梳理面试过程中Mybatis相关的常见问题。为保证知识点覆盖,参考了《Mybatis从入门到精通》、《深入浅出Mybatis技术原理与实战》、《Mybatis技术内幕》等书籍。
Mybatis 简介
Mybatis 是一款优秀的持久层框架(ORM框架),它支持自定义SQL、存储过程以及高级映射。Mybatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。Mybatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
Mybatis优缺点
在介绍Mybatis优缺点前,先简单介绍下传统JDBC开发存在以下问题:
(1) 频繁地创建数据库连接对象、释放,容易造成系统资源浪费,影响系统性能。可以使用连接池解决这个问题。但是使用jdbc需要自己实现并管理连接池。
(2) sql语句定义、参数设置、结果集处理存在硬编码。实际项目中sql语句变化的可能性较大,一旦发生变化,需要修改java代码,系统需要重新编译,重新发布。(不能很好的适应变化)
(3) 使用preparedStatement向占位符传参数存在硬编码,因为sql语句的where条件不固定(如条件查询),可能多也可能少,修改sql还要修改代码,系统不易维护。
(4) 结果集处理存在重复代码,处理麻烦。如果可以映射成Java对象会比较方便。
Mybatis针对传统JDBC开发存在的问题,进行优化,实现以下功能(优点):
(1) 实现数据库连接配置及管理,无需编写数据库连接、释放等代码。(减少编码)
(2) 将Sql语句配置xml文件中,实现SQL语句与java代码分离,便于统一管理。提供XML标签,支持编写动态SQL语句。
(3) 支持自动将java对象映射至sql语句、自动将sql执行结果映射至java对象。(打通sql与java对象的交互)
但Mybatis也存在以下问题:
(1) SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
(2) SQL语句依赖于特定数据库,无法做到数据库无关,导致数据库移植性差。
Mybatis 是一个足够灵活的ORM框架。对性能的要求很高,或者需求变化较多的项目,Mybatis是比较不错的选择。
Mybatis和hibernate对比
Hibernate和Mybatis都是对jdbc的封装,都是ORM框架,在选择时,要根据业务场景合理选择。Hibernate和Mybatis主要有以下不同:
(1) 映射关系
Mybatis 是一个半自动映射的框架,配置Java对象与sql语句执行结果的对应关系,多表关联关系配置简单。
Hibernate 是一个全表映射的框架,配置Java对象与数据库表的对应关系,多表关联关系配置复杂。
Mybatis 需要编写原生SQL,可以严格控制sql执行性能,灵活度高,但无法做到数据库无关性,如果需要实现支持多种数据库的软件,则需要自定义多套sql映射文件,工作量大。
Hibernate 无需编写原生SQL,可以做到数据库无关性,但是其多表关联关系配置复杂。
(2) SQL优化和移植性
Hibernate 对SQL语句封装,提供了日志、缓存、级联(级联比 Mybatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但SQL语句优化困难。
Mybatis 需要手动编写 SQL,支持动态 SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用SQL语句操作数据库,不支持数据库无关性,但sql语句优化容易。
(3) 开发难易程度和学习成本
Hibernate 是重量级框架,学习使用门槛相对较高,适合于需求相对稳定、对性能要求不高、关联查询场景较少的场景,如:办公自动化系统。
Mybatis 是轻量级框架,学习使用门槛相对较低,适合于需求变化频繁、对性能要求较高、关联查询场景较多的场景,如:互联网电子商务系统。
为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
简单介绍下一条SQL在Mybatis中是如何执行的
这里重点介绍下基于xml编写SQL的场景。
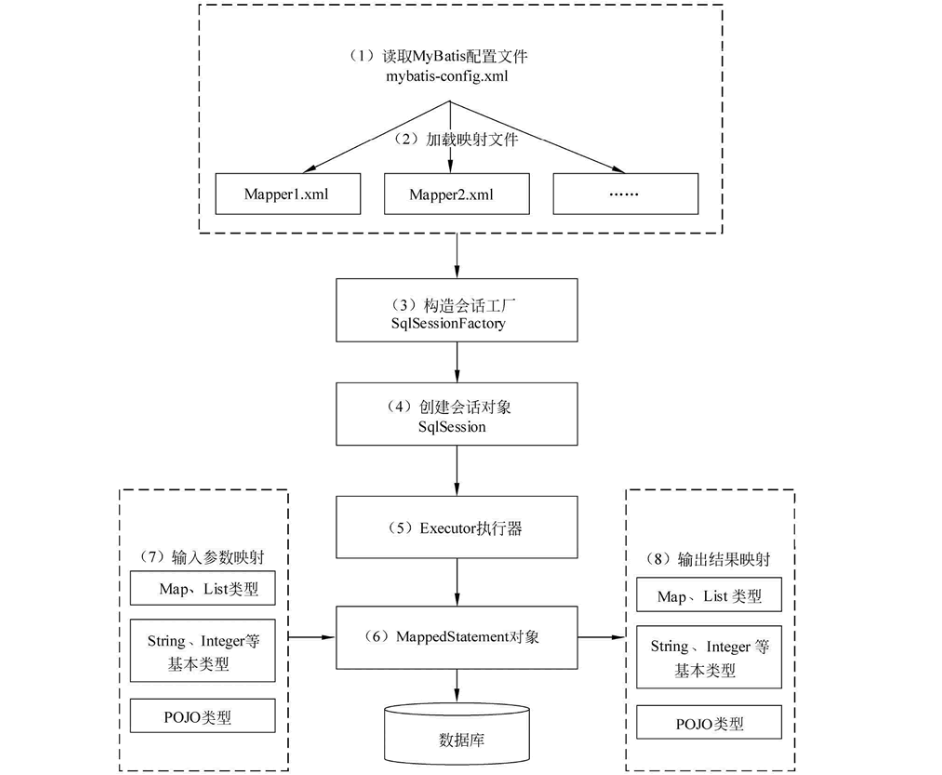
(1) 读取 MyBatis 配置文件。如名为mybatis-config.xml的文件为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
(2) 加载映射文件。映射文件即 xxxMapper.xml文件。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
(3) 构造会话工厂。通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。SqlSessionFactory用来创建SqlSession。
(4) 创建会话实例。会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
(5) 执行Executor(执行器)。MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护。
(6) 访问MappedStatement对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
(7) 输入参数映射。输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于JDBC对preparedStatement对象设置参数的过程。
(8) 输出结果映射。输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于JDBC对结果集的解析过程。
能简单介绍下Mybatis映射器吗?
映射器是Mybatis最强大的工具,也是我们使用Mybatis时使用最多的工具。
在映射器中可以定义的元素有:select、insert、update、delete、resultMap、parameterMap、sql、include、selectKey,此外,还有动态sql的元素trim、where、set、foreach、if、choose、when、otherwise、bind等。
Mybatis如何实现主键回填
在插入记录时,会遇到主键回填的问题。针对这个场景,可以使用keyProperty属性来指定主键字段,并通过useGeneratedKeys来启用数据库内置生成策略,或通过selectKey来自定义生成策略。
Mybatis为什么引入延迟加载?它的实现原理是什么?
使用级联(多表查询或嵌套查询)后,即使不需要关联的信息,在执行select语句时也会被执行,这会造成SQL执行过多导致性能下降,这就是N+1问题。为了解决N+1问题,Mybatis引入延迟加载功能。延迟加载功能默认开启,无需手动开启。如果需要禁止,
延迟记载功能的意义在于,一开始并不取出级联数据,只有当使用级联数据时,才发送SQL去取回数据。
在Mybatis的配置中有两个全局的参数lazyLoadingEnabled和aggressiveLazyLoading。lazyLoadingEnabled用于表示是否启用延迟加载功能(默认是即时加载)。aggressiveLazyLoading表示积极应对延迟加载(层级加载),默认是true。在设置延迟加载时,要主动将该参数设置为false。(也即是说,延迟加载默认是关闭的,需要主动开启)
上述方案是全局延迟加载方案,有时需要实现局部延迟加载。可以在association和collection元素上添加属性fetchType。其中eager表示主动加载,lazy表示延迟加载。局部延迟加载的优先级高于全局延迟加载。
延迟加载的实现原理是动态代理。在默认情况下,Mybatis在3.3及以后的版本,采用JAVASSIST实现动态代理,在低版本,采用CGLIB。举例来说,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。
Mybatis动态sql了解吗?其执行原理可以介绍下吗?有哪些动态sql?
在实际的应用中,常常需要动态的组装SQL。Mybatis提供对SQL语句动态的组装能力,只需用几个基本元素,就可实现大量代码才能实现的功能,这体现了Mybatis的灵活性、高度可配置性和可维护性。
Mybatis也支持在注解中配置SQL,但由于注解中配置功能受限,对于复杂的SQL而言,可读性较差。推荐在Mapper.xml中动态组装SQL。
Mybatis的动态SQL主要分内如下几类:
(1) if元素。判断语句,单条件分支判断。
(2) choose(when、when、otherwise)元素。多条件分支判断,类比Java语言中的switch、case、default。
(3) trim、where、set等元素。辅助元素,用于处理一些SQL拼装问题。
(4) foreach元素。循环语句。在in语句等列举条件中常用。
动态SQL的原理是使用OGNL(Object-Graph Navigation Language)从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。
多数据库支持
Mybatis是一种半自动映射的框架,需要配置Java对象与sql语句执行结果的对应关系,无法做到数据库无关性。Mybatis提供了多数据库支持的能力。Mybatis 可以根据不同的数据库厂商执行不同的语句,这种多厂商的支持是基于映射语句中的 databaseld 属性的。 MyBatis 会加载不带 databaseId 属性和带有匹配当前数据库 databaseld 属性的所有语句。如果同时找到带有 databaseId 和不带 databaseId 的相 同语句,则后者会被舍弃。
接下来以select元素为例,介绍如何实现多数据库支持。
<select id="selectXxx" databaseId="mysql">select id, code, name from Xxx where name like concat (#{name},'%')
</select>
<select id="selectXxx" databaseId="oracle">select id, code, name from Xxx where name like #{userName}||'%'
</select>
需要说明的是,databaseId通过是通过DatabaseMetaData#getDatabaseProductName()返回的字符串进行设置。
注意,尽管Mybatis支持使用if标签配合上下文中的 databaseOd 参数实现多数据库支持,但是因为这种写法在同一个SQL里面包含了不同类型的数据库,不利于后面的维护,不建议使用这种写法。反例如下:
<select id="selectXxx" databaseId=”mysql”>select id, code, name from Xxx <where><if test="name != null and name != ''"><if test="databaseId == 'mysql'">and name like concat (#{name},'%')</if><if test="databaseId == 'oracle'">and name like #{userName}||'%'</if></if></where>
</select>
Mybatis的一级缓存和二级缓存了解吗?该如何使用?
使用缓存可以使应用更快地获取数据,避免频繁的数据库交互,尤其是在查询越多、缓存命中率越高的情况下,使用缓存的作用就越明显。Mybatis作为持久化框架,提供了非常强大的查询缓存特性,可以非常方便地配置和定制使用。
Mybatis提供两级缓存。一般提到Mybatis缓存的时候,都是指二级缓存。一级缓存(也叫本地缓存〉默认会启用,并且不能控制,因此很少会提到。
一级缓存默认开启。 一级缓存存在于SqlSession的生命周期中,在同一个SqlSession中查询时,Mybatis会把执行的方法和参数通过算法生成缓存的键值,将键值和查询结果存入一个Map对象中。如果同一个SqlSession中执行的方法和参数完全一致,那么通过算法会生成相同的键值,当Map缓存对象中己经存在该键值时,则会返回缓存中的对象。
如果在执行方式的时候不想使用一级缓存,可以对该方法做如下修改。
二级缓存默认不开启。Mybatis的二级缓存存在于SqlSessionFactory的生命周期中,对应作用域为Mapper(Namespace)。虽然目前还没接触过同时存在多个SqlSessionFactory的情况,但可以知道,当存在多个SqlSessioηFactory时,它们的缓存都是绑定在各自对象上的,缓存数据在一般情况下是不相通的。只有在使用如Redis这样的缓存数据库时,才可以共享缓存。
将Mybatis二级缓存应用于生产环境,还需考虑二级缓存可能带来的脏读问题及避免策略。
Mybatis的二级缓存是和命名空间绑定的,所以通常情况下每一个Mapper映射文件都拥有自己的二级缓存,不同Mapper的二级缓存互不影响。在关联多表查询时肯定会将该查询放到某个命名空间下的映射文件中,这样一个多表的查询就会缓存在该命名空间的二级缓存中。涉及这些表的增、删、改操作通常不在一个映射文件中,它们的命名空间不同,因此当有数据变化时,多表查询的缓存未必会被清空,这种情况下就会产生脏数据。(二级缓存面向命名空间,不同的Mapper的二级缓存相互隔离。对于多表联合查询,涉及的表的增、删、改操作不在一个映射文件中,当数据变化时,多表查询的缓存未必会被清空,会产生脏数据)
对于多表联合查询存在的脏数据问题,可以使用参照缓存解决。当某几个表可以作为一个业务整体时,通常是让几个会关联的ER表同时使用同一个二级缓存,这样就能解决脏数据问题。
什么是Mybatis的接口绑定?有哪些实现方式?
接口绑定,就是在Mybatis中任意定义接口,然后把接口里面的方法和SQL语句绑定,我们直接调用接口方法就可以,这样比起原来了SqlSession提供的方法我们可以有更加灵活的选择和设置。
接口绑定有两种实现方式:
(1) 注解绑定,就是在接口的方法上面加上 @Select、@Update等注解,里面包含Sql语句来绑定;
(2) 通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名。当Sql语句比较简单时候,用注解绑定,当SQL语句比较复杂时候,用xml绑定,一般用xml绑定的比较多。
推荐使用xml方式,SQL本身就是变化点,同一个接口可能面向不同的数据库有不同的实现。
#{}和${}的区别是什么?
/#{} 是预编译处理,${}是字符串替换。
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值,可以有效的防止SQL注入,提高系统安全性。
Mybatis在处理${}时,就是把${}替换成变量的值,存在SQL注入的风险。
Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页。可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
Mybatis多表查询了解吗?
实现一对一有几种方式?具体怎么操作的?
有联合查询和嵌套查询两种方式。
联合查询是几个表联合查询,只查询一次,通过在resultMap里面配置association节点配置一对一的类就可以完成。
嵌套查询是先查一个表,根据这个表里面的结果的外键id,去再另外一个表里面查询数据,也是通过association配置,但另外一个表的查询通过select属性配置。
实现一对多有几种方式?怎么操作的?
有联合查询和嵌套查询。
联合查询是几个表联合查询,只查询一次,通过在resultMap里面的collection节点配置一对多的类就可以完成。
嵌套查询是先查一个表,根据这个表里面的 结果的外键id,去再另外一个表里面查询数据,也是通过配置collection,但另外一个表的查询通过select节点配置。
参考
https://zhuanlan.zhihu.com/p/347935099 Mybatis面试题
《Mybatis从入门到精通》 刘增辉 著
《深入浅出Mybatis技术原理与实战》 杨开振著
《Mybatis技术内幕》 徐郡明 著