目录
1、什么是MyBatis
2、说说MyBatis的优点和缺点
3、#{}和${}的区别是什么?
4、当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
5、Mybatis是如何进行分页的?分页插件的原理是什么?
6、Mybatis是否支持延迟加载?实现原理是什么?
7、说说Mybatis的缓存机制
8、MyBatis 中见过什么设计模式?
1、什么是MyBatis
- Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。程序员直接编写原生态sql,可以严格控制sql执行性能,灵活度高。
- MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
- 通过xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java对象和statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。(从执行sql到返回result的过程)。
2、说说MyBatis的优点和缺点
优点:
- 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用。
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接。
- 很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)。
- 能够与Spring很好的集成。
- 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护。
缺点:
- SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
- SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
3、#{}和${}的区别是什么?
#{}是预编译处理,${}是字符串替换。
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性。
4、当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致。
<select id=”selectorder” parametertype=”int” resultetype=”me.gacl.domain.order”>select order_id id, order_no orderno ,order_price price form orders where order_id=#{id}
</select>通过来映射字段名和实体类属性名的一一对应的关系。
<select id="getOrder" parameterType="int" resultMap="orderresultmap">select * from orders where order_id=#{id}
</select>
<resultMap type=”me.gacl.domain.order” id=”orderresultmap”><!–用id属性来映射主键字段–><id property=”id” column=”order_id”><!–用result属性来映射非主键字段,property为实体类属性名,column为数据表中的属性–><result property = “orderno” column =”order_no”/><result property=”price” column=”order_price” />
</reslutMap>5、Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分
页。可以在sql内直接拼写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页,比如:MySQL数据的时候,在原有SQL后面拼写limit。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截
待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
6、Mybatis是否支持延迟加载?实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一
对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载
lazyLoadingEnabled=true|false。
实现原理:使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调
用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
7、说说Mybatis的缓存机制

一级缓存localCache
在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的 SQL,
MyBatis 提供了一级缓存的方案优化这部分场景,如果是相同的 SQL 语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。
每个 SqlSession 中持有了 Executor,每个 Executor 中有一个 LocalCache。当用户发起查询时,
MyBatis 根据当前执行的语句生成 MappedStatement,在 Local Cache 进行查询,如果缓存命中
的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入 Local Cache,最后
返回结果给用户。具体实现类的类关系图如下图所示:

- MyBatis 一级缓存的生命周期和 SqlSession 一致。
- MyBatis 一级缓存内部设计简单,只是一个没有容量限定的 HashMap,在缓存的功能性上有所欠缺。
- MyBatis 的一级缓存最大范围是 SqlSession 内部,有多个 SqlSession 或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为 Statement。
二级缓存
在上文中提到的一级缓存中,其最大的共享范围就是一个 SqlSession 内部,如果多个 SqlSession
之间需要共享缓存,则需要使用到二级缓存。开启二级缓存后,会使用 CachingExecutor 装饰
Executor,进入一级缓存的查询流程前,先在 CachingExecutor 进行二级缓存的查询,具体的工作
流程如下所示:
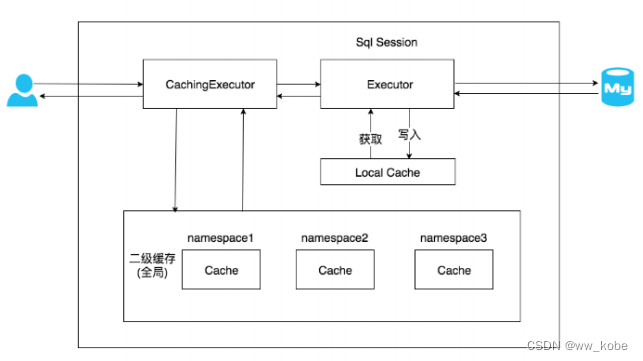
二级缓存开启后,同一个 namespace 下的所有操作语句,都影响着同一个 Cache,即二级缓存被
多个 SqlSession 共享,是一个全局的变量。
当开启缓存后,数据的查询执行的流程为:二级缓存 -> 一级缓存 -> 数据库
- MyBatis 的二级缓存相对于一级缓存来说,实现了 SqlSession 之间缓存数据的共享,同时粒度更加细,能够到 namespace 级别,通过 Cache 接口实现类不同的组合,对 Cache 的可控性也更强。
- MyBatis 在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
- 在分布式环境下,由于默认的 MyBatis Cache 实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将 MyBatis 的 Cache 接口实现,有一定的开发成本,直接使用 Redis、Memcached 等分布式缓存可能成本更低,安全性也更高。
8、MyBatis 中见过什么设计模式?