2022年,大模型技术的出色表现让人们瞩目。随着深度学习和大数据技术的发展,大模型在很多领域的应用已经成为可能。许多公司开始探索如何将大模型技术应用于自己的业务中,智能客服也不例外。
智能客服是现代企业中非常重要的一部分,它可以提供更好的客户服务,提高客户满意度,并增强企业的竞争力。传统的智能客服系统通常基于规则和模板构建,但是这些方法无法处理复杂的语义和上下文信息,因此有时候会出现误解客户意图的情况。
而大模型技术的应用可以很好地解决这个问题。大模型是一种深度学习模型,它通过对大量语料库进行训练,可以学习到丰富的语言模式和语义信息。在智能客服领域,大模型可以学习到客户的问题和回答之间的模式,从而更准确地理解客户的意图。
基于大模型的智能客服系统可以进行更加精准的意图识别和自然语言生成,从而为客户提供更加个性化的服务。这种服务不仅快速响应了客户的问题,还可以通过预测客户的需求来提供更加个性化的服务。此外,大模型还可以进行文本摘要、文本分类等任务,从而为智能客服提供更多的功能。
在2022年,不少公司已经成功地将大模型技术应用在了自己的智能客服上。例如,美国一家大型银行就使用大模型技术来构建智能客服系统。该银行的数据科学家使用无监督学习来训练一个大模型,然后将其应用于客服对话系统中。通过使用这个大模型,银行能够更好地理解客户的问题并快速响应该要求。这个智能客服系统不仅能够理解客户的语言和意图,还可以提供更加个性化的服务。
下面来看看大模型如何帮助智能客服搭建知识库:
1.知识抽取:根据文章自动生成QA对
1.1示例
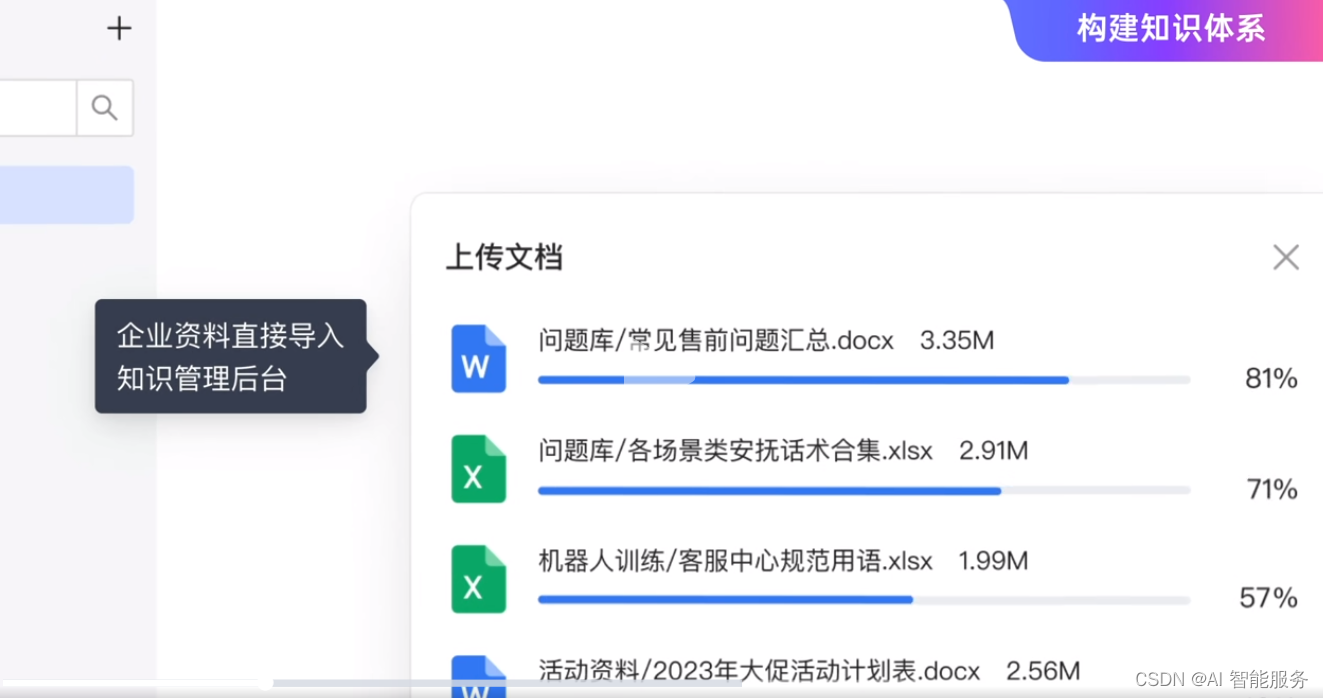
实操:让文心一言写一篇马斯克的文章

下面我让文心一言提炼出10个QA问答:
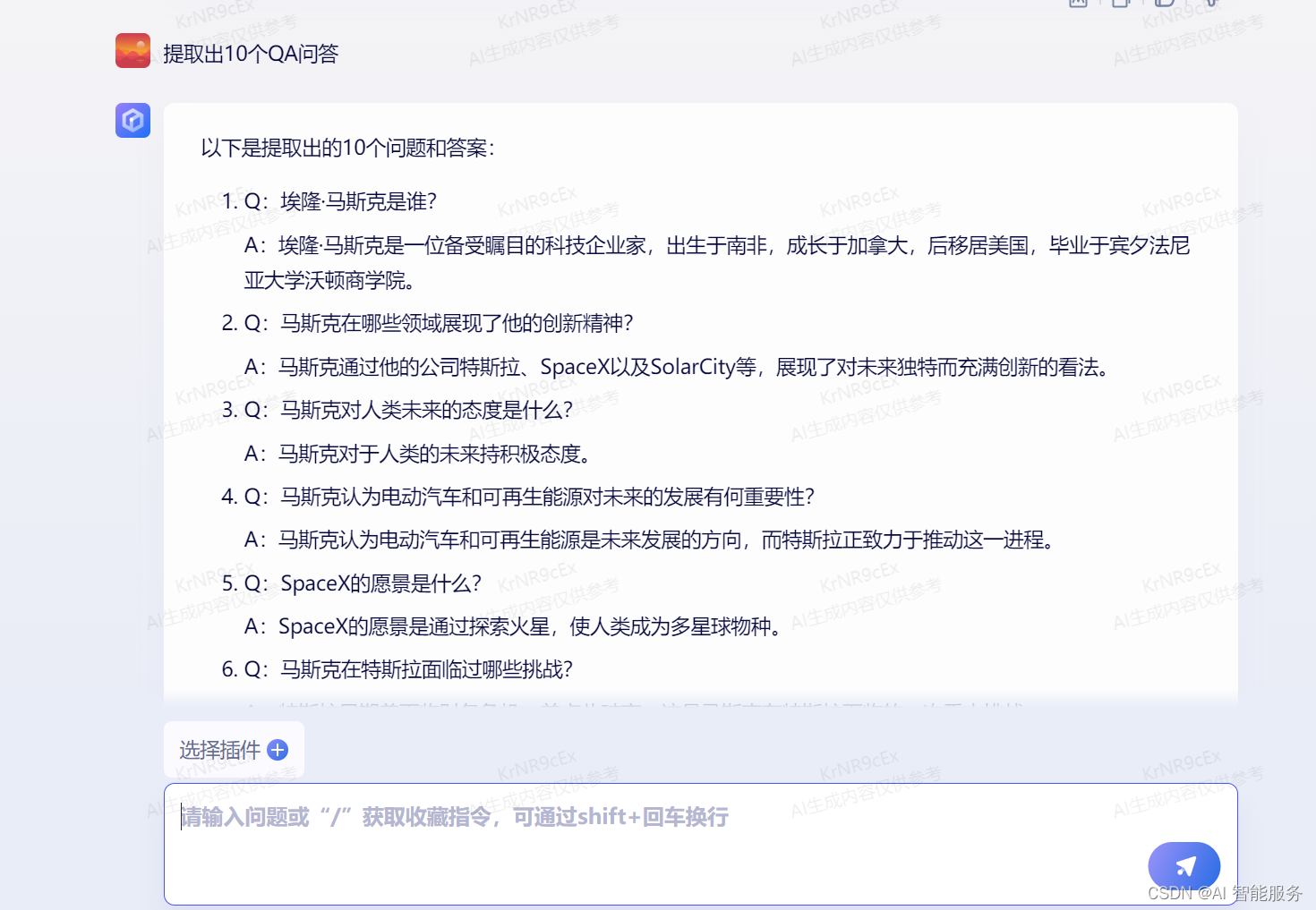
这就意味着客户只需要把文件发送过来,无需整理,就可以让机器人学习回答客户问题了。
1.2技术原理
将一篇文章提炼为QA对(问题与答案对)的技术原理主要涉及自然语言处理(NLP)和信息抽取。以下是一些关键步骤:
1. 文本预处理:首先,需要对文章进行一些预处理,包括分词、词性标注和句法分析。这些步骤能帮助理解文章中每个单词和短语的含义,以及它们之间的关系。
2. 关键词提取:接下来,可以通过TF-IDF(词频-逆文档频率)等方法来提取文章中的关键词。这些关键词可以帮助确定文章的主要讨论点。
3. 问题生成:基于文章中的主题和关键词,可以生成一系列可能的问题。这可能需要一些领域知识和对文章内容的理解。例如,可以通过关键词的同义词、反义词或关联词来生成问题。
4. 答案抽取:在生成问题的同时,需要从文章中抽取相应的答案。这通常涉及到对文章进行再次的深度阅读,并找出与问题相关的信息。有些答案可能直接在文中,而有些可能需要通过对文中的信息的逻辑推理才能得出。
5. QA对形成:最后,将生成的问题和抽取的答案配对形成QA对。这一步可能需要一些语言处理技巧,以确保问题和答案在语义上的一致性。
请注意,上述步骤并不保证生成的QA对完全准确或全面。这主要取决于文章的复杂性、领域知识以及算法的精确度。然而,这种技术方法为理解文章内容并提炼出关键信息提供了一种有用的途径。为了提高准确性,可以对算法进行训练和优化,或者采用更复杂的模型,如BERT等预训练模型。
2.基于标准问题自动生成相似问题
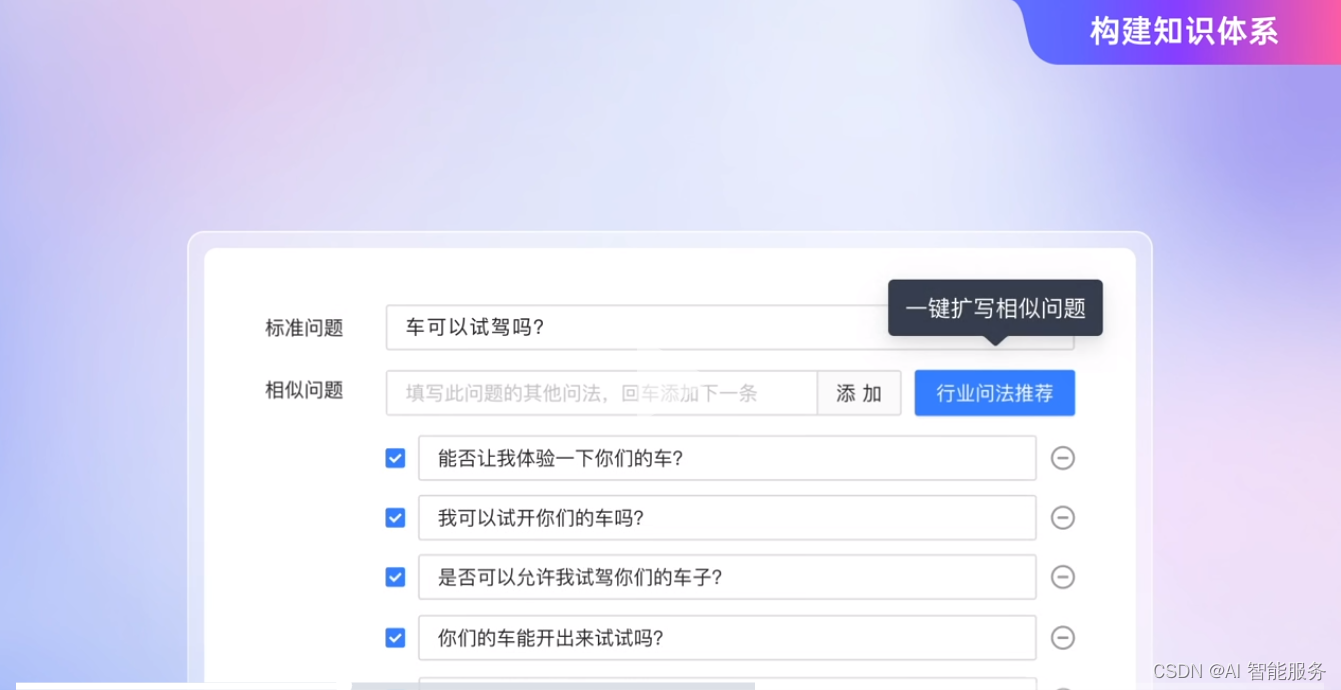
相似问的扩写可以优化模型,使模型更加精确地识别用户问题。
然而,早期许多企业的扩展问依靠人工编写,极大的拉长了项目周期,大模型自动扩充相似问题就显得尤为必要。
2.1技术原理
大模型编写相似问题的技术原理主要是基于深度学习和自然语言处理技术。
大模型需要通过对大量语料库进行训练来学习语言的模式和语义信息。这通常需要使用无监督学习算法,例如自编码器或变分自编码器等。这些算法可以通过学习输入数据的内在规律和结构,自动推断出数据的表示和生成方式。在大模型中,这些算法被用来学习对输入数据进行编码和解码的能力,从而能够将输入的文本转换为具有丰富语义信息的向量表示。
大模型在处理相似问题时,需要比较两个问题之间的相似性程度。这通常需要使用有监督学习算法,例如余弦相似度或欧氏距离等度量学习方法。这些算法可以学习问题的特征,并计算两个问题之间的相似性程度。在大模型中,这些算法被用来建立问题之间的联系和比较关系,从而能够识别相似问题和生成新的问题。
大模型需要使用生成式对话技术来回答相似问题。这通常需要使用神经网络模型,例如循环神经网络或变换器等。这些模型可以学习将输入的文本转换为输出的文本的能力,从而能够生成具有逻辑清晰、语义准确的回答。在大模型中,这些模型被用来生成回答并理解问题之间的联系和规律,从而能够回答相似问题和解决相似问题。