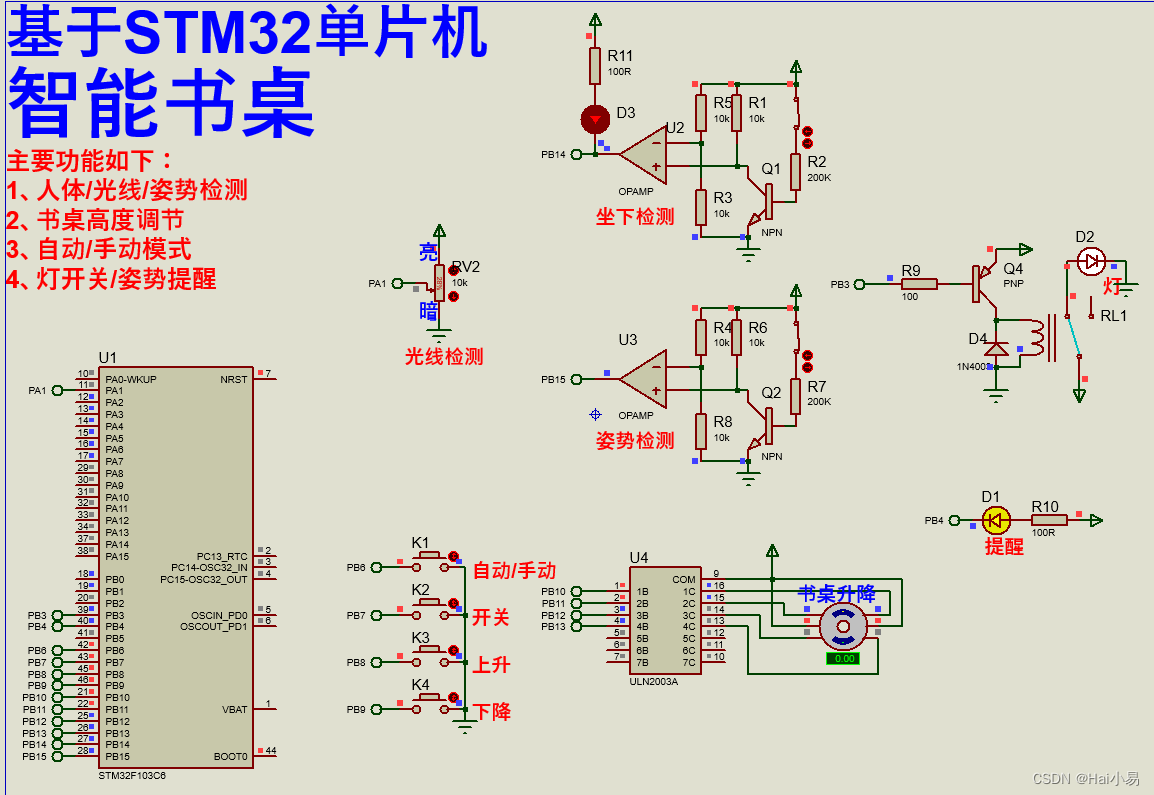
EDA(Exploratory Data Analysis)中文名称为探索性数据分析,是为了在特征工程或模型开发之前对数据有个基本的了解。数据类型通常分为两类:连续类型和离散类型,特征类型不同,我们探索的内容也不同。
1. 特征类型
1.1 连续型特征
定义:取值为数值类型且数值之间的大小具有实际含义。例如:收入。对于连续型变量,需要进行EDA的内容包括:
- 缺失值
- 均值
- 方差
- 标准差
- 最大值
- 最小值
- 中位数
- 众数
- 四分位数
- 偏度
- 最大取值类别对应的样本数
1.2 离散型特征
定义:不具有数学意义的特征。如:性别。对于离散型变量,需要进行EDA的内容包括:
- 缺失值
- 众数
- 取值个数
- 最大取值类别对应的样本数
- 每个取值对应的样本数
2. EDA目的
通过EDA,需要达到以下几个目的:
(1)可以有效发现变量类型、分布趋势、缺失值、异常值等。
(2)缺失值处理:(i)删除缺失值较多的列,通常缺失超过50%的列需要删除;(ii)缺失值填充。对于离散特征,通常将NAN单独作为一个类别;对于连续特征,通常使用均值、中值、0或机器学习算法进行填充。具体填充方法因业务的不同而不同。
(3)异常值处理(主要针对连续特征)。如:Winsorizer方法处理。
(4)类别合并(主要针对离散特征)。如果某个取值对应的样本个数太少,就需要将该取值与其他值合并。因为样本过少会使数据的稳定性变差,且不具有统计意义,可能导致结论错误。由于展示空间有限,通常选择取值个数最少或最多的多个取值进行展示。
(5)删除取值单一的列。
(6)删除最大类别取值数量占比超过阈值的列。
3.实验
3.1 统计变量类型、分布趋势、缺失值、异常值等
#!/usr/bin/pythonimport pandas as pd
import numpy as npdef getTopValues(series, top = 5, reverse = False):"""Get top/bottom n valuesArgs:series (Series): data seriestop (number): number of top/bottom n valuesreverse (bool): it will return bottom n values if True is givenReturns:Series: Series of top/bottom n values and percentage. ['value:percent', None]"""itype = 'top'counts = series.value_counts()counts = list(zip(counts.index, counts, counts.divide(series.size)))if reverse:counts.reverse()itype = 'bottom'template = "{0[0]}:{0[2]:.2%}"indexs = [itype + str(i + 1) for i in range(top)]values = [template.format(counts[i]) if i < len(counts) else None for i in range(top)]return pd.Series(values, index = indexs)def getDescribe(series, percentiles = [.25, .5, .75]):"""Get describe of seriesArgs:series (Series): data seriespercentiles: the percentiles to include in the outputReturns:Series: the describe of data include mean, std, min, max and percentiles"""d = series.describe(percentiles)return d.drop('count')def countBlank(series, blanks = []):"""Count number and percentage of blank values in seriesArgs:series (Series): data seriesblanks (list): list of blank valuesReturns:number: number of blanksstr: the percentage of blank values"""if len(blanks)>0:isnull = series.replace(blanks, None).isnull()else:isnull = series.isnull()n = isnull.sum()ratio = isnull.mean()return (n, "{0:.2%}".format(ratio))def isNumeric(series):"""Check if the series's type is numericArgs:series (Series): data seriesReturns:bool"""return series.dtype.kind in 'ifc'def detect(dataframe):""" Detect dataArgs:dataframe (DataFrame): data that will be detectedReturns:DataFrame: report of detecting"""numeric_rows = []category_rows = []for name, series in dataframe.items():# 缺失值比例nblank, pblank = countBlank(series)# 最大类别取值占比biggest_category_percentage = series.value_counts(normalize=True, dropna=False).values[0] * 100if isNumeric(series):desc = getDescribe(series,percentiles=[.01, .1, .5, .75, .9, .99])details = desc.tolist()details_index = ['mean', 'std', 'min', '1%', '10%', '50%', '75%', '90%', '99%', 'max']row = pd.Series(index=['type', 'size', 'missing', 'unique', 'biggest_category_percentage', 'skew'] + details_index,data=[series.dtype, series.size, pblank, series.nunique(), biggest_category_percentage, series.skew()] + details)row.name = namenumeric_rows.append(row)else:top5 = getTopValues(series)bottom5 = getTopValues(series, reverse=True)details = top5.tolist() + bottom5[::-1].tolist()details_index = ['top1', 'top2', 'top3', 'top4', 'top5', 'bottom5', 'bottom4', 'bottom3', 'bottom2', 'bottom1']row = pd.Series(index=['type', 'size', 'missing', 'unique', 'biggest_category_percentage'] + details_index,data=[series.dtype, series.size, pblank, series.nunique(), biggest_category_percentage] + details)row.name = namecategory_rows.append(row)return pd.DataFrame(numeric_rows), pd.DataFrame(category_rows)demo(数据来自:https://www.kaggle.com/competitions/home-credit-default-risk/data)
import os
import eda
import pandas as pd
import numpy as npdata_dir = "./"df = pd.read_csv(os.path.join(data_dir, "bureau.csv"))
numeric_df, category_df = eda.detect(df)


3.2 缺失值处理(示例)
#连续特征
df[col].fillna(-df[col].mean(), inplace=True)
#离散特征
df[col].fillna('nan', inplace=True)
3.3 删除无用特征
def get_del_columns(df):del_columns = {}for index, row in df.iterrows():if row["unique"] < 2:del_columns[row["Feature"]] = "取值单一"continueif row["missing"] > 90:del_columns[row["Feature"]] = "缺失值数量大于90%"continueif row["biggest_category_percentage"] > 99:del_columns[row["Feature"]] = "取值最多的类别占比超过99%"continuedel_columns[row["Feature"]] = "正常"return del_columns
3.4 异常值处理
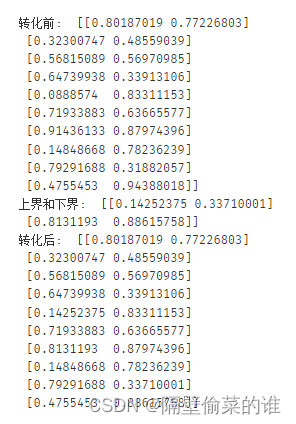
Winsorizer算法(定义某个变量的上界和下界,取值超过边界的话会用边界的值取代):

class Winsorizer():"""Performs Winsorization 1->1*Warning: this class should not be used directly.""" def __init__(self,trim_quantile=0.0):self.trim_quantile=trim_quantileself.winsor_lims=Nonedef train(self,X):# get winsor limitsself.winsor_lims=np.ones([2,X.shape[1]])*np.infself.winsor_lims[0,:]=-np.infif self.trim_quantile>0:for i_col in np.arange(X.shape[1]):lower=np.percentile(X[:,i_col],self.trim_quantile*100)upper=np.percentile(X[:,i_col],100-self.trim_quantile*100)self.winsor_lims[:,i_col]=[lower,upper]def trim(self,X):X_=X.copy()X_=np.where(X>self.winsor_lims[1,:],np.tile(self.winsor_lims[1,:],[X.shape[0],1]),np.where(X<self.winsor_lims[0,:],np.tile(self.winsor_lims[0,:],[X.shape[0],1]),X))return X_
winsorizer = Winsorizer (0.1)
a=np.random.random((10,2))
print("转化前: ", a)
winsorizer.train(a)
print("上界和下界: ", winsorizer.winsor_lims)
b = winsorizer.trim(a)
print("转化后: ", b)
4.总结
这篇文章只总结了EDA的常用做法,实际应用过程中还需要根据具体业务来做调整。