回顾
1. HTTP Server
在 go 中启动一个 http server 只需短短几行代码
func PingHandler(w http.ResponseWriter, r *http.Request) {io.WriteString(w, "pong!")
}func main() {http.HandleFunc("/ping", PingHandler)log.Fatal(http.ListenAndServe(":8080", nil))
}
2. HTTP Client
func main() {resp, err := http.Get("http://localhost:8080/ping")if err != nil {fmt.Println(err)return}defer resp.Body.Close()body, _ := io.ReadAll(resp.Body)fmt.Println(string(body))
}
net/http 库
本文涉及内容的源码均位于 net/http 库下,各模块的文件位置如下表所示:
| 模块 | 文件 |
|---|---|
| 服务端 | net/http/server.go |
| 客户端——主流程 | net/http/client.go |
| 客户端——构造请求 | net/http/request.go |
| 客户端——网络交互 | net/http/transport.go |
HTTP Client
Client Struct
type Client struct {Transport RoundTripperCheckRedirect func(req *Request, via []*Request) error Jar CookieJarTimeout time.Duration
}
Client 结构体总共由四个字段组成:
- Transport:负责 http 通信的核心部分;
- CheckRedirect:用于指定处理重定向的策略;
- Jar:用于管理和存储请求中的 cookie;
- Timeout:指定客户端请求的最大超时时间,该超时时间包括连接、任何的重定向以及读取相应的时间;
RoundTripper
RoundTripper 是通信模块的 interface,需要实现方法 Roundtrip,即通过传入请求 Request,与服务端交互后获得响应 Response.
type RoundTripper interface {RoundTrip(*Request) (*Response, error)
}
Transport
Transport 实现了 RoundTripper 接口,是 RoundTripper 的实现类, 也是整个请求过程中最重要并且最复杂的结构体,该结构体会在 Transport.roundTrip 中发送 HTTP 请求并等待响应
核心字段包括:
- idleConn:空闲连接 map,实现复用
- DialContext:新连接生成器
type Transport struct {idleConn map[connectMethodKey][]*persistConn // most recently used at end// ...DialContext func(ctx context.Context, network, addr string) (net.Conn, error)// ...
}
Request
http 请求参数结构体.
type Request struct {// 方法Method string// 请求路径URL *url.URL// 请求头Header Header// 请求参数内容Body io.ReadCloser// 服务器主机Host string// query 请求参数Form url.Values// 响应参数 structResponse *Response// 请求链路的上下文ctx context.Context// ...
}
Response
http 响应参数结构体.
type Response struct {// 请求状态,200 为 请求成功StatusCode int // e.g. 200// http 协议,如:HTTP/1.0Proto string // e.g. "HTTP/1.0"// 请求头Header Header// 响应参数内容 Body io.ReadCloser// 指向请求参数Request *Request// ...
}
发起 http 请求链路总览
客户端发起一次 http 请求大致分为几个步骤:
- • 构造 http 请求参数
- • 获取用于与服务端交互的 tcp 连接
- • 通过 tcp 连接发送请求参数
- • 通过 tcp 连接接收响应结果
整体方法链路如下图:
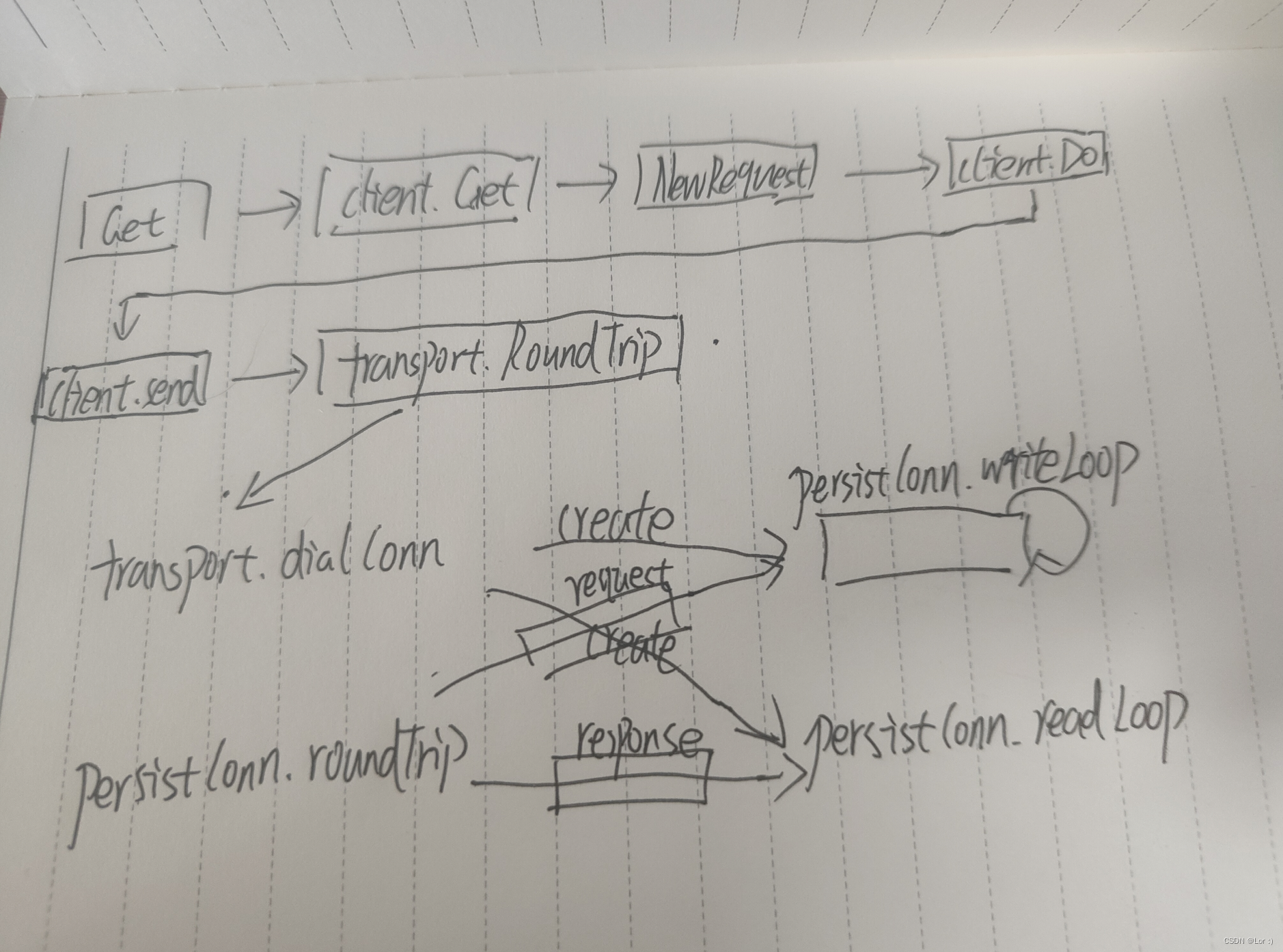
NewRequest
func (c *Client) Get(url string) (resp *Response, err error) {req, err := NewRequest("GET", url, nil)if err != nil {return nil, err}return c.Do(req)
}
NewRequestWithContext 方法中,根据用户传入的 url、method等信息,构造了 Request 实例.
func NewRequestWithContext(ctx context.Context, method, url string, body io.Reader) (*Request, error) {// ...u, err := urlpkg.Parse(url)// ...rc, ok := body.(io.ReadCloser)// ...req := &Request{ctx: ctx,Method: method,URL: u,// ...Header: make(Header),Body: rc,Host: u.Host,}// ...return req, nil
}
Client.Do
发送请求方法时,经由 Client.Do、Client.do 辗转,继而步入到 Client.send 方法中.
func (c *Client) Do(req *Request) (*Response, error) {return c.do(req)
}
func (c *Client) do(req *Request) (retres *Response, reterr error) {var (deadline = c.deadline()resp *Response// ...) for {// ...var err error if resp, didTimeout, err = c.send(req, deadline); err != nil {// ...}// ...}
}
在 Client.send 方法中,会在通过 send 方法发送请求之前和之后,分别对 cookie 进行更新.
func (c *Client) send(req *Request, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {// 设置 cookie 到请求头中if c.Jar != nil {for _, cookie := range c.Jar.Cookies(req.URL) {req.AddCookie(cookie)}}// 发送请求resp, didTimeout, err = send(req, c.transport(), deadline)if err != nil {return nil, didTimeout, err}// 更新 resp 的 cookie 到请求头中if c.Jar != nil {if rc := resp.Cookies(); len(rc) > 0 {c.Jar.SetCookies(req.URL, rc)}}return resp, nil, nil
}
在调用 send 方法时,需要注入 RoundTripper 模块,默认会使用全局单例 DefaultTransport 进行注入,核心逻辑位于 Transport.RoundTrip 方法中,其中分为两个步骤:
- 获取/构造 tcp 连接
- 通过 tcp 连接完成与服务端的交互
var DefaultTransport RoundTripper = &Transport{// ...DialContext: defaultTransportDialContext(&net.Dialer{Timeout: 30 * time.Second,KeepAlive: 30 * time.Second,}),// ...
}func (c *Client) transport() RoundTripper {if c.Transport != nil {return c.Transport}return DefaultTransport
}
func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {// ...resp, err = rt.RoundTrip(req)// ...return resp, nil, nil
}
func (t *Transport) RoundTrip(req *Request) (*Response, error) {return t.roundTrip(req)
}
func (t *Transport) roundTrip(req *Request) (*Response, error) {ctx := req.Context()scheme := req.URL.Schemeif altRT := t.alternateRoundTripper(req); altRT != nil {if resp, err := altRT.RoundTrip(req); err != ErrSkipAltProtocol {return resp, err}}// ...for { // ... treq := &transportRequest{Request: req, trace: trace, cancelKey: cancelKey} // ...pconn, err := t.getConn(treq, cm) // ...resp, err = pconn.roundTrip(treq) // ...}
}
可以将该函数的执行过程分成两个部分:
- 根据 URL 的协议查找并执行自定义的 net/http.RoundTripper 实现;
- 从连接池中获取或者初始化新的持久连接并调用连接的 net/http.persistConn.roundTrip 发出请求;
可以在标准库的 net/http.Transport 中调用 net/http.Transport.RegisterProtocol 为不同的协议注册 net/http.RoundTripper 的实现,在下面的这段代码中就会根据 URL 中的协议选择对应的实现来替代默认的逻辑:
Transport.getConn
获取 tcp 连接的策略分为两步:
- 通过 queueForIdleConn 方法,尝试复用采用相同协议、访问相同服务端的空闲连接
- 倘若无可用连接,则通过 queueForDial 方法,异步创建一个新的连接,并通过接收 ready channel 信号的方式,确认构造连接的工作已经完成.
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) {// 获取连接的请求参数体w := &wantConn{cm: cm,// key 由 http 协议、服务端地址等信息组成key: cm.key(),ctx: ctx,// 标识连接构造成功的信号发射器ready: make(chan struct{}, 1),}// 倘若连接获取失败,在 wantConn.cancel 方法中,会尝试将 tcp 连接放回队列中以供后续复用defer func() {if err != nil {w.cancel(t, err)}}()// 尝试复用指向相同服务端地址的空闲连接if delivered := t.queueForIdleConn(w); delivered {pc := w.pc// ...return pc, nil}// 异步构造新的连接t.queueForDial(w)select {// 通过阻塞等待信号的方式,等待连接获取完成case <-w.ready:// ...return w.pc, w.err// ...}
}
(1)复用连接
- 尝试从 Transport.idleConn 中获取指向同一服务端的空闲连接 persisConn
- 获取到连接后会调用 wantConn.tryDeliver 方法将连接绑定到 wantConn 请求参数上
- 绑定成功后,会关闭 wantConn.ready channel,以唤醒阻塞读取该 channel 的 goroutine
func (t *Transport) queueForIdleConn(w *wantConn) (delivered bool) {// ...if list, ok := t.idleConn[w.key]; ok {// ...for len(list) > 0 && !stop {pconn := list[len(list)-1]// ...delivered = w.tryDeliver(pconn, nil)if delivered {// ...list = list[:len(list)-1] }stop = true}// ...if stop {return delivered}}// ... return false
}
func (w *wantConn) tryDeliver(pc *persistConn, err error) bool {w.mu.Lock()defer w.mu.Unlock()// ...w.pc = pcw.err = err// ...close(w.ready)return true
}
(2)创建连接
在 queueForDial 方法会异步调用 Transport.dialConnFor 方法,创建新的 tcp 连接. 由于是异步操作,所以在上游会通过读 channel 的方式,等待创建操作完成.
这里之所以采用异步操作进行连接创建,有两部分原因:
- 一个 tcp 连接并不是一个静态的数据结构,它是有生命周期的,创建过程中会为其创建负责读写的两个守护协程,伴随而生
- 在上游 Transport.queueForIdleConn 方法中,当通过 select 多路复用的方式,接收到其他终止信号时,可以提前调用 wantConn.cancel 方法打断创建连接的 goroutine. 相比于串行化执行而言,这种异步交互的模式,具有更高的灵活度
func (t *Transport) queueForDial(w *wantConn) {// ...go t.dialConnFor(w) // ...
}
Transport.dialConnFor 方法中,首先调用 Transport.dialConn 创建 tcp 连接 persisConn,接着执行 wantConn.tryDeliver 方法,将连接绑定到 wantConn 上,然后通过关闭 ready channel 操作唤醒上游读 ready channel 的 goroutine.
func (t *Transport) dialConnFor(w *wantConn) {// ...pc, err := t.dialConn(w.ctx, w.cm)delivered := w.tryDeliver(pc, err)// ...
}
Transport.dialConn 方法包含了创建连接的核心逻辑:
- 调用 Transport.dial 方法,最终通过 Tranport.DialContext 成员函数,创建好 tcp 连接,封装到 persistConn 当中
- 异步启动连接的伴生读写协程 readLoop 和 writeLoop 方法,组成提交请求、接收响应的循环
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {pconn = &persistConn{t: t,reqch: make(chan requestAndChan, 1),writech: make(chan writeRequest, 1),// ...}conn, err := t.dial(ctx, "tcp", cm.addr())// ...pconn.conn = conn // ...go pconn.readLoop()go pconn.writeLoop()return pconn, nil
}
func (t *Transport) dial(ctx context.Context, network, addr string) (net.Conn, error) {// ...return t.DialContext(ctx, network, addr)// ...
}
在读协程 persisConn.readLoop 方法中,会读取来自服务端的响应,并添加到 persistConn.reqCh 中,供上游 persistConn.roundTrip 方法接收.
func (pc *persistConn) readLoop() { // ...alive := truefor alive {// ...rc := <-pc.reqch// ...var resp *Response// ...resp, err = pc.readResponse(rc, trace)// ...select{rc.ch <- responseAndError{res: resp}:// ...}// ... }
}
在伴生协程persistConn.wireLoop()方法中,会通过 persistConn.writech 读取到客户端提交的请求,然后将其发送到服务端.
func (pc *persistConn) writeLoop() { for {select {case wr := <-pc.writech:// ...err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))// ... }
}
归还连接
有复用连接的能力,就必然存在归还连接的机制.
首先,在构造新连接中途,倘若被打断,则可能会将连接放回队列以供复用:
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) {// ...// 倘若连接获取失败,在 wantConn.cancel 方法中,会尝试将 tcp 连接放回队列中以供后续复用defer func() {if err != nil {w.cancel(t, err)}}()// ...
}
func (w *wantConn) cancel(t *Transport, err error) {// ...if pc != nil {t.putOrCloseIdleConn(pc)}
}
func (t *Transport) putOrCloseIdleConn(pconn *persistConn) {if err := t.tryPutIdleConn(pconn); err != nil {pconn.close(err)}
}
func (t *Transport) tryPutIdleConn(pconn *persistConn) error {// ...key := pconn.cacheKey// ...t.idleConn[key] = append(idles, pconn)// ...return nil
}
其次,倘若与服务端的一轮交互流程结束,也会将连接放回队列以供复用.
func (pc *persistConn) readLoop() {tryPutIdleConn := func(trace *httptrace.ClientTrace) bool {if err := pc.t.tryPutIdleConn(pc); err != nil {// ...}// ...}// ...alive := truefor alive {// ...select {case bodyEOF := <-waitForBodyRead:// ...tryPutIdleConn(trace)// ...} }}
persistConn.roundTrip

一个连接 persistConn 是一个具有生命特征的角色. 它本身伴有 readLoop 和 writeLoop 两个守护协程,与上游应用者之间通过 channel 进行读写交互.
而其中扮演应用者这一角色的,正式本小节谈到的主流程中的方法:persistConn.roundTrip:
- 首先将 http 请求通过 persistConn.writech 发送给连接的守护协程 writeLoop,并进一步传送到服务端
- 其次通过读取 resc channel,接收由守护协程 readLoop 代理转发的客户端响应数据.
func (pc *persistConn) roundTrip(req *transportRequest) (resp *Response, err error) {// ...pc.writech <- writeRequest{req, writeErrCh, continueCh}resc := make(chan responseAndError)pc.reqch <- requestAndChan{req: req.Request,cancelKey: req.cancelKey,ch: resc,// ...}// ...for { select {// ...case re := <-resc:// ...return re.res, nil// ...}}
}
调用关键流程
- step1 - http.NewRequest(method, url string, body io.Reader) 创建请求
- step2 - http.Client.Do(req *Request) 发送请求&接收应答
整个http.Client.Do逻辑分为两道,第一道执行send发送请求接收Response,关闭Req.Body;第二层对请求执行重定向等操作(若需要redirect),并关闭Resp.Bodyhttp.Client.Do(req) => send(ireq *Request, rt RoundTripper, deadline time.Time)-> setRequestCancel(req, rt, deadline) 设置请求超时时间-> http.Client.RoundTrip(req) => http.Client.RoundTrip(req) -> http.Transport.t.getConn(treq, cm) 获取连接(新创建的 or 复用空闲连接) -> http.Transport.queueForIdleConn(w *wantConn) 获取空闲连接-> http.Transport.dialConnFor(w *wantConn) -> http.Transport.dialConn(ctx context.Context, cm connectMethod) 创建新连接-> http.Transport.dial(ctx context.Context, network, addr string) -> http.Transport.DialContext(net.Dialer.DialContext)-> http.persistConn.readLoop() read http.Response(读取响应内容,并构建http.Response)-> http.persistConn.writeLoop() write http.Request(发送请求) -> http.persistConn.roundTrip(treq) 发送请求,读取Response并返回
- step3 - http.Response.Body.Close() 关闭应答Body
HTTP Server
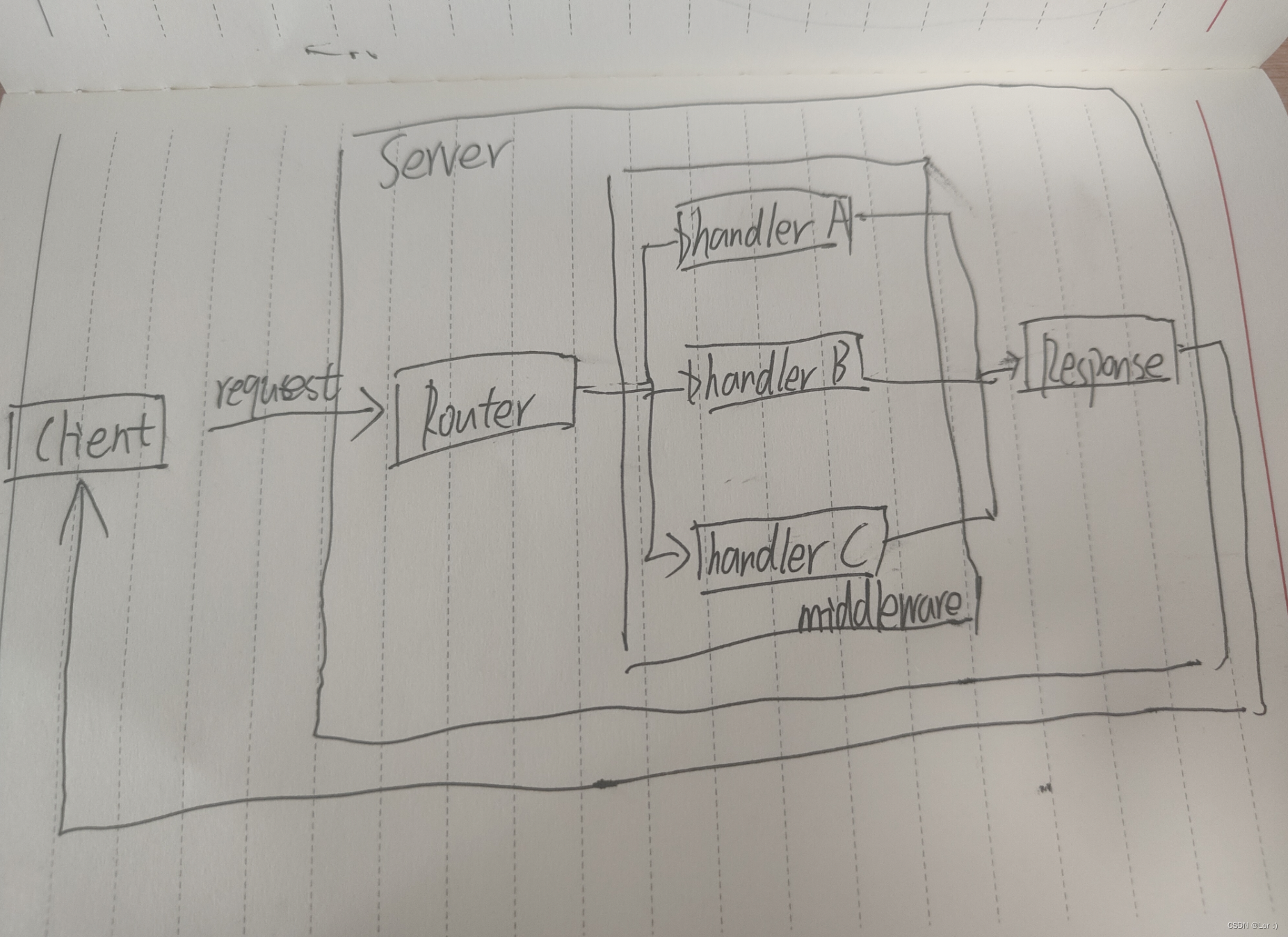
启动 http 服务
func PingHandler(w http.ResponseWriter, r *http.Request) {io.WriteString(w, "pong!")
}func main() {http.HandleFunc("/ping", PingHandler)log.Fatal(http.ListenAndServe(":8080", nil))
}
- 调用 http.HandleFunc 注册 handler 函数
- 调用 http.ListenAndServe 启动 http 服务
路由注册
首先,我们调用http.HandleFunc("/ping", PingHandler)注册路径处理函数,这里将路径/ping的处理函数设置为PingHandler。处理函数的类型必须是:
func (http.ResponseWriter, *http.Request)
其中*http.Request表示 HTTP 请求对象,该对象包含请求的所有信息,如 URL、首部、表单内容、请求的其他内容等。
http.ResponseWriter是一个接口类型:
// net/http/server.go
type ResponseWriter interface {Header() HeaderWrite([]byte) (int, error)WriteHeader(statusCode int)
}
用于向客户端发送响应,实现了ResponseWriter接口的类型显然也实现了io.Writer接口。所以在处理函数index中,可以调用fmt.Fprintln() 和 io.WriteString()向ResponseWriter写入响应信息。
仔细阅读net/http包中HandleFunc()函数的源码:
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {DefaultServeMux.HandleFunc(pattern, handler)
}
我们发现它直接调用了一个名为DefaultServeMux对象的HandleFunc()方法。DefaultServeMux是ServeMux类型的实例:
type ServeMux struct {mu sync.RWMutexm map[string]muxEntryes []muxEntry // slice of entries sorted from longest to shortest.hosts bool // whether any patterns contain hostnames
}var DefaultServeMux = &defaultServeMux
var defaultServeMux ServeMux
像这种提供默认类型实例的用法在 Go 语言的各个库中非常常见,在默认参数就已经足够的场景中使用默认实现很方便。ServeMux保存了注册的所有路径和处理函数的对应关系。ServeMux.HandleFunc()方法如下:
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {mux.Handle(pattern, HandlerFunc(handler))
}
这里将处理函数handler转为HandlerFunc类型,然后调用ServeMux.Handle()方法注册。注意这里的HandlerFunc(handler)是类型转换,而非函数调用,类型HandlerFunc的定义如下:
type HandlerFunc func(ResponseWriter, *Request)func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {f(w, r)
}
HandlerFunc实际上是以函数类型func(ResponseWriter, *Request)为底层类型,为HandlerFunc类型定义了方法ServeHTTP。是的,Go 语言允许为(基于)函数的类型定义方法。Serve.Handle()方法只接受类型为接口Handler的参数:
type Handler interface {ServeHTTP(ResponseWriter, *Request)
}func (mux *ServeMux) Handle(pattern string, handler Handler) {if mux.m == nil {mux.m = make(map[string]muxEntry)}e := muxEntry{h: handler, pattern: pattern}if pattern[len(pattern)-1] == '/' {mux.es = appendSorted(mux.es, e)}mux.m[pattern] = e
}
显然HandlerFunc实现了接口Handler。HandlerFunc类型只是为了方便注册函数类型的处理器。我们当然可以直接定义一个实现Handler接口的类型,然后注册该类型的实例:
type greeting stringfunc (g greeting) ServeHTTP(w http.ResponseWriter, r *http.Request) {fmt.Fprintln(w, g)
}http.Handle("/greeting", greeting("Welcome, pepsi"))
我们基于string类型定义了一个新类型greeting,然后为它定义一个方法ServeHTTP()(实现接口Handler),最后调用http.Handle()方法注册该处理器。
注册了处理逻辑后,调用http.ListenAndServe(":8080", nil)监听本地计算机的 8080 端口,开始处理请求。下面看源码的处理:
func ListenAndServe(addr string, handler Handler) error {server := &Server{Addr: addr, Handler: handler}return server.ListenAndServe()
}
ListenAndServe创建了一个Server类型的对象:
type Server struct {Addr stringHandler HandlerTLSConfig *tls.ConfigReadTimeout time.DurationReadHeaderTimeout time.DurationWriteTimeout time.DurationIdleTimeout time.Duration
}
Server结构体有比较多的字段,我们可以使用这些字段来调节 Web 服务器的参数,如上面的ReadTimeout/ReadHeaderTimeout/WriteTimeout/IdleTimeout用于控制读写和空闲超时。在该方法中,先调用net.Listen()监听端口,将返回的net.Listener作为参数调用Server.Serve()方法:
func (srv *Server) ListenAndServe() error {addr := srv.Addrln, err := net.Listen("tcp", addr)if err != nil {return err}return srv.Serve(ln)
}
在Server.Serve()方法中,使用一个无限的for循环,不停地调用Listener.Accept()方法接受新连接,开启新 goroutine 处理新连接:
func (srv *Server) Serve(l net.Listener) error {var tempDelay time.Duration // how long to sleep on accept failurefor {rw, err := l.Accept()if err != nil {if ne, ok := err.(net.Error); ok && ne.Temporary() {if tempDelay == 0 {tempDelay = 5 * time.Millisecond} else {tempDelay *= 2}if max := 1 * time.Second; tempDelay > max {tempDelay = max}srv.logf("http: Accept error: %v; retrying in %v", err, tempDelay)time.Sleep(tempDelay)continue}return err}tempDelay = 0c := srv.newConn(rw)go c.serve(connCtx)}
}
这里有一个指数退避策略的用法。如果l.Accept()调用返回错误,我们判断该错误是不是临时性地(ne.Temporary())。如果是临时性错误,Sleep一小段时间后重试,每发生一次临时性错误,Sleep的时间翻倍,最多Sleep 1s。获得新连接后,将其封装成一个conn对象(srv.newConn(rw)),创建一个 goroutine 运行其serve()方法。省略无关逻辑的代码如下:
func (c *conn) serve(ctx context.Context) {for {w, err := c.readRequest(ctx)serverHandler{c.server}.ServeHTTP(w, w.req)w.finishRequest()}
}
serve()方法其实就是不停地读取客户端发送地请求,创建serverHandler对象调用其ServeHTTP()方法去处理请求,然后做一些清理工作。serverHandler只是一个中间的辅助结构,代码如下:
type serverHandler struct {srv *Server
}func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {handler := sh.srv.Handlerif handler == nil {handler = DefaultServeMux}handler.ServeHTTP(rw, req)
}
从Server对象中获取Handler,这个Handler就是调用http.ListenAndServe()时传入的第二个参数。在Hello World的示例代码中,我们传入了nil。所以这里handler会取默认值DefaultServeMux。调用DefaultServeMux.ServeHTTP()方法处理请求:
func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) {h, _ := mux.Handler(r)h.ServeHTTP(w, r)
}
mux.Handler(r)通过请求的路径信息查找处理器,然后调用处理器的ServeHTTP()方法处理请求:
func (mux *ServeMux) Handler(r *Request) (h Handler, pattern string) {host := stripHostPort(r.Host)return mux.handler(host, r.URL.Path)
}func (mux *ServeMux) handler(host, path string) (h Handler, pattern string) {h, pattern = mux.match(path)return
}func (mux *ServeMux) match(path string) (h Handler, pattern string) {v, ok := mux.m[path]if ok {return v.h, v.pattern}for _, e := range mux.es {if strings.HasPrefix(path, e.pattern) {return e.h, e.pattern}}return nil, ""
}
上面的代码省略了大量的无关代码,在match方法中,首先会检查路径是否精确匹配mux.m[path]。如果不能精确匹配,后面的for循环会匹配路径的最长前缀。只要注册了/根路径处理,所有未匹配到的路径最终都会交给/路径处理。为了保证最长前缀优先,在注册时,会对路径进行排序。所以mux.es中存放的是按路径排序的处理列表:
func appendSorted(es []muxEntry, e muxEntry) []muxEntry {n := len(es)i := sort.Search(n, func(i int) bool {return len(es[i].pattern) < len(e.pattern)})if i == n {return append(es, e)}es = append(es, muxEntry{})copy(es[i+1:], es[i:])es[i] = ereturn es
}
创建ServeMux
调用http.HandleFunc()/http.Handle()都是将处理器/函数注册到ServeMux的默认对象DefaultServeMux上。使用默认对象有一个问题:不可控。
一来Server参数都使用了默认值,二来第三方库也可能使用这个默认对象注册一些处理,容易冲突。更严重的是,我们在不知情中调用http.ListenAndServe()开启 Web 服务,那么第三方库注册的处理逻辑就可以通过网络访问到,有极大的安全隐患。所以,除非在示例程序中,否则建议不要使用默认对象。
我们可以使用http.NewServeMux()创建一个新的ServeMux对象,然后创建http.Server对象定制参数,用ServeMux对象初始化Server的Handler字段,最后调用Server.ListenAndServe()方法开启 Web 服务:
func main() {mux := http.NewServeMux()mux.HandleFunc("/", index)mux.Handle("/greeting", greeting("Welcome, pepsi"))server := &http.Server{Addr: ":8080",Handler: mux,ReadTimeout: 20 * time.Second,WriteTimeout: 20 * time.Second,}server.ListenAndServe()
}
Middleware
有时候需要在请求处理代码中增加一些通用的逻辑,如统计处理耗时、记录日志、捕获宕机等等。如果在每个请求处理函数中添加这些逻辑,代码很快就会变得不可维护,添加新的处理函数也会变得非常繁琐。所以就有了中间件的需求。
中间件有点像面向切面的编程思想,但是与 Java 语言不同。在 Java 中,通用的处理逻辑(也可以称为切面)可以通过反射插入到正常逻辑的处理流程中,在 Go 语言中基本不这样做。
在 Go 中,中间件是通过函数闭包来实现的。Go 语言中的函数是第一类值,既可以作为参数传给其他函数,也可以作为返回值从其他函数返回。我们前面介绍了处理器/函数的使用和实现。那么可以利用闭包封装已有的处理函数。
首先,基于函数类型func(http.Handler) http.Handler定义一个中间件类型:
type Middleware func(http.Handler) http.Handler
接下来我们来编写中间件,最简单的中间件就是在请求前后各输出一条日志:
func WithLogger(handler http.Handler) http.Handler {return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {logger.Printf("path:%s process start...\n", r.URL.Path)defer func() {logger.Printf("path:%s process end...\n", r.URL.Path)}()handler.ServeHTTP(w, r)})
}
实现很简单,通过中间件封装原来的处理器对象,然后返回一个新的处理函数。在新的处理函数中,先输出开始处理的日志,然后用defer语句在函数结束后输出处理结束的日志。接着调用原处理器对象的ServeHTTP()方法执行原处理逻辑。
类似地,我们再来实现一个统计处理耗时的中间件:
func Metric(handler http.Handler) http.HandlerFunc {return func (w http.ResponseWriter, r *http.Request) {start := time.Now()defer func() {logger.Printf("path:%s elapsed:%fs\n", r.URL.Path, time.Since(start).Seconds())}()time.Sleep(1 * time.Second)handler.ServeHTTP(w, r)}
}
Metric中间件封装原处理器对象,开始执行前记录时间,执行完成后输出耗时。为了能方便看到结果,我在上面代码中添加了一个time.Sleep()调用。
最后,由于请求的处理逻辑都是由功能开发人员(而非库作者)自己编写的,所以为了 Web 服务器的稳定,我们需要捕获可能出现的 panic。PanicRecover中间件如下:
func PanicRecover(handler http.Handler) http.Handler {return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {defer func() {if err := recover(); err != nil {logger.Println(string(debug.Stack()))}}()handler.ServeHTTP(w, r)})
}
调用recover()函数捕获 panic,输出堆栈信息,为了防止程序异常退出。实际上,在conn.serve()方法中也有recover(),程序一般不会异常退出。但是自定义的中间件可以添加我们自己的定制逻辑。
现在我们可以这样来注册处理函数:
mux.Handle("/a", PanicRecover(WithLogger(Metric(http.HandlerFunc(index)))))
mux.Handle("/greeting", PanicRecover(WithLogger(Metric(greeting("welcome, pepsi")))))
这种方式略显繁琐,我们可以编写一个帮助函数,它接受原始的处理器对象,和可变的多个中间件。对处理器对象应用这些中间件,返回新的处理器对象:
func applyMiddlewares(handler http.Handler, middlewares ...Middleware) http.Handler {for i := len(middlewares)-1; i >= 0; i-- {handler = middlewares[i](handler)}return handler
}
注意应用顺序是从右到左的,即右结合,越靠近原处理器的越晚执行。
利用帮助函数,注册可以简化为:
middlewares := []Middleware{PanicRecover,WithLogger,Metric,
}
mux.Handle("/", applyMiddlewares(http.HandlerFunc(index), middlewares...))
mux.Handle("/greeting", applyMiddlewares(greeting("welcome, pepsi"), middlewares...))
上面每次注册处理逻辑都需要调用一次applyMiddlewares()函数,还是略显繁琐。我们可以这样来优化,封装一个自己的ServeMux结构,然后定义一个方法Use()将中间件保存下来,重写Handle/HandleFunc将传入的http.HandlerFunc/http.Handler处理器包装中间件之后再传给底层的ServeMux.Handle()方法:
type MyMux struct {*http.ServeMuxmiddlewares []Middleware
}func NewMyMux() *MyMux {return &MyMux{ServeMux: http.NewServeMux(),}
}func (m *MyMux) Use(middlewares ...Middleware) {m.middlewares = append(m.middlewares, middlewares...)
}func (m *MyMux) Handle(pattern string, handler http.Handler) {handler = applyMiddlewares(handler, m.middlewares...)m.ServeMux.Handle(pattern, handler)
}func (m *MyMux) HandleFunc(pattern string, handler http.HandlerFunc) {newHandler := applyMiddlewares(handler, m.middlewares...)m.ServeMux.Handle(pattern, newHandler)
}
注册时只需要创建MyMux对象,调用其Use()方法传入要应用的中间件即可:
middlewares := []Middleware{PanicRecover,WithLogger,Metric,
}
mux := NewMyMux()
mux.Use(middlewares...)
mux.HandleFunc("/", index)
mux.Handle("/greeting", greeting("welcome, pepsi"))
这种方式简单易用,但是也有它的问题,最大的问题是必须先设置好中间件,然后才能调用Handle/HandleFunc注册,后添加的中间件不会对之前注册的处理器/函数生效。
为了解决这个问题,我们可以改写ServeHTTP方法,在确定了处理器之后再应用中间件。这样后续添加的中间件也能生效。很多第三方库都是采用这种方式。http.ServeMux默认的ServeHTTP()方法如下:
func (m *ServeMux) ServeHTTP(w http.ResponseWriter, r *http.Request) {if r.RequestURI == "*" {if r.ProtoAtLeast(1, 1) {w.Header().Set("Connection", "close")}w.WriteHeader(http.StatusBadRequest)return}h, _ := m.Handler(r)h.ServeHTTP(w, r)
}
改造这个方法定义MyMux类型的ServeHTTP()方法也很简单,只需要在m.Handler(r)获取处理器之后,应用当前的中间件即可:
func (m *MyMux) ServeHTTP(w http.ResponseWriter, r *http.Request) {// ...h, _ := m.Handler(r)// 只需要加这一行即可h = applyMiddlewares(h, m.middlewares...)h.ServeHTTP(w, r)
}
思考题
再思考一下有没有其他实现方式
放在闭包中延迟执行
func (mux *MyMux) HandleFunc(pattern string, handler http.HandlerFunc) {mux.ServeMux.Handle(pattern, http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {h := applyMiddlewares(handler, mux.middlewares...)h.ServeHTTP(w, r)}))
}
思考题
根据最长前缀的逻辑,如果键入localhost:8080/hello/a/b/c/,应该会匹配/hello路径。 如果键入localhost:8080/a/b/c/,应该会匹配/路径。是这样么?
/hello/




![[网鼎杯 2020 朱雀组]Nmap 通过nmap写入木马 argcmd过滤实现逃逸](https://img-blog.csdnimg.cn/45de470718864a15ba9c255414e8ee05.png)