1(xi)2əL(y,fm−1(xi))2, L ( y , f m − 1 ( x ) ) L(y,f_{m-1}(x)) L(y,fm−1(x))这仨都是前m-1轮的,相当于常数
令 f ( x ) = f m ( x ) f(x)=f_m(x) f(x)=fm(x),则有 T m = f m ( x ) − f m − 1 ( x ) T_m = f_m(x)-f_{m-1}(x) Tm=fm(x)−fm−1(x)
则 L m ( y , f m ( x ) ) = L m − 1 ( y , f m − 1 ( x ) ) + ∑ i = 1 N d a t a g i ∗ T m ( x i , θ m ) + 1 2 ∑ i = 1 N d a t a h i ∗ T m 2 ( x i , θ m ) L_m(y,f_m(x)) = L_{m-1}(y,f_{m-1}(x))+∑_{i=1}^{N_{data}}g_i*T_m(x_i,θ_m)+\frac{1}{2}∑_{i=1}^{N_{data}}h_i*T^2_m(x_i,θ_m) Lm(y,fm(x))=Lm−1(y,fm−1(x))+∑i=1Ndatagi∗Tm(xi,θm)+21∑i=1Ndatahi∗Tm2(xi,θm)
2. 其次,XGBoost的优化①:增加正则化项 Ω ( T m ( x ) ) Ω(T_m(x)) Ω(Tm(x))
晕了…明天再说!
本来周末把书带回家,准备要看看…果然,美男误我…
这里的 Ω ( T m ( x ) ) = γ ∗ N 叶 + λ ∑ i = 1 N 叶 C i 2 ( x ) Ω(T_m(x)) = γ*N_{叶}+λ∑_{i=1}^{N_{叶}}C_{i}^2(x) Ω(Tm(x))=γ∗N叶+λ∑i=1N叶Ci2(x),这里的 N 叶 N_叶 N叶表示所有叶子节点的个数, C i ( x ) C_{i}(x) Ci(x)是叶子节点的均值
γ ∗ N 叶 γ*N_{叶} γ∗N叶是对叶子节点个数的惩罚,毕竟如果分裂太多,容易过拟合
但 λ ∑ i = 1 N 叶 C i 2 ( x ) λ∑_{i=1}^{N_{叶}}C_{i}^2(x) λ∑i=1N叶Ci2(x)是为什么要对叶子均值进行惩罚呢?
哦!
因为在XGBoost中,每个叶子节点的均值,其实都是这组叶子节点的残差均值
但有些残差是正的,有些是负的,那要衡量拟合效果是否好,应该看与0的差距。
- 残差为0,表示完美拟合
- 残差为正,表示大于原值
- 残差为负,表示小于原值
那么为了统一表示拟合效果,直接求平方,可避免正、负判别,且计算起来比绝对值更方便。
因此, λ ∑ i = 1 N 叶 C i 2 ( x ) λ∑_{i=1}^{N_{叶}}C_{i}^2(x) λ∑i=1N叶Ci2(x)主要是对残差的惩罚
所以有 Ω ( T m ( x ) ) = γ ∗ N 叶 + λ ∑ i = 1 N 叶 C i 2 ( x ) Ω(T_m(x)) = γ*N_{叶}+λ∑_{i=1}^{N_{叶}}C_{i}^2(x) Ω(Tm(x))=γ∗N叶+λ∑i=1N叶Ci2(x),完成了对叶子数量和残差的惩罚
惩罚项也加入到 L K L_K LK损失函数里
L m ( y , f m ( x ) ) = L m − 1 ( y , f m − 1 ( x ) ) + ∑ i = 1 N d a t a g i ∗ T m ( x i , θ m ) + 1 2 ∑ i = 1 N d a t a h i ∗ T m 2 ( x i , θ m ) + γ ∗ N 叶 + λ ∑ i = 1 N 叶 C i 2 ( x ) L_m(y,f_m(x)) = L_{m-1}(y,f_{m-1}(x))+∑_{i=1}^{N_{data}}g_i*T_m(x_i,θ_m)+\frac{1}{2}∑_{i=1}^{N_{data}}h_i*T^2_m(x_i,θ_m)+ γ*N_{叶}+λ∑_{i=1}^{N_{叶}}C_{i}^2(x) Lm(y,fm(x))=Lm−1(y,fm−1(x))+∑i=1Ndatagi∗Tm(xi,θm)+21∑i=1Ndatahi∗Tm2(xi,θm)+γ∗N叶+λ∑i=1N叶Ci2(x)
求这个损失函数的极小值,求极值的时候,常数项不需要参与运算,因此函数里可以去掉常数项 L m − 1 ( y , f m − 1 ( x ) ) L_{m-1}(y,f_{m-1}(x)) Lm−1(y,fm−1(x)),并且为了求极值计算方便,还可以将平方项 λ ∑ i = 1 N 叶 C i 2 ( x ) λ∑_{i=1}^{N_{叶}}C_{i}^2(x) λ∑i=1N叶Ci2(x)的系数,设为 1 2 \frac{1}{2} 21这样后续求极值时可以化简运算
最终 L m ( y , f m ( x ) ) = ∑ i = 1 N d a t a g i ∗ T m ( x i , θ m ) + 1 2 ∑ i = 1 N d a t a h i ∗ T m 2 ( x i , θ m ) + γ ∗ N 叶 + 1 2 λ ∑ i = 1 N 叶 C i 2 ( x ) L_m(y,f_m(x)) =∑_{i=1}^{N_{data}}g_i*T_m(x_i,θ_m)+\frac{1}{2}∑_{i=1}^{N_{data}}h_i*T^2_m(x_i,θ_m)+ γ*N_{叶}+\frac{1}{2}λ∑_{i=1}^{N_{叶}}C_{i}^2(x) Lm(y,fm(x))=∑i=1Ndatagi∗Tm(xi,θm)+21∑i=1Ndatahi∗Tm2(xi,θm)+γ∗N叶+21λ∑i=1N叶Ci2(x)
这里要梳理一下 N d a t a 和 N 叶 N_{data}和N_{叶} Ndata和N叶的关系
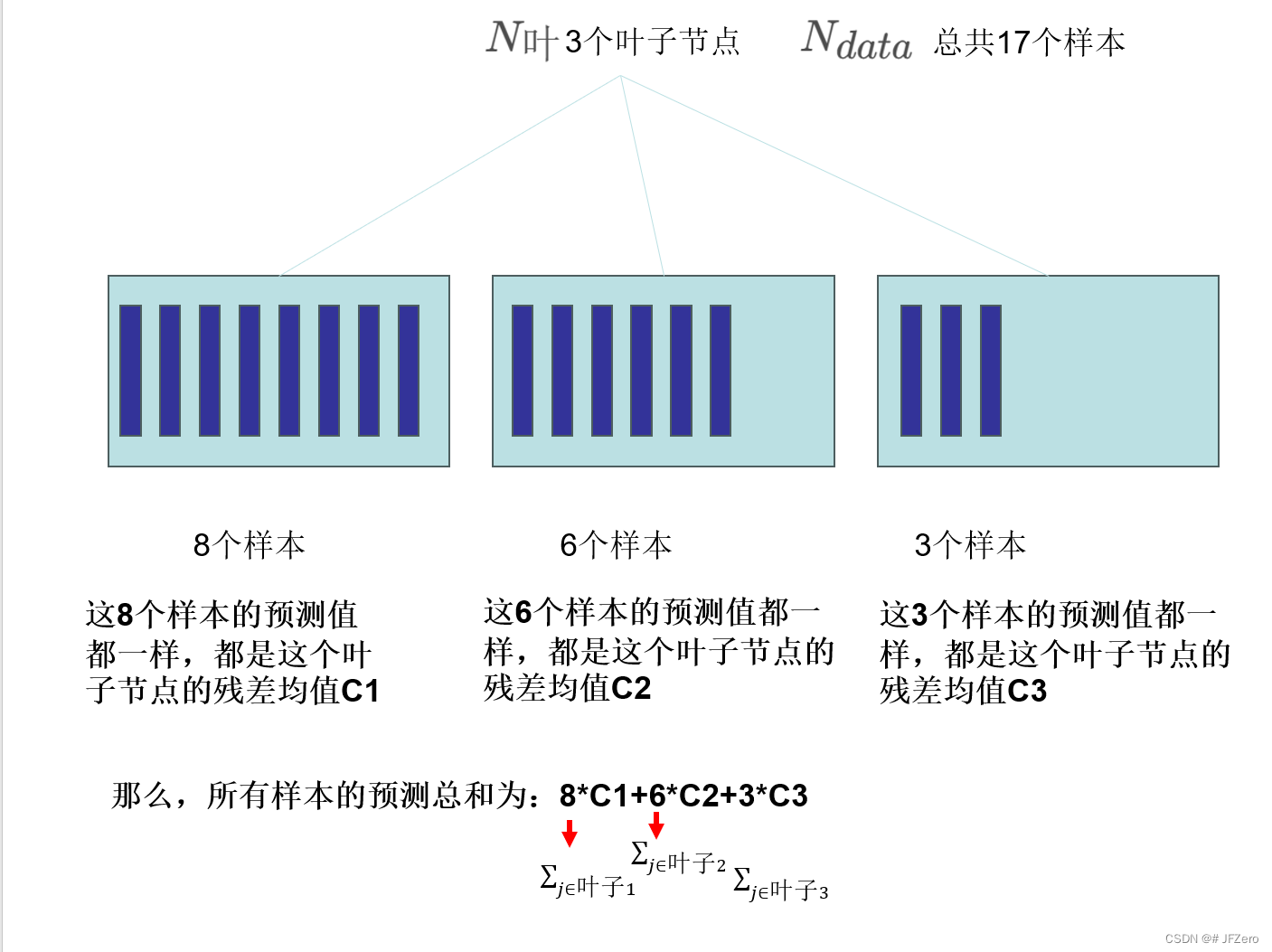
所以,可以将损失函数里式子进行转化
- ∑ i = 1 N d a t a g i ∗ T m ( x i , θ m ) = ∑ j = 1 N 叶 ( ∑ i ∈ I ( j ) g i ) C j ( x ) ∑_{i=1}^{N_{data}}g_i*T_m(x_i,θ_m)=∑_{j=1}^{N_{叶}}(∑_{i∈I(j)}g_i)C_{j}(x) ∑i=1Ndatagi∗Tm(xi,θm)=∑j=1N叶(∑i∈I(j)gi)Cj(x),用 G j 表示 ∑ i ∈ I ( j ) g i G_j表示∑_{i∈I(j)}g_i Gj表示∑i∈I(j)gi
- ∑ i = 1 N d a t a h i ∗ T m 2 ( x i , θ m ) = ∑ j = 1 N 叶 ( ∑ i ∈ I ( j ) h i ) C j 2 ( x ) ∑_{i=1}^{N_{data}}h_i*T^2_m(x_i,θ_m)=∑_{j=1}^{N_{叶}}(∑_{i∈I(j)}h_i)C_{j}^2(x) ∑i=1Ndatahi∗Tm2(xi,θm)=∑j=1N叶(∑i∈I(j)hi)Cj2(x),用 H j 表示 ∑ i ∈ I ( j ) h i H_j表示∑_{i∈I(j)}h_i Hj表示∑i∈I(j)hi
则损失函数为
L m ( y , f m ( x ) ) = ∑ j = 1 N 叶 G j C j ( x ) + 1 2 ∑ j = 1 N 叶 H j C j 2 ( x ) + γ ∗ N 叶 + 1 2 λ ∑ j = 1 N 叶 C j 2 ( x ) + λ N 叶 L_m(y,f_m(x)) =∑_{j=1}^{N_{叶}}G_jC_{j}(x)+\frac{1}{2}∑_{j=1}^{N_{叶}}H_jC_{j}^2(x)+ γ*N_{叶}+\frac{1}{2}λ∑_{j=1}^{N_{叶}}C_{j}^2(x)+λN_{叶} Lm(y,fm(x))=∑j=1N叶GjCj(x)+21∑j=1N叶HjCj2(x)+γ∗N叶+21λ∑j=1N叶Cj2(x)+λN叶
合并同类项:
L m ( y , f m ( x ) ) L_m(y,f_m(x)) Lm(y,fm(x))
= ∑ j = 1 N 叶 G j C j ( x ) + 1 2 ∑ j = 1 N 叶 ( H j + λ ) C j 2 ( x ) + γ ∗ N 叶 =∑_{j=1}^{N_{叶}}G_jC_{j}(x)+\frac{1}{2}∑_{j=1}^{N_{叶}}(H_j+λ)C_{j}^2(x)+ γ*N_{叶} =∑j=1N叶GjCj(x)+21∑j=1N叶(Hj+λ)Cj2(x)+γ∗N叶
= ∑ j = 1 N 叶 [ G j C j ( x ) + 1 2 ( H j + λ ) C j 2 ( x ) + γ ] =∑_{j=1}^{N_{叶}}[G_jC_{j}(x)+\frac{1}{2}(H_j+λ)C_{j}^2(x)+ γ] =∑j=1N叶[GjCj(x)+21(Hj+λ)Cj2(x)+γ]
- G j = ∑ i ∈ I ( j ) g i = ∑ i ∈ I ( j ) ə L ( y i , f m − 1 ( x i ) ) ə f m − 1 ( x i ) G_j=∑_{i∈I(j)}g_i=∑_{i∈I(j)} \frac{ə_{L(y_i,f_{m-1}(x_i))}}{ə_{f_{m-1}(x_i)}} Gj=∑i∈I(j)gi=∑i∈I(j)əfm−1(xi)əL(yi,fm−1(xi)),是常数项
- H j = ∑ i ∈ I ( j ) h i = ∑ i ∈ I ( j ) ə L ( y , f m − 1 ( x i ) ) 2 ə f m − 1 ( x i ) 2 H_j=∑_{i∈I(j)}h_i=∑_{i∈I(j)}\frac{ə^2_{L(y,f_{m-1}(x_i))}}{ə^2_{f_{m-1}(x_i)}} Hj=∑i∈I(j)hi=∑i∈I(j)əfm−1(xi)2əL(y,fm−1(xi))2,也是常数项
- γ也是我们提前设置的常数项
- 只要计算出每个叶子节点中的 G j C j ( x ) + 1 2 ( H j + λ ) C j 2 ( x ) + γ G_jC_{j}(x)+\frac{1}{2}(H_j+λ)C_{j}^2(x)+ γ GjCj(x)+21(Hj+λ)Cj2(x)+γ极小值,就可以算出所有叶子节点 ∑ j = 1 N 叶 G j C j ( x ) + 1 2 ∑ j = 1 N 叶 ( H j + λ ) C j 2 ( x ) + γ ∗ N 叶 ∑_{j=1}^{N_{叶}}G_jC_{j}(x)+\frac{1}{2}∑_{j=1}^{N_{叶}}(H_j+λ)C_{j}^2(x)+ γ*N_{叶} ∑j=1N叶GjCj(x)+21∑j=1N叶(Hj+λ)Cj2(x)+γ∗N叶的极小值
- L j = 1 2 ( H j + λ ) C j 2 ( x ) + G j C j ( x ) + γ L_j =\frac{1}{2}(H_j+λ)C_{j}^2(x)+ G_jC_{j}(x)+ γ Lj=21(Hj+λ)Cj2(x)+GjCj(x)+γ相当于一元二次方程 y = a x 2 + b x + c y = ax^2+bx+c y=ax2+bx+c,在 x = − b 2 a x=-\frac{b}{2a} x=−2ab处可以取到极值 4 a c − b 2 4 a \frac{4ac-b^2}{4a} 4a4ac−b2
- 因此当 C j ( x ) = − G j H j + λ C_{j}(x) = -\frac{G_j}{H_j+λ} Cj(x)=−Hj+λGj时,可以求到单个叶子节点的损失函数极小值 m i n : L j = 2 γ ( H j + λ ) − G j 2 2 ( H j + λ ) = γ − G j 2 2 ( H j + λ ) min:L_j=\frac{2γ(H_j+λ)-G_j^2}{2(H_j+λ)}=γ-\frac{G_j^2}{2(H_j+λ)} min:Lj=2(Hj+λ)2γ(Hj+λ)−Gj2=γ−2(Hj+λ)Gj2
- 那么第m次迭代时所有样本的损失函数为, m i n : L m ( y , f m ( x ) ) = ∑ j = 1 N 叶 [ γ − G j 2 2 ( H j + λ ) ] min:L_m(y,f_m(x))=∑_{j=1}^{N_{叶}}[γ-\frac{G_j^2}{2(H_j+λ)}] min:Lm(y,fm(x))=∑j=1N叶[γ−2(Hj+λ)Gj2]
3. 最后,XGBoost的决策树分裂的特征及特征值,与CART决策树选取标准是不同的
CART决策树是根据基尼系数最小,选取的特征及特征值来分裂树
而XGBoost是可以采用贪心算法,根据特征及特征值分裂后的损失函数增益最大值,来选取的特征及特征值来分裂树
- 损失函数增益,指的是,每次分裂一个节点时,损失值减小的程度
- 当前节点的损失值会发生改变,而其他节点的损失值不变。
- 如果当前节点的损失值比分裂前非常非常小,说明整体的损失值也会变小,增益程度也会更大
- 如果当前节点的损失值比分裂前差不多,说明整体的损失值没有太大改变,增益程度不大
- 因此,应该选择损失值增益最大的特征及特征值,作为分裂的节点
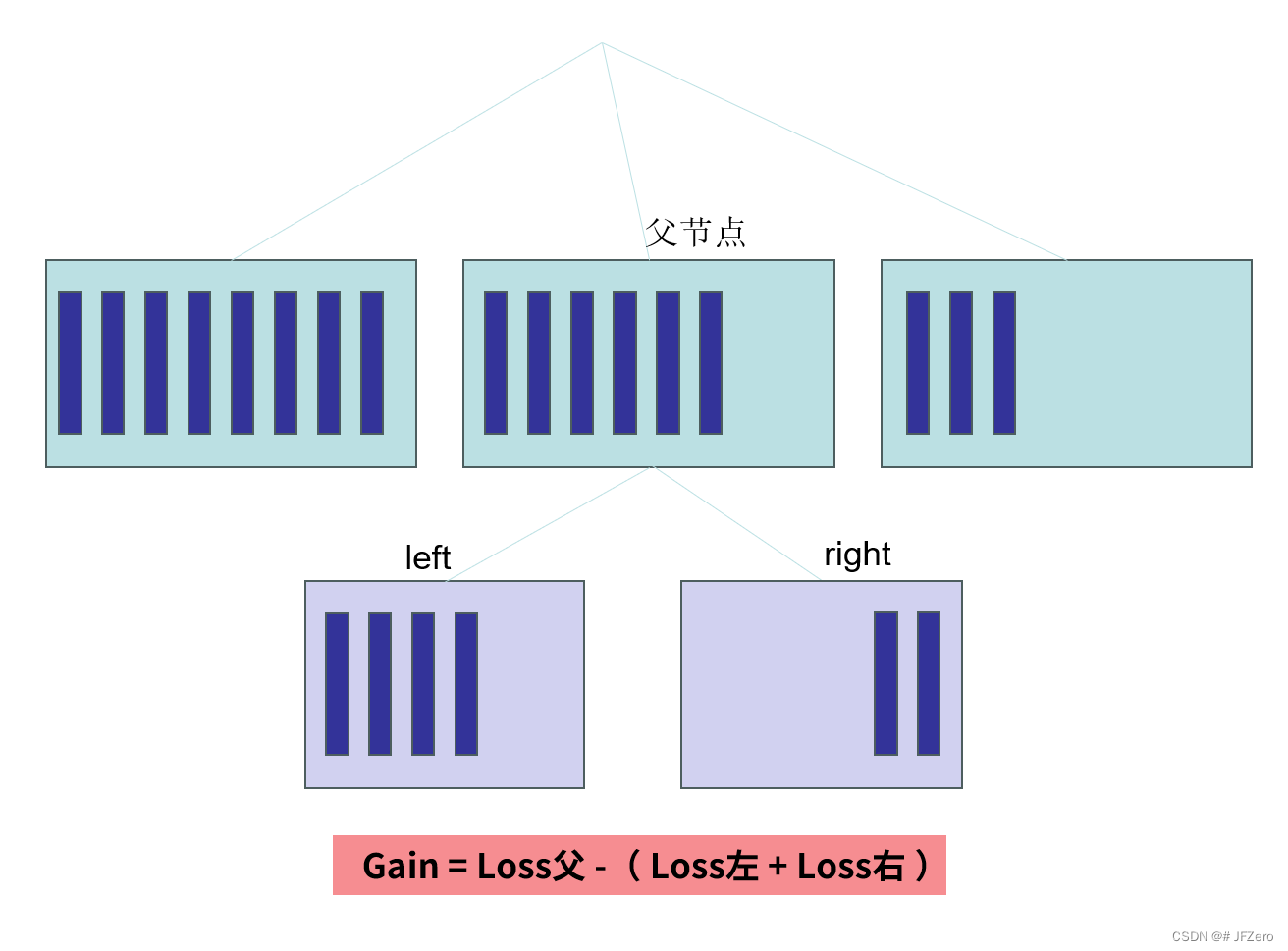
因此,
G a i n = [ γ − G j 父 2 2 ( H j 父 + λ ) ] − [ γ − G j 左 2 2 ( H j 左 + λ ) ] − [ γ − G j 右 2 2 ( H j 右 + λ ) ] Gain =[γ-\frac{G_{j父}^2}{2(H_{j父}+λ)}]-[γ-\frac{G_{j左}^2}{2(H_{j左}+λ)}]-[γ-\frac{G_{j右}^2}{2(H_{j右}+λ)}] Gain=[γ−2(Hj父+λ)Gj父2]−[γ−2(Hj左+λ)Gj左2]−[γ−2(Hj右+λ)Gj右2]
= G j 左 2 2 ( H j 左 + λ ) + G j 右 2 2 ( H j 右 + λ ) − G j 父 2 2 ( H j 父 + λ ) − γ =\frac{G_{j左}^2}{2(H_{j左}+λ)}+\frac{G_{j右}^2}{2(H_{j右}+λ)}-\frac{G_{j父}^2}{2(H_{j父}+λ)}-γ =2(Hj左+λ)Gj左2+2(Hj右+λ)Gj右2−2(Hj父+λ)Gj父2−γ
其中 G j 父 2 2 ( H j 父 + λ ) \frac{G_{j父}^2}{2(H_{j父}+λ)} 2(Hj父+λ)Gj父2,
G j 父 = ∑ i ∈ I ( j 左 + j 右 ) g i = ∑ i ∈ I ( j 左 ) g i + ∑ i ∈ I ( j 右 ) g i = G j 左 + G j 右 G_{j父}=∑_{i∈I(j左+j右)}g_i=∑_{i∈I(j左)}g_i+∑_{i∈I(j右)}g_i = G_{j左}+G_{j右} Gj父=∑i∈I(j左+j右)gi=∑i∈I(j左)gi+∑i∈I(j右)gi=Gj左+Gj右
H j 父 = ∑ i ∈ I ( j 左 + j 右 ) h i = ∑ i ∈ I ( j 左 ) h i + ∑ i ∈ I ( j 右 ) h i = H j 左 + H j 右 H_{j父}=∑_{i∈I(j左+j右)}h_i=∑_{i∈I(j左)}h_i+∑_{i∈I(j右)}h_i = H_{j左}+H_{j右} Hj父=∑i∈I(j左+j右)hi=∑i∈I(j左)hi+∑i∈I(j右)hi=Hj左+Hj右
因此, G j 父 2 2 ( H j 父 + λ ) = ( G j 左 + G j 右 ) 2 2 ( H j 左 + H j 右 + λ ) \frac{G_{j父}^2}{2(H_{j父}+λ)}=\frac{(G_{j左}+G_{j右})^2}{2(H_{j左}+H_{j右}+λ)} 2(Hj父+λ)Gj父2=2(Hj左+Hj右+λ)(Gj左+Gj右)2
所以最终的
G a i n = G j 左 2 2 ( H j 左 + λ ) + G j 右 2 2 ( H j 右 + λ ) − G j 父 2 2 ( H j 父 + λ ) − γ Gain=\frac{G_{j左}^2}{2(H_{j左}+λ)}+\frac{G_{j右}^2}{2(H_{j右}+λ)}-\frac{G_{j父}^2}{2(H_{j父}+λ)}-γ Gain=2(Hj左+λ)Gj左2+2(Hj右+λ)Gj右2−2(Hj父+λ)Gj父2−γ
= G j 左 2 2 ( H j 左 + λ ) + G j 右 2 2 ( H j 右 + λ ) − ( G j 左 + G j 右 ) 2 2 ( H j 左 + H j 右 + λ ) − γ =\frac{G_{j左}^2}{2(H_{j左}+λ)}+\frac{G_{j右}^2}{2(H_{j右}+λ)}-\frac{(G_{j左}+G_{j右})^2}{2(H_{j左}+H_{j右}+λ)}-γ =2(Hj左+λ)Gj左2+2(Hj右+λ)Gj右2−2(Hj左+Hj右+λ)(Gj左+Gj右)2−γ
因此,最终是根据Gain最大的结果,来选取最优的分裂特征及特征值
完美!
程序设计
1. 数据结构:一棵二叉树
- 每个节点存储的数据:
- 当前节点的样本残差集
- 选择分裂的特征及特征值
2. 实现流程:核心步骤
-
获取当前节点的所有特征及特征值
-
遍历每个特征及特征值
- 根据当前特征及特征值分两组
- 计算G左、G右
- G i = ∑ i ∈ I ( j ) ə L ( y i , f m − 1 ( x i ) ) ə f m − 1 ( x i ) G_i=∑_{i∈I(j)} \frac{ə_{L(y_i,f_{m-1}(x_i))}}{ə_{f_{m-1}(x_i)}} Gi=∑i∈I(j)əfm−1(xi)əL(yi,fm−1(xi))
- L ( y i , f m − 1 ( x i ) ) = ( y i − y p r e ) 2 = [ y i − f m − 1 ( x i ) ] 2 L(y_i,f_{m-1}(x_i))=(y_i-y_{pre})^2=[y_i-f_{m-1}(x_i)]^2 L(yi,fm−1(xi))=(yi−ypre)2=[yi−fm−1(xi)]2
- G i = ∑ i ∈ I ( j ) ə L ( y i , f m − 1 ( x i ) ) ə f m − 1 ( x i ) = ∑ i ∈ I ( j ) [ − 2 ( y i − f m − 1 ( x i ) ) ] G_i=∑_{i∈I(j)} \frac{ə_{L(y_i,f_{m-1}(x_i))}}{ə_{f_{m-1}(x_i)}}=∑_{i∈I(j)} [-2(y_i-f_{m-1}(x_i))] Gi=∑i∈I(j)əfm−1(xi)əL(yi,fm−1(xi))=∑i∈I(j)[−2(yi−fm−1(xi))]
- 计算H左、H右
- H i = ∑ i ∈ I ( j ) ə L ( y i , f m − 1 ( x i ) ) 2 ə f m − 1 ( x i ) = ∑ i ∈ I ( j ) [ − 2 ( y i − f m − 1 ( x i ) ) ] ′ = ∑ i ∈ I ( j ) 2 y i H_i=∑_{i∈I(j)} \frac{ə^2_{L(y_i,f_{m-1}(x_i))}}{ə_{f_{m-1}(x_i)}}=∑_{i∈I(j)} [-2(y_i-f_{m-1}(x_i))]'=∑_{i∈I(j)} 2y_i Hi=∑i∈I(j)əfm−1(xi)əL(yi,fm−1(xi))2=∑i∈I(j)[−2(yi−fm−1(xi))]′=∑i∈I(j)2yi
- 计算分组后的Gain值,记录最大值及对应的特征、特征值
- G a i n = G j 左 2 2 ( H j 左 + λ ) + G j 右 2 2 ( H j 右 + λ ) − ( G j 左 + G j 右 ) 2 2 ( H j 左 + H j 右 + λ ) − γ Gain=\frac{G_{j左}^2}{2(H_{j左}+λ)}+\frac{G_{j右}^2}{2(H_{j右}+λ)}-\frac{(G_{j左}+G_{j右})^2}{2(H_{j左}+H_{j右}+λ)}-γ Gain=2(Hj左+λ)Gj左2+2(Hj右+λ)Gj右2−2(Hj左+Hj右+λ)(Gj左+Gj右)2−γ
-
判断Gain最大值情况下,是否可以分裂左右组
- 条件:Gain大于0 则可以分裂,否则停止分裂
-
将最终划分的两个组,设置为左右节点分裂,再分别递归划分
实践遇到的问题
问题1:XGBoost到底是一棵树还是多棵树?
显然是多棵树
问题2:那第一棵树的第一个分裂节点,没有 y p r e y_{pre} ypre怎么计算G值,怎么计算Gain值?
没有Gain值,怎么选择分裂节点?
直击灵魂深处,万事开头难,古人诚不欺我也
所以,为了踏出第一步,需要提前设置一个 y p r e 0 y_{pre0} ypre0初始预测值
这里,可以设置为 y p r e 0 = a v e r a g e ( y t r u e ) y_{pre0}=average(y_{true}) ypre0=average(ytrue),表示第0棵树的所有样本预测值为所有样本真实值的均值,并记录当前预测值 f 0 ( x ) = y p r e 0 f_0(x)=y_{pre0} f0(x)=ypre0,计算出初始残差值 r 0 r_0 r0
-
1、计算出初始残差值 r 0 r_0 r0后,开始建立第一棵树
- 先分裂节点:
- ①获取当前节点的所有特征及特征值
- ②遍历特征及特征值,计算出最大gain
- ③判断是否可以分裂
- ④完成分裂,左右树递归
- 再进行预测:
- ①预测所有样本的预测值 y p r e 1 y_{pre1} ypre1
- ②计算当前所有树的预测结果 f 1 ( x ) = f 0 ( x ) + y p r e 1 f_{1}(x)=f_0(x)+y_{pre1} f1(x)=f0(x)+ypre1
- 先分裂节点:
-
2、计算出第一棵树的残差值 r 1 = y − f 1 ( x ) r_1=y-f_{1}(x) r1=y−f1(x)后,开始建立第二棵树
- 先分裂节点:
- ①获取当前节点的所有特征及特征值
- ②遍历特征及特征值,计算出最大gain
- ③判断是否可以分裂
- ④完成分裂,左右树递归
- 再进行预测:
- ①预测所有样本的预测值 y p r e 2 y_{pre2} ypre2
- ②计算当前所有树的预测结果 f 2 = f 1 ( x ) + y p r e 2 f_{2}=f_1(x)+y_{pre2} f2=f1(x)+ypre2
- 先分裂节点:
-
…
-
这里要区分 f m ( x ) 和 y p r e f_m(x)和y_{pre} fm(x)和ypre的定义
- f m ( x ) f_m(x) fm(x)是对实际y值拟合的预测值, y p r e y_{pre} ypre是对上一轮的残差拟合的预测值, T ( x ) = y p r e T(x)=y_{pre} T(x)=ypre
应该是这样的,估计要创建树的多个对象,然后维护一个全局的数据样本残差表,然后依次根据每棵树对象来更新这个样本残差表
最后模型保留的,就是每棵树以及树的结构,树里每个节点都保留分裂的特征及特征值,保留叶子节点的均值