一、说明
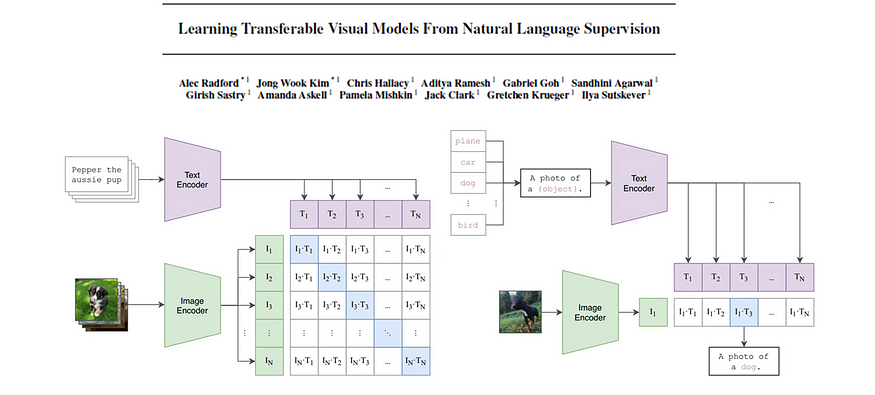
图片来源:
论文:从自然语言监督中学习可转移的视觉模型
代码:https://github.com/OpenAI/CLIP
首次发布时间:26 年 2021 月 <> 日
作者:亚历克·拉德福德、金钟旭、克里斯·哈拉西、阿迪亚·拉梅什、加布里埃尔·吴、桑迪尼·阿加瓦尔、吉里什·萨斯特里、阿曼达·阿斯克尔、帕梅拉·米什金、杰克·克拉克、格雷琴·克鲁格、伊利亚·苏茨克弗
类别: 多模态深度学习, 计算机视觉, 自然语言处理, 基础模型, 表示学习
二、背景简述
CLIP(Contrastive Language-I mage Pre-Training)是一个多模态模型,用于学习自然语言和图像之间的对应关系。它根据从互联网收集的 400 亿个文本图像对进行训练。正如我们将在本文后面发现的那样,CLIP 具有强大的零镜头性能,这意味着它在与训练不同的下游任务中表现良好,无需执行任何微调。
CLIP旨在:
- 将自然语言处理中已知的大规模预训练技术(例如GPT家族,T5和BERT)的成功应用于计算机视觉。
- 通过使用自然语言而不是固定的集合类标签,实现灵活的零镜头功能。
为什么你可能会问自己这是一件大事?首先,许多计算机视觉模型都是在众包标记数据集上训练的。这些数据集通常包含数十万个样本。一些例外情况是在百万个或两位数样本的范围内。可以想象,这是一个非常耗时且昂贵的过程。另一方面,自然语言模型的数据集通常要大几个数量级,并且是从互联网上抓取的。其次,如果对象检测模型已在某些类上训练,并且您想要添加额外的类,则需要在数据中标记此新类并重新训练模型。
CLIP将自然语言和图像特征相结合的能力与其零镜头性能相结合,导致许多其他流行的基础模型的广泛采用,例如UnCLIP,EVA,SAM,Stable Diffusion,GLIDE或VQGAN-CLIP,仅举几例。
三、CLIP的方法
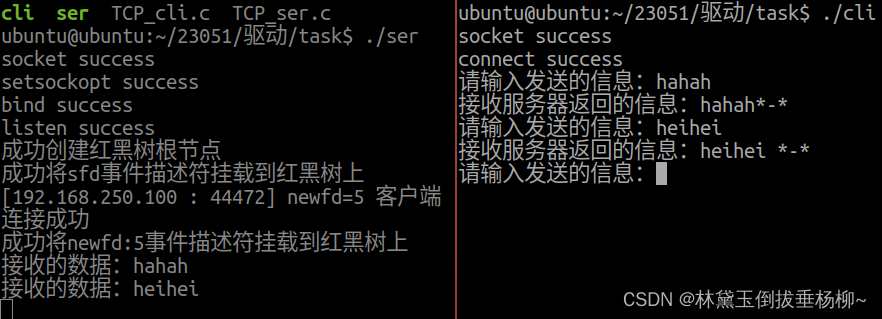
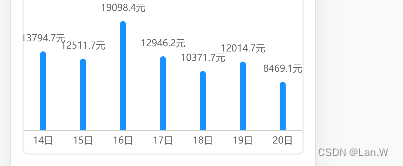
现在让我们深入了解 CLIP 的方法。图 1 中描绘的波纹管显示了 CLIP 的架构及其训练过程
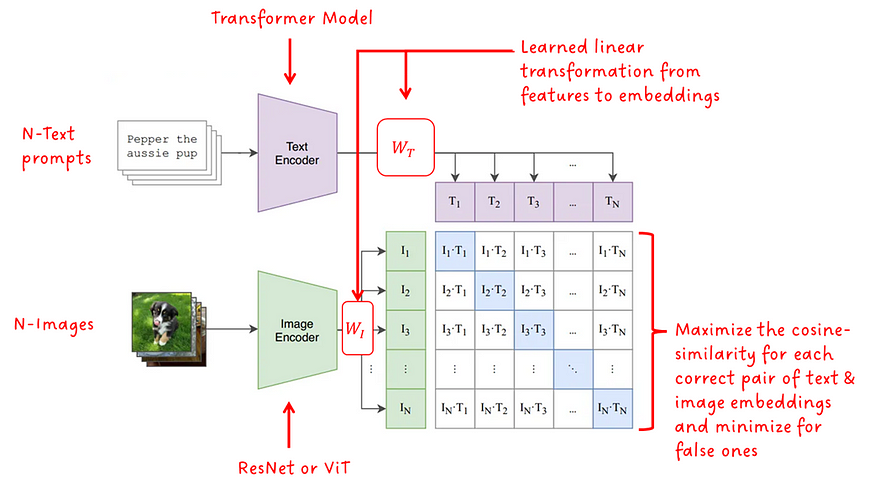
模型体系结构由两个编码器模型组成,每个模型对应一个模态。对于文本编码器,使用转换器,而图像编码器使用ResNet或ViT(视觉转换器)的版本。学习的线性变换(每种模态一个)将特征转换为大小匹配的嵌入。最后,计算相反模态的每个嵌入之间的余弦相似性,并通过学习的温度标量进行缩放。在训练过程中,匹配对之间的余弦相似性最大化,而不正确的对之间的余弦相似性最小化,因此框架名称中的术语“对比”。
当然,除了大型数据集之外,还有一些微妙之处对成功至关重要。首先,对比学习方法在很大程度上取决于批量大小 N。沿着正确的样本提供的负样本越多,学习信号就越强。CLIP 的批量大小为 32,768,这是相当大的。其次,CLIP不会学习确切措辞的匹配,而是一种更简单的代理任务,只学习整个文本,也称为单词袋(BoW)。
有趣的事实:使用 ResNet50x64 作为图像编码器的 CLIP 版本在 18 V592 GPU 上训练了 100 天,而使用 ViT 模型的版本在 12 V256 GPU 上训练了 100 天。换句话说,分别在单个 GPU 上超过 29 年和超过 8 年(忽略将使用不同的批量大小的事实)。
训练模型后,它可用于对图像执行对象分类。问题是:如何使用尚未训练对图像进行分类的模型进行分类,也没有输入类标签但文本提示?图2.演示如何:
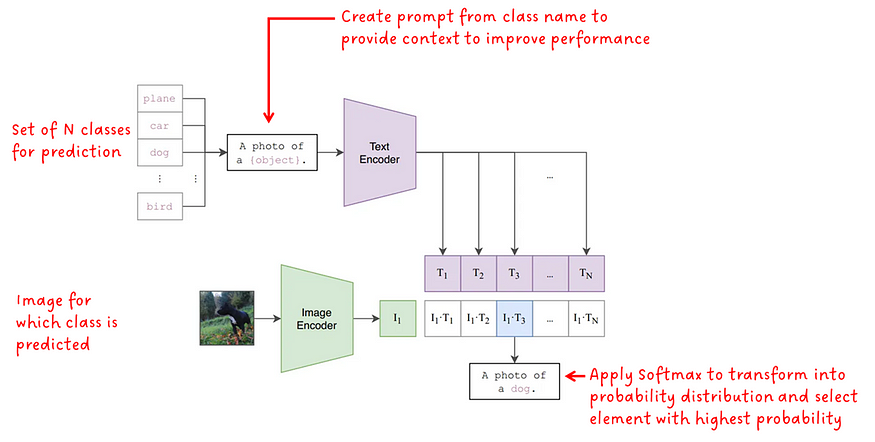
类标签可以看作是由单个单词组成的文本提示。为了告诉模型哪些类可用于分类任务,将一组 N 个类输入到模型中。与在一组固定标签上训练的分类模型相比,这是一个巨大的优势。我们现在可以输入 3 个类或 100 个类;这是我们的选择。正如我们稍后将看到的,为了提高 CLIP 的性能,类标签被转换为提示,以便为模型提供进一步的上下文。然后将每个提示馈送到文本编码器,然后转换为嵌入向量。
输入图像被馈送到图像编码器以获得嵌入向量。
然后计算每对文本和图像嵌入的余弦相似性。对获得的相似性值应用 Softmax 以形成概率分布。最后,选择概率最高的值作为最终预测。
四、实验和消融
CLIP论文介绍了大量的实验和消融。在这里,我们将介绍五个,我认为从中理解CLIP的成功很重要。先介绍一下要点(由 CLIP 的作者制定),然后我们将深入了解细节:
- 培训效率:CLIP在零镜头传输时比我们的图像标题基线更有效
- 文本输入格式:快速工程和集成可提高零射性能
- 零镜头性能:零镜头剪辑具有完全监督基线的竞争力
- 少镜头性能:零射程 CLIP 优于少射程线性探头
- 分配班次:零镜头 CLIP 比标准 ImageNet 型号更能抵抗分布偏移
4.1 培训效率
在训练期间,图像编码器和文本编码器是联合训练的,这意味着同时使用单个训练目标。CLIP不仅执行对比学习方案,而且将文本提示作为一个整体与给定的图像进行比较,因此单词的顺序无关紧要。它只是一个“文字袋”。短语“我的名字是萨沙”与“萨沙的名字是我的”产生相同的嵌入。
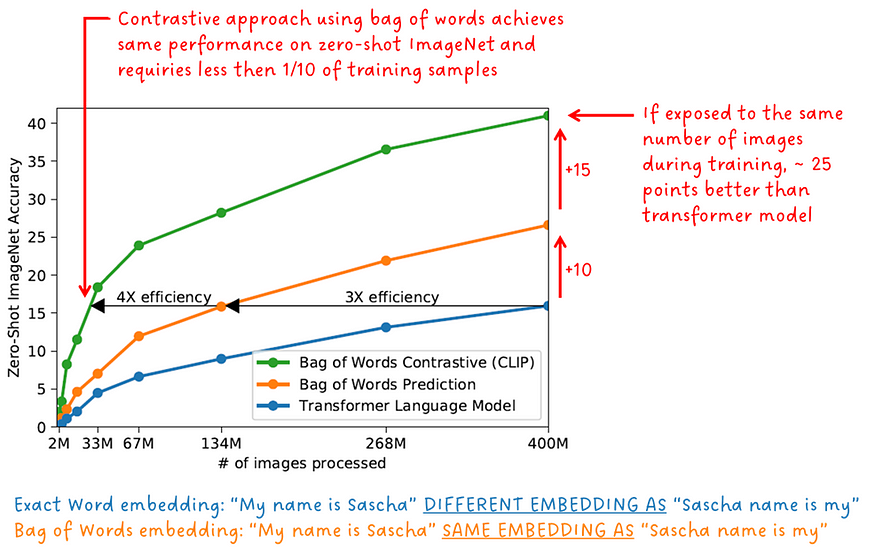
预测一袋单词而不是正确的单词及其在短语中的位置是一个更容易的代理目标。图3.波纹管显示了 ImageNet 上针对训练用于预测精确单词的初始转换器模型、训练用于预测单词袋的初始转换器模型以及使用单词袋执行对比学习的 CLIP 模型的训练样本数的零镜头精度。
“CLIP 在零镜头传输方面比我们的图像标题基线效率高得多” — CLIP 作者
4.2 文本输入格式
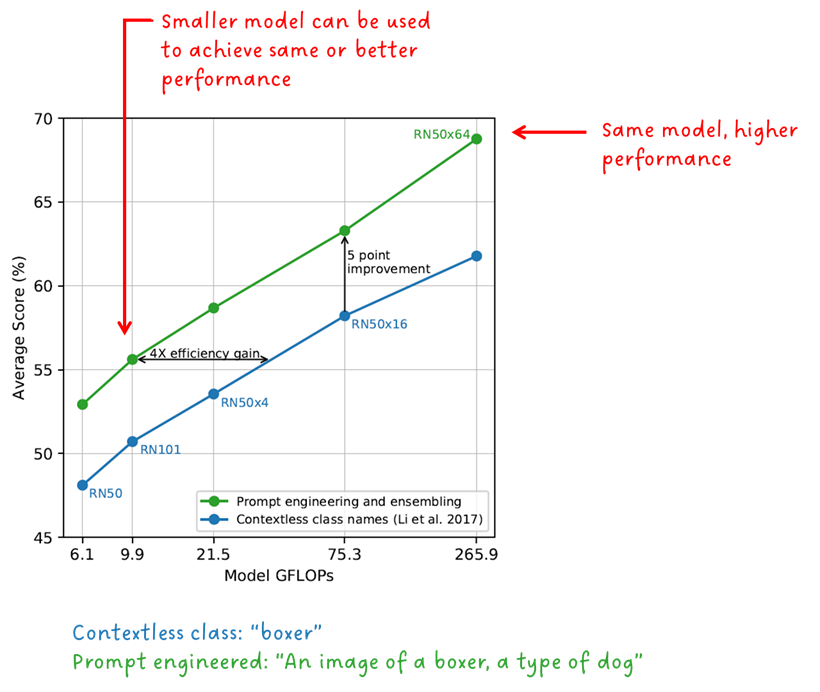
正如我们在图 2 中看到的,为了执行对象分类,类标签已转换为文本提示。当然,这不是偶然的,因为CLIP完全可以用一个词。这样做是为了利用语言的描述性,并提供上下文来解决可能的歧义。让我们以“拳击手”这个词为例。它可能是一种狗或一种运动员。CLIP的作者已经表明,文本提示的格式非常重要,可以提高性能并提高效率。
“快速工程和集成提高了零镜头性能” — CLIP 作者
4.3 零镜头性能
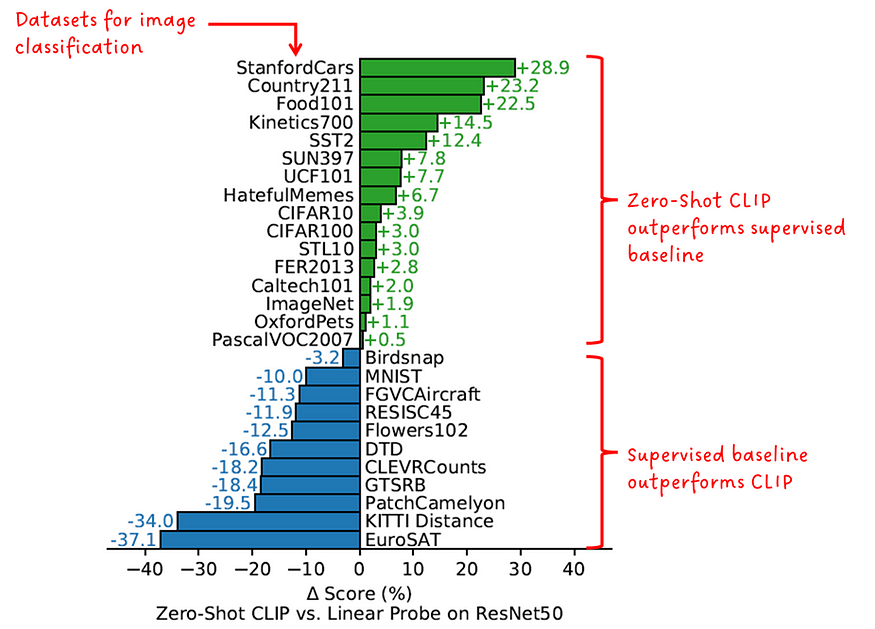
在另一个实验中,作者将CLIP的零镜头图像分类性能与专门在比较数据集上训练的模型进行了比较。
“零镜头 CLIP 与完全监督的基线具有竞争力” — CLIP 作者
4.4 少镜头性能
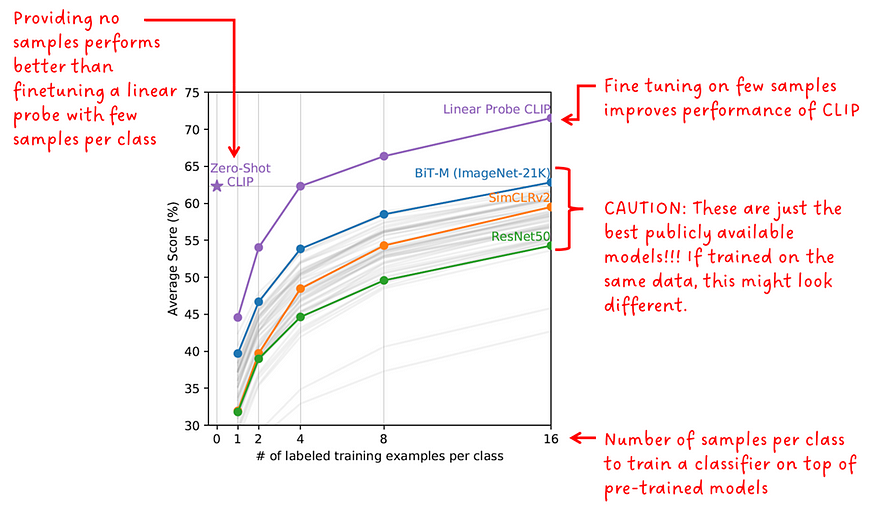
虽然零镜头预测器没有对下游任务进行微调,但很少有镜头检测器可以。作者对多个公开可用的预训练模型进行了实验,并将其在20个不同数据集上的少数镜头性能与零镜头和少镜头CLIP进行了比较。少数镜头模型在每个班级的 1、2、4、8 和 16 个样本上进行了微调。
有趣的是,零镜头 CLIP 的表现大致与 4 镜头 CLIP 一样好。
如果将CLIP与其他模型进行比较,则必须考虑所比较的公开可用模型(即BiT,SimCLR和ResNet)已经在不同且较小的数据集上预先训练为CLIP模型。
“零镜头 CLIP 优于少镜头线性探头” — CLIP 作者
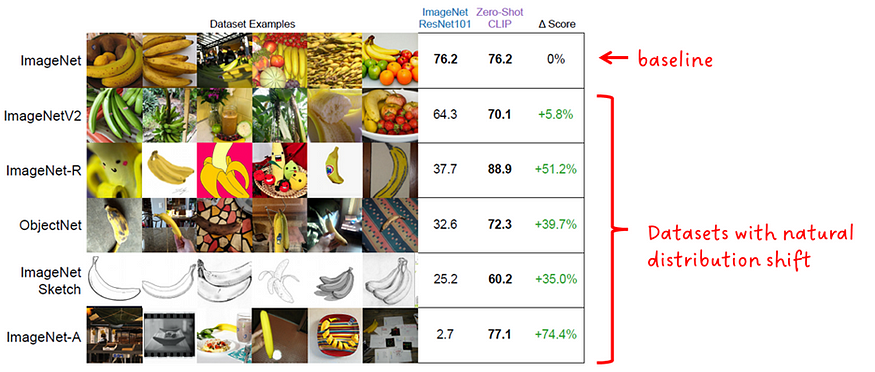
4.5 分布转移
一般来说,模型对分布偏移的鲁棒性是指它能够在不同数据分布的数据上表现得与在训练数据的数据分布上一样好。理想情况下,它的性能同样好。实际上,它的性能会下降。
零镜头CLIP的鲁棒性已与ResNet101 ImageNet模型进行了比较。两种模型都在 ImageNet 的自然分布偏移上进行评估,如图 7 所示。
“零镜头 CLIP 比标准 ImageNet 模型更能适应分布偏移” — CLIP 作者
五、更多阅读和资源
萨沙·基尔希
正如本文开头提到的,CLIP已被大量项目广泛采用。以下是使用 CLIP 的论文列表:
- [解剪辑]使用 CLIP 潜伏生成分层文本条件图像
- [伊娃]探索大规模遮罩视觉表示学习的局限性
- [山姆]细分任何内容
- [稳定扩散]基于潜在扩散模型的高分辨率图像合成
- [滑翔]使用文本引导扩散模型实现逼真的图像生成和编辑
- [VQGAN-CLIP]使用自然语言指导生成和编辑开放域图像
如果您想深入了解实现并自己测试,则提供存储库列表:
- OpenAI 的官方回购
- Python Notebook 可以玩 CLIP
- OpenCLIP:CLIP的开源实现