当涉及到数据库管理系统(DBMS)的高级主题时,包括数据库的约束、表的设计以及各种类型的查询,特别是聚合查询、联合查询和合并查询,是非常重要的。这些主题可以帮助我们更好地理解数据库的内部工作机制以及如何有效地操作数据。在这篇博客中,我们将深入探讨这些主题~~
目录
数据库的约束
表的设计
1.一对一关系(One-to-One Relationship):
2.一对多关系(One-to-Many Relationship):
3.多对多关系(Many-to-Many Relationship):
聚合查询
1.SUM():计算列中所有值的总和。
2.AVG():计算列中所有值的平均值。
3.COUNT():计算行的数量或特定列的非空值数量。
4.MAX():找到列中的最大值。
5.MIN():找到列中的最小值。
6.GROUP BY
7.HAVING
联合查询
合并查询
1.UNION操作符:
2.UNION ALL操作符:
数据库的约束
数据库约束是一种用于确保数据完整性和一致性的方法。以下是一些常见的数据库约束类型:
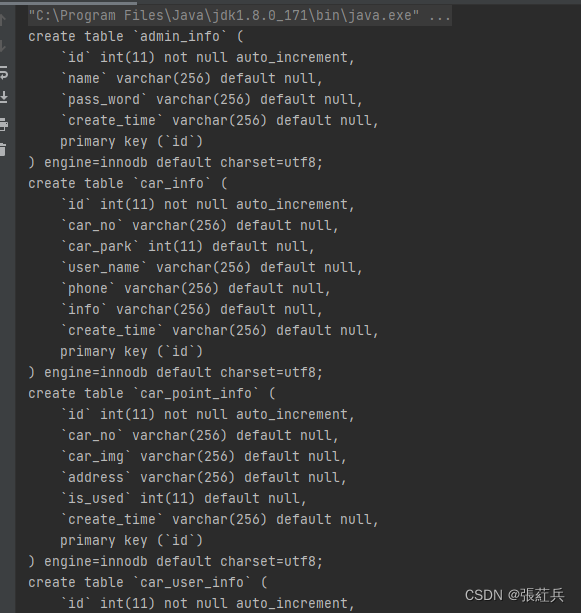
主键约束(Primary Key):主键用于唯一标识表中的每一行数据。它通常是一个自增的整数。例如:
CREATE TABLE Students (student_id INT PRIMARY KEY,first_name VARCHAR(50),last_name VARCHAR(50)
);
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
如图,这里不是3+1,而是100+1~~
-- 主键是 NOT NULL 和 UNIQUE 的结合,可以不用 NOT NULL
id INT PRIMARY KEY auto_increment,

外键约束(Foreign Key):外键用于在两个表之间建立关联关系。例如:
CREATE TABLE Orders (order_id INT PRIMARY KEY,product_id INT,customer_id INT,FOREIGN KEY (product_id) REFERENCES Products(product_id),FOREIGN KEY (customer_id) REFERENCES Customers(customer_id)
);
唯一约束(Unique Constraint):唯一约束确保列中的所有值都是唯一的。例如,如果你想确保电子邮件地址在表中是唯一的:
CREATE TABLE Users (user_id INT PRIMARY KEY,email VARCHAR(100) UNIQUE,password_hash VARCHAR(255)
);
检查约束(Check Constraint):检查约束用于定义特定条件,以确保数据的有效性。例如,如果你只希望存储年龄大于18的用户:
CREATE TABLE Employees (employee_id INT PRIMARY KEY,first_name VARCHAR(50),last_name VARCHAR(50),age INT CHECK (age > 18)
);
默认值约束(Default Constraint):默认值约束用于为列指定默认值。例如,姓名的默认值为“无名氏”

表的设计
表的设计涉及到数据之间的关系,这些关系可以用来描述一对一、一对多、多对一和多对多等不同类型的关系。这些关系有助于确定如何将数据组织成表以满足应用程序的需求。下面我将解释每种关系类型并提供示意图~~
1.一对一关系(One-to-One Relationship):
- 一对一关系表示两个实体之间的关系,其中一个实体的每个记录对应另一个实体的一个记录。
- 示例:一个人可以有一个唯一的身份证号,而每个身份证号只能对应一个人。
- 示意图:

2.一对多关系(One-to-Many Relationship):
- 一对多关系表示一个实体的每个记录可以对应另一个实体的多个记录。
- 示例:一个班级可以有多名学生,但每名学生只属于一个班级。
- 示意图:

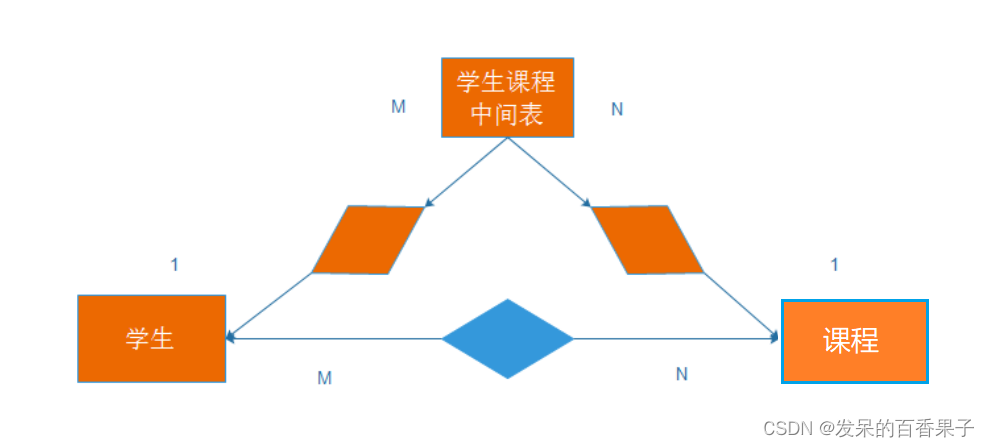
3.多对多关系(Many-to-Many Relationship):
- 多对多关系表示多个实体的记录可以相互关联,一个实体可以与多个实体相关联。
- 示例:多个学生可以选择多门课程,同时一门课程也可以被多个学生选择。
- 示意图:
聚合查询
聚合查询用于对数据进行汇总和计算。以下是一些常见的聚合函数:
1.SUM():计算列中所有值的总和。
2.AVG():计算列中所有值的平均值。
3.COUNT():计算行的数量或特定列的非空值数量。
4.MAX():找到列中的最大值。
5.MIN():找到列中的最小值。
6.GROUP BY
- 作用:GROUP BY 子句用于将查询结果按照一个或多个列的值进行分组。
- 语法:在 SQL 查询中,GROUP BY 子句位于 WHERE 子句之后,可以跟一个或多个列名,用逗号分隔。
- 示例:假设我们有一个包含订单信息的表格,我们想要按照客户 ID 对订单进行分组,并计算每个客户的订单总额。
SELECT customer_id, SUM(order_amount)
FROM orders
GROUP BY customer_id;
在这个例子中,我们将订单表按客户 ID 分组,然后计算每个客户的订单总额。
7.HAVING
- 作用:HAVING 子句用于在 GROUP BY 子句之后对分组结果进行筛选。
- 语法:HAVING 子句紧随 GROUP BY 子句之后,可以包含聚合函数和条件表达式。
- 示例:查询在 2023 年内下了订单总额大于500的客户的订单总额。
SELECT customer_id, SUM(order_amount)
FROM orders
WHERE order_date >= '2023-01-01' AND order_date <= '2023-12-31'
GROUP BY customer_id
HAVING SUM(order_amount) > 500;
联合查询
![]()
笛卡儿积:是集合论中的一个概念,用于表示两个或多个集合之间的所有可能的组合。在数据库中,笛卡尔积通常用于联接(JOIN)操作,其中两个表的笛卡尔积表示了它们之间的所有可能的行组合。
示例: 考虑两个集合 A 和 B,其中 A 包含元素 {1, 2},B 包含元素 {a, b}。它们的笛卡尔积是一个新的集合,包含了所有可能的组合:
以下是一个示意图,展示了集合 A 和 B 的笛卡尔积:
A: {1, 2}
B: {a, b}A × B:(1, a) (1, b)(2, a) (2, b)
联合查询(也称为JOIN查询)用于从多个表中检索相关数据。常见的JOIN类型包括:
- INNER JOIN:返回两个表中匹配的行。
- LEFT JOIN:返回左表中的所有行以及与右表匹配的行。
- RIGHT JOIN:返回右表中的所有行以及与左表匹配的行。
合并查询
1.UNION操作符:
UNION用于合并多个查询的结果集,并自动去重重复的行,只返回唯一的行。
示例:假设我们有两个表A和B,并且我们希望合并它们的结果并去除重复的行。
SELECT column1 FROM A
UNION
SELECT column1 FROM B;
2.UNION ALL操作符:
UNION ALL也用于合并多个查询的结果集,但不去重,返回所有行,包括重复的行。
示例:如果我们希望合并表A和B的结果,包括重复的行。
SELECT column1 FROM A
UNION ALL
SELECT column1 FROM B;