引自:https://blog.csdn.net/no1xiaoqianqian/article/details/130593783
友好借鉴,总体抄袭。
所需要的文件如下:https://download.csdn.net/download/m0_37567738/88340795
import os
import torch
import torch.nn as nn
import numpy as npclass TextRNN(nn.Module):def __init__(self, Config):super(TextRNN, self).__init__()self.hidden_size = 128 # lstm隐藏层self.num_layers = 2 # lstm层数self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)self.lstm = nn.LSTM(Config.embed_dim, self.hidden_size, self.num_layers,bidirectional=True, batch_first=True, dropout=Config.dropout)self.fc = nn.Linear(self.hidden_size * 2, Config.num_classes)def forward(self, x):out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]out, _ = self.lstm(out)out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden statereturn outimport torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import copyclass Transformer(nn.Module):def __init__(self, Config):super(Transformer, self).__init__()self.hidden = 1024self.last_hidden = 512self.num_head = 5self.num_encoder = 2self.dim_model = 300self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)self.postion_embedding = Positional_Encoding(Config.embed_dim, Config.all_seq_len, Config.dropout, Config.device)self.encoder = Encoder(self.dim_model, self.num_head, self.hidden, Config.dropout)self.encoders = nn.ModuleList([copy.deepcopy(self.encoder)# Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)for _ in range(self.num_encoder)])self.fc1 = nn.Linear(Config.all_seq_len * self.dim_model, Config.num_classes)# self.fc2 = nn.Linear(config.last_hidden, config.num_classes)# self.fc1 = nn.Linear(config.dim_model, config.num_classes)def forward(self, x):out = self.embedding(x)out = self.postion_embedding(out)for encoder in self.encoders:out = encoder(out)out = out.view(out.size(0), -1)# out = torch.mean(out, 1)out = self.fc1(out)return outclass Encoder(nn.Module):def __init__(self, dim_model, num_head, hidden, dropout):super(Encoder, self).__init__()self.attention = Multi_Head_Attention(dim_model, num_head, dropout)self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)def forward(self, x):out = self.attention(x)out = self.feed_forward(out)return outclass Positional_Encoding(nn.Module):def __init__(self, embed, pad_size, dropout, device):super(Positional_Encoding, self).__init__()self.device = deviceself.pe = torch.tensor([[pos / (10000.0 ** (i // 2 * 2.0 / embed)) for i in range(embed)] for pos in range(pad_size)])self.pe[:, 0::2] = np.sin(self.pe[:, 0::2])self.pe[:, 1::2] = np.cos(self.pe[:, 1::2])self.dropout = nn.Dropout(dropout)def forward(self, x):out = x + nn.Parameter(self.pe, requires_grad=False).to(self.device)out = self.dropout(out)return outclass Scaled_Dot_Product_Attention(nn.Module):'''Scaled Dot-Product Attention '''def __init__(self):super(Scaled_Dot_Product_Attention, self).__init__()def forward(self, Q, K, V, scale=None):'''Args:Q: [batch_size, len_Q, dim_Q]K: [batch_size, len_K, dim_K]V: [batch_size, len_V, dim_V]scale: 缩放因子 论文为根号dim_KReturn:self-attention后的张量,以及attention张量'''attention = torch.matmul(Q, K.permute(0, 2, 1))if scale:attention = attention * scale# if mask: # TODO change this# attention = attention.masked_fill_(mask == 0, -1e9)attention = F.softmax(attention, dim=-1)context = torch.matmul(attention, V)return contextclass Multi_Head_Attention(nn.Module):def __init__(self, dim_model, num_head, dropout=0.0):super(Multi_Head_Attention, self).__init__()self.num_head = num_headassert dim_model % num_head == 0self.dim_head = dim_model // self.num_headself.fc_Q = nn.Linear(dim_model, num_head * self.dim_head)self.fc_K = nn.Linear(dim_model, num_head * self.dim_head)self.fc_V = nn.Linear(dim_model, num_head * self.dim_head)self.attention = Scaled_Dot_Product_Attention()self.fc = nn.Linear(num_head * self.dim_head, dim_model)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(dim_model)def forward(self, x):batch_size = x.size(0)Q = self.fc_Q(x)K = self.fc_K(x)V = self.fc_V(x)Q = Q.view(batch_size * self.num_head, -1, self.dim_head)K = K.view(batch_size * self.num_head, -1, self.dim_head)V = V.view(batch_size * self.num_head, -1, self.dim_head)# if mask: # TODO# mask = mask.repeat(self.num_head, 1, 1) # TODO change thisscale = K.size(-1) ** -0.5 # 缩放因子context = self.attention(Q, K, V, scale)context = context.view(batch_size, -1, self.dim_head * self.num_head)out = self.fc(context)out = self.dropout(out)out = out + x # 残差连接out = self.layer_norm(out)return outclass Position_wise_Feed_Forward(nn.Module):def __init__(self, dim_model, hidden, dropout=0.0):super(Position_wise_Feed_Forward, self).__init__()self.fc1 = nn.Linear(dim_model, hidden)self.fc2 = nn.Linear(hidden, dim_model)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(dim_model)def forward(self, x):out = self.fc1(x)out = F.relu(out)out = self.fc2(out)out = self.dropout(out)out = out + x # 残差连接out = self.layer_norm(out)return outimport torch.nn as nn
import torch
import torch.nn.functional as Fclass TextCNN(nn.Module):def __init__(self, Config):super(TextCNN, self).__init__()self.filter_sizes = (2, 3, 4) # 卷积核尺寸self.num_filters = 64 # 卷积核数量(channels数)self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)self.convs = nn.ModuleList([nn.Conv2d(1, self.num_filters, (k, Config.embed_dim)) for k in self.filter_sizes])self.dropout = nn.Dropout(Config.dropout)self.fc = nn.Linear(self.num_filters * len(self.filter_sizes), Config.num_classes)def conv_and_pool(self, x, conv):x = F.relu(conv(x))x = x.squeeze(3)x = F.max_pool1d(x, x.size(2)).squeeze(2)return xdef forward(self, x):out = self.embedding(x)out = out.unsqueeze(1)out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)out = self.dropout(out)out = self.fc(out)return outimport matplotlib.pyplot as plt
import numpy as npdef draw_loss_pic(train_loss, test_loss, y):x = np.linspace(0, len(train_loss), len(train_loss))plt.plot(x, train_loss, label="train_" + y, linewidth=1.5)plt.plot(x, test_loss, label="test_" + y, linewidth=1.5)plt.xlabel("epoch")plt.ylabel(y)plt.legend()plt.show()import torchclass Config():train_data_path = '../data/virus_train.txt'test_data_path = '../data/virus_eval_labeled.txt'vocab_path = '../data/vocab.pkl'split_word_all_path = '../data/split_word_all.txt'model_file_name_path = '../data/vec_model.txt'id_vec_path = '../data/id_vec.pkl'device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')word_level = True # 按照字级别进行分词embedding_pretrained = False # 是否使用预训练的词向量label_fields = {'neural': 0, 'happy': 1, 'angry': 2, 'sad': 3, 'fear': 4, 'surprise': 5}all_seq_len = 64 # 句子长度,长剪短补batch_size = 128learning_rate = 0.0001epoches = 50dropout = 0.5num_classes = 6embed_dim = 300n_vocab = 0import re
import os
import json
#import jieba
import pickle as pkl
import numpy as np
import gensim.models.word2vec as w2v
import torch
#from src.Config import Config
import torch.utils.data as Datatrain_data_path = Config.train_data_path
test_data_path = Config.test_data_path
vocab_path = Config.vocab_pathlabel_fields = Config.label_fields
all_seq_len = Config.all_seq_lenUNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号def build_vocab(content_list, tokenizer):file_split_word = open(Config.split_word_all_path, 'w', encoding='utf-8')vocab_dic = {}for content in content_list:word_lines = []for word in tokenizer(content):vocab_dic[word] = vocab_dic.get(word, 0) + 1word_lines.append(word)str = " ".join(word_lines) + "\n"file_split_word.write(str)file_split_word.close()vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})vocab_dic = {word_count: idx for idx, word_count in enumerate(vocab_dic)}return vocab_dicdef build_id_vec(vocab_dic, model):model.wv.add_vector(UNK, np.zeros(300))model.wv.add_vector(PAD, np.ones(300))id2vec = {}for word in vocab_dic.keys():id = vocab_dic.get(word, vocab_dic.get(UNK))vec = model.wv.get_vector(word)id2vec.update({id: vec})return id2vecdef train_vec():model_file_name = Config.model_file_name_pathsentences = w2v.LineSentence(Config.split_word_all_path)model = w2v.Word2Vec(sentences, vector_size=300, window=20, min_count=0)model.save(model_file_name)def load_data(root):content_list = []content_token_list = []label_list = []if Config.word_level:tokenizer = lambda x: [y for y in x]else:tokenizer = lambda x: jieba.cut(x, cut_all=False)file = open(root, 'r', encoding='utf-8')datas = json.load(file)# pattern = re.compile(r'[^\u4e00-\u9fa5|,|。|!|?|\[|\]]')pattern = re.compile(r'[^\u4e00-\u9fa5|,|。|!|?]')# pattern = re.compile(r'[^\u4e00-\u9fa5|,|。]') # seq_len=32 CNN:67%-68% RNN:61%-62% Transformer:63-64%# pattern = re.compile(r'[^\u4e00-\u9fa5|,|。|!]') # CNN:65%-66%for data in datas:content_after_clean = re.sub(pattern, '', data['content'])content_list.append(content_after_clean)label_list.append(label_fields[data['label']])if os.path.exists(vocab_path):vocab = pkl.load(open(vocab_path, 'rb'))else:vocab = build_vocab(content_list, tokenizer)pkl.dump(vocab, open(vocab_path, 'wb'))if Config.embedding_pretrained:train_vec()model = w2v.Word2Vec.load(Config.model_file_name_path)id_vec = build_id_vec(vocab, model)pkl.dump(id_vec, open(Config.id_vec_path, 'wb'))for content in content_list:word_line = []token = list(tokenizer(content))seq_len = len(token)if seq_len < all_seq_len:token.extend([PAD] * (all_seq_len - seq_len))else:token = token[:all_seq_len]for word in token:word_line.append(vocab.get(word, vocab.get(UNK)))content_token_list.append(word_line)n_vocab = len(vocab)return content_token_list, label_list, n_vocabclass WeiBboDataset(Data.Dataset):def __init__(self, content_token_list, label_list):super(WeiBboDataset, self).__init__()self.content_token_list = content_token_listself.label_list = label_listdef __getitem__(self, index):label = float(self.label_list[index])return torch.tensor(self.content_token_list[index]), torch.tensor(label)def __len__(self):return len(self.label_list)def get_data(batch_size):train_content_token_list, train_label_list, n_vocab = load_data(train_data_path)test_content_token_list, test_label_list, _ = load_data(test_data_path)train_dataset = WeiBboDataset(train_content_token_list, train_label_list)test_dataset = WeiBboDataset(test_content_token_list, test_label_list)train_dataloader = Data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)test_dataloader = Data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)return train_dataloader, test_dataloader, n_vocabif __name__ == '__main__':get_data(32)import os
import torch
import torch.nn as nn
from torch.autograd import Variable
#from utils.draw_loss_pic import draw_loss_picos.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"def train(net, loss, optimizer, train_loader, test_loader, epoches, device):train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epoches):net.train()total_loss = 0.0correct = 0sample_num = 0for batch_idx, (data, target) in enumerate(train_loader):data = data.to(device).long()target = target.to(device).long()optimizer.zero_grad()output = net(data)ls = loss(output, target)ls.backward()optimizer.step()total_loss += ls.item()sample_num += len(target)max_output = output.data.max(1, keepdim=True)[1].view_as(target)correct += (max_output == target).sum()print('epoch %d, train_loss %f, train_acc: %f' % (epoch + 1, total_loss/sample_num, float(correct.data.item()) / sample_num))train_loss.append(total_loss/sample_num)train_acc.append(float(correct.data.item()) / sample_num)test_ls, test_accury = test(net, test_loader, device, loss)test_loss.append(test_ls)test_acc.append(test_accury)draw_loss_pic(train_loss, test_loss, "loss")draw_loss_pic(train_acc, test_acc, "acc")def test(net, test_loader, device, loss):net.eval()total_loss = 0.0correct = 0sample_num = 0for batch_idx, (data, target) in enumerate(test_loader):data = data.to(device)target = target.to(device).long()output = net(data)ls = loss(output, target)total_loss += ls.item()sample_num += len(target)max_output = output.data.max(1, keepdim=True)[1].view_as(target)correct += (max_output == target).sum()print('test_loss %f, test_acc: %f' % (total_loss / sample_num, float(correct.data.item()) / sample_num))return total_loss / sample_num, float(correct.data.item()) / sample_numimport torch
import torch.nn as nn
import torch.optim as optim
import pickle as pkl
#from src.models.textCNN import TextCNN
#from src.models.textRNN import TextRNN
#from src.models.Transformer import Transformer
#from src.Config import Config
#from src.get_data import get_data
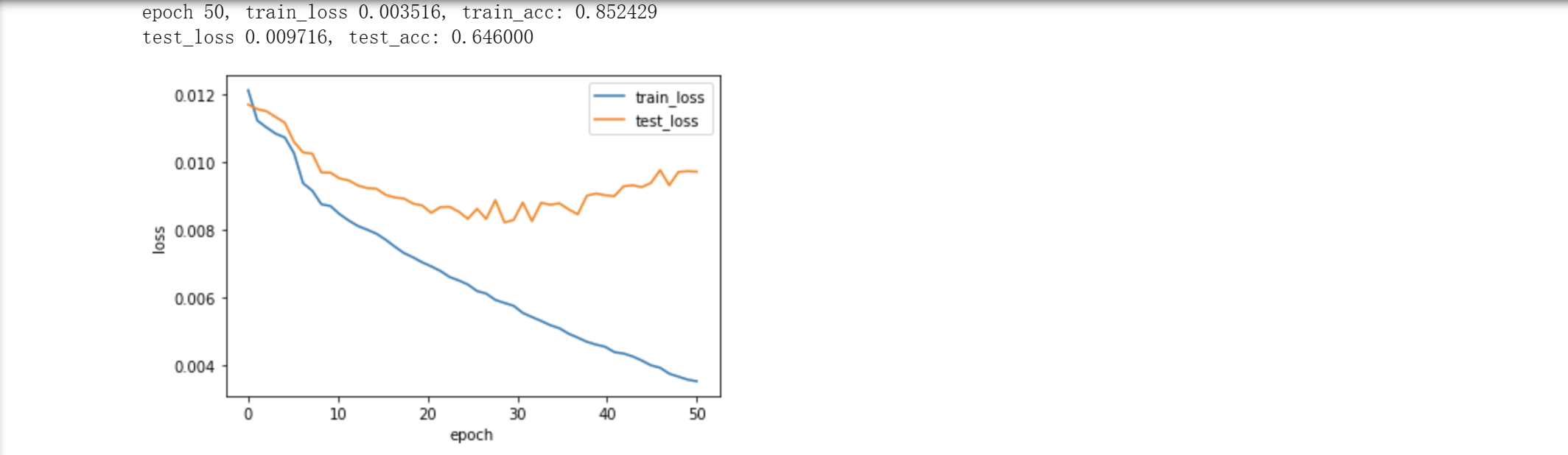
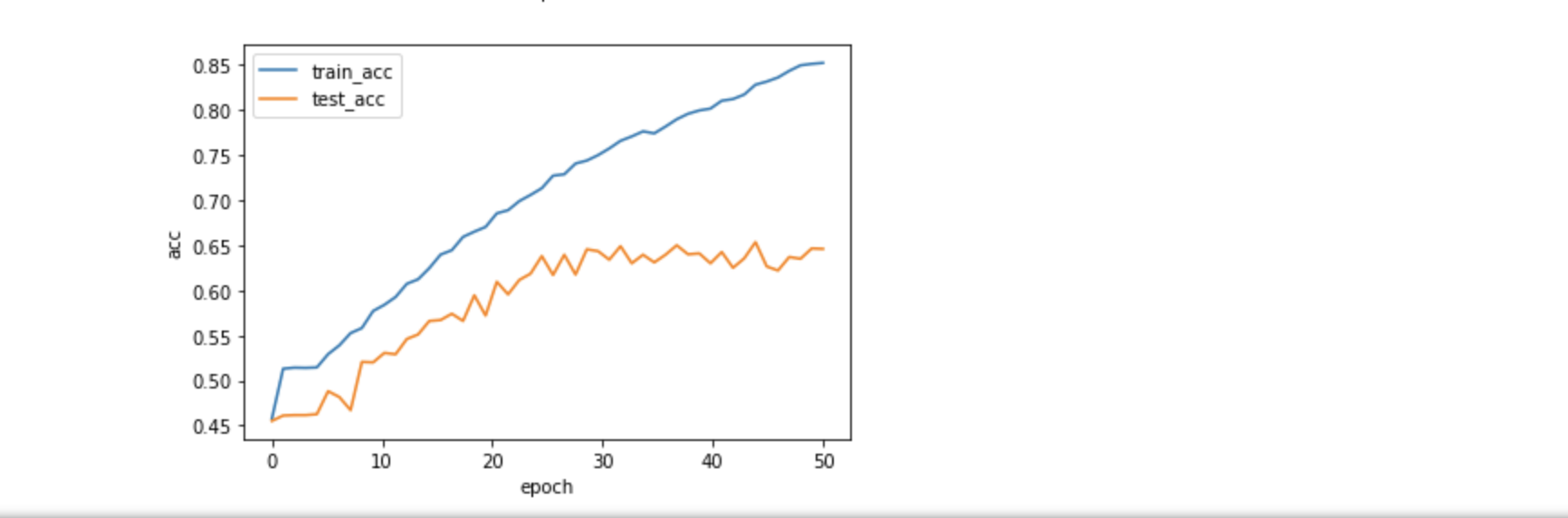
#from src.train import trainif __name__ == '__main__':config = Config()batch_size = config.batch_sizelearning_rate = config.learning_ratetrain_dataloader, test_dataloader, n_vocab = get_data(batch_size)config.n_vocab = n_vocab# model = TextCNN(config).to(Config.device)model = TextRNN(config).to(Config.device)# model = Transformer(config).to(Config.device)# 导入word2vec训练出来的预训练词向量id_vec = open(Config.id_vec_path, 'rb')id_vec = pkl.load(id_vec)id_vec = torch.tensor(list(id_vec.values())).to(Config.device)if config.embedding_pretrained:model.embedding = nn.Embedding.from_pretrained(id_vec)loss = nn.CrossEntropyLoss().to(Config.device)optimizer = optim.Adam(params=model.parameters(), lr=learning_rate)train(model, loss, optimizer, train_dataloader, test_dataloader, Config.epoches, Config.device)运行结果(准确率和错误率):
正确率达到85%。