🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

目录
一、Python处理Excel
二、用Python在Excel中查找并替换数据
三、往期推荐
四、文末推荐与福利
一、Python处理Excel
-
Python处理Excel的好处
1.批量操作:当要处理众多Excel文件时,例如出现重复性的手工劳动,那么使用Python就可以实现批量扫描文件、自动化进行处理,利用代码代替手工重复劳动,实现自动化,是Python第一个比Excel强大的地方
2.大型文件,当Excel文件超过几十兆、甚至上百兆时,打开文件很慢、处理文件更加慢,这时候若使用Python,会发现处理几十兆、几百兆甚至几GB都是没有问题的
3.当使用Excel进行复杂的计算时,会使用VBA,但是VBA本身是过时并且复杂的语言,Python是当前最简单且容易实现的一门语言,用Python能够处理比VBA难度更高的业务逻辑
4.Python是通用语言,不仅可以处理Excel,使用Python就可以得到很多额外的功能,例如:爬虫、发布网页的Web服务、与数据库进行连接、同时结合word和PPT进行处理、加入定时任务处理、人工智能分析等,各种额外的功能,这是Excel和VBA所不具备的
-
Python处理Excel主要有三大类库
1.pandas:是Python领域非常重要的,用于数据分析和可视化的类库,在处理Excel中,90%可以利用pandas类库就可以搞掂,利用pandas就可以读取Excel、处理Excel和输出Excel,但是pandas也有缺点,就是无法做到格式类,例如Excel中合并单元、大量复杂的样式(看起来很精美)的时候,用pandas无法搞掂,此时,依然是使用pandas结合openyxl、xlwings来搞掂需求
2.openpyxl:若电脑上未安装office时,也可以使用openpyxl,这个类型可以运行在linux上,并且也可以实现操作大部分Excel格式和样式的功能,使用它配合pandas,也可以完成大部分场景的需求
3.xlwings:比openyxl更加强大,只能运行在Windows或者Mac系统,并且该系统中必须安装了office才能运行,xlwings的原理,就是基于当前系统已经安装好的office软件,来进行功能的拓展来操作Excel
-
使用pandas的时候,经常会结合其他类库,来完成更加复杂的功能
-
requests, bs4:可以完成爬虫的功能
-
flask:可以做网页,把表格展示在网页上
-
Matplotlib:读取表格后,进行可视化
-
sklearn:进行复杂的数据分析时,也可以结合机器学习Sklearn把读取的Excel数据,进行数据分析和机器学习
-
Python-docx:也可以结合Python-docx类库,实现Excel和word的互通
-
smtplib:也可以使用smtplib,讲Excel数据发送邮件出去
-
-
开发环境
操作系统:使用windows, mac都可以
Python版本:系统中需要安装Python3.6以上的版本,Python2已经过期不建议使用,Python3.6以前的版本功能相对弱,最好就是采用Python3.6以上的版本
开发工具:有两个可以选择,jupyter notebook,是个网页编辑器,可以运行Python,常常用于交互性、探索性的开发;pycharm,用于成熟脚本,或者web服务的一些开发;这两个工具可以随意选择。
二、用Python在Excel中查找并替换数据
技术工具:
Python版本:3.9
代码编辑器:jupyter notebook
随着项目的进展,需要经常在Excel业务表格中查找及替换数据,已保证数据与实际项目进度一致。手动一个一个查找,然后替换,效率太低,还容易遗漏。现在我们来试试用Python自动完成查找及替换吧。具体要求如下。

首先,我们先将左边表格中的数据提取,并存入字典data,其键为“查找内容”中的数据,值为“替换内容”中的数据。
from openpyxl import load_workbook #用于读取Excel中的信息
#获取Excel表格中的数据
wb = load_workbook('查找替换.xlsx')#读取工作簿
ws = wb.active #读取活动工作表
data={} #新建字典,用于储存数据for row in range(2,ws.max_row+1):chazhao = str(ws['A' + str(row)].value) #转换成字符串,以免后续比对时出现数据类型冲突tihuan = str(ws['B' + str(row)].value) #转换成字符串,以免后续比对时出现数据类型冲突data[chazhao]=tihuan #键值对应存入字典data
然后,读取目标表格,将D列中的所有数据提取出来,以便后续比对及替换。通过`for`循环遍历“原表”,将D列每个单元格的值提取并存入`ID_list`。然后通过切片`ID_list[:10]`查看前10个数据是否OK。结果显示相当正常。
wb = load_workbook('原表.xlsx') #读取目标工作簿
ws = wb.active
ID_list = [] #新建一个列表,用于储存原表D列的信息
for row in range(2,ws.max_row+1):ID = ws['D' + str(row)].value #遍历整个工作表,将D列的数据逐个存入ID变量ID_list.append(ID) #将读取到的结果存入列表
ID_list[:10] #查看列表中前10个数据
type("") 
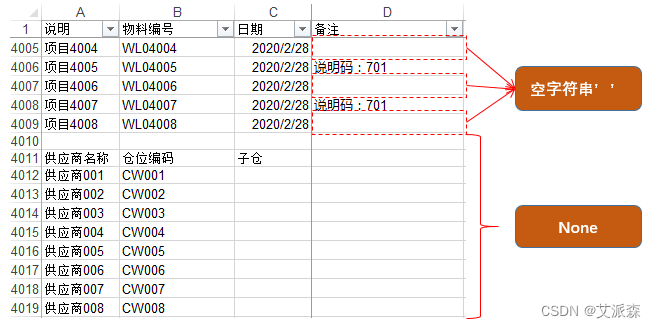
为了比对数据,我们需要将`'说明码:77601'`中的“说明码:”字符拿掉,只保留“77601”。于是调用`split`函数来进行分割,并将分割好的数字部分存入新建的列表`code`。不好,居然报错了,说`ID_list`列表中有"None"(空)类型的数据,而"None"类型的数据是不能使用`split`函数的。目测了一下,`ID_list`列表中除了`'说明码:77601'`和`''`这样的空字符串,没看到None啊。再回来“原表”侦察一下,发现最下面还有一些单元格很有嫌疑。原来是表尾有一些“供应商”和仓位信息,这些信息所在位置对应的D列都是空单元格,其值为"None"。用`ID_list[-10:]`查看最后10个元素,果然都是"None"。
code = [i.split(":")[-1] for i in ID_list]
code
ID_list[-10:]
这样,我们就知道`ID_list`中有三种数据,即含内容的字符串(比如'说明码:77601'),空字符串(比如'')和空值None。因此,需要修改一下字符串分割代码如下。加入了`if`判断语句,如果`ID_list`中的值是None,则放入None占位,以保持列表的值的顺序与原表一致;值不是None,则按":"符号分割,并放分割后的最后一个值`[-1]`进入新列表code。空字符串在这里也要经过`split`分割,但其中没有“:”符号,所以就分割不了,只得直接跳过,最后放入新列表的还是空字符串。
code = []
for i in ID_list:if i == None:# 如果是None,则放入None占位,以保持列表的值的顺序与原表一致code.append(None)else:code.append(i.split(":")[-1]) #不是None,则按":"符号分割,并放分割后的最后一个值进入新列表code
code[:10]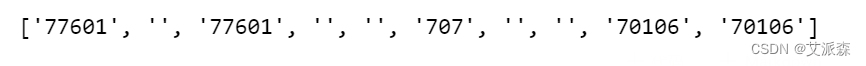
处理完数据后,即可开始查找并替换目标数据了。用`for`循环遍历列表`code`,即原表D列中的数字部分。如果其中的值也存在于data的键中,即语句`if code[i] in data`,则将原表中D列(`column=4`)对应的行中的数据改写成新的值。新的值由两部分组成,一部分是“说明码:”这样的,即`ID_list[i].split(":")[0]`,另一部分则是要替换的数字,即`data[code[i]]`。这样保证只替换了需要替换的数字部分,而保留中文和冒号部分。最后保存为新的文件,替换完成。
for i in range(len(code)):if code[i] in data:ws.cell(row=i+2,column=4).value = ID_list[i].split(":")[0] +":"+ data[code[i]]
wb.save('原表-替换.xlsx') 如果以上不能通过观察原表,发现空值问题,还可以用`enumerate`函数给列表里的所有元素加上索引,以便精确定位`ID_list`中的空值。加上索引后,在转换成列表,并存入新的列表`ID_list_idx`中。观察其中前10个数据,可见索引已加好了。然后遍历新列表,判断其中的值是否为空值,若是则打印其对应的索引编号,这样就能精准定位哪些是空值了,再回到原Excel表,就容易弄清楚发生了什么事啦。其中,新列表中的元素的结构是一个元组,像这样`(2, '说明码:77601')`,`i[0]`是索引`2`,`i[1]`是索引对应的值`说明码:77601`。
ID_list_idx = list(enumerate(ID_list)) #加索引
ID_list_idx[:10]
for i in ID_list_idx: #遍历列表if i[1] == None: #判断索引对应的值是否为空值。i的结构是一个元组,像这样(2, '说明码:77601'),i[0]是索引,i[1]是索引对应的值print(i[0]) #打印索引编号 
三、往期推荐
Python提取pdf中的表格数据(附实战案例)
使用Python自动发送邮件
Python操作ppt和pdf基础
Python操作word基础
Python操作excel基础
使用Python一键提取PDF中的表格到Excel
使用Python批量生成PPT版荣誉证书
使用Python批量处理Excel文件并转为csv文件
四、文末推荐与福利
《码上行动:利用Python与ChatGPT高效搞定Excel数据分析》免费包邮送出3本!

内容简介:
本书在理论方面和实践方面都讲解得浅显易懂,能够让读者快速上手,一步步学会使用Python与Excel相结合进行数据处理与分析。
全书内容分3个部分共12章。第1~4章为入门部分,主要介绍什么是数据分析,以及Python的编程环境和基础语法知识。第5~9章为进阶部分,主要介绍数据处理和分析的各种方法。第10~12章为实战部分,这部分的3个实例综合了本书前面部分的知识点,介绍了如何结合Python与Excel在实际工作中进行数据处理与分析操作。
本书内容由浅入深,且配有案例的素材文件和代码文件,便于读者边学边练。本书还创新性地将ChatGPT引入教学当中,给读者带来全新的学习方式。本书既适合Python和数据分析的初学者学习,也适合希望从事数据分析相关行业的读者学习,还可作为广大职业院校数据分析培训相关专业的教材参考用书。
编辑推荐:
(1)本书面向零基础读者,无须额外的背景知识即可学习Python+Excel进行数据分析。本书讲解细致,便于读者由浅入深地学习。
(2)内容系统、体系完整,可以帮助读者快速全面地了解Python的基本语法并掌握开发能力。
(3)理论与实践相结合,每个理论都有对应的代码示例,读者参考代码示例完成编写,就可以看到实践效果。
(4)本书配有实训与问答,方便读者阅读后尽快巩固知识点,做到举一反三、学以致用。
(5)将AI前沿产品ChatGPT应用到Python进行Excel数据分析学习的过程中,演示了如何利用ChatGPT提高学习和开发的效率。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-09-20 20:00:00
购买链接:https://item.jd.com/14069538.html
名单公布时间:2023-09-20 21:00:00