1、新生代和老年代的比例
默认的,新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ),即:新生代 ( Young ) = 1/3 的堆空间大小。老年代 ( Old ) = 2/3 的堆空间大小。其中,新生代 ( Young ) 被细分为 Eden 和 两个 Survivor 区域,这两个 Survivor 区域分别被命名为 from 和 to,以示区分。
2、java进程CPU使用率过高如何排查
方法一:
1.jps 获取Java进程的PID。
2.jstack pid >> java.txt 导出CPU占用高进程的线程栈。
3.top -H -p PID 查看对应进程的哪个线程占用CPU过高。
4.echo “obase=16; PID” | bc 将线程的PID转换为16进制,大写转换为小写。
5.在第二步导出的Java.txt中查找转换成为16进制的线程PID。找到对应的线程栈。
6.分析负载高的线程栈都是什么业务操作。优化程序并处理问题。
方法二:
1.使用top 定位到占用CPU高的进程PID
top
通过ps aux | grep PID命令
2.获取线程信息,并找到占用CPU高的线程
ps -mp pid -o THREAD,tid,time | sort -rn
3.将需要的线程ID转换为16进制格式
printf "%x\n" tid
4.打印线程的堆栈信息
jstack pid |grep tid -A 30
3、lettuce、jedis和redisTemplate的关系
lettuce、jedis是操作redis的底层客户端,spring对底层客户端操作再次封装成redisTemplate。
springboot2.0以后默认使用lettuce作为操作redis的客户端。它使用netty进行网络通信。
lettuce的bug导致netty堆外内存溢出 -Xmx;netty如果没有指定堆外内存,默认使用-Xmx设置的内存大小,可以通过-Dio.netty.maxDirectMemory进行设置。
解决方案:不能使用-Dio.netty.maxDirectMemory只去调大堆外内存。
- 、升级Lettuce客户端。
2)、切换使用jedis
4、HashMap
当HashMap的key冲突过多时,会导致链表过长。而链表的查询效率很差,因此引入红黑树优化查询效率。
为什么当链表长度大于8时候才会转红黑树而不是一开始直接使用红黑树:
树节点占用空间是普通节点的两倍,因此在开始较短时候使用链表,占用空间少,查询性能也相差不大。但是当链表越来越长,查询效率逐渐变低,为保证查询效率才会舍弃链表转为红黑树,以空间换时间。
根据统计,HashMap链表长度为8的概率仅有不到千万分之一,这时链表的查询性能很差了。在这种极端罕见的情况下才会将链表转换为红黑树。
5、JMM
JMM是Java内存模型,也就是Java Memory Model,简称JMM,本身是一种抽象的概念,实际上并不存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM关于同步的规定:
- 线程解锁前,必须把共享变量的值刷新回主内存
- 线程加锁前,必须读取主内存的最新值,到自己的工作内存
- 加锁和解锁是同一把锁
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写会主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程:

数据传输速率:硬盘 < 内存 < < cache < CPU
上面提到了两个概念:主内存 和 工作内存
-
主内存:就是计算机的内存,也就是经常提到的8G内存,16G内存
-
工作内存:但我们实例化 new student,那么 age = 25 也是存储在主内存中
- 当同时有三个线程同时访问 student中的age变量时,那么每个线程都会拷贝一份,到各自的工作内存,从而实现了变量的拷贝
即:JMM内存模型的可见性,指的是当主内存区域中的值被某个线程写入更改后,其它线程会马上知晓更改后的值,并重新得到更改后的值。
volatile
volatile是jvm提供的轻量级的同步机制。有3大特性:
- 保证可见性
- 不保证原子性
- 禁止指令重排
可见性测试代码:
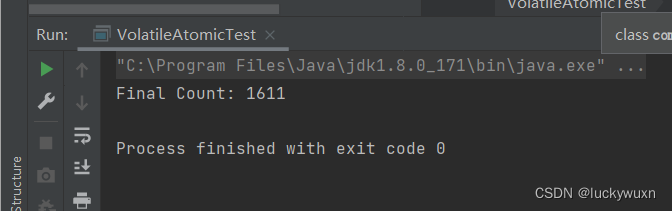
package com.test.mianshi;import java.util.concurrent.TimeUnit;public class VolatileTest {public static void main(String[] args) {Cat cat = new Cat();new Thread(() -> {System.out.println("begin。。。");try {TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {e.printStackTrace();}cat.addNum();System.out.println("===============" + cat.num);}).start();while (cat.num == 0){// println方法中有synchronized关键字触发MESI缓存一致性协议,从而解决可见性问题
// System.out.println("main===============" + cat.num);}System.out.println("main over。。。。");}
}class Cat {volatile int num = 0;public void addNum(){this.num = 70;}}
发生可见性问题,需要两个条件,①各线程操作数据是在缓存中操作,才会存在缓存不一致;②没有触发缓存一致性协议。
原子性
通过前面对JMM的介绍,我们知道,各个线程对主内存中共享变量的操作都是各个线程各自拷贝到自己的工作内存进行操作后在写回到主内存中的。
这就可能存在一个线程AAA修改了共享变量X的值,但是还未写入主内存时,另外一个线程BBB又对主内存中同一共享变量X进行操作,但此时A线程工作内存中共
享变量X对线程B来说是不可见,这种工作内存与主内存同步延迟现象就造成了可见性问题。
原子性:
不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被加塞或者被分割,需要具体完成,要么同时成功,要么同时失败。数据库也经常提到事务具备原子性
例如对一个int类型变量的多线程操作,要保证原子性,可以引入synchronized,或者使用原子包装类AtomicInteger(CAS)。
Volatile禁止指令重排
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令重排,一般分为以下三种:
源代码 -> 编译器优化的重排 -> 指令并行的重排 -> 内存系统的重排 -> 最终执行指令
单线程环境里面确保最终执行结果和代码顺序的结果一致
处理器在进行重排序时,必须要考虑指令之间的数据依赖性
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
Volatile针对指令重排做了啥
Volatile实现禁止指令重排优化,从而避免了多线程环境下程序出现乱序执行的现象
首先了解一个概念,内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
- 保证特定操作的顺序
- 保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)
由于编译器和处理器都能执行指令重排的优化,如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,也就是说 通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。 内存屏障另外一个作用是刷新出各种CPU的缓存数,因此任何CPU上的线程都能读取到这些数据的最新版本。

也就是过在Volatile的写 和 读的时候,加入屏障,防止出现指令重排的
线程安全获得保证
工作内存与主内存同步延迟现象导致的可见性问题
- 可通过synchronized或volatile关键字解决,他们都可以使一个线程修改后的变量立即对其它线程可见
对于指令重排导致的可见性问题和有序性问题
- 可以使用volatile关键字解决,因为volatile关键字的另一个作用就是禁止重排序优化
DCL Double Check Lock 双端检锁机制单例模式
package com.test.mianshi;public class SingletonDemo {private static volatile SingletonDemo instance = null;private SingletonDemo () {System.out.println(Thread.currentThread().getName() + "\t 我是构造方法SingletonDemo");}public static SingletonDemo getInstance() {if(instance == null) {// 同步代码段的时候,进行检测synchronized (SingletonDemo.class) {if(instance == null) {instance = new SingletonDemo();}}}return instance;}public static void main(String[] args) {// 这里的 == 是比较内存地址System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());}
}
DCL(双端检锁)机制不一定是线程安全的,原因是有指令重排的存在,加入volatile可以禁止指令重排
原因是在某一个线程执行到第一次检测的时候,读取到 instance 不为null,instance的引用对象可能没有完成实例化。因为 instance = new SingletonDemo();可以分为以下三步进行完成:
- memory = allocate(); // 1、分配对象内存空间
- instance(memory); // 2、初始化对象
- instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时instance != null
但是我们通过上面的三个步骤,能够发现,步骤2 和 步骤3之间不存在 数据依赖关系,而且无论重排前 还是重排后,程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的。
- memory = allocate(); // 1、分配对象内存空间
- instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时instance != null,但是对象还没有初始化完成
- instance(memory); // 2、初始化对象
这样就会造成什么问题呢?
也就是当我们执行到重排后的步骤2,试图获取instance的时候,会得到null,因为对象的初始化还没有完成,而是在重排后的步骤3才完成,因此执行单例模式的代码时候,就会重新在创建一个instance实例
指令重排只会保证串行语义的执行一致性(单线程),但并不会关心多线程间的语义一致性
所以当一条线程访问instance不为null时,由于instance实例未必已初始化完成,这就造成了线程安全的问题
所以需要引入volatile,来保证出现指令重排的问题,从而保证单例模式的线程安全性
缓存一致性
为什么这里主线程中某个值被更改后,其它线程能马上知晓呢?其实这里是用到了总线嗅探技术
在说嗅探技术之前,首先谈谈缓存一致性的问题,就是当多个处理器运算任务都涉及到同一块主内存区域的时候,将可能导致各自的缓存数据不一。
为了解决缓存一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议进行操作,这类协议主要有MSI、MESI等等。
MESI
当CPU写数据时,如果发现操作的变量是共享变量,即在其它CPU中也存在该变量的副本,会发出信号通知其它CPU将该内存变量的缓存行设置为无效,因此当其它CPU读取这个变量的时,发现自己缓存该变量的缓存行是无效的,那么它就会从内存中重新读取。
总线嗅探
那么是如何发现数据是否失效呢?
这里是用到了总线嗅探技术,就是每个处理器通过嗅探在总线上传播的数据来检查自己缓存值是否过期了,当处理器发现自己的缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置为无效状态,当处理器对这个数据进行修改操作的时候,会重新从内存中把数据读取到处理器缓存中。
总线风暴
总线嗅探技术有哪些缺点?
由于Volatile的MESI缓存一致性协议,需要不断的从主内存嗅探和CAS循环,无效的交互会导致总线带宽达到峰值。因此不要大量使用volatile关键字,至于什么时候使用volatile、什么时候用锁以及Syschonized都是需要根据实际场景的。
6、mybatis-plus分页原理及实际使用
PageHelper内部原理是将传⼊的页码和每页条数赋值给了Page对象,保存到了⼀个本地线程ThreadLoacl中,然后会进⼊Mybatis的拦截器中。然后在拦截器中获取本地线程中保存的分页的参数。最后再将这些分页参数和原本的sql以及内部定义好的sql进⾏拼接完成sql的分页处理。中间会进⾏判断该sql 的类型是查询还是修改操作。如果是查询才会进⼊分页的逻辑并判断封装好的Page对象是否是null,null则不分页,否则分页。IPage内部原理也是基于拦截器,但是这个拦截的是⽅法以及⽅法中的参数,这个也会判断是否是查询操作。如果是查询操作,才会进⼊分页的处理逻辑。进⼊分页逻辑处理后,拦截器会通过反射获取该⽅法的参数进⾏判断是否存在IPage对象的实现类。如果不存在则不进⾏分页,存在则将该参数赋值给IPage对象。然后进⾏拼接sql的处理完成分页操作。
实际项目中使用的是通过pom引入github包下的PageHelper,定义全局aop代理类,在查询方法前计算分页size和当前页码,以及排序,并执行PageHelper.startPage
7、Innodb引擎的存储结构
1、InnoDB引擎的结构分为内存结构和磁盘结构。
2、内存结构由缓冲池(Buffer Pool),写缓冲(Change Buffer),日志缓冲( Log Buffer),自适应hash索引(Adaptive Hash Index)组成。
3、缓冲池(Buffer Pool)主要是缓存表数据与索引数据,加快访问速度。内部采用基于LRU算法的变体算法来管理缓存对象。
4、写缓冲(Change Buffer)主要是缓存辅助索引的更新操作,加快辅助索引的更新速度。
5、日志缓冲( Log Buffer)使大型事务可以运行,而无需在事务提交之前将redo日志数据写入磁盘,节省了磁盘I/O。注意事务提交时刷redo log有三种策略。
8、MyBatis 的插件有哪些
Mybatis中插件分为4种分别是Executor、StatementHandler、ParameterHandler、ResultSetHandler。
其中StatementHandler实例化过程中会初始化ParameterHandler、ResultSetHandler插件。该三种插件都是在Configuration中完成初始化。
MyBatis 主要有以下几个常用的插件:
- 鉴权插件(AuthorizationPlugin)
在每次执行SQL前,检查用户是否有权限执行。通过 onboarding InvocationHandler实现。 - 分页插件(PageHelper)
在执行SQL前,自动加入分页逻辑。通过重写Executor和StatmentHandler实现。 - 缓存插件(EhcachePlugin、OcachePlugin等)
为Mybatis添加二级缓存支持。通过拦截Executor和StatementHandler实现。 - 日志插件(Log4jPlugin、Slf4jPlugin)
使用对应日志框架打印Mybatis执行的SQL及时长。 - 性能分析插件(StatisticsPlugin)
统计Mybatis各类方法的执行时间和调用次数。 - 事务插件(SpringPlugin、SpringManagedTransactionPlugin等)
9、redis客户端有哪些
Jedis:是Redis的Java实现客户端,提供了比较全面的Redis命令的支持,
Redisson:实现了分布式和可扩展的Java数据结构。
Lettuce:高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器。
10、openfeign重试机制
哪些错误响应码需要重试
常见的响应码除了 200 就是 4xx、5xx 了。通常 4xx 错误是不该重试的,因为这是客户端错误。以 400、405 为例,不管重试多少次都是一样的结果,没必要浪费系统资源。
接下来就是 5xx 了, 503 是肯定应该重试的,那 500 要不要重试?这个东西很难去界定,如果说是因为程序本身的 bug 导致,那大概率不用重试,因为还会失败。如果被调用方请求了一个第三方接口,然后因为奇怪的原因返回了奇怪的异常。这种我觉得是可以进行重试的,所以对于 5xx 我觉得可以定义一些特殊的异常标明它们是可重试的
哪些请求类型可以重试
接口的幂等性,这是很重要的一点,你敢对 POST 请求重试吗?即便不是微服务的调用,在设计普通 Rest 接口时我们也要考虑接口的幂等性。对于 POST 这种本身就不幂等的 HTTP 请求,对它开启重试不是自己给自己找 bug 吗。顺便想提一句那些啥请求都 POST 一把梭的公司做微服务调用重试的时候是不是又要加工作量了…当然车到山前必有路,很可能别人会采取不通过 OpenFeign 重试来解决问题~~
我们都知道 HTTP 请求中 GET、HEAD、PUT、DELETE 等方法都是幂等的,所以在正确的实现下我们可以对这些请求类型进行重试。
OpenFeign是通过 Retry 来实现重试的,默认是关闭该功能的,这一点我们可以从 FeignClientsConfiguration里面看到
@Bean
@ConditionalOnMissingBean
public Retryer feignRetryer() {return Retryer.NEVER_RETRY; //代表永远不重试
}
复制代码
所以开启重试我们只需要自己定义一个 Retry 的 Bean 即可。
@Bean
public Retryer retryer(){return new Retryer.Default();
}
11、dockerfile中run、cmd、entrypoint区别
ENTRYPOINT指令和CMD指令类似,都可以让容器在每次启动时执行指定的命令,但二者又有不同。ENTRYPOINT只能是命令 ,而CMD可以是参数,也可以是指令。另外,docker run命令行参数可以覆盖CMD,但不能覆盖ENTRYPOINT。
RUN指令会在前一条命令创建出的镜像的基础上创建一个容器,并在容器中运行命令,在命令结束运行后提交容器为新镜像,新镜像被Dockerfile中的下一条指令使用。
12、springcloud bus的作用
刷新项目配置,具体参考spring cloud学习笔记https://blog.csdn.net/noob9527/article/details/118140519
13、JDK1.8 新特性之Stream
foreach、filter、map
allMatch --- 检查是否匹配所有元素
anyMatch --- 检查是否至少匹配一个元素
noneMatch --- 检查是否没有匹配所有元素
findFirst --- 返回第一个元素
findAny --- 返回当前流中的任意元素
count --- 返回流中元素的总个数
max --- 返回流中最大值
min --- 返回流中最小值
14、分布式事物解决方案
1、两阶段提交(Two-phase Commit,2PC),seata的AT 模式是一种无侵入的分布式事务解决方案。在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
2、TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
- Try 阶段主要是对业务系统做检测及资源预留
- Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
- Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
优点: 跟2PC比起来,实现以及流程相对简单了一些,但数据的一致性比2PC也要差一些
缺点: 缺点还是比较明显的,在2,3步中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
3、mq消息保证最终一致性。
15、springboot自动装配实现原理
1、导入starter,就会导入autoconfigure包。
2、autoconfigure 包里面 有一个文件 META-INF/spring/**org.springframework.boot.autoconfigure.AutoConfiguration**.imports,里面指定的所有启动要加载的自动配置类
3、@EnableAutoConfiguration 会自动的把上面文件里面写的所有自动配置类都导入进来。xxxAutoConfiguration 是有条件注解进行按需加载
4、xxxAutoConfiguration给容器中导入一堆组件,组件都是从 xxxProperties中提取属性值
5、xxxProperties又是和配置文件进行了绑定
效果:导入starter、修改配置文件,就能修改底层行为。
16、k8s中ingress和service通信的区别
Kubernetes中的Ingress和Service都是用于构建和管理应用程序的网络服务的重要组件,两者的作用不同。
- Service: 是Kubernetes中一个抽象的概念,用于定义一组Pod的访问方式和网络访问规则。Service通常用于在内部网络中提供可靠的负载均衡机制,如将服务映射到固定的端口。
具体而言,Service可以将Pod集合作为一个整体来对外提供服务,使用Service的Cluster IP作为虚拟IP地址。当客户端访问此IP时,Kubernetes的Service负载均衡器将流量转发到与此Service相关联的Pod集合中的任意Pod。Service可以使用不同的负载均衡算法,如轮询和IP哈希等,可以与Kubernetes DNS服务结合使用,并通过标签选择器和端口映射提供丰富的筛选和路由选项。
- Ingress: 是一种Kubernetes资源对象,用于从集群外部公开HTTP和HTTPS路由,以便在单个IP上托管多个域。Ingress充当入口控制器,允许网络流量从外部进入集群,并将其路由到正确的Service上。
Ingress与Service之间的关系是,Ingress控制器将HTTP/HTTPS流量路由到正确的Pods/Services,而Service则负责在Kubernetes集群中负载均衡流量。Ingress允许用户以URL路径或主机名为基础定义和路由HTTP和HTTPS流量,允许HTTP和HTTPS在同一IP和端口上进行处理,从而简化了网络架构。
总之,Service主要用于在内部网络中提供负载均衡和访问规则,而Ingress则用于将外部网络流量路由到适当的Service和Pod上,使得在Kubernetes集群中公开应用程序成为可能。
17、jvm垃圾回收机制如何回收互相引用的对象
将一系列被称为GC Roots的变量作为初始的存活对象合集,然后从该合集出发,所有能够被该集合引用到的对象,并将其加入到该集合中,而不能被该合集所引用到的对象,并可对其宣告死亡。
那么什么是 GC Roots 呢?
注意这句话:GC Roots是一些由堆外指向堆内的引用,
一般而言,GC Roots 包括(但不限于)如下几种:
vices,而Service则负责在Kubernetes集群中负载均衡流量。Ingress允许用户以URL路径或主机名为基础定义和路由HTTP和HTTPS流量,允许HTTP和HTTPS在同一IP和端口上进行处理,从而简化了网络架构。
总之,Service主要用于在内部网络中提供负载均衡和访问规则,而Ingress则用于将外部网络流量路由到适当的Service和Pod上,使得在Kubernetes集群中公开应用程序成为可能。

![[libc-2.31 off_by_null] N0wayBack ezheap练习](https://img-blog.csdnimg.cn/18c2e9f5c29c4ea1b197cf08bb39bf19.png)





![深度学习-全连接神经网络-激活函数- [北邮鲁鹏]](https://img-blog.csdnimg.cn/48cb48cf61fc4fae970da98a4abb667b.png)